Dans la difficile tâche d’optimisation du référencement d’un site, il est important de connaître sur le bout des doigts chaque composante de ce dernier. Un audit SEO est primordial afin de cibler les éventuels freins à votre évolution dans les moteurs de recherche. Screaming Frog se présente comme l’un des meilleurs outils pour vous accompagner dans cette première étape et en tout cas l’un des plus célèbres auprès des référenceurs.fi
- Screaming Frog SEO, l’outil idéal pour analyser un site
- Crawler son site, extraire toutes les données nécessaires à un audit SEO
- Screaming Frog permet de vérifier les codes de réponses, anticiper les 404 et les redirections 301
- Vérifier les URLs avec Screaming Frog, booster son référencement
- Les filtres titres de pages et meta-descriptions, adapter la sémantique d’un site via Screaming Frog
- Réduire la taille des images, améliorer la vitesse du site avec Screaming Frog
- Activer l’exploration JavaScript pour auditer les sites modernes avec Screaming Frog
- Analyser les données structurées pour améliorer la visibilité dans les SERP
- Auditer les balises hreflang pour un SEO international efficace
- Extraire des données personnalisées avec la fonction Custom Extraction
- Optimiser le maillage interne grâce à l’audit des liens internes
- Comparer deux crawls pour surveiller les changements SEO d’un site avec Screaming Frog
- Connecter Google Search Console et Google Analytics à Screaming Frog pour enrichir l’audit SEO
- Optimiser les canonicals, les meta-robot et générer un sitemap avec Screaming Frog
Screaming Frog SEO, l’outil idéal pour analyser un site
Lancé en 2010 par une agence digitale britannique du même nom, Screaming Frog SEO Spider s’est rapidement imposé comme une référence incontournable dans le monde du référencement technique. Conçu initialement comme un simple crawler local pour Windows, macOS et Linux, il a su évoluer en intégrant des fonctionnalités avancées comme l’audit JavaScript, l’intégration avec Google Analytics ou encore la génération de fichiers sitemap XML. Aujourd’hui, il est utilisé aussi bien par des agences spécialisées que par des services SEO internes de grandes entreprises. Avant de l’utiliser, encore faut-il savoir ce que cette fameuse grenouille hurlante a dans le ventre. L’outil simule le comportement d’un robot d’indexation : il explore les pages de votre site (ou de celui d’un concurrent) pour en extraire une quantité impressionnante de données. URLs, liens internes, images, balises HTML, entêtes HTTP, scripts, fichiers CSS… tout y passe. Et le tout est exportable au format CSV pour une analyse plus poussée dans Excel, Google Sheets ou tout outil de traitement de données. Screaming Frog propose aussi une large gamme de filtres et d’onglets pour segmenter l’analyse, visualiser rapidement les anomalies et prioriser les optimisations. Nous allons voir comment les utiliser intelligemment pour construire un audit SEO solide et pertinent, étape par étape.
Crawler son site, extraire toutes les données nécessaires à un audit SEO
Le crawl est l’étape fondatrice de tout audit SEO technique. Il s’agit d’une simulation du comportement des robots des moteurs de recherche, afin d’explorer et d’analyser l’architecture d’un site web. Une fois Screaming Frog SEO Spider installé en local sur votre machine (Windows, macOS ou Linux), l’opération peut commencer en quelques clics. Il suffit de saisir l’URL du site à analyser dans le champ prévu et de lancer l’exploration. Selon le volume de pages, les redirections internes et les ressources embarquées, le crawl peut durer de quelques secondes à plusieurs dizaines de minutes. Dans sa version gratuite, Screaming Frog limite l’analyse à 500 URLs. C’est suffisant pour un petit site vitrine, mais très vite limitant dès qu’on aborde un site e-commerce, un blog fourni ou tout projet avec une arborescence complexe. Pour aller plus loin, la version payante (licence annuelle abordable) devient indispensable. Elle permet le crawl illimité, mais surtout débloque de nombreuses fonctionnalités professionnelles, comme l’exploration de sous-domaines, les analyses JavaScript, ou encore l’intégration API avec des services comme Google Analytics, Search Console ou PageSpeed Insights.
