Lorsque l’on parle de visibilité sur les moteurs de recherche, on pense souvent au contenu, aux mots-clés, voire au netlinking. Mais derrière ces éléments bien visibles se cache une autre dimension, souvent méconnue, mais pourtant essentielle : Le SEO technique. C’est lui qui garantit que le site est bien exploré, indexé et interprété par les moteurs comme Google. Sans une base technique solide, même le meilleur contenu peut rester invisible. Dans cet article, voyons ensemble ce qu’est réellement le SEO technique, pourquoi il est indispensable pour le bon positionnement d’un site web, et passer en revue quelques exemples concrets d’optimisations techniques que tout site devrait envisager dans l’optique de la performance. Il s’agit ici d’un complément détaillé d’une définition du référencement naturel pour commencer.
- La définition du SEO technique et son rôle dans le référencement naturel
- Les principaux éléments à optimiser en SEO technique
- Exemples concrets d’optimisations techniques SEO techniques
- L’optimisation technique SEO sur le serveur pour commencer
- La reconstruction d’une arborescence sémantique
- Le nettoyage massif de contenu zombie d’un site Web
- La réduction du gaspillage du budget crawl via un audit de logs
- La réécriture et simplification des URLs pour améliorer l’analyse sémantique
- L’optimisation de la structure Hn et du balisage HTML
- La migration technique d’un CMS non-SEO-friendly vers un CMS performant
- L’implémentation des balises hreflang sur un site multilingue
- L’optimisation du sitemap pour un site à fort volume de pages
- La suppression des chaînes de redirection inutiles en SEO technique
- L’intégration avancée de données structurées dans le SEO technique
- La détection de pages orphelines et l’intégration dans le maillage interne
- La suppression des paramètres d’URL inutiles dans la Search Console
- Création d’une page 404 optimisée avec rebond interne
- L’élimination des liens internes en nofollow
- L’amélioration du code HTML et la suppression du JavaScript bloquant
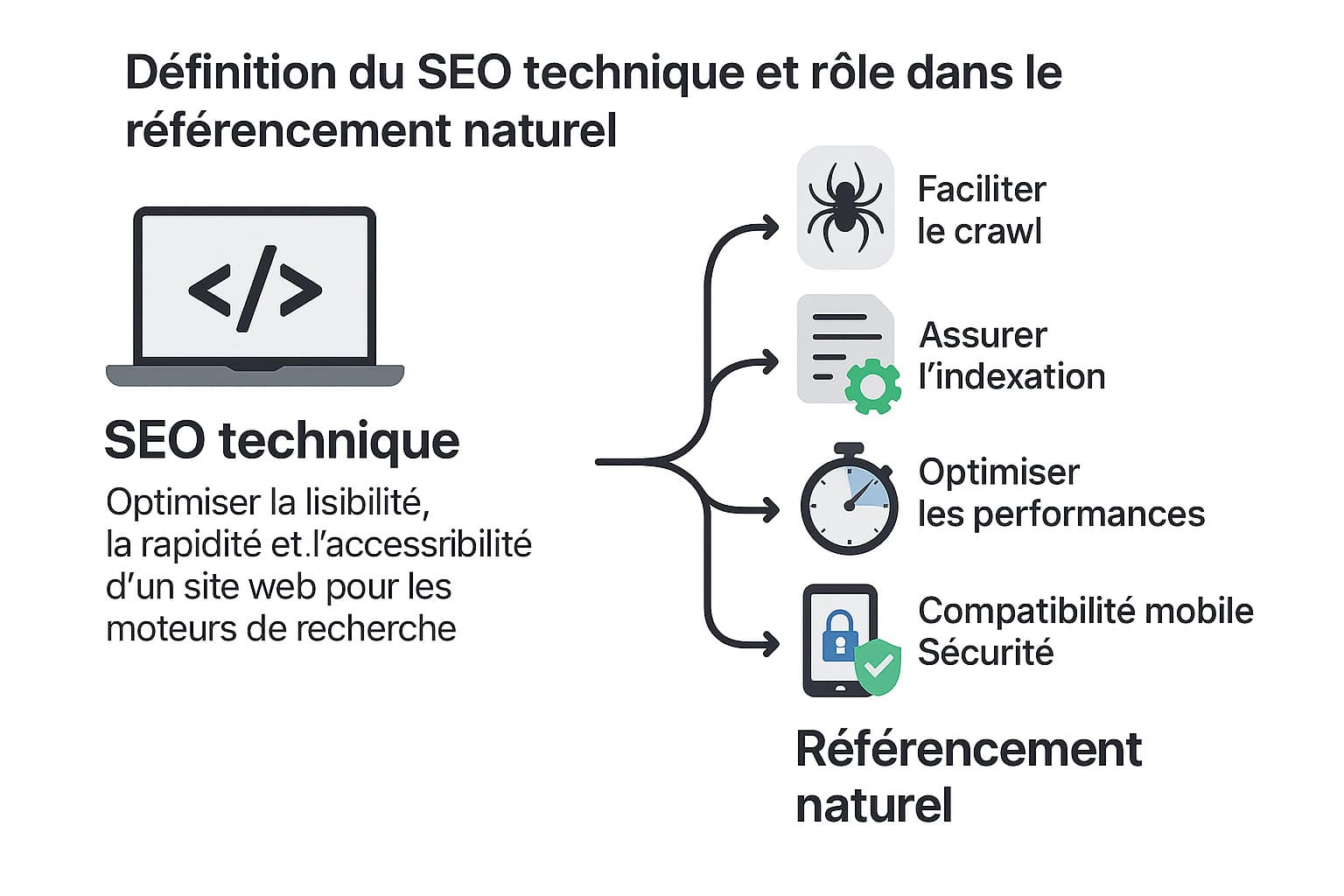
La définition du SEO technique et son rôle dans le référencement naturel
Le SEO technique correspond à l’ensemble des optimisations qui visent à améliorer la lisibilité, la rapidité et l’accessibilité d’un site web pour les moteurs de recherche. Contrairement au SEO on-page, qui se concentre sur la qualité du contenu et l’usage des mots-clés, ou au SEO off-page, qui englobe les liens externes et la notoriété, le SEO technique agit en profondeur sur les fondations invisibles du site. Il prend en compte des paramètres comme la structure HTML, l’arborescence des pages, les en-têtes HTTP, la configuration du serveur, la gestion des redirections, ou encore l’optimisation des fichiers statiques. L’objectif principal du SEO technique est de permettre aux robots d’exploration (comme Googlebot, Bingbot ou même encore YandexBot) de parcourir et de comprendre un site web avec un minimum de frictions. Ces robots utilisent des algorithmes pour détecter et analyser les pages pertinentes à indexer. Si certaines de ces pages sont difficiles d’accès, mal codées, lentes à charger ou sujettes à des erreurs techniques (codes HTTP erronés, duplication de contenu, etc.), elles peuvent être ignorées ou mal positionnées dans les résultats de recherche.
Le SEO technique ne se limite donc pas à « rendre le site propre ». Il s’agit d’un travail d’optimisation de bas niveau, où chaque décision technique peut impacter la visibilité globale du site sur les moteurs de recherche. Voici quelques axes structurants autour desquels s’articule une stratégie de SEO technique efficace :
- Faciliter le crawl des robots : Cela implique une gestion rigoureuse des fichiers
robots.txtpour indiquer clairement aux moteurs de recherche quelles sections du site peuvent ou non être explorées. La mise en place de balisesmeta robotspermet de spécifier au cas par cas les comportements d’indexation (index, noindex, follow, nofollow). Un maillage interne bien pensé, avec des liens contextuels pertinents et logiques, aide également les robots à naviguer efficacement d’une page à l’autre tout en redistribuant la popularité des pages importantes. De plus, l’optimisation de l’arborescence repose en grande partie sur une structure d’URLs propre et lisible. Le recours au rewriting d’URLs permet de créer des chemins clairs, hiérarchiques et compréhensibles tant pour les utilisateurs que pour les moteurs, par exemple :/categorie/produit-nomplutôt que/index.php?id=123. Cette structure facilite l’exploration et favorise le bon classement des contenus dans les résultats de recherche. - Assurer une indexation correcte : L’objectif ici est d’éviter que les moteurs de recherche indexent des pages inutiles, redondantes ou à faible valeur ajoutée, ce qui pourrait diluer la pertinence globale du site. Cela passe par l’utilisation appropriée de balises
noindexsur des pages comme les filtres de tri, les formulaires, ou les résultats de recherche internes. L’ajout de balisescanonicalest essentiel pour gérer les contenus dupliqués involontaires, en précisant à Google quelle version d’une page doit être considérée comme la source principale. En complément, un fichier sitemap XML bien structuré et mis à jour automatiquement permet de fournir aux moteurs une carte exhaustive des pages à indexer, en tenant compte des priorités et de la fréquence de mise à jour. Pour les sites e-commerce ou éditoriaux à forte volumétrie, cette gestion fine de l’indexation permet d’éviter une surcharge de l’index avec des pages peu stratégiques, et oriente l’autorité du site vers les pages les plus importantes. - Optimiser les performances techniques : Le temps de chargement est un levier central du SEO technique, directement lié à l’expérience utilisateur et désormais intégré aux critères d’évaluation de Google via les Core Web Vitals. Pour optimiser les performances, plusieurs techniques peuvent être combinées : compression des fichiers statiques (HTML, CSS, JS) via GZIP ou Brotli, réduction du nombre de requêtes HTTP, chargement différé des images (
lazy loading), minification des ressources, et limitation des scripts tiers. La mise en cache serveur, qu’elle soit côté navigateur ou via un proxy (Varnish, Redis, etc.), permet de réduire drastiquement le temps d’affichage des pages. L’amélioration du TTFB (Time To First Byte) dépend quant à elle du choix d’un hébergement performant et d’une configuration serveur optimisée (PHP, base de données, etc.). Le recours à un CDN (Content Delivery Network) assure quant à lui une distribution plus rapide des ressources aux utilisateurs géographiquement éloignés du serveur principal, tout en renforçant la résilience du site face à des pics de trafic. - Assurer la compatibilité mobile : Depuis le déploiement de l’indexation mobile-first par Google, la version mobile d’un site est la version de référence utilisée pour l’analyse et le classement dans les SERP. Il est donc essentiel que le site propose une expérience fluide et cohérente sur tous les types de terminaux. Cela implique l’usage d’un design responsive, qui adapte dynamiquement l’affichage aux tailles d’écran, mais aussi une attention particulière à l’ergonomie mobile : menus accessibles, boutons assez grands pour être cliqués facilement, champs de formulaire adaptés au clavier tactile, etc. Au-delà du design, les performances techniques sur mobile doivent être optimisées. Les signaux des Core Web Vitals comme le Largest Contentful Paint (LCP), le First Input Delay (FID) et le Cumulative Layout Shift (CLS) doivent être surveillés et améliorés via des outils comme Lighthouse ou PageSpeed Insights. Un site rapide, lisible et stable sur mobile a davantage de chances d’être bien positionné dans les résultats mobiles, qui représentent aujourd’hui la majorité du trafic web.
- Renforcer la sécurité du site : La sécurité est un facteur de confiance déterminant pour les utilisateurs et un signal positif pour les moteurs. La transition vers le protocole HTTPS, via l’installation d’un certificat SSL, est désormais un prérequis pour tout site web, notamment parce que Google affiche des alertes dans Chrome pour les sites en HTTP. Mais au-delà du chiffrement des données, le SEO technique intègre également des pratiques de sécurisation avancée : ajout de headers de sécurité HTTP (
Strict-Transport-Securitypour forcer l’usage du HTTPS,X-Content-Type-Optionspour éviter les interprétations malveillantes des fichiers,Content-Security-Policypour limiter les scripts externes). - Un autre levier du SEO technique lié à la clarté et à la fiabilité du contenu est l’implémentation de données structurées au format Schema.org. Ces balises permettent de décrire précisément le contenu d’une page. Le SEO technique agit donc comme un levier d’accessibilité algorithmique : il s’assure que le site peut être exploré sans obstacle, compris sans ambiguïté et servi aux internautes dans des conditions optimales. Autrement dit, il établit un environnement favorable dans lequel les efforts de contenu et de netlinking pourront pleinement exprimer leur potentiel.
Un site techniquement bien conçu, avec une architecture claire, un temps de chargement réduit, des redirections maîtrisées, et une indexation bien pilotée, a toutes les chances d’être correctement interprété par les moteurs. À l’inverse, des défauts techniques non corrigés (même mineur) peuvent freiner le positionnement de l’ensemble du site, voire entraîner des pénalités algorithmiques dans les cas les plus extrêmes (contenu dupliqué, cloaking, URLs indéxables en masse, etc.).
Le SEO technique n’est donc pas une couche secondaire à ajouter après coup, mais une fondation à poser dès la conception du site, puis à entretenir régulièrement au rythme de ses évolutions. Il exige une collaboration étroite entre les développeurs, les webmasters, les UX designers et les experts SEO pour faire converger les exigences techniques, les attentes des utilisateurs et les règles des moteurs de recherche.
Les principaux éléments à optimiser en SEO technique
Le SEO technique regroupe un ensemble d’optimisations visant à améliorer l’accessibilité, la compréhension et la performance d’un site web aux yeux des moteurs de recherche. Ces optimisations agissent en coulisses, mais ont un impact déterminant sur la capacité d’un site à se positionner dans les premiers résultats. Que ce soit au niveau de la structure, du code, de la vitesse ou de la conformité aux standards web, chaque détail technique compte. Voici un tableau détaillé des éléments techniques à surveiller, avec une description exhaustive des actions à mettre en place :
| Élément technique | Optimisations recommandées |
|---|---|
| Architecture du site | Construire une arborescence logique avec une profondeur de clics sémantiquement réfléchie. Utiliser des catégories bien définies, mettre en place un maillage interne thématique, limiter les pages orphelines, et générer des URLs explicites grâce au rewriting (ex. : /categorie/produit plutôt que /index.php?id=123). |
| Sitemap XML | Créer un fichier sitemap.xml listant les pages à indexer, mis à jour automatiquement à chaque ajout ou suppression de contenu. Indiquer la priorité de chaque page et sa fréquence de mise à jour. Soumettre le sitemap via la Google Search Console pour faciliter l’exploration. |
| Fichier robots.txt | Configurer le fichier robots.txt pour bloquer les répertoires inutiles ou sensibles (/admin/, /cgi-bin/…), et éviter le crawl de pages sans intérêt SEO (paramètres d’URL, sessions, tri). Vérifier qu’aucune page stratégique n’y est bloquée par erreur. |
| Balises meta robots | Utiliser les balises meta robots pour contrôler l’indexation au cas par cas : noindex pour les pages à exclure des résultats, nofollow pour limiter la transmission de popularité, etc. Très utile pour les pages de filtrage ou les versions imprimables. |
| Canonicalisation | Mettre en place la balise <link rel="canonical"> sur chaque page pour indiquer la version principale d’un contenu en cas de duplication (produits similaires, URL avec paramètres…). Cela permet de concentrer le PageRank et d’éviter l’indexation multiple de contenus similaires. |
| Données structurées (Schema.org) | Ajouter des balises Schema.org pour décrire précisément les contenus (articles, produits, avis, événements, FAQ…). Ces données enrichissent les résultats Google (rich snippets), facilitent la compréhension du contenu par les moteurs et améliorent le taux de clic (CTR). |
| Vitesse de chargement | Optimiser les Core Web Vitals : compresser les images (WebP, AVIF), activer la mise en cache, minifier les scripts CSS/JS, utiliser un CDN, optimiser le TTFB, éviter les scripts bloquants, et réduire les requêtes inutiles. Surveiller les performances avec Lighthouse ou PageSpeed Insights. |
| Version mobile (mobile-first) | Adopter un design responsive, rendre les éléments interactifs accessibles au tactile, éviter les contenus masqués ou tronqués sur mobile, tester l’affichage avec l’outil mobile-friendly de Google. Corriger les problèmes d’ergonomie dans la Search Console. |
| HTTPS / Sécurité | Installer un certificat SSL valide. Rediriger toutes les pages HTTP vers HTTPS. Ajouter des headers de sécurité : HSTS, X-Content-Type-Options, Content-Security-Policy. Mettre à jour régulièrement le CMS et les plugins pour éviter les failles de sécurité. |
| Erreurs 404 et redirections | Surveiller les erreurs 404 dans la Search Console, mettre en place des redirections 301 permanentes vers des pages pertinentes. Éviter les redirections en chaîne ou les boucles. Créer une page 404 personnalisée, avec des liens utiles pour conserver les utilisateurs sur le site. |
| Nettoyage des URLs et paramètres | Éviter les URLs trop longues ou à paramètres multiples. Canonicaliser les pages filtrées, utiliser Google Search Console pour configurer les paramètres d’URL. Préférer des structures courtes, descriptives et sans caractères spéciaux (/blog/seo-technique plutôt que /page.php?id=45&cat=seo). |
| Gestion des erreurs serveur | Corriger rapidement les erreurs 5xx (503, 502…), surveiller la disponibilité du site, utiliser des outils de monitoring comme UptimeRobot. Configurer correctement les réponses HTTP selon le type d’erreur. Une mauvaise disponibilité impacte directement le crawl et la confiance des moteurs. |
| Compression et poids des pages | Limiter le poids des pages en optimisant les images, les polices web, les animations et les vidéos embarquées. Compresser les ressources statiques, regrouper les fichiers CSS/JS, et éviter les widgets tiers trop lourds. Viser un poids total inférieur à 2 Mo par page pour mobile. |
| Pagination | Utiliser les balises rel="next" et rel="prev" (même si Google les ignore aujourd’hui), ou créer des pages « tout afficher » canonicalisées. S’assurer que les contenus paginés sont crawlables et que chaque page apporte de la valeur unique. |
| Accessibilité pour le crawl | Éviter les contenus chargés en JavaScript uniquement sans rendu côté serveur. Privilégier le HTML sémantique, pré-rendre les pages si nécessaire (prerendering ou SSR), et vérifier que le contenu principal est visible sans interaction (scroll, clic, etc.). |
| Gestion des langues (hreflang) | Pour les sites multilingues, utiliser les balises hreflang pour indiquer les versions linguistiques ou géographiques d’une page. Cela permet à Google de proposer la version la plus appropriée selon la langue ou la localisation de l’utilisateur. |
Chaque optimisation technique contribue à la stabilité, la lisibilité et la performance globale du site. Un audit SEO régulier, couplé à une surveillance continue via des outils spécialisés (Google Search Console, Screaming Frog, Sitebulb, etc.), permet de maintenir un socle technique sain, essentiel pour capitaliser sur les efforts de contenu et de netlinking.

Exemples concrets d’optimisations techniques SEO techniques
Le SEO technique ne repose pas sur des suppositions ou des interventions abstraites : Il produit des effets concrets, mesurables, durables. À travers une multitude de configurations, de CMS, de structures et de volumétries, il s’impose comme un levier stratégique pour améliorer l’indexation, la qualité des signaux envoyés aux moteurs de recherche et la stabilité de l’écosystème digital. Voici un tour d’horizon riche et varié d’exemples d’optimisations techniques (malheureusement non exhaustif compte tenu de toutes les optimisations possibles sur un site Internet) ayant un impact significatif sur la visibilité et la performance SEO de différents sites.
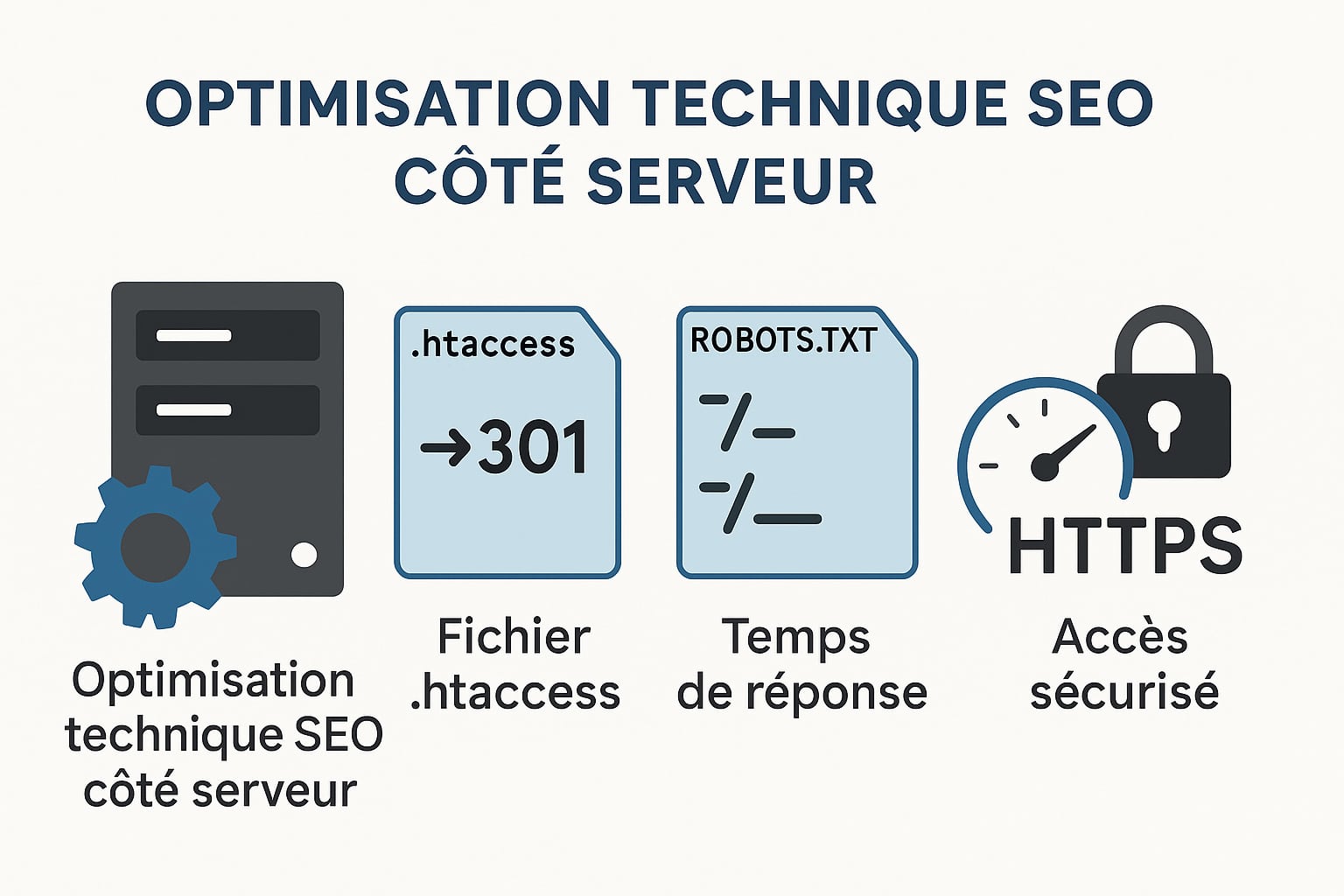
L’optimisation technique SEO sur le serveur pour commencer
Au-delà des optimisations visibles dans le contenu HTML ou la structure du site, une part essentielle du SEO technique repose sur la configuration serveur. C’est à ce niveau que se déterminent de nombreux comportements liés à l’exploration, à l’indexation, à la sécurité ou encore à la performance de chargement. Une mauvaise configuration peut nuire à la visibilité dans les moteurs de recherche, ralentir l’exploration du site par les robots, ou même provoquer l’exclusion involontaire de pages clés. L’intervention par un consultant SEO expérimenté sur les paramètres serveur, que ce soit via les fichiers de configuration comme le .htaccess, le robots.txt, ou via le gestionnaire de cache et de compression, est une composante stratégique du SEO technique, souvent négligée. Voici quelques exemples de ce que l’on peut faire, sachant que ces aspects sont par ailleurs traités dans d’autres sections de cet article :
Le fichier .htaccess : Un levier de contrôle puissant
Le fichier .htaccess est un fichier de configuration propre aux serveurs Apache, très utilisé sur les hébergements mutualisés. Il permet de définir des règles de réécriture, de redirection, de sécurité, de gestion de cache ou de compression. Voici quelques usages clés pour le SEO :
- Redirections 301 permanentes : rediriger proprement les anciennes URLs vers leurs nouvelles versions, sans passer par des chaînes de redirection (exemple :
Redirect 301 /ancienne-page /nouvelle-page). - Réécriture d’URL (URL rewriting) : supprimer les paramètres ou les URLs dynamiques pour générer des URLs propres et lisibles (exemple :
/produit?id=23devient/produit/nom-du-produit). - Forcer le HTTPS : imposer la version sécurisée du site via redirection automatique (important pour la sécurité, mais aussi pour éviter le contenu dupliqué entre HTTP et HTTPS).
- Forcer ou supprimer le www : éviter la duplication entre les versions
wwwetnon-wwwen définissant une version canonique unique. - Activer la compression GZIP : améliorer les temps de chargement en compressant les fichiers texte, HTML, CSS et JS avant l’envoi au navigateur.
- Définir les en-têtes de cache : mettre en place une politique de cache sur les ressources statiques pour accélérer l’affichage et réduire les requêtes.
- Blocage d’accès aux fichiers sensibles : empêcher l’indexation ou l’accès à des fichiers techniques (config, logs, backups), souvent explorés par les robots malveillants.
Le .htaccess agit donc comme un véritable tableau de bord de pilotage SEO côté serveur. Il est important de le maintenir propre, cohérent, et régulièrement audité pour éviter les conflits de règles ou les erreurs de configuration.
Le fichier robots.txt : Gérer le crawl avec finesse
Le fichier robots.txt, situé à la racine du site (https://www.exemple.com/robots.txt), permet de donner des directives aux robots d’indexation (notamment Googlebot, Bingbot, etc.). Contrairement à une idée reçue, il ne sert pas à empêcher l’indexation, mais à bloquer l’exploration de certaines ressources par les crawlers.
Voici les usages courants en SEO technique :
- Empêcher le crawl de zones inutiles : dossiers système, fichiers d’administration, scripts, dossiers contenant des assets ou du contenu en double.
- Limiter le crawl de filtres ou de paramètres d’URL : si ceux-ci créent des millions de variantes d’URLs sans valeur ajoutée, il est préférable de les désactiver ici pour préserver le budget crawl.
- Référencer le sitemap XML : via la directive
Sitemap:, on peut indiquer l’emplacement du fichier sitemap pour faciliter l’exploration (exemple :Sitemap: https://www.exemple.com/sitemap.xml). - Bloquer temporairement certains environnements (préproduction, staging) avant la mise en ligne, pour éviter leur indexation accidentelle.
Un exemple simple de robots.txt optimisé :
User-agent: *
Disallow: /admin/
Disallow: /recherche/
Disallow: /*?tri=
Allow: /assets/
Sitemap: https://www.exemple.com/sitemap.xml
Attention : l’utilisation du Disallow empêche uniquement l’exploration, pas l’indexation. Si une page est bloquée dans le robots.txt mais reçoit des liens externes, elle peut tout de même apparaître dans Google avec une balise vide ou partielle. Pour empêcher réellement l’indexation, il faut combiner cette approche avec la balise <meta name="robots" content="noindex">.
Les autres paramètres serveur influençant le SEO technique
En plus du .htaccess et du robots.txt, plusieurs éléments de configuration serveur peuvent impacter directement la performance SEO :
- Temps de réponse du serveur (TTFB) : un temps de réponse lent peut freiner l’exploration des pages. Il doit idéalement rester sous 200 ms.
- Configuration des erreurs 404 et 410 : les pages supprimées doivent renvoyer un code d’erreur HTTP approprié (404 pour les pages perdues, 410 pour les pages définitivement retirées). Une page d’erreur mal configurée peut envoyer un code
200trompeur pour les moteurs. - Compression et cache serveur : via les modules Apache (mod_deflate, mod_expires) ou via NGINX, il est possible d’alléger le poids des fichiers transmis et d’améliorer les Core Web Vitals.
- Sécurité et accès HTTPS : le certificat SSL doit être valide, à jour, et forcer la redirection vers la version HTTPS. Un site HTTP peut être considéré comme non sécurisé par les navigateurs modernes, ce qui impacte la confiance des utilisateurs et donc les signaux comportementaux.
Enfin, pour les sites à fort trafic ou à fort volume de pages, une configuration avancée peut inclure l’usage d’un reverse proxy (Varnish), d’un CDN (Cloudflare, Fastly), ou d’une architecture serveur dédiée (NGINX, Apache avec MariaDB optimisé) pour garantir une disponibilité, une rapidité et une scalabilité optimales.
Le niveau serveur est un levier central du SEO technique. Il conditionne la lisibilité du site par les robots, l’efficacité de l’exploration, la cohérence des signaux techniques, et la robustesse globale de l’écosystème digital. Sa maîtrise permet d’anticiper les erreurs bloquantes, de fluidifier le passage des crawlers, et de consolider la base sur laquelle repose toute stratégie de référencement naturel.
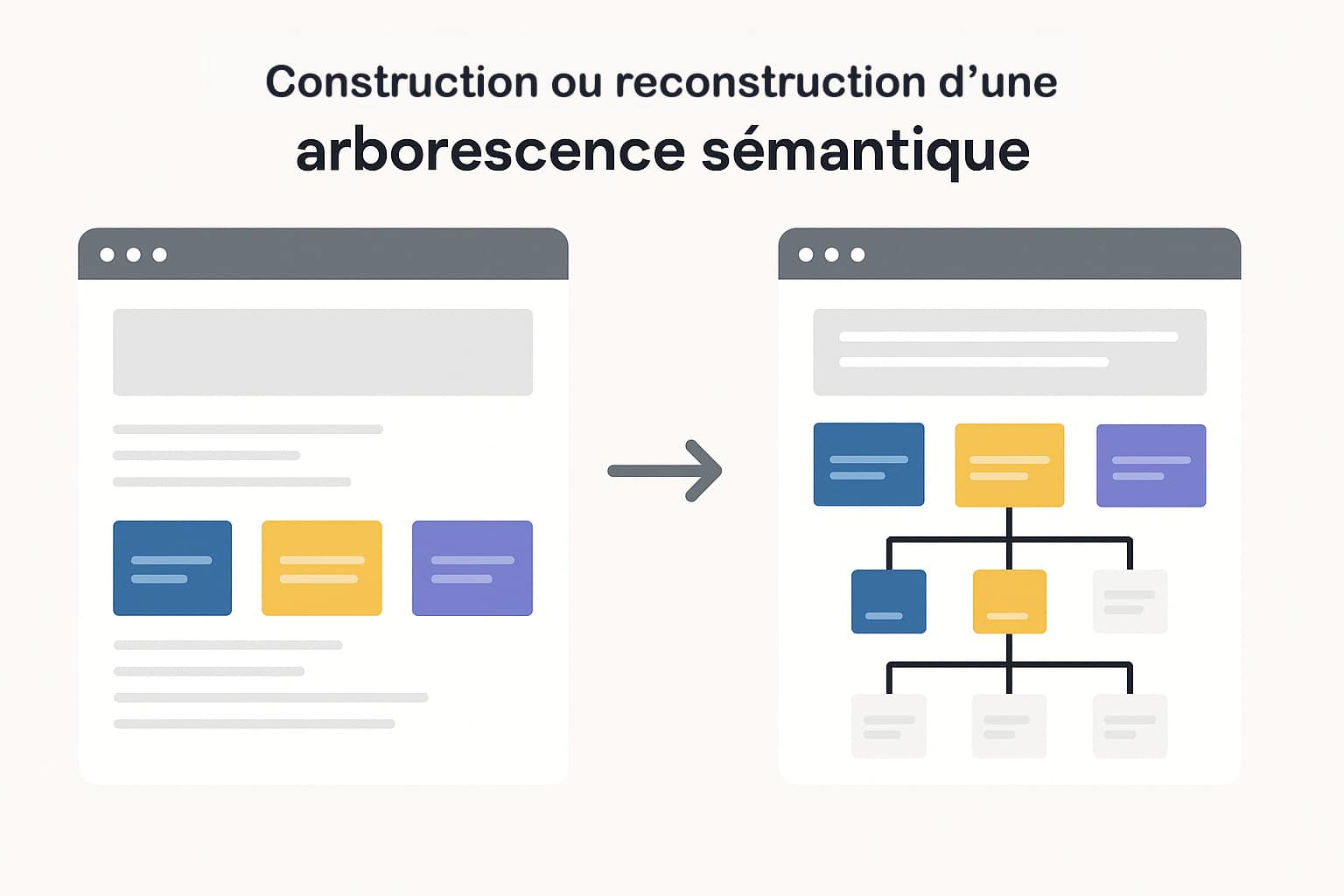
La reconstruction d’une arborescence sémantique
Repenser l’arborescence d’un site web dans une logique sémantique consiste à organiser les contenus de manière hiérarchique, logique et compréhensible, tant pour les utilisateurs que pour les moteurs de recherche. Cela repose sur une structuration fine des thématiques abordées, à travers une taxonomie éditoriale cohérente : chaque sujet doit être rattaché à une catégorie principale et, si nécessaire, à des sous-catégories plus spécifiques, créant ainsi un arbre de navigation clair et intuitif. Une bonne arborescence sémantique se traduit par une organisation verticale des contenus (du général au spécifique), ainsi qu’un maillage horizontal pertinent entre les contenus liés. Elle permet à Google de mieux comprendre la thématique dominante de chaque section, d’identifier les pages piliers (pages catégories ou hubs) et de favoriser une exploration fluide du site. Ce type d’organisation contribue à une meilleure répartition du PageRank interne, facilite l’indexation des contenus profonds et améliore leur visibilité sur les requêtes de longue traîne.
Sur le plan technique, cette reconstruction passe par :
- la définition d’une arborescence claire, validée par une analyse sémantique des sujets traités ;
- la réécriture des URLs pour refléter cette hiérarchie (
/rubrique/sous-rubrique/contenu) ; - la création ou l’enrichissement des pages de catégories avec du contenu éditorial unique et optimisé ;
- la mise en place d’un maillage interne logique depuis les articles vers leurs catégories et entre articles connexes ;
- la réduction de la profondeur de clics pour permettre aux robots de découvrir plus rapidement les pages profondes ;
- l’optimisation des balises de titre (
<title>,<h1>, etc.) des pages catégories selon leur rôle dans la hiérarchie ; - l’évitement des duplications de contenus entre les niveaux de l’arborescence.
Ce type de structuration bénéficie directement à l’exploration algorithmique et à la pertinence perçue de chaque page. En adoptant une arborescence sémantique, le site devient plus lisible pour Google, plus navigable pour l’utilisateur et plus robuste pour accueillir de futurs contenus sans générer de confusion dans la classification.
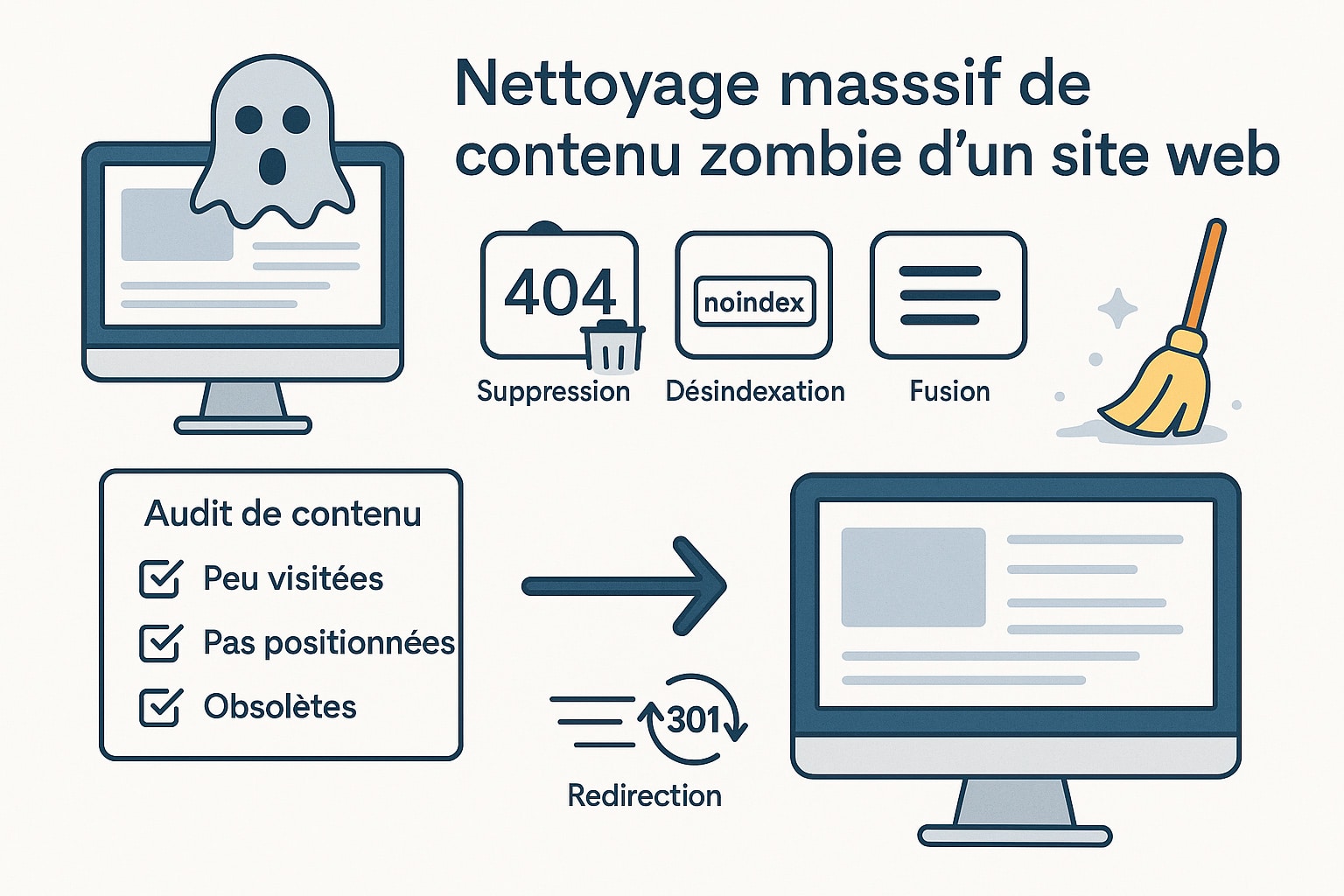
Le nettoyage massif de contenu zombie d’un site Web
Le contenu zombie désigne les pages d’un site qui n’apportent aucune valeur ajoutée, ni aux utilisateurs ni aux moteurs de recherche. Ce sont souvent des pages peu visitées, jamais positionnées dans les résultats de recherche, ou encore dupliquées, pauvres en contenu, obsolètes ou générées automatiquement. Leur présence en trop grand nombre peut affecter l’efficacité globale du site en diluant la pertinence sémantique, en gaspillant le budget crawl, et en rendant l’architecture plus confuse pour les algorithmes. Le nettoyage de ces contenus consiste à mener un audit approfondi afin d’identifier les pages n’ayant généré ni trafic organique, ni conversions, ni signaux de performance sur une période définie (souvent 6 à 12 mois). Une fois ces pages repérées, plusieurs actions peuvent être envisagées en fonction de leur nature :
- Suppression définitive des pages sans valeur, accompagnée d’un code HTTP 410 (contenu supprimé) ou 404 si nécessaire ;
- Désindexation des pages secondaires (variantes, doublons, pages générées automatiquement) à l’aide de balises
noindex; - Fusion de contenus proches pour créer des pages plus riches, consolidées et plus pertinentes sémantiquement ;
- Redirection 301 des pages expirées vers des pages équivalentes, comme un produit similaire, une catégorie pertinente ou une page d’information sur le sujet ;
- Mise à jour ou réécriture des pages encore pertinentes mais mal optimisées, afin de relancer leur potentiel SEO.
Ce processus permet de rationaliser l’architecture du site, de concentrer le PageRank interne sur les pages à fort potentiel, et de recentrer les signaux d’autorité autour des contenus réellement utiles. En supprimant ou désindexant les pages « mortes », le site devient plus lisible pour les robots, qui peuvent alors consacrer plus de ressources à l’exploration et à l’indexation des contenus stratégiques ou récents.
Ce travail de fond, souvent négligé car perçu comme destructeur, est en réalité une étape fondamentale dans toute stratégie SEO technique à long terme. Il s’agit d’un acte de clarification, qui permet de renforcer la cohérence thématique du site et d’améliorer globalement sa performance organique.
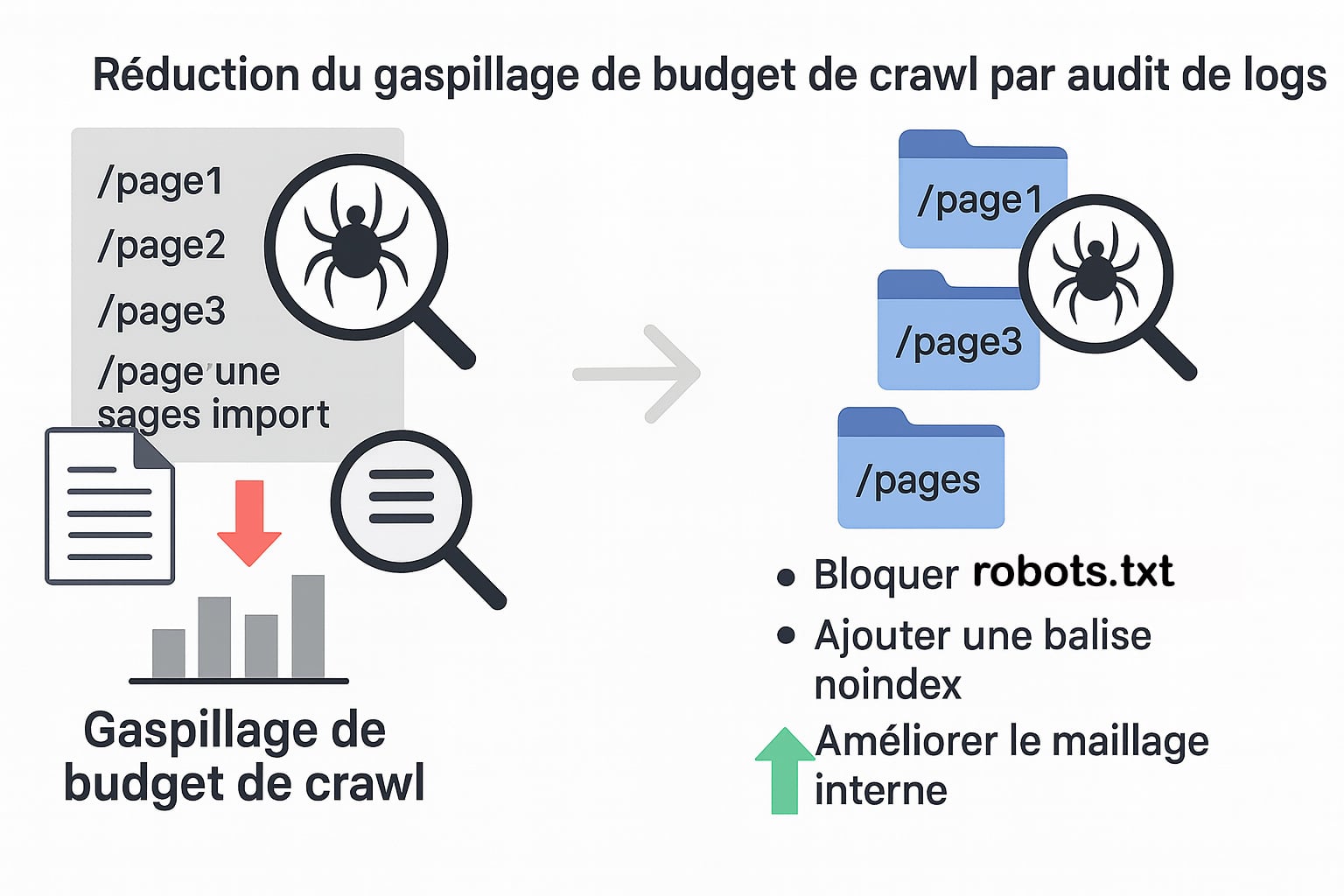
La réduction du gaspillage du budget crawl via un audit de logs
Le budget crawl représente la quantité de ressources que les moteurs de recherche, et en particulier Googlebot, sont prêts à consacrer à l’exploration d’un site. Plus un site est volumineux, dynamique ou fréquemment mis à jour, plus ce budget devient un enjeu critique. Lorsqu’une partie significative du crawl est utilisée pour explorer des pages peu pertinentes, non indexables ou redondantes (comme des paginations profondes, des filtres de tri ou des pages à paramètres), cela empêche Google d’accéder efficacement aux pages stratégiques du site. La première étape pour optimiser le budget crawl est l’analyse des fichiers de logs serveur, qui permettent d’observer en détail le comportement des bots sur le site. Contrairement à une simple analyse de crawl simulé, l’étude des logs révèle exactement quelles pages ont été explorées, à quelle fréquence, par quel user-agent et avec quel code de réponse HTTP.
Sur la base de cette analyse, les actions d’optimisation peuvent inclure :
- Le blocage du crawl de certaines familles d’URLs inutiles via le fichier
robots.txt(ex. : paramètres de tri, paginations profondes, variantes de pages non stratégiques) ; - L’ajout de balises
noindexsur des pages accessibles mais non destinées à être indexées (comme les pages de filtres ou les duplications techniques) ; - La suppression ou la consolidation des pages créées dynamiquement qui n’ont pas de valeur SEO autonome ;
- La priorisation du maillage interne vers les pages à fort potentiel, afin de guider les robots vers les contenus prioritaires (pages produits, articles à fort volume de recherche, pages catégories principales) ;
- La création de landing pages dédiées pour concentrer le trafic et les signaux sur des URLs indexables, stables, bien structurées et thématisées.
En réduisant le gaspillage du budget crawl, on libère des ressources pour que les robots explorent plus fréquemment les pages importantes du site, notamment les nouvelles publications, les contenus mis à jour et les pages à fort potentiel de conversion. Cela accélère leur indexation, renforce leur visibilité organique, et permet d’éviter que des contenus essentiels restent « invisibles » faute d’exploration suffisante.
Ce travail d’optimisation, bien qu’invisible pour l’utilisateur final, joue un rôle fondamental dans l’alignement entre la structure technique du site et les exigences des moteurs de recherche. Il garantit que les efforts de contenu et de netlinking bénéficient d’un socle technique bien géré, sans perte d’efficacité liée à un gaspillage algorithmique.
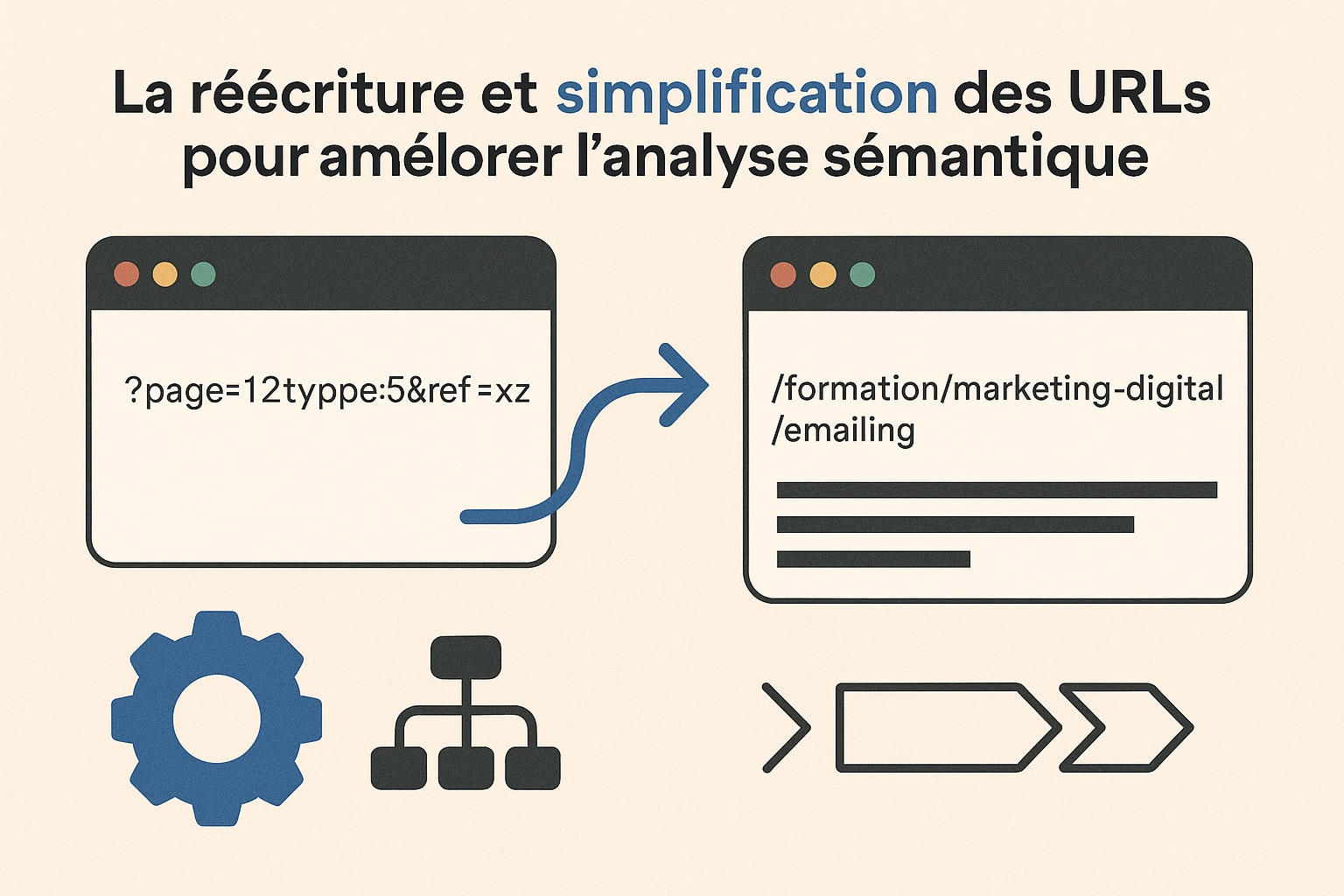
La réécriture et simplification des URLs pour améliorer l’analyse sémantique
La structure des URLs joue un rôle fondamental dans la lisibilité sémantique d’un site, à la fois pour les utilisateurs et pour les moteurs de recherche. Une URL bien construite agit comme un indicateur de contexte et facilite l’association entre une page et les intentions de recherche qu’elle cible. À l’inverse, des URLs techniques, obscures ou générées dynamiquement à l’aide de paramètres (ex. : ?page=12&type=5&ref=xyz) compliquent cette lecture, diluent la valeur des mots-clés, et créent des risques de duplication ou d’inefficacité dans le crawl. Une démarche de simplification et de réécriture des URLs consiste à adopter une logique descriptive, hiérarchique et thématique. Elle repose sur plusieurs principes :
- Mettre en cohérence la structure des URLs avec l’arborescence sémantique du site, en intégrant les catégories, sous-catégories et le nom de la page cible (
/formation/marketing-digital/emailing) ; - Supprimer les paramètres techniques et tout élément inutile à la compréhension de l’URL (numéros d’identifiants, langages serveurs, chaînes de session) ;
- Utiliser des mots-clés cibles dans les segments de l’URL, en cohérence avec la stratégie SEO de la page, afin de renforcer la correspondance lexicale avec les requêtes visées ;
- Maintenir les anciennes URLs via des redirections 301 pour ne pas perdre les signaux accumulés (backlinks, historique d’indexation) ;
- Harmoniser la profondeur d’URL en fonction du rôle de la page dans l’entonnoir de conversion ou de sa cible SEO (ex. : autoriser une grande profondeur sur des contenus longue traîne ultra-spécifiques, tout en évitant l’uniformisation forcée de la hiérarchie).
Cette structuration permet à Google de comprendre non seulement la thématique d’une page, mais aussi son contexte dans la hiérarchie du site. En complément, le fil d’Ariane (breadcrumb) devient un signal supplémentaire de cette organisation, visible à la fois dans le code source et dans les résultats de recherche enrichis, ce qui renforce la lisibilité structurelle du site pour les moteurs.
Par ailleurs, une révision complète des menus de navigation (header) et du footer permet de concentrer le PageRank interne. En réduisant drastiquement le nombre de liens sortants non essentiels dans ces blocs globaux, on évite la dilution de popularité sur des pages secondaires, inutiles ou redondantes. Chaque lien ajouté dans ces zones doit répondre à un objectif stratégique clair, idéalement en lien direct avec les clusters thématiques du site.
Cette approche structurelle s’inscrit dans une logique de précision sémantique, de hiérarchisation thématique et de pilotage du maillage. Elle permet d’optimiser la correspondance entre les intentions de recherche, la structure du site et les signaux envoyés à Google via les URLs, tout en renforçant la maîtrise du flux de popularité interne.
L’optimisation de la structure Hn et du balisage HTML
La structure des balises de titres HTML (appelées balises Hn, de <h1> à <h6>) joue un rôle fondamental dans l’interprétation du contenu par les moteurs de recherche. Ces balises ne sont pas seulement des éléments de mise en forme visuelle ; elles définissent une hiérarchie logique et sémantique du contenu, permettant aux crawlers de comprendre la structure informationnelle d’une page, ses sections, sous-sections et l’organisation des idées qu’elle développe.
Un balisage Hn bien conçu reflète la hiérarchie logique du contenu, à l’image d’un plan structuré : <h1> pour le titre principal de la page, <h2> pour les grandes sections, <h3> pour les sous-sections, et ainsi de suite. Il est essentiel qu’une seule balise <h1> soit utilisée par page, afin d’indiquer clairement à Google le sujet central du document. L’usage répétitif ou désordonné de balises Hn peut non seulement nuire à la lisibilité algorithmique, mais aussi créer une confusion quant aux thématiques principales abordées. L’optimisation SEO technique de cette structure passe par plusieurs étapes techniques et éditoriales :
- Identification et correction des balises Hn multiples ou désordonnées : suppression des balises
<h1>superflues, révision des niveaux hiérarchiques pour assurer une progression logique sans sauts (pas de<h4>directement après un<h1>) ; - Rédaction de titres structurants et descriptifs : chaque balise de titre doit annoncer clairement le contenu de la section qu’elle introduit, en intégrant si possible des mots-clés secondaires liés à l’intention de recherche ciblée ;
- Intégration de balises HTML sémantiques complémentaires :
<section>,<article>,<aside>,<nav>, qui permettent de segmenter proprement le code et de renforcer la compréhension algorithmique des rôles de chaque partie ; - Éviter les titres vides ou génériques comme « Section 1 » ou « Autres informations », qui n’apportent aucun signal sémantique pertinent aux moteurs de recherche ;
- Contrôle des titres générés automatiquement par les CMS ou les constructeurs de pages, qui peuvent insérer des balises Hn en dehors de toute logique hiérarchique ou dans les widgets (menus, sliders, footers), faussant ainsi l’analyse globale.
Au-delà de la structure Hn elle-même, un travail sur l’ensemble du balisage HTML de la page est nécessaire. L’objectif est de produire un code propre, allégé, respectueux des standards du W3C et sémantiquement riche. Cela implique notamment :
- la suppression des balises inutiles ou redondantes (ex. :
<div>imbriqués sans raison), - l’usage approprié de
<strong>,<em>pour mettre en valeur des notions importantes, - l’accessibilité des contenus (attributs
altsur les images,aria-labelsur les éléments interactifs), - la hiérarchisation logique des blocs de contenu via
<main>,<header>,<footer>, etc.
Ce travail de fond améliore considérablement la lisibilité du contenu par les moteurs de recherche. Il permet également une meilleure identification des sections clés d’une page, favorisant l’apparition de sitelinks automatiques dans les résultats de recherche, l’enrichissement des extraits avec des sous-titres ou ancres internes, et une meilleure structuration du contenu dans les outils d’analyse de Google (comme l’outil d’inspection d’URL ou les données structurées).
Une structure Hn rigoureusement hiérarchisée, combinée à un balisage HTML propre et sémantique, constitue donc un socle essentiel du SEO technique. Elle permet aux algorithmes d’interpréter efficacement le contenu, de le classer plus finement par thématique et de favoriser son affichage enrichi dans les résultats de recherche.

La migration technique d’un CMS non-SEO-friendly vers un CMS performant
Le choix d’un CMS (Content Management System) est une décision stratégique qui conditionne directement la capacité d’un site à être correctement exploré, interprété et indexé par les moteurs de recherche. De nombreux sites, notamment institutionnels ou issus d’environnements fermés (intranets, applications métier, CMS propriétaires), fonctionnent sur des plateformes qui ne respectent pas les standards du web moderne et offrent peu voire aucune marge de manœuvre en matière de SEO technique. Un CMS non-optimisé présente généralement plusieurs limitations :
- Code HTML obsolète, peu sémantique et souvent lourd ;
- Impossibilité de personnaliser les balises
<title>,meta description, ou les balisescanonical; - Génération d’URLs dynamiques, illisibles et non maîtrisables ;
- Absence de sitemap XML exploitable ou de fichiers robots.txt configurables ;
- Manque de compatibilité mobile, de gestion des performances ou d’accessibilité ;
- Impossible d’ajouter des balisages sémantiques type Schema.org sans développement spécifique ;
- Absence d’extensions SEO ou de fonctionnalités natives pour gérer le contenu et sa hiérarchisation.
Dans ce contexte, une migration vers un CMS plus performant (comme WordPress, Drupal, TYPO3 ou toute autre solution open-source évolutive)constitue une étape technique décisive pour redonner au site sa capacité de progression en SEO. Cette migration implique une planification rigoureuse afin de limiter les pertes de positionnement et garantir la continuité des signaux SEO existants.
Les axes d’optimisation à intégrer dans une migration réussie sont nombreux :
- Structure d’URL maintenue ou rationalisée avec redirections 301 systématiques depuis les anciennes URLs ;
- Intégration native des balises SEO (titre, méta description, canonical, meta robots) personnalisables par page ;
- Possibilité d’éditer le maillage interne facilement à travers des blocs de contenus, menus contextuels ou shortcodes ;
- Génération automatique et dynamique des sitemaps XML, mis à jour à chaque ajout ou suppression de contenu ;
- Compatibilité mobile native (responsive design) à travers des thèmes modernes, optimisés pour les Core Web Vitals ;
- Optimisation technique du code source : suppression des balises inutiles, usage de HTML5 sémantique, meilleure structuration Hn, allègement du DOM ;
- Intégration facilitée des données structurées Schema.org, grâce à des extensions ou des blocs dédiés (type Article, FAQ, Event, Organization…) ;
- Contrôle des erreurs techniques (pages 404, redirections, erreurs 5xx) via des plugins SEO avancés et une surveillance automatisée ;
- Possibilité de connecter facilement la Search Console, Google Analytics et des outils de suivi SEO ;
- Meilleure évolutivité pour les besoins futurs : multilingue, blog, landing pages, formulaire optimisé, etc.
La migration technique vers un CMS SEO-friendly ne doit pas être perçue uniquement comme un changement d’interface. C’est un levier stratégique permettant de repositionner le site sur des bases techniques saines, adaptables et compatibles avec les exigences actuelles des moteurs de recherche. Cela permet également de réduire la dépendance aux développements spécifiques, en rendant le site plus autonome dans sa gestion SEO. Enfin, cette transition doit toujours s’accompagner d’un audit de pré-migration (cartographie des URLs, analyse des performances SEO existantes), d’une phase de redirection proprement documentée, et d’un suivi post-migration rigoureux pour ajuster le comportement du site en fonction des retours de crawl et des données Search Console.
Adopter un CMS performant, pensé pour le SEO, c’est s’assurer de disposer d’une base technique qui soutiendra durablement les efforts de contenu, de maillage et de visibilité organique, sans être freiné par des limites structurelles obsolètes.

L’implémentation des balises hreflang sur un site multilingue
Pour un site multilingue ou multirégional, l’un des enjeux majeurs en SEO technique est de bien orienter chaque utilisateur vers la version de contenu qui correspond à sa langue ou à sa localisation. À défaut, les moteurs de recherche peuvent afficher des versions inadaptées dans leurs résultats : par exemple, une page en français pour un internaute allemand, ou une version canadienne pour un utilisateur en France. Cela nuit non seulement à l’expérience utilisateur, mais aussi à la performance SEO globale, avec des taux de rebond élevés, une mauvaise compréhension des intentions, et parfois une dilution des signaux de pertinence.
La solution repose sur la mise en œuvre correcte des balises hreflang, qui permettent d’indiquer aux moteurs de recherche les relations d’équivalence entre différentes versions linguistiques ou géographiques d’une même page. Ces balises informent Google sur la version à privilégier en fonction de la langue ou du pays de l’utilisateur, sans que cela soit considéré comme du contenu dupliqué.
L’implémentation des balises hreflang peut se faire de trois manières principales :
- Dans l’en-tête HTML de chaque page, sous forme de balises
<link rel="alternate" hreflang="..." href="...">; - Dans les en-têtes HTTP, pour les fichiers non-HTML comme les PDF ;
- Dans le sitemap XML, en ajoutant des balises
hreflangà chaque URL listée, ce qui est particulièrement utile pour les sites de très grande taille.
Pour que le signal soit bien pris en compte, chaque page doit impérativement :
- déclarer ses propres variantes linguistiques (y compris elle-même) ;
- être réciproquement liée aux autres versions (règle de réciprocité entre les balises) ;
- être accessible aux robots d’exploration (pas de blocage via
robots.txtou balisenoindex) ; - indiquer correctement les codes de langue et, si nécessaire, les variantes régionales (ex. :
fr-fr,fr-ca,en-us,en-gb, etc.) ; - éviter les chaînes de redirections ou les erreurs 404 sur les URLs mentionnées dans les balises
hreflang.
Un site multilingue optimisé avec hreflang bénéficie de plusieurs avantages notables :
- amélioration de la pertinence des résultats affichés selon la langue de l’utilisateur ;
- réduction significative du taux de rebond sur les pages mal ciblées ;
- préservation de la valeur SEO des contenus localisés sans être pénalisé par la duplication ;
- meilleure visibilité sur les versions locales de Google (Google.de, Google.ca, Google.ch, etc.) ;
- centralisation des signaux SEO pour des pages similaires traduites (notamment les backlinks et les signaux comportementaux).
Enfin, il est recommandé d’accompagner l’implémentation des hreflang par :
- un balisage HTML cohérent sur toutes les versions du site, notamment pour les balises titres, descriptions, et structure Hn ;
- un maillage interne adapté à chaque langue, sans forcer les liens vers d’autres versions sauf dans des blocs dédiés (ex. : sélecteur de langue) ;
- la prise en compte des préférences linguistiques via l’en-tête HTTP
Accept-Languageen option pour l’expérience utilisateur ; - un suivi dans la Google Search Console, qui affiche les éventuelles erreurs ou incohérences liées aux balises
hreflang.
Bien implémentées, les balises hreflang permettent donc d’aligner la structure technique du site avec ses objectifs de ciblage international. Elles assurent que chaque utilisateur, peu importe sa langue ou son pays, accède à une version du contenu qui répond précisément à son besoin, tout en préservant la cohérence et la performance SEO globale du site.

L’optimisation du sitemap pour un site à fort volume de pages
Sur un site disposant de plusieurs dizaines ou centaines de milliers de pages, le sitemap XML devient un outil central dans la stratégie de SEO technique. Il s’agit d’un fichier destiné aux moteurs de recherche, qui liste l’ensemble des URLs du site qu’on souhaite faire explorer et potentiellement indexer. Bien utilisé, ce fichier facilite la découverte de contenus, en particulier pour les pages profondes ou peu maillées, comme les fiches produits, les avis clients, les entrées de blog, ou les pages générées dynamiquement.
Mais dans un contexte de forte volumétrie, un simple fichier sitemap ne suffit pas. Google recommande de ne pas dépasser 50 000 URLs par fichier, ou un poids de 50 Mo non compressé. Au-delà de ces limites techniques, c’est la logique de segmentation qui devient stratégique : chaque type de contenu doit faire l’objet d’un sitemap dédié, ce qui permet non seulement de mieux organiser les données, mais aussi de mieux diagnostiquer l’indexation grâce aux outils comme la Google Search Console.
Une optimisation efficace du sitemap XML dans ce type de contexte repose sur plusieurs principes clés :
- Segmenter les sitemaps par type de contenu : un sitemap pour les avis, un pour les fiches produits, un pour les guides, un pour les pages marques, etc. Cela facilite l’analyse de la couverture par section et permet de détecter plus rapidement les problèmes d’indexation sur une famille de contenus précise.
- Ajouter une balise
<lastmod>à chaque URL, renseignée automatiquement à chaque mise à jour de la page. Cela signale aux moteurs les pages modifiées récemment, améliorant ainsi leur fréquence de réexamen. - Mettre à jour les fichiers de manière dynamique, idéalement via un CMS ou un outil automatisé, pour garantir que les sitemaps reflètent l’état réel du site (sans erreurs 404, redirections, ou pages désindexées).
- Soumettre chaque sitemap individuellement dans la Search Console, pour suivre les statistiques de couverture par silo, surveiller les erreurs d’indexation et ajuster les priorités.
En complément des sitemaps XML destinés aux moteurs, il est pertinent dans certains cas d’ajouter un sitemap HTML destiné aux utilisateurs (et aux crawlers). Ce sitemap prend la forme d’une page classique listant les liens vers les principales sections ou toutes les pages importantes du site. Il peut être utile notamment lorsque :
- le site contient des contenus mal maillés ou difficiles d’accès depuis la navigation principale ;
- des pages profondes ou isolées ont besoin d’être reliées à une structure visible ;
- on souhaite aider Google à découvrir des pages importantes sans dépendre uniquement du fichier XML ;
- on veut améliorer la navigation et l’expérience utilisateur sur des sites volumineux ou complexes.
Un sitemap HTML bien construit peut faire office de hub de navigation secondaire, à condition de rester lisible, structuré, et limité aux pages stratégiques. Il ne remplace pas le sitemap XML, mais le complète intelligemment dans certains cas particuliers.
Enfin, l’optimisation des sitemaps (qu’ils soient XML ou HTML) ne se limite pas à un exercice de formatage. Elle s’intègre dans une logique plus large de contrôle de l’indexation. Elle permet de piloter efficacement ce que Google découvre, comprend et choisit d’indexer, tout en offrant un outil de monitoring précieux pour anticiper et corriger les erreurs techniques. Sur des sites à fort volume, c’est une pratique indispensable pour garder la maîtrise du SEO technique à l’échelle.

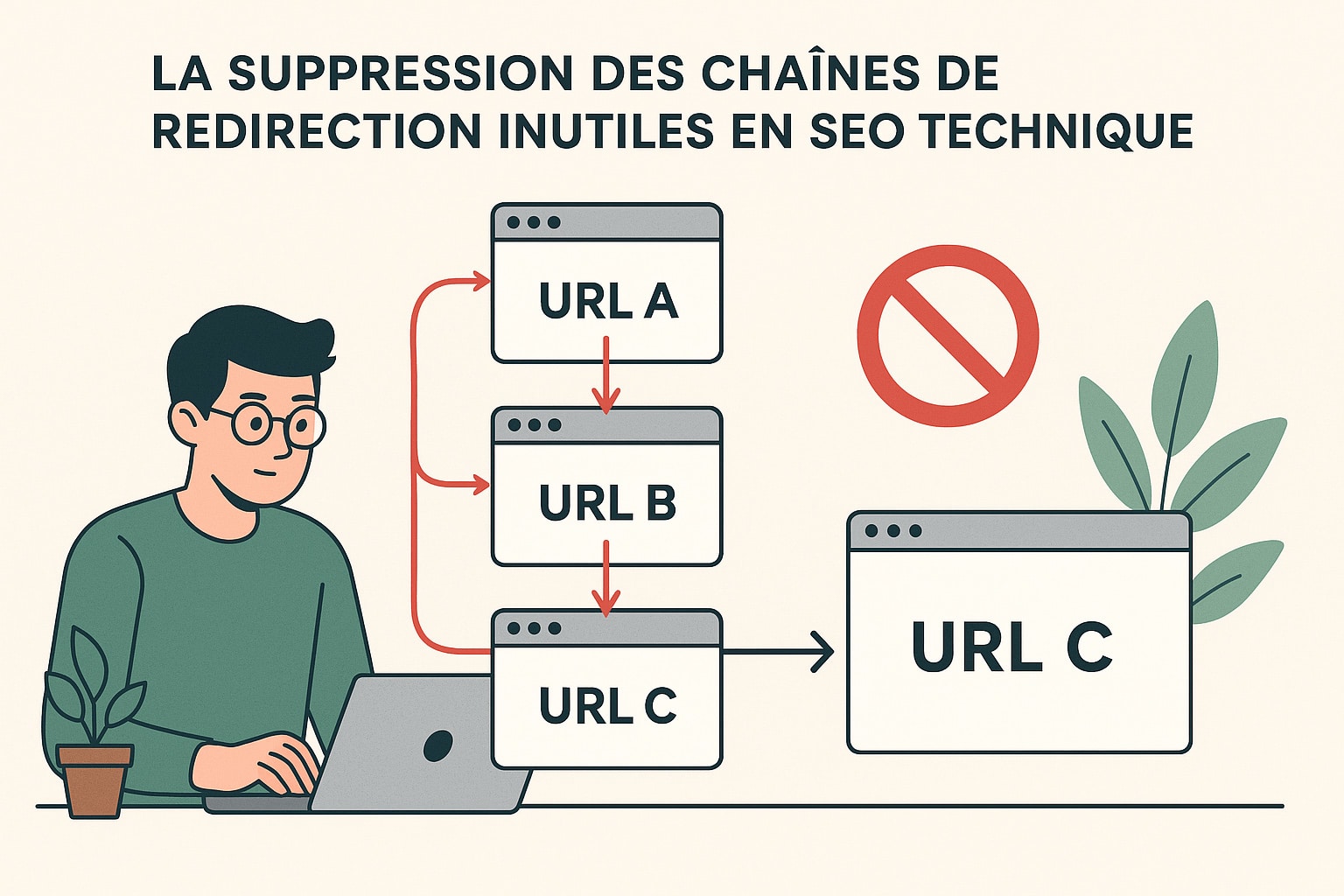
La suppression des chaînes de redirection inutiles en SEO technique
Les redirections font partie intégrante de la gestion d’un site web, notamment lors d’une refonte, d’un changement de structure d’URLs, de la suppression de contenus ou d’une migration technique. Pourtant, lorsqu’elles sont mal gérées, les redirections peuvent devenir contre-productives, en particulier lorsqu’elles s’enchaînent en cascade. C’est ce que l’on appelle une chaîne de redirection, où une URL redirige vers une autre, qui redirige elle-même vers une troisième, et parfois davantage (URL A ➝ URL B ➝ URL C).
Ces enchaînements sont problématiques à plusieurs titres :
- Allongement du temps de réponse : chaque redirection ajoute un aller-retour serveur, ce qui ralentit le chargement perçu par l’utilisateur comme par le crawler ;
- Perte d’efficacité du crawl : les robots de Google ont un temps limité pour explorer un site ; les redirections successives les ralentissent, et réduisent la quantité de pages qu’ils peuvent visiter sur une session donnée ;
- Dilution du PageRank : bien que Google affirme que le PageRank passe à travers les redirections 301, une chaîne excessive peut affaiblir la transmission du signal d’autorité ;
- Problèmes d’indexation : certaines chaînes trop longues ou mal configurées peuvent générer des erreurs ou être ignorées, entraînant des URLs non indexées ou désindexées ;
- Risque d’erreurs ou de boucles : des configurations incorrectes peuvent aboutir à des redirections circulaires (
A ➝ B ➝ A) ou vers des pages inexistantes.
La bonne pratique consiste à limiter au strict minimum le nombre de redirections entre une URL d’origine et sa destination finale. L’objectif est de rediriger directement l’ancienne URL vers la version définitive, sans passer par des intermédiaires. Cette action repose sur :
- Un audit technique complet à l’aide d’outils comme Screaming Frog, Sitebulb ou les logs serveur pour identifier les chaînes existantes ;
- La réécriture manuelle ou automatisée des redirections dans le fichier
.htaccess, les règles NGINX ou via le CMS si un plugin de redirection est utilisé ; - Le nettoyage des anciennes règles obsolètes ou conflictuelles, notamment celles issues de refontes antérieures qui n’ont jamais été supprimées ;
- La centralisation des redirections dans un seul système, pour éviter les conflits entre CMS, plugins, serveur et CDN ;
- La vérification finale des codes HTTP renvoyés (200, 301, 404, etc.) pour chaque ancienne URL, afin de s’assurer que le chemin est bien direct et fonctionnel.
Dans une logique plus large, ce travail de nettoyage participe à la qualité technique globale du site. Il permet d’optimiser l’exploration par les moteurs, d’accélérer le chargement, de limiter les pertes de trafic liées à des erreurs ou à des redirections mal configurées, et d’améliorer l’expérience utilisateur. Il est également recommandé de coupler cette action avec une mise à jour du sitemap XML, en retirant les URLs redirigées, ainsi qu’un suivi dans la Google Search Console pour surveiller les éventuelles erreurs persistantes. Une attention particulière doit être portée à l’impact sur le maillage interne, afin de remplacer les anciens liens pointant vers des URLs redirigées par leurs destinations finales, réduisant ainsi la dépendance aux redirections dans la navigation courante.
La suppression des chaînes de redirection n’est donc pas une simple opération de nettoyage technique, mais un levier pour restaurer la clarté structurelle d’un site, améliorer la vitesse d’exploration, préserver le jus SEO, et sécuriser le parcours utilisateur et crawler de bout en bout.
L’intégration avancée de données structurées dans le SEO technique
Les données structurées sont un ensemble d’informations ajoutées au code HTML d’une page pour permettre aux moteurs de recherche de mieux comprendre son contenu. Elles utilisent un vocabulaire standardisé, principalement celui de Schema.org, reconnu par Google, Bing, Yahoo et Yandex. Ces balises n’ont aucun effet visuel pour l’internaute, mais elles ont une valeur importante dans le cadre du SEO technique : elles enrichissent la compréhension algorithmique des pages et peuvent déclencher l’apparition de rich results dans les pages de résultats de recherche (SERP). L’intégration des données structurées est donc une action stratégique, qui va bien au-delà de l’ajout de quelques balises. Elle repose sur une analyse fine du contenu et de la structure du site, afin d’en extraire des entités clairement identifiables (produits, événements, formations, articles, personnes, organisations, FAQ, avis, etc.).
Voici les grandes étapes et bonnes pratiques pour une implémentation avancée :
- Identification des types de contenus à baliser : Cela peut inclure des fiches produits, des articles, des formations, des événements, des profils d’entreprise, des avis, des guides pratiques, des recettes, etc. Chaque type a son propre vocabulaire Schema.org ;
- Sélection des propriétés pertinentes : Au-delà des champs obligatoires, l’enrichissement avec des propriétés supplémentaires augmente les chances d’apparition en résultats enrichis. Par exemple, une formation balisée avec
Coursepeut inclurename,description,provider,educationalCredentialAwarded,offers, etc. Si elle est couplée àEvent, on peut aussi ajouter la date, le lieu, les modalités, et le tarif ; - