Chaque jour, des milliards de données sont publiées sur Internet : prix de produits, avis clients, annonces immobilières, horaires de train, publications sur les réseaux sociaux, et bien plus encore. Dans cet océan d’informations, le web scraping s’impose comme une technique puissante pour extraire automatiquement ces données (notamment en SEO) et les utiliser à des fins diverses. Mais que recouvre exactement ce terme ? Comment fonctionne-t-il, et dans quels cas peut-il être utile, ou problématique ? Plongeons ensemble dans le monde fascinant du web scraping, où automatisation, code et stratégie se rencontrent au cœur du web visible.
- La définition du web scraping : Extraire automatiquement des données depuis des sites web
- Le fonctionnement du web scraping : Étapes, outils et techniques principales
- Exploiter le web scraping pour booster sa stratégie SEO
- 1. L’analyse sémantique et l’optimisation des mots-clés en SEO
- 2.L’audit technique SEO de sites concurrents
- 3. Le suivi de positionnement et de contenu en SEO
- 4. La création de contenus enrichis et pertinents
- 5. Détection d’opportunités de backlinks
- Web scraping et SEO : Un tandem à manier avec discernement
La définition du web scraping : Extraire automatiquement des données depuis des sites web
Le web scraping, ou extraction de données web en français, désigne une méthode automatisée permettant de récupérer des informations depuis des pages Internet. Contrairement à une lecture humaine classique d’un site, cette technique repose sur des scripts ou des programmes informatiques qui analysent le code source HTML des pages web, identifient les données ciblées (titres, prix, images, liens, etc.) et les extraient dans un format structuré (comme CSV, JSON ou SQL) pour une utilisation ultérieure. Le mot « scraping » provient du verbe anglais to scrape, qui signifie « gratter » ou « racler ». Dans ce contexte, il illustre parfaitement le principe du web scraping : « racler » le contenu d’un site web, couche par couche, afin d’en isoler les informations pertinentes, à des fins diverses : veille concurrentielle, analyse de marché, création de bases de données, ou encore optimisation de contenus web.
Une origine liée à l’évolution du web et des moteurs de recherche
L’histoire du web scraping est étroitement liée à celle de l’Internet grand public et des moteurs de recherche. Dès les années 1990, à l’émergence du World Wide Web, les premiers besoins en collecte massive d’information sont apparus dans des domaines comme la recherche universitaire, la finance et le commerce électronique. L’un des premiers exemples connus de scraping organisé est celui du projet World Wide Web Worm (1994), un ancêtre des moteurs de recherche, développé par Oliver McBryan à l’Université du Colorado. Il s’agissait déjà d’explorer automatiquement des pages web pour en extraire des métadonnées.
Avec l’arrivée de Google en 1998, le web scraping a pris une dimension nouvelle : le web crawling (ou exploration automatisée du web) est devenu une fonction essentielle du référencement naturel (SEO). Les robots d’indexation comme Googlebot parcourent continuellement des milliards de pages pour alimenter les bases de données des moteurs de recherche. Ces crawlers peuvent être vus comme des cousins du scraping, bien que leur objectif soit différent : ils indexent l’information, sans forcément l’extraire pour un usage personnalisé.
Le web scraping au service de la donnée : vers une automatisation croissante
Dans les années 2000, avec l’essor de l’e-commerce, des forums et des réseaux sociaux, les entreprises ont commencé à se doter de scrapers spécialisés pour suivre les prix des concurrents, détecter des tendances de consommation ou alimenter des agrégateurs. Des outils comme cURL (développé en 1997 par Daniel Stenberg), Scrapy (2008, projet open-source en Python), ou BeautifulSoup (créé en 2004 par Leonard Richardson) sont devenus des piliers du scraping moderne.
Parallèlement, les géants du numérique ont commencé à se doter de systèmes pour limiter ou contrôler l’accès à leurs données, comme des APIs officielles (Application Programming Interfaces). Par exemple :
- Twitter a lancé son API dès 2006 pour encadrer l’accès à ses données ;
- Facebook a mis en place des restrictions d’accès renforcées après le scandale Cambridge Analytica (2018) ;
- LinkedIn a mené plusieurs actions juridiques contre des entreprises pratiquant le scraping illégal de profils (exemple : l’affaire HiQ Labs vs. LinkedIn, en 2017).
Malgré cela, le web scraping reste une pratique légitime dans de nombreux cas, en particulier quand il s’applique à des données publiques non protégées par des restrictions contractuelles ou techniques. Les scrapers modernes sont capables de gérer des sites dynamiques, des contenus en JavaScript ou des interfaces complexes, grâce à des outils comme Selenium, Puppeteer ou Playwright.
Des usages multiples, de la veille au SEO
Le web scraping peut servir à des fins très diverses, et de nombreux professionnels y ont recours, souvent sans le savoir, via des outils ou plateformes qui intègrent cette logique. Voici quelques exemples d’usages courants :
- Veille concurrentielle : suivre automatiquement les prix ou les promotions de concurrents sur les sites e-commerce ;
- Optimisation SEO : extraire les balises titres, méta-descriptions ou h1 d’un site concurrent pour analyser sa stratégie de référencement ;
- Content marketing : surveiller les sujets qui génèrent le plus d’engagement sur les blogs ou les réseaux sociaux ;
- Ressources humaines : collecter des annonces d’emploi pour nourrir un site ou une base de données RH ;
- Recherche académique : extraire des publications, citations ou contenus spécialisés pour constituer un corpus de travail.
Dans le cadre du SEO, le scraping peut être un levier stratégique. Des outils comme Screaming Frog, Semrush ou Ahrefs utilisent des technologies similaires pour collecter et analyser des données de sites web. Grâce au scraping, les professionnels du référencement peuvent :
- Repérer des erreurs techniques (liens cassés, redirections, pages orphelines) ;
- Analyser la structure des balises HTML (h1, h2, title, etc.) ;
- Extraire les contenus des pages à des fins d’audit ou de refonte ;
- Surveiller les modifications SEO d’un concurrent dans le temps.
Le web scraping se situe donc au croisement de l’automatisation, de la stratégie digitale et de l’analyse de données. Il constitue un outil précieux dans un environnement numérique où l’information évolue vite, et où la capacité à capter ces changements fait souvent la différence entre la réaction et l’anticipation.
Le fonctionnement du web scraping : Étapes, outils et techniques principales
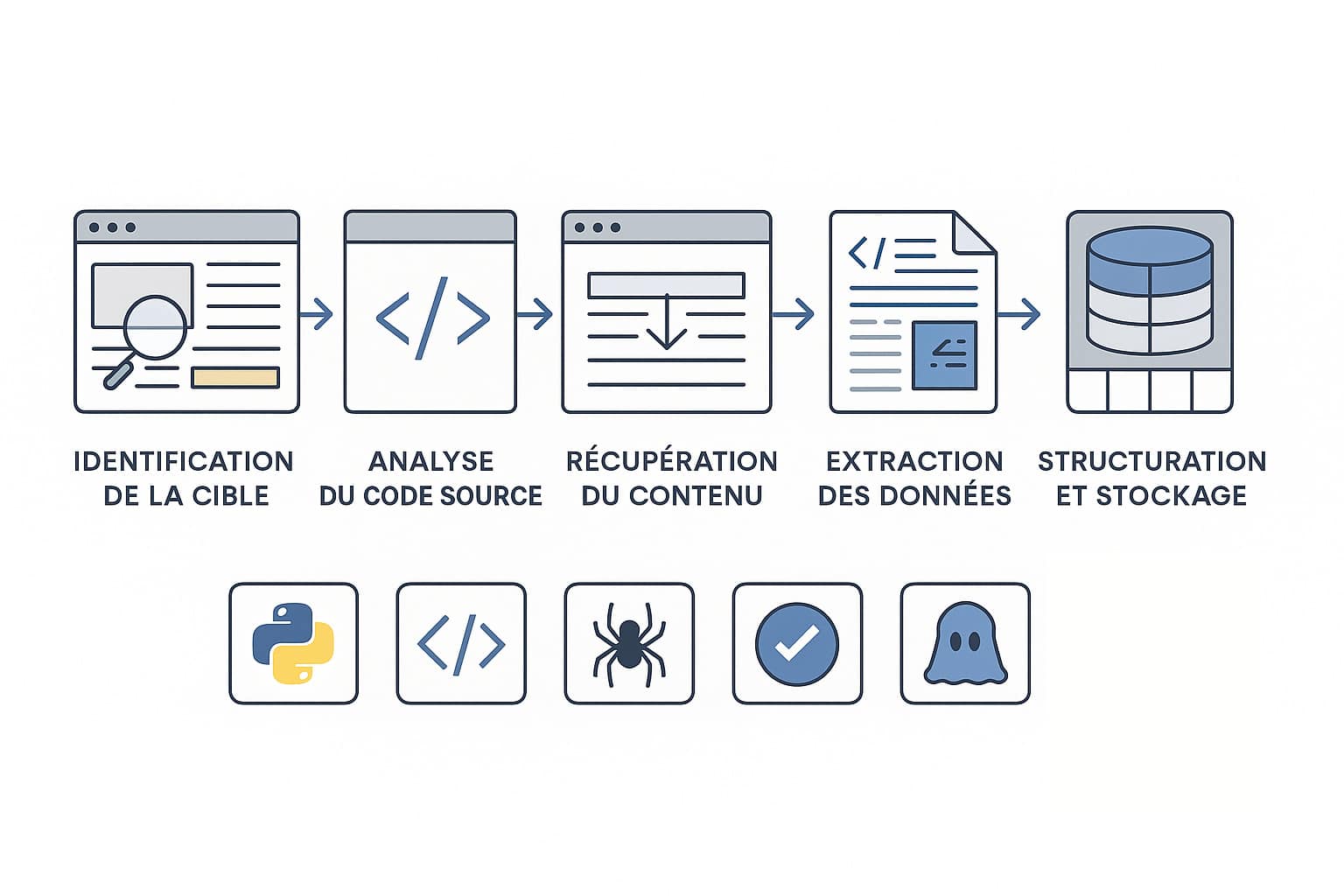
Le web scraping repose sur une série d’étapes méthodiques qui permettent d’extraire, transformer et exploiter des données disponibles sur des sites web. Contrairement à une copie manuelle de contenu, le scraping automatise le processus en utilisant des langages de programmation, des bibliothèques spécialisées et parfois des outils graphiques ou des navigateurs virtuels. Chaque opération suit un chemin logique, mais la complexité varie selon le site ciblé, sa technologie et ses mesures de protection. Voici les principales étapes d’un processus de scraping bien structuré :
- L’identification de la cible : il s’agit de déterminer quels sites web contiennent les données recherchées et quelles informations précises doivent être extraites (titres d’articles, prix de produits, notes clients, liens, dates, images, etc.). À cette étape, on définit également la fréquence de scraping (ponctuel, quotidien, horaire, etc.) et les règles de priorité dans les données ;
- L’analyse du code source : Chaque site est construit avec du HTML (et souvent du CSS et JavaScript). Il faut donc inspecter la structure du DOM (Document Object Model) via les outils de développement des navigateurs (comme l’inspecteur Chrome ou Firefox) pour repérer les balises pertinentes (comme <div>, <span>, <a>, <img>, etc.) ;
- La récupération du contenu : une requête HTTP (GET) est envoyée vers l’URL cible pour obtenir le contenu de la page. Le serveur répond avec le code HTML, que le programme de scraping va ensuite lire. Dans certains cas, il est nécessaire d’ajouter des en-têtes spécifiques (user-agent, cookies, tokens) pour simuler la visite d’un véritable navigateur ;
- L’extraction des données : C’est l’étape clé où le script « lit » le code source, identifie les éléments ciblés (grâce à leur ID, leur classe CSS ou leur position dans le DOM) et les extrait. Des bibliothèques spécialisées permettent de parcourir la structure HTML et de récupérer précisément ce dont on a besoin ;
- La structuration et le stockage : Une fois les données extraites, elles sont nettoyées (on enlève les balises HTML, espaces superflus, caractères spéciaux), puis organisées sous forme de tableau ou d’objets structurés. On peut ensuite les exporter vers des fichiers CSV, JSON, XML ou les insérer directement dans une base de données MySQL, PostgreSQL ou MongoDB, en fonction de l’usage prévu.
Dans certains cas, notamment pour les sites complexes ou à contenu dynamique, une étape supplémentaire s’ajoute :
- Le rendu JavaScript : Si le contenu n’est pas directement visible dans le HTML initial (cas fréquent avec React, Angular ou Vue.js), il est nécessaire d’utiliser un navigateur automatisé pour simuler une session utilisateur. Cela permet de charger complètement la page et d’attendre que les données apparaissent avant de les scraper.
Panorama des outils et langages les plus utilisés pour le web scraping
Le web scraping peut être réalisé avec des outils de programmation classique, mais aussi avec des solutions no-code accessibles aux non-développeurs. Le choix dépend du niveau de précision et de contrôle requis.
| Outil ou langage | Utilisation principale |
|---|---|
| Python | Langage très utilisé grâce à sa simplicité, sa communauté active et ses nombreuses bibliothèques dédiées au scraping. |
| BeautifulSoup | Outil Python pour parcourir et extraire facilement des éléments HTML ou XML. |
| Scrapy | Framework Python très puissant pour construire des scrapers robustes, gérer plusieurs pages, crawler des sites entiers avec pipelines, logs, etc. |
| Selenium | Permet de simuler un vrai navigateur, très utile pour interagir avec des formulaires, cliquer sur des boutons ou scraper des sites JavaScript. |
| Puppeteer | Outil Node.js basé sur Chrome headless, excellent pour rendre du JavaScript et prendre des captures d’écran ou PDF de pages. |
| Octoparse | Outil visuel no-code qui permet de créer des workflows de scraping avec glisser-déposer, accessible aux non-techniciens. |
Les défis techniques du scraping moderne
Alors que scraper des sites statiques (comme des pages HTML simples) est relativement aisé, de nombreux sites modernes rendent le processus plus complexe. Ils utilisent du contenu dynamique chargé via JavaScript, des techniques d’obfuscation, ou encore des mécanismes pour détecter et bloquer les bots. Voici les principaux obstacles rencontrés :
- JavaScript dynamique : Les données n’apparaissent qu’après un certain délai ou une action utilisateur (scroll, clic). Il faut alors utiliser Selenium ou Puppeteer pour simuler ces interactions ;
- Captcha et reCaptcha : Les sites protègent l’accès aux contenus avec des vérifications automatisées pour distinguer les humains des robots ;
- Limitations d’IP : Certains sites bloquent les adresses IP après plusieurs requêtes suspectes. Pour contourner cela, les scrapers utilisent des proxies (adresses IP alternatives) ou des services comme ScraperAPI, Bright Data, ou Smartproxy ;
- Changement de structure HTML : les sites peuvent modifier leur code régulièrement pour empêcher le scraping. Il faut alors adapter les sélecteurs CSS ou XPath du script ;
- Cookies et sessions : certaines pages nécessitent une session utilisateur authentifiée, ou utilisent des cookies spécifiques qu’il faut répliquer dans les requêtes.
Pour surmonter ces obstacles, il existe des techniques avancées :
- Rotation d’user-agents : Simuler différents navigateurs ou appareils pour éviter d’être identifié comme bot.
- Délai entre requêtes : Insérer des temps d’attente aléatoires pour imiter le comportement humain.
- Utilisation d’APIs publiques : Si disponibles, elles offrent souvent une alternative légale, fiable et stable au scraping direct.
Scraping et gestion des données : Au-delà de l’extraction
Une fois les données extraites, elles doivent être nettoyées, filtrées, parfois croisées avec d’autres sources pour être réellement exploitables. Cette phase de traitement des données (ou data cleaning) est essentielle pour produire des tableaux de bord fiables, des visualisations ou des analyses prédictives. Enfin, de nombreux scrapers modernes s’intègrent dans des architectures plus larges, comme :
- Des pipelines de données (ETL : extract, transform, load) avec Apache Airflow ou Talend ;
- Des outils de data visualisation comme Tableau, Power BI ou Google Data Studio ;
- Des moteurs de recherche personnalisés ou des bases documentaires ;
- Des systèmes de veille concurrentielle, de pricing dynamique ou de recommandation produit.
Le fonctionnement du web scraping dépasse ainsi largement la simple extraction : il s’agit d’une véritable chaîne de traitement, allant de l’analyse du besoin jusqu’à l’exploitation stratégique des données. Maîtriser ces techniques, c’est ouvrir la voie à une intelligence de l’information toujours plus fine et réactive.
Exploiter le web scraping pour booster sa stratégie SEO
Si le web scraping est souvent présenté comme un outil technique, son potentiel dans une stratégie de référencement naturel (SEO) est considérable. En permettant de collecter des données clés à grande échelle, le scraping offre aux professionnels du SEO une vision claire de leur environnement concurrentiel, une analyse rapide des performances d’un site, et des insights précieux pour optimiser leurs propres contenus. Loin d’être un simple outil d’automatisation, il devient une source stratégique d’intelligence marketing.
1. L’analyse sémantique et l’optimisation des mots-clés en SEO
Grâce au web scraping, il est possible d’extraire rapidement les titres, sous-titres, balises meta et contenus textuels d’un grand nombre de pages concurrentes. Ces informations permettent :
- D’identifier les mots-clés les plus fréquents utilisés sur un secteur donné ;
- De repérer les expressions longue traîne présentes dans les balises h1/h2 ou dans les paragraphes ;
- D’étudier la densité sémantique sur des pages bien positionnées dans les résultats de recherche (SERP) ;
- De dresser une cartographie des thématiques traitées sur un site concurrent pour ajuster sa propre stratégie de contenus.
Par exemple, un spécialiste SEO peut scraper les résultats de Google sur un mot-clé donné pour analyser les structures de contenu les plus performantes et ainsi bâtir un plan éditorial plus compétitif.
2.L’audit technique SEO de sites concurrents
Le scraping permet aussi de réaliser un audit technique automatisé sur un site tiers : Nombre de pages, balises title dupliquées, erreurs 404, temps de chargement, structure des URLs, balises canonical, etc. En automatisant ce type d’analyse, il devient plus facile de :
- Comparer plusieurs sites à la fois sur leurs performances SEO techniques ;
- Repérer les points faibles ou négligés par des concurrents ;
- Identifier des pratiques inspirantes en matière d’optimisation on-page.
De nombreux outils SEO tels que Screaming Frog, Oncrawl ou Sitebulb utilisent eux-mêmes des techniques de web scraping pour analyser les structures HTML des sites et produire des rapports exploitables.
3. Le suivi de positionnement et de contenu en SEO
En utilisant le scraping de manière ciblée, il est possible de suivre l’évolution des positions d’un mot-clé donné dans les résultats Google, ou d’analyser les changements opérés par un concurrent sur ses pages stratégiques. Cela permet :
- De repérer les mises à jour de contenu ;
- D’anticiper les montées ou baisses de position ;
- De surveiller l’arrivée de nouveaux concurrents sur des requêtes importantes ;
- De collecter régulièrement les snippets affichés dans les SERP (titres, meta-descriptions, URLs, etc.).
Ce type de veille permet de prendre des décisions SEO basées sur des faits mesurables, et non sur des hypothèses. Le scraping devient alors un outil de pilotage décisionnel dans une logique d’amélioration continue.
4. La création de contenus enrichis et pertinents
En SEO, la qualité du contenu est un facteur majeur de classement. Le web scraping peut contribuer à enrichir les pages web avec :
- Des données chiffrées et mises à jour automatiquement (ex. : prix du marché, tendances, statistiques) ;
- Des listes actualisées (top produits, classements, événements à venir) ;
- Des citations ou extraits issus de sources tierces, correctement référencées ;
- Des FAQ ou questions fréquentes inspirées de forums, moteurs de recherche ou plateformes sociales.
Ces contenus dynamiques renforcent la valeur perçue par l’utilisateur et par les moteurs de recherche. Attention cependant à toujours respecter les droits d’auteur et à privilégier l’utilisation de données publiques ou libres d’accès, ou encore issues d’APIs officielles.
5. Détection d’opportunités de backlinks
Enfin, le web scraping peut aider à identifier des opportunités de netlinking, pilier du SEO off-page. Par exemple :
- Repérer les annuaires ou blogs listant des sites similaires au vôtre ;
- Extraire les sites qui mentionnent vos concurrents sans vous citer ;
- Identifier des articles ou contenus dans lesquels vous pourriez proposer une contribution ou un échange de lien ;
- Scraper les profils de liens externes d’un concurrent (à l’aide d’outils spécialisés comme Majestic, Ahrefs ou SEMrush).
Ces données peuvent ensuite alimenter une campagne de prospection ciblée auprès des webmasters ou éditeurs de contenus, pour renforcer la notoriété et l’autorité du site à long terme.
Web scraping et SEO : Un tandem à manier avec discernement
Le web scraping, lorsqu’il est bien utilisé, constitue un véritable levier d’analyse SEO avancée. Il permet d’automatiser la collecte de données, d’économiser un temps précieux, et d’adapter sa stratégie en fonction de données actualisées. Cependant, il est important de respecter l’éthique et les règles juridiques : scraper uniquement des données publiques, ne pas surcharger les serveurs des sites visés, et consulter les conditions d’utilisation (ou préférer les APIs quand elles existent).

0 commentaires