Grâce à une interface en onglets bien structurée, Screaming Frog affiche une quantité impressionnante d’informations techniques extraites de chaque page : codes de réponse HTTP, titres, meta-descriptions, balises Hn, poids des images, canonicals, directives robots, temps de réponse serveur, profondeur de clic, statut d’indexation, et bien plus. Toutes ces données sont exportables en CSV, facilitant le travail d’analyse dans un tableur ou un logiciel de data visualisation. Cela permet non seulement de repérer les erreurs, mais aussi de détecter des opportunités d’optimisation souvent invisibles à l’œil nu.

Un des atouts majeurs de la version payante est la possibilité de configurer finement le comportement du spider. Par exemple, en activant l’option “Crawl all Subdomains” dans le menu Configuration > Spider, vous pouvez inclure dans votre audit tous les sous-domaines liés à votre domaine principal (comme blog.monsite.fr ou shop.monsite.fr). C’est particulièrement utile pour avoir une vue complète d’un écosystème web réparti sur plusieurs environnements, souvent négligés dans les audits classiques.
Le crawler peut également être personnalisé pour exclure certaines URL, simuler un user-agent spécifique, respecter les règles du fichier robots.txt ou au contraire les ignorer pour forcer l’exploration de pages désindexées. Ces réglages font de Screaming Frog un véritable couteau suisse de l’analyse technique SEO, adapté aux besoins d’un consultant freelance comme à ceux d’un département SEO d’entreprise.
Screaming Frog permet de vérifier les codes de réponses, anticiper les 404 et les redirections 301
Une fois le crawl terminé, l’un des premiers réflexes à adopter est l’analyse des codes de réponse HTTP. Ces statuts, accessibles dans l’onglet “Response Codes” de Screaming Frog, vous informent du comportement serveur pour chaque URL rencontrée : succès, redirection, erreur client ou erreur serveur. Ils sont essentiels pour diagnostiquer la santé technique de votre site et optimiser l’expérience utilisateur comme le budget de crawl alloué par Googlebot.
Voici les principaux codes à surveiller et leur signification :
- 200 : Requête traitée avec succès. La page est accessible et renvoie un contenu valide ;
- 301 : Redirection permanente. Elle transmet le PageRank et doit être utilisée pour les redirections définitives ;
- 302 : Redirection temporaire. Elle ne transmet pas systématiquement l’autorité SEO, et doit être utilisée avec parcimonie ;
- 404 : Page non trouvée. Une ressource a été supprimée ou déplacée sans redirection appropriée ;
- 500 : Erreur serveur. Elle indique souvent un problème PHP ou une surcharge des ressources serveur ;
- 503 : Service temporairement indisponible. Peut être intentionnel (maintenance) ou révélateur d’un incident technique.
Les erreurs 404 sont particulièrement problématiques si elles concernent des pages qui généraient du trafic ou disposaient de backlinks. À force, elles nuisent à l’expérience utilisateur et à la réputation technique du site auprès des moteurs. Grâce à l’export CSV des URLs concernées, vous pouvez facilement élaborer un plan de redirection dans un fichier .htaccess ou via un plugin dédié sous WordPress (comme Redirection). Les redirections 302 méritent une attention particulière. Par défaut, elles ne sont pas prises en compte comme définitives par les moteurs. En phase d’audit, vous devez déterminer si leur présence est justifiée. Si ce n’est pas le cas, il est fortement recommandé de les convertir en 301 afin de préserver le jus SEO et stabiliser la structure du site.
Les erreurs 500 ou 503, quant à elles, sont souvent le signal de problèmes plus profonds : surcharge de serveur, scripts défaillants, ressources trop lourdes ou conflits d’extensions CMS. En audit technique, ces erreurs sont à corréler avec les temps de réponse ou les performances générales du site pour engager des actions correctives côté hébergement ou développement.
Vérifier les URLs avec Screaming Frog, booster son référencement
Une URL bien construite est l’un des piliers techniques du SEO. Elle doit être lisible, concise, contenir des mots-clés pertinents, et refléter l’intention de la page qu’elle représente. Grâce à Screaming Frog, vous pouvez auditer rapidement la structure de vos URLs et détecter les anomalies susceptibles de pénaliser votre visibilité sur les moteurs de recherche. Dans l’onglet “Internal” ou “URL”, vous accédez à la liste complète des permaliens explorés. L’objectif ici est de se concentrer sur les URLs HTML (pages et articles) et d’exclure les ressources techniques comme les fichiers CSS, JS ou PHP qui ne sont pas indexables. En filtrant les données, vous identifierez :
- Les URLs excessivement longues ou générées dynamiquement ;
- Celles qui contiennent des paramètres inutiles ou dupliqués ;
- Les URLs sans mot-clé, ou avec une structure peu descriptive.
Un bon permalink doit être à la fois sémantique (compréhensible par un humain), optimisé pour l’indexation (par Google), et stable dans le temps. Il est recommandé de :
- Limiter la longueur à 3 ou 4 segments maximum ;
- Utiliser des tirets
-pour séparer les mots (et non des underscores) ; - Éviter les accents, caractères spéciaux, majuscules et mots vides comme “et”, “de”, “le”.
En exportant les URLs en CSV, vous pouvez facilement repérer les anomalies de structure. Voici un tableau comparatif d’optimisations typiques :
| URL avant optimisation | URL optimisée |
|---|---|
| http://monsite.fr/avoir-un-bon-referencement-naturel | http://monsite.fr/referencement-naturel |
| http://monsite.fr/page.php?id=324&cat=seo | http://monsite.fr/seo/audit |
| http://monsite.fr/produit-1234-nom-long-et-confus | http://monsite.fr/produits/nom-produit |
| http://monsite.fr/blog/2023/11/article-a-lire-sur-le-seo | http://monsite.fr/blog/seo |
Ce travail de nettoyage est également l’occasion d’améliorer le maillage interne : Une structure d’URLs cohérente et épurée facilite la transmission du “jus SEO” entre les pages et améliore l’indexation par les robots. En couplant cela à une analyse de la profondeur de clic (onglet “Site Structure” dans Screaming Frog), vous pourrez réorganiser votre architecture en limitant les pages trop profondes ou orphelines.
N’oubliez pas de mettre en place des redirections 301 si vous modifiez vos URLs, afin de préserver l’autorité accumulée sur les anciennes adresses et éviter les erreurs 404 qui nuisent au SEO.
Les filtres titres de pages et meta-descriptions, adapter la sémantique d’un site via Screaming Frog
Les balises <title> et meta-description sont les premiers éléments visibles par les internautes dans les pages de résultats (SERP). Ils jouent un double rôle : attirer l’œil pour inciter au clic, et signaler aux moteurs de recherche le sujet de la page. Leur optimisation est donc stratégique pour améliorer à la fois le positionnement et le taux de clic (CTR).
Dans Screaming Frog, l’onglet “Page Titles” permet d’auditer tous les titres présents sur le site, tandis que “Meta Description” répertorie les descriptions. Ces deux filtres vous aident à détecter :
- Les balises manquantes ;
- Les doublons (sur plusieurs pages différentes) ;
- Les titres ou descriptions trop courts ou trop longs ;
- Les balises contenant des caractères non pertinents, des mots vides ou hors sujet.
Un bon titre doit respecter plusieurs critères :
- Faire entre 50 et 65 caractères pour éviter la coupure dans les résultats Google ;
- Inclure le mot-clé principal de la page, de préférence au début ;
- Être unique sur l’ensemble du site ;
- Donner envie de cliquer (approche marketing et informative combinée).
La meta-description, bien que non prise en compte directement dans l’algorithme de classement, influence fortement le CTR. Elle doit :
- Faire entre 150 et 160 caractères ;
- Contenir un ou deux mots-clés secondaires ;
- Être claire, concise et incitative (ajouter un appel à l’action si possible) ;
- Être différente pour chaque page du site.
Voici un tableau récapitulatif des bonnes pratiques :
| Élément | Bonnes pratiques SEO |
|---|---|
| Titre (title) | 50-65 caractères, mot-clé en début, unique, attractif |
| Meta-description | 150-160 caractères, mot-clé secondaire, incitative, unique |
| Doublons | Éviter d’avoir deux pages avec le même titre ou la même description |
| Balises manquantes | Chaque page doit contenir un titre et une description définis |
Grâce à l’option “SERP Snippet Preview” de Screaming Frog (clic droit sur une page > SERP Snippet), vous pouvez prévisualiser directement l’apparence de vos titres et descriptions tels qu’ils seraient affichés dans Google. Cela permet d’ajuster la longueur et le ton en quelques secondes.
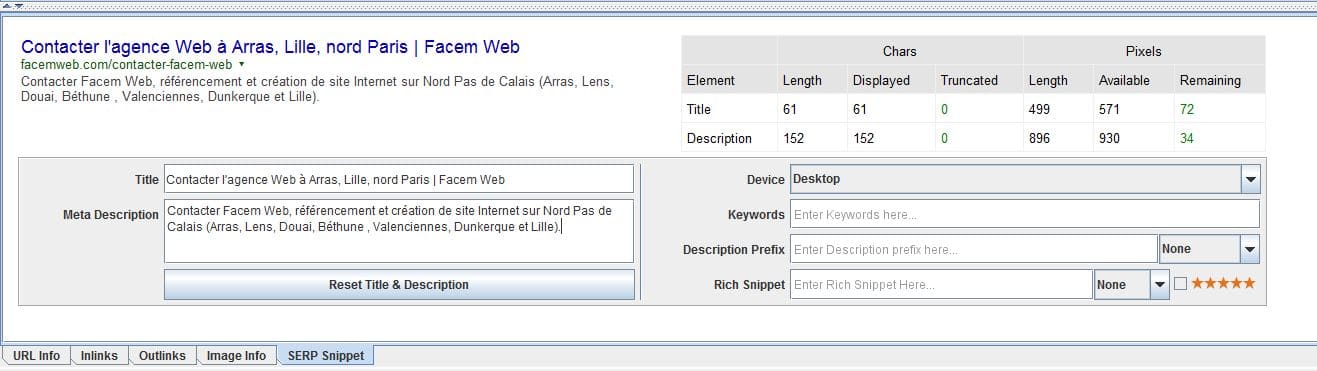
Pour les sites volumineux, l’export CSV des titres et meta-descriptions offre une vue d’ensemble parfaite pour prioriser les optimisations. Il est également possible de faire des modifications en masse depuis une feuille Excel, puis de réintégrer les contenus dans votre CMS ou via un plugin SEO comme Rank Math ou Yoast SEO. La qualité des titres et des meta-descriptions influence autant votre présence dans les résultats de recherche que la façon dont les utilisateurs perçoivent la pertinence de votre site. C’est un levier simple à exploiter, mais trop souvent négligé dans les audits SEO.
Réduire la taille des images, améliorer la vitesse du site avec Screaming Frog
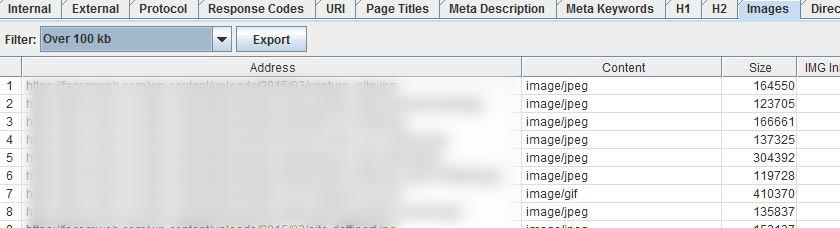
Les images occupent une place essentielle dans le design et la communication web, mais mal optimisées, elles deviennent l’un des premiers freins à la performance. Un site lent génère une mauvaise expérience utilisateur, augmente le taux de rebond, et peut faire chuter le positionnement SEO. C’est pourquoi leur audit est une étape incontournable dans toute stratégie d’optimisation. Dans Screaming Frog, l’onglet “Images” vous offre une vue complète de toutes les ressources image détectées sur le site. Il est alors possible d’identifier rapidement :
- Les images trop lourdes (souvent au-dessus de 100 Ko) ;
- Les images sans attribut
alt(nécessaire pour l’accessibilité et le SEO) ; - Les images en double ou inutilisées.
Le filtre “Over 100kb” est particulièrement utile : il vous permet d’extraire une liste précise des fichiers trop volumineux pour une navigation fluide. Ces ressources peuvent être compressées sans perte de qualité visuelle, en utilisant :
- Des outils en ligne comme TinyPNG, ImageCompressor ou Squoosh.
- Des logiciels comme Photoshop (export en “Save for Web”) ou Affinity Photo.
- Des plugins WordPress comme ShortPixel, Imagify ou Smush qui automatisent la compression au moment du téléversement.
Voici un tableau comparatif des recommandations à suivre pour optimiser vos images :
| Critère | Bonne pratique |
|---|---|
| Poids | Inférieur à 100 Ko pour les images standard ; jusqu’à 300 Ko pour les visuels HD |
| Format | JPEG pour les photos, PNG pour les images avec transparence, WebP ou AVIF pour les performances |
| Attribut alt | Doit être renseigné avec une description sémantique (utile pour le SEO image) |
| Dimensions | Adapter la taille de l’image aux dimensions réelles d’affichage sur le site |
Le gain obtenu grâce à la réduction du poids des images peut être spectaculaire : parfois plus de 50 % de réduction sur le temps de chargement total d’une page. Screaming Frog vous aide à cibler précisément les éléments à corriger, que ce soit sur une page produit, un portfolio, un article de blog ou une bannière promotionnelle.
Ainsi, en auditant le poids des images et en mettant en œuvre des optimisations ciblées, vous améliorez non seulement la vitesse de votre site, mais aussi son référencement naturel et son accessibilité. Une étape simple, mais souvent négligée, qui peut faire la différence dans vos performances globales.
Activer l’exploration JavaScript pour auditer les sites modernes avec Screaming Frog
De nombreux sites web actuels utilisent des frameworks JavaScript comme React, Angular ou Vue.js pour générer dynamiquement le contenu des pages. Cela pose un vrai défi en SEO, car les robots des moteurs de recherche n’interprètent pas toujours correctement les éléments injectés côté client. C’est là qu’intervient la fonctionnalité JavaScript Rendering de Screaming Frog. Grâce à l’intégration du moteur Chromium headless, Screaming Frog peut simuler un rendu complet d’une page, exactement comme le ferait Googlebot dans sa version la plus avancée. L’objectif est de comparer le contenu initial du HTML brut (source serveur) avec le contenu visible après exécution du JavaScript (DOM rendu). Pour activer ce mode, il suffit d’aller dans “Configuration > Spider > Rendering” et de sélectionner “JavaScript” au lieu de “Text Only”. Le crawl sera alors un peu plus lent, mais infiniment plus représentatif pour les sites basés sur du contenu dynamique.
Voici un tableau comparatif entre un crawl standard et un crawl JavaScript :
| Mode d’exploration | Comportement |
|---|---|
| Text Only (HTML brut) | Le crawler lit uniquement le code source envoyé par le serveur – certains contenus générés dynamiquement peuvent être manquants. |
| JavaScript Rendering | Screaming Frog exécute le JS via Chromium, charge les éléments dynamiques et simule le comportement de Googlebot rendu. |
Ce rendu permet de détecter des problèmes critiques que l’on ne voit pas en HTML seul :
- Des liens internes injectés en JavaScript non explorables sans rendu ;
- Des balises SEO (title, h1, meta description) générées dynamiquement, absentes à l’état brut ;
- Du contenu fantôme : visible en front-end, invisible dans le code source initial.
Le rendu JavaScript est donc indispensable pour auditer les Single Page Applications (SPA), les plateformes e-commerce modernes, ou tout site dont le contenu repose sur l’appel de données après chargement initial (AJAX, API REST, GraphQL…). En couplant cette fonctionnalité avec un comparatif DOM brut vs DOM rendu (via l’onglet “Rendered Page”), vous obtenez une analyse fiable et complète, parfaitement alignée avec la façon dont Google indexe les sites web aujourd’hui.
Analyser les données structurées pour améliorer la visibilité dans les SERP
Les données structurées sont des balises intégrées au code HTML d’une page web, utilisées pour décrire son contenu de manière formelle et standardisée. Basées sur le vocabulaire schema.org et souvent implémentées en JSON-LD, elles permettent aux moteurs de recherche comme Google de mieux comprendre le contexte d’une page. Avec Screaming Frog, vous pouvez extraire et auditer automatiquement ces balises via l’onglet “Structured Data”. L’outil identifie les différents types de marquage (Microdata, RDFa, JSON-LD) et les classes associées (FAQ, produit, événement, article, avis, etc.). Il signale aussi les éventuelles erreurs ou alertes selon les directives de la Google Rich Results Test. L’objectif est simple : améliorer votre présence dans les résultats de recherche grâce aux rich snippets, ces extraits enrichis qui attirent l’attention de l’internaute (étoiles d’avis, dates d’événements, recettes, prix, etc.).
Voici un aperçu des types de balisages fréquemment rencontrés :
| Type de données structurées | Fonction et affichage possible |
|---|---|
FAQPage |
Affichage en accordéon dans les résultats – utile pour répondre à des questions courantes |
Product |
Affiche le prix, la disponibilité et les avis sur les fiches produit |
Article |
Utilisé pour les actualités ou blogs – permet d’ajouter l’auteur, la date de publication et l’image |
Review / AggregateRating |
Affichage d’étoiles dans les SERP pour renforcer la preuve sociale |
Event |
Affiche les dates, lieux et prix pour les événements – utile pour les concerts, conférences, etc. |
Dans Screaming Frog, vous pouvez activer l’extraction des données structurées dans “Configuration > Spider > Structured Data”. L’analyse croise ensuite les résultats avec les règles de validation officielles de Google. Les erreurs critiques, comme des champs obligatoires manquants, y sont listées pour une correction rapide. Ce contrôle est essentiel si vous souhaitez que vos pages bénéficient des extraits enrichis. Ces derniers améliorent non seulement votre visibilité dans les résultats de recherche, mais aussi votre taux de clic (CTR), en rendant votre contenu plus engageant et plus crédible. Grâce à son moteur d’extraction puissant, Screaming Frog permet aussi de vérifier la cohérence du marquage entre les pages, d’identifier les types de contenu mal balisés ou oubliés, et de suivre l’évolution des enrichissements après mise à jour ou refonte.
Auditer les balises hreflang pour un SEO international efficace
Sur les sites multilingues ou multi-régionaux, l’utilisation correcte des balises hreflang est essentielle pour que Google comprenne quelles versions linguistiques afficher selon la localisation de l’internaute. Une mauvaise configuration peut entraîner des problèmes d’indexation, de duplication de contenu ou un mauvais ciblage géographique dans les résultats de recherche. Dans Screaming Frog, vous pouvez facilement auditer les balises <link rel="alternate" hreflang="..."> en activant leur détection via “Configuration > Spider > Advanced”. L’outil analyse ensuite leur présence, leur validité syntaxique, et leur cohérence d’un point de vue SEO. Chaque balise hreflang doit indiquer à Google qu’il existe une ou plusieurs variantes de la page, destinées à des langues ou régions spécifiques. Elle doit aussi faire référence à elle-même pour fonctionner correctement (“balise de retour”).
Voici un tableau des éléments à vérifier dans un audit hreflang :
| Élément à contrôler | Recommandation SEO |
|---|---|
| Présence de la balise | Toutes les versions localisées doivent avoir une balise hreflang définie |
| Syntaxe correcte | Utiliser les codes ISO valides (ex. : fr-fr, en-us, es-mx) |
| Référencement croisé (return tag) | Chaque page doit référencer les autres et se référencer elle-même |
| Matching des URLs | Les URLs définies doivent correspondre à des pages réellement accessibles (200 OK) |
| Pas de conflits | Une URL ne doit pas être déclarée plusieurs fois avec des valeurs hreflang différentes non cohérentes |
Une mauvaise configuration du hreflang peut provoquer :
- Une mauvaise page affichée dans un pays cible (ex. : version anglaise au Canada au lieu du français).
- Des problèmes de duplication de contenu si les pages sont trop similaires et mal balisées.
- L’exclusion de certaines pages des résultats Google à l’international.
Grâce à son moteur de crawl avancé, Screaming Frog permet non seulement de détecter l’absence ou les erreurs de balisage hreflang, mais aussi de comparer les chaînes de balises entre plusieurs langues pour garantir leur symétrie. Si vous gérez un site en plusieurs langues ou pays, l’audit hreflang est indispensable pour garantir une stratégie SEO internationale cohérente et efficace. Screaming Frog vous fait gagner un temps précieux dans cette vérification souvent complexe à la main.
Extraire des données personnalisées avec la fonction Custom Extraction
En SEO comme en e-commerce, certains éléments stratégiques ne sont pas visibles via les balises HTML standard analysées par défaut. Pour cela, Screaming Frog propose une fonctionnalité avancée : Custom Extraction. Elle permet d’extraire tout type d’information présente dans le code source, en utilisant des sélecteurs XPath, CSS Path ou expressions régulières (Regex).
Vous pouvez ainsi extraire des contenus personnalisés comme :
- Les prix sur les fiches produit.
- Les balises
og:titleouog:image(Open Graph). - Les identifiants produits (SKU, ID techniques).
- Les dates de publication, catégories, noms d’auteur, ou tout élément HTML ciblé.
Voici un tableau des cas d’usage les plus fréquents :
| Élément extrait | Utilité SEO ou marketing |
|---|---|
| Prix affiché | Contrôle des incohérences entre produits et sitemap ou feed e-commerce |
| Balises Open Graph | Optimisation du partage sur les réseaux sociaux (Facebook, LinkedIn) |
| Texte des boutons CTA | Audit UX/CRO pour vérifier la clarté des appels à l’action |
| Date de publication | Identifier les contenus anciens à mettre à jour |
La custom extraction transforme Screaming Frog en véritable robot de collecte ciblée, utile aussi bien pour le SEO que pour l’analyse concurrentielle ou le suivi de performances commerciales sur site.
Optimiser le maillage interne grâce à l’audit des liens internes
Le maillage interne est l’un des leviers les plus efficaces (et les plus négligés) pour améliorer l’indexation et la transmission de popularité interne (link equity). Screaming Frog propose plusieurs fonctionnalités pour l’analyser en profondeur, en identifiant les pages peu liées, trop profondes ou carrément orphelines.
Depuis l’onglet “Site Structure” ou via l’analyse de la profondeur de clic (crawl depth), vous pouvez :
- Voir la hiérarchie d’accès aux pages ;
- Identifier les pages accessibles à 4, 5 ou 6 clics de la page d’accueil (souvent trop profondes) ;
- Repérer les pages sans aucun lien entrant (orphans), à relier ou désindexer selon leur utilité.
Voici un tableau des problèmes fréquents et leurs effets SEO :
| Problème détecté | Conséquence SEO |
|---|---|
| Page orpheline (aucun lien interne) | Risque de non-indexation car inatteignable par Googlebot |
| Profondeur de clic > 3 | Diminution du “jus SEO” transmis, contenu moins visible |
| Surcharge de liens dans un menu ou un footer | Dilution du PageRank interne, confusion sémantique |
En optimisant le maillage interne, vous améliorez la découvrabilité des pages clés, favorisez l’indexation rapide des nouveaux contenus, et orientez le crawl de Google vers les sections prioritaires de votre site.
Comparer deux crawls pour surveiller les changements SEO d’un site avec Screaming Frog
La fonction crawl comparison ou crawl diff de Screaming Frog est un outil précieux pour tout SEO travaillant sur des migrations, des refontes ou des mises à jour techniques. Elle permet de comparer deux scans du site à des moments différents afin d’identifier rapidement ce qui a changé.
Les différences détectées peuvent concerner :
- Des pages ajoutées, supprimées ou modifiées ;
- Des balises
title,metaoucanonicalchangées ; - Des modifications dans la structure de liens ou dans la hiérarchie des contenus.
Voici les cas d’usage les plus courants :
| Situation | Utilité de la comparaison |
|---|---|
| Avant / après une refonte de site | Détection des erreurs d’URL, redirections manquantes, balises perdues |
| Suivi mensuel d’un site actif | Monitoring des évolutions SEO techniques non documentées |
| Audit d’un site client par une agence | Justification des améliorations ou régressions dans le temps |
La fonction de comparaison de crawls est accessible via “File > Compare Crawls” et nécessite que les deux exports aient été sauvegardés en format natif .seospider. Elle permet une analyse précise, fichier par fichier, pour prendre des décisions rapidement.
Connecter Google Search Console et Google Analytics à Screaming Frog pour enrichir l’audit SEO
Au-delà de l’analyse purement technique, Screaming Frog permet — dans sa version payante — de connecter directement vos comptes Google Search Console (GSC) et Google Analytics (GA) via leurs APIs respectives. Cette intégration est extrêmement précieuse car elle permet de croiser les performances réelles des pages avec les résultats du crawl technique.
Concrètement, cela signifie que vous pouvez, en un seul tableau, visualiser :
- Les pages indexables qui génèrent du trafic… ou non ;
- Les pages avec un bon maillage mais peu de clics ou d’impressions ;
- Les URLs à fort taux de rebond pouvant cacher un problème de contenu ou de structure technique.
Voici un tableau récapitulatif des données croisées les plus utiles :
| Donnée importée | Analyse possible avec Screaming Frog |
|---|---|
| Clics / impressions (GSC) | Identifier les pages bien optimisées mais peu visibles ou peu cliquées |
| CTR (taux de clics) | Comparer avec le contenu des titres et meta-descriptions (corrélation texte / performance) |
| Taux de rebond (GA) | Détecter les pages techniques valides mais peu engageantes |
| Temps moyen passé sur la page | Identifier les contenus à faible engagement malgré un bon référencement |
Pour configurer la connexion, rendez-vous dans “Configuration > API Access” puis sélectionnez Google Search Console ou Google Analytics. Il vous suffit ensuite d’autoriser Screaming Frog à accéder à vos données via votre compte Google, et de sélectionner le site à analyser. Une fois la synchronisation effectuée, les données issues de GSC et GA sont associées aux URLs du crawl. Cela vous permet d’exporter un fichier unique contenant à la fois :
- Les performances SEO (trafic, CTR, position moyenne) ;
- Les indicateurs UX (rebond, durée de session) ;
- Les données techniques (status code, balises, profondeur, etc.).
Cette vue croisée est particulièrement utile pour prioriser vos actions SEO : inutile d’optimiser techniquement une page qui ne génère aucun trafic ou que Google ignore. À l’inverse, une page stratégique mal balisée ou trop lente pourra être rapidement repérée grâce à ce croisement de données.
En bref, la connexion aux APIs Google transforme Screaming Frog en un outil d’audit SEO complet, combinant la donnée de crawl et la donnée utilisateur dans une même interface.
Optimiser les canonicals, les meta-robot et générer un sitemap avec Screaming Frog
Une fois les fondations techniques d’un site auditées (performances, structure, contenu), il est indispensable de s’attarder sur les signaux que vous envoyez aux moteurs de recherche. Ces signaux sont notamment transmis via les balises canonical et les directives meta-robots, deux éléments que vous pouvez analyser finement dans l’onglet “Directives” de Screaming Frog.
La balise <link rel="canonical"> est utilisée pour indiquer à Google et aux autres moteurs quelle version d’une page doit être considérée comme la source principale. C’est un outil puissant pour éviter les problèmes de contenu dupliqué, en précisant l’URL de référence même si d’autres versions de la page existent (avec paramètres, pagination, session ID, etc.).
Voici ce qu’il faut surveiller :
- Absence de canonical sur certaines pages : elle doit être définie pour chaque page importante ;
- Canonicals contradictoires : une page qui pointe vers une autre page non pertinente ou obsolète ;
- Canonicals auto-référencés : c’est la bonne pratique par défaut, chaque page renvoyant vers elle-même, sauf cas spécifiques.
De la même manière, la balise <meta name="robots"> permet d’indiquer aux crawlers si une page doit être indexée (index) ou non (noindex), et si ses liens doivent être suivis (follow) ou ignorés (nofollow).
Les incohérences les plus courantes à repérer sont :
- Pages stratégiques en
noindexpar erreur. - Pages internes importantes en
nofollow, empêchant le passage du “jus SEO”. - Utilisation excessive de
noindex, nofollowsur des pages qui mériteraient d’être indexées (ex. : articles, pages produits, etc.).
Voici un tableau pour clarifier les usages :
| Directive | Signification et usage recommandé |
|---|---|
index, follow |
Indexation autorisée, liens suivis – configuration standard pour les pages à référencer |
noindex, follow |
Contenu exclu de l’index, mais liens explorés – utilisé pour des pages d’archives ou de recherche interne |
noindex, nofollow |
Page invisible pour Google et liens ignorés – à réserver à des pages techniques ou temporaires |
canonical vers URL externe |
Indique que le contenu original est sur un autre site – attention aux erreurs stratégiques |
Enfin, Screaming Frog vous permet de générer un sitemap XML complet et conforme aux exigences des moteurs. Cette option se trouve dans le menu “Sitemaps > XML Sitemap…” et vous permet de sélectionner :
- Les types de contenus à inclure (pages, images, vidéos, etc.) ;
- Les URLs filtrées selon leur statut (uniquement les 200, par exemple) ;
- La fréquence de mise à jour (
changefreq) et la priorité (priority).
Une fois généré, le fichier sitemap.xml peut être directement téléversé à la racine de votre site ou soumis à la Google Search Console. Il joue un rôle essentiel pour guider le crawl, notamment sur les sites volumineux ou récemment restructurés. Screaming Frog (que vous pouvez télécharger ici) ne remplace pas les outils d’analyse sémantique ou les stratégies de contenu, mais il vous offre une base technique solide pour prendre des décisions éclairées. En travaillant avec des canonicals bien positionnés, des directives robot maîtrisées et un sitemap bien structuré, vous posez les fondations d’un site propre, lisible et performant pour les moteurs comme pour les utilisateurs.

0 commentaires