Lorsque l’on développe un site Web, on est très tenté de mettre beaucoup de contenu et notamment du contenu texte car « si je veux être référencé, il faut que mon site dispose de contenu ». Et vous avez raison car à quoi sert-il d’avoir un site Web si c’est pour ne pas apparaître dans les moteurs de recherche ? Alors OUI, c’est la règle du contenu qui est tant développée un peu partout par les référenceurs de site ; Cependant, il existe un risque de duplication de contenu. Les balises « canonical » sont un remède que nous allons détailler.
Éviter la duplication de contenu avec la balise rel=canonical
Lorsque l’on développe un site web, on est naturellement tenté d’y intégrer beaucoup de contenu texte. Et pour cause : le contenu reste un levier fondamental du référencement naturel. La célèbre phrase « Content is king », formulée par Bill Gates en 1996, souligne déjà l’importance stratégique du texte dans l’écosystème numérique.
Mais si le contenu est roi, la structure et l’unicité sont ses gardes du corps. En effet, trop de contenu dupliqué nuit à la performance SEO. Et c’est précisément pour cette raison que la balise rel=canonical, introduite officiellement par Google en février 2009 (en partenariat avec Bing et Yahoo), a été conçue. Elle constitue une réponse technique simple à un problème complexe : le duplicate content.
La duplication de contenu, c’est quoi ?
La duplication de contenu désigne l’existence de contenus strictement identiques ou très proches accessibles via différentes URL. Google la distingue en deux catégories principales :
- Interne : duplication au sein d’un même site (par exemple : un même produit e-commerce apparaissant sous plusieurs filtres ou catégories, ou plusieurs versions d’une même page accessible via différentes requêtes GET).
- Externe : duplication entre plusieurs sites, parfois due à du syndication de contenu, du scraping, ou des pratiques de republication automatisées via des flux RSS.
Dans un environnement technique comme celui de sites e-commerce, ce phénomène est courant : filtres, tris dynamiques, recherches internes, paramètres de sessions, déclinaisons produits (taille, couleur, etc.), tout cela génère des dizaines de variations d’URL pointant vers un même contenu. Par exemple :
https://monsite.com/chaussures?tri=prix-croissant
https://monsite.com/chaussures?couleur=noir
https://monsite.com/chaussuresPour un moteur de recherche, chacune de ces URL représente une page à crawler, à indexer, à analyser. Mais si le contenu est identique ou presque, cela dilue l’autorité, surcharge le budget de crawl et introduit de l’ambiguïté sur la version « principale » à afficher dans les SERP.
Filtres Google et duplication : Panda, Core Update & co
Depuis 2011, Google applique un filtre algorithmique très connu pour lutter contre les contenus dupliqués ou pauvres : Google Panda. Déployé initialement en février 2011, ce filtre a impacté jusqu’à 12 % des requêtes anglophones lors de son lancement. L’objectif ? Récompenser les sites à forte valeur ajoutée et pénaliser ceux contenant des contenus redondants, creux ou dupliqués.
Depuis sa fusion dans le cœur de l’algorithme de Google (en 2016), Panda n’est plus un filtre périodique, mais un signal d’évaluation en temps réel. Cela signifie que la présence de duplication peut impacter en continu le classement d’un site, notamment sur les longues traînes et pages profondes.
En plus de Panda, les Core Updates de Google (déployées plusieurs fois par an depuis 2018) prennent également en compte des critères de qualité globale du site, dont la gestion du duplicate content fait partie. Ignorer la structuration canonique d’un site, c’est donc risquer des fluctuations brutales de position.
Les formes modernes de duplication
- Problèmes de versions d’URL (avec ou sans slash final, HTTP vs HTTPS, www vs non-www) ;
- Pagination (pages 2, 3, 4 affichant des blocs de contenu similaires) ;
- Paramètres d’URL dynamiques sans gestion côté serveur ou balisage adéquat ;
- Catégories, tags, archives date/heure dans WordPress ;
- Contenus repris partiellement sur d’autres domaines (syndication partielle ou complète).
Une conséquence indirecte de cette duplication est la division de l’autorité sémantique d’une page : au lieu d’avoir un signal fort pour une URL unique, on obtient plusieurs signaux faibles dispersés. C’est inefficace.
Conséquence technique : gaspillage du crawl budget
Chaque site dispose d’un budget de crawl alloué par Googlebot. Ce budget correspond à la fréquence et au volume de pages que le robot est prêt à explorer sur une période donnée. Plus vous avez de pages dupliquées, inutiles ou peu qualitatives, plus vous consommez inutilement ce budget — au détriment de vos pages stratégiques.
C’est là que la balise rel=canonical prend tout son sens : elle permet de centraliser le signal SEO sur une seule URL officielle, de guider Google dans son exploration et d’éviter des erreurs de classement ou de désindexation involontaire.
En SEO moderne, bien baliser, c’est savoir déléguer au robot la bonne interprétation du contenu, sans ambiguïté.
Utiliser la balise rel=canonical
La balise rel=canonical est un élément HTML inséré dans la section <head> d’une page web. Elle permet d’indiquer à Google et aux autres moteurs de recherche quelle URL est la version originale ou principale d’un contenu dupliqué ou similaire. Son objectif est d’éviter la dilution du signal SEO causée par des URLs concurrentes pointant vers un contenu identique ou quasi identique.
Voici un exemple classique de syntaxe :
<link rel="canonical" href="https://www.mondomaine.com/page-principale/" />Fonctionnement technique
Lorsqu’un moteur de recherche détecte plusieurs URL avec des contenus équivalents, il tente de choisir lui-même une URL canonique. La balise rel=canonical a pour but de lui fournir une recommandation explicite. Cela permet de :
- centraliser les signaux d’autorité (liens entrants, partage social, engagement) sur une seule URL ;
- éviter que plusieurs versions d’une page ne se concurrencent dans l’index ;
- optimiser le budget de crawl du site ;
- stabiliser le positionnement SEO d’un contenu unique.
Règles fondamentales à suivre
- Utiliser une URL absolue dans l’attribut
href, incluant le protocole (http/https) et le nom de domaine complet. - Insérer la balise le plus tôt possible dans le fichier HTML, idéalement avant la balise
<title>. - Ne jamais insérer plusieurs balises
rel=canonicaldans une même page. Cela crée une contradiction et invalide le signal. - Ne pas ajouter cette balise sur les pages comportant une directive
noindexdans la balise<meta name="robots">: le message envoyé au moteur serait incohérent. - Éviter d’utiliser rel=canonical dans les systèmes de pagination (pages 2, 3, etc.). Il est préférable ici d’utiliser les balises
rel="prev"etrel="next"ou, dans certains cas, une stratégie basée surnoindex, follow.
Cas pratiques fréquents
Voici quelques cas où l’usage de rel=canonical est indispensable :
- Filtres produits sur un site e-commerce : lorsqu’un produit est accessible via plusieurs chemins d’URL (
/chaussures?couleur=noirvs/chaussures?taille=43) ; - Contenus partagés sur plusieurs catégories : les articles de blog assignés à plusieurs taxonomies peuvent générer des chemins redondants.
- Paramètres d’URL (campagnes UTM, tri, pagination de recherche interne) ;
- Articles traduits ou syndiqués publiés sur d’autres domaines : il est important de conserver la paternité du contenu original via une balise canonique renvoyant vers l’URL source.
Cas particulier : les sites multilingues
Lorsque vous développez un site en plusieurs langues, il est essentiel de coupler rel=canonical avec les balises hreflang. Voici un exemple de combinaison typique :
<link rel="canonical" href="https://example.com/fr/produit/" />
<link rel="alternate" href="https://example.com/fr/produit/" hreflang="fr" />
<link rel="alternate" href="https://example.com/en/product/" hreflang="en" />
<link rel="alternate" href="https://example.com/de/produkt/" hreflang="de" />Important : chaque page traduite doit avoir son propre canonical pointant vers elle-même, et les balises hreflang doivent s’auto-référencer et se croiser avec les autres versions.
Impact sur l’indexation et les filtres de Google
La balise canonical n’est pas une directive stricte (comme noindex) mais une suggestion forte. Google se réserve le droit de ne pas la suivre s’il estime qu’elle est mal utilisée, notamment lorsque :
- l’URL canonique est une erreur 404 ou renvoie un code HTTP autre que 200 ;
- le contenu de la page canonique est radicalement différent du contenu de la page qui l’indique ;
- la canonical pointe vers une page
noindex; - elle entre en contradiction avec une redirection serveur (ex. redirection 301 d’une URL A vers B mais canonical sur A vers A).
Audit SEO et canonicalisation
Pour vérifier la bonne implémentation des balises rel=canonical :
- Utilisez la Google Search Console, section « Inspection de l’URL » pour voir quelle page Google considère comme canonique.
- Testez vos pages avec des outils comme Screaming Frog (onglet Canonical) ou Sitebulb.
- Assurez-vous qu’une canonical n’est jamais autoréférencée en cas de contenu très différent (par exemple, une page avec une forte personnalisation dynamique).
Canonical et CMS comme WordPress
Sur WordPress, la plupart des thèmes et des plugins SEO (notamment Yoast SEO ou Rank Math) gèrent automatiquement la génération de balises rel=canonical correctes. Il est néanmoins recommandé de :
- contrôler les pages paginées, les catégories, les archives date et auteur ;
- désactiver les URL inutiles via
noindexou exclusions dans le sitemap.xml ; - paramétrer manuellement une URL canonique si la version générée automatiquement est incorrecte (possible via l’onglet avancé de l’éditeur Yoast).
Enfin, gardez à l’esprit que la balise canonical n’est pas une redirection : elle ne redirige pas l’utilisateur, seulement les moteurs. Pour une action immédiate sur l’URL à charger, utilisez une redirection HTTP 301.
Bonus : n’oubliez pas de désigner une URL canonique dans les flux RSS, notamment pour limiter les cas de scraping automatisé de contenu.
Utiliser rel=canonical avec WordPress
Si vous utilisez le CMS WordPress, sachez que celui-ci ne propose pas de gestion native avancée de la balise rel=canonical. C’est pourquoi il est recommandé d’installer une extension spécialisée en SEO. Le plugin Yoast SEO figure parmi les plus populaires et les plus fiables pour cette tâche. Il permet d’automatiser l’injection de la balise rel=canonical dans la section <head> de vos pages et de la personnaliser selon vos besoins.
Gestion manuelle via l’onglet Avancé
Lorsque vous rédigez ou modifiez une page ou un article avec Yoast SEO activé, vous disposez d’un onglet Avancé dans l’interface de l’éditeur. Dans cette section, un champ dédié vous permet de spécifier manuellement l’URL canonique souhaitée :
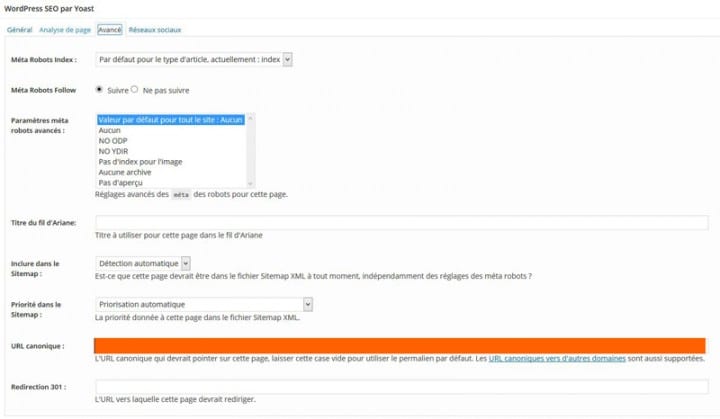
Si ce champ est laissé vide, Yoast générera automatiquement une balise canonique basée sur l’URL actuelle de la page. Cette configuration par défaut convient dans la majorité des cas, sauf dans les situations où :
- plusieurs pages ont un contenu très similaire (ex. : versions A/B ou landing pages proches) ;
- vous réutilisez du contenu déjà publié ailleurs (y compris sur un autre domaine) ;
- vous voulez centraliser plusieurs sources vers une URL unique de référence (canonisation vers une version consolidée).
Où et comment Yoast insère la balise ?
Une fois renseignée, la balise rel=canonical est injectée dans le code HTML, dans la section <head>, juste après la balise <title> et avant les autres balises meta. Voici à quoi cela ressemble dans le code source :
<link rel="canonical" href="https://www.mondomaine.com/ma-page-principale/" />Cette approche respecte les recommandations de Google en matière d’ordre de lecture du DOM (Document Object Model), ce qui permet une prise en compte plus rapide et plus fiable lors du passage du Googlebot.
Cas particuliers à traiter dans WordPress
Outre les articles et pages classiques, WordPress génère plusieurs types de pages automatiquement, souvent problématiques en matière de contenu dupliqué :
- Archives par auteur : peuvent générer du contenu redondant si l’auteur publie souvent les mêmes types de contenus ;
- Archives par date : risquent de dupliquer les articles par mois ou année ;
- Archives par mot-clé ou étiquette : provoquent souvent des répétitions inutiles si mal gérées ;
- Pages paginées : nécessitent une gestion spécifique (souvent
noindex, followau lieu de canonical) ; - Résultats de recherche internes : peuvent produire de nombreuses URLs vides de sens pour Google.
Yoast SEO propose, dans l’onglet Apparence dans les résultats de recherche, de désactiver l’indexation de ces pages problématiques ou de les gérer via des directives automatiques, sans balise canonical inutile.
Utilisation avancée avec WooCommerce
Si vous utilisez WooCommerce, la gestion des URL produit peut devenir très vite problématique : un même produit peut apparaître dans plusieurs catégories, générant plusieurs URLs uniques pour un seul contenu. Cela entraîne une dilution du PageRank et du signal d’autorité. Yoast SEO, dans sa version premium ou couplé à l’extension Yoast WooCommerce SEO, gère correctement la canonicalisation :
- il crée une canonical sur l’URL principale du produit, indépendamment du chemin catégoriel ;
- il vous permet de forcer une URL canonique si nécessaire ;
- il est compatible avec les variantes de produits configurées via des attributs (taille, couleur, etc.).
Autres plugins compatibles
Yoast n’est pas la seule option. D’autres plugins populaires permettent une gestion manuelle ou automatisée des balises rel=canonical :
- Rank Math : plus granulaire, avec des options pour chaque type de contenu personnalisé (CPT) et des règles automatiques pour le multilingue ;
- SEOPress : une alternative légère à Yoast, qui permet aussi d’éditer les canonicals page par page ;
- All in One SEO : historiquement concurrent direct de Yoast, avec une interface plus orientée novice mais aussi des fonctions avancées de canonicalisation.
Bonnes pratiques spécifiques à WordPress
Voici quelques conseils techniques supplémentaires pour garantir une bonne gestion des balises canonicals sur un site WordPress :
- Évitez les plugins qui génèrent des URLs paramétrées dynamiquement (ex. : plugins de tri ou de filtre non-SEO friendly) sans intégrer une stratégie de canonicalisation claire ;
- Déclarez votre version canonique de domaine (avec ou sans www) dans la Search Console, pour guider Google ;
- Vérifiez les balises canonical sur les pages AMP, qui doivent pointer vers la version desktop HTML canonique ;
- Sur un site multilingue, utilisez à la fois
rel=canonicalethreflangpour éviter l’indexation croisée des versions traduites.
Important : la canonicalisation ne remplace pas les redirections. Si vous supprimez une page ou changez son URL, utilisez une redirection 301 en plus de la balise
rel=canonicalpour maintenir le signal SEO.
Cas pratiques et protection contre le scraping
La balise rel=canonical ne se limite pas à la gestion des pages similaires ou aux doublons techniques issus de votre propre site. Elle constitue aussi une mesure défensive stratégique contre le contenu dupliqué externe, notamment en cas de scraping (aspiration de contenu).
Définition du scraping
Le scraping est une technique automatisée qui consiste à extraire du contenu d’un site web à l’aide de scripts ou de bots, souvent sans autorisation. Cela peut se faire par analyse HTML directe, via des flux RSS ou via des API non sécurisées. Les objectifs varient : alimenter un réseau de sites satellites, dupliqués, ou gonfler artificiellement des plateformes de type MFA (Made For Ads).
Dans la majorité des cas, les sites voleurs recopient le contenu à l’identique, sans en modifier les structures HTML, balises ou paragraphes. Cette pratique entraîne un risque SEO réel : si le site copieur est indexé avant vous, ou possède une meilleure autorité, Google peut confondre la source originale et la copie. Cela a été observé à plusieurs reprises, notamment avant 2011, date de lancement du filtre Panda (première version en février 2011).
Comment la balise rel=canonical agit-elle dans ce contexte ?
Insérée dans le <head> de vos pages, la balise rel=canonical spécifie l’URL que les moteurs doivent considérer comme la version de référence. Si un scraper reprend votre contenu tel quel (y compris le <head>), il importera aussi cette balise. Résultat : Google interprétera que la page copiée renvoie vers votre version comme source principale, et attribuera la valeur SEO (link equity) à votre page d’origine.
Scénario : site scrappé via RSS
Imaginez un site WordPress alimenté par un flux RSS. Un autre site utilise un agrégateur pour republier tous vos articles. S’il ne supprime pas la balise rel=canonical (ce qui est souvent le cas), alors :
- Votre page conserve la priorité dans l’indexation (grâce au signal canonique) ;
- Le contenu dupliqué est dévalorisé par Google (filtré ou ignoré) ;
- Votre page ne perd pas son autorité — voire en récupère si un lien de la copie pointe vers vous.
Compléments de protection : lien profond et ancre désoptimisée
Outre la balise canonical, il est recommandé d’inclure systématiquement dans vos contenus un ou plusieurs liens internes profonds (vers d’autres pages de votre propre site), avec une ancre désoptimisée (du type « Lire la suite », « En savoir plus », « Découvrez ici »…).
Pourquoi ? Parce que ces liens seront repris par les scrapeurs s’ils copient votre HTML. Résultat : Google verra que le contenu dupliqué pointe vers l’original, renforçant ainsi la légitimité de votre version. Cela contribue indirectement à la consolidation de votre autorité (par redistribution du link equity).
Cas réels et filtrage algorithmique
Depuis le lancement de Panda dont on a déjà parlé et de ses nombreuses itérations, Google a renforcé sa capacité à détecter les contenus dupliqués à grande échelle. Il applique ce que l’on appelle un filtrage algorithmique (par opposition à une pénalité manuelle) :
- les contenus identiques sont comparés et classés en fonction de leur originalité, ancienneté et contexte d’apparition ;
- seule la version « canonique » jugée la plus fiable est conservée dans l’index principal (les autres versions sont parfois indexées dans l’index secondaire, avec très peu de visibilité) ;
- en cas de doute, Google peut aussi tester les liens internes, les mentions externes, ou les signaux comportementaux (CTR, taux de rebond).
⚠️ Attention : si vous ne maîtrisez pas l’implémentation de la balise canonical, vous pouvez involontairement désigner une page non pertinente comme source principale, ce qui peut entraîner une désindexation temporaire ou un déclassement SEO.
La balise rel=canonical n’est pas une assurance tous risques, mais c’est une excellente police d’assurance contre le contenu dupliqué, à condition d’être correctement intégrée et vérifiée.
Enfin, n’oubliez pas de coupler l’usage de cette balise avec :
- des redirections 301 bien structurées en cas de suppression ou de déplacement de contenu ;
- un suivi via la Search Console pour vérifier l’indexation des bonnes URLs ;
- des outils anti-plagiat (comme Copyscape ou Siteliner) pour surveiller les copies non autorisées de vos contenus.
Conclusion sur l’usage stratégique du rel=canonical
Correctement utilisé, le rel=canonical permet donc beaucoup de choses dont les faits :
- d’éviter les effets négatifs du duplicate content ;
- de consolider le référencement autour d’une seule URL principale ;
- de guider les moteurs dans des environnements complexes (filtres, catégories, tags, paramètres d’URL) ;
- de sécuriser vos contenus contre les risques de scraping et de syndication abusive.
Couplé à une bonne architecture d’information, à des redirections 301 propres et à une stratégie de maillage interne cohérente, il devient un outil puissant de contrôle SEO.

Coup de chapeau pour l’article.
Coup de chapeau oui 🙂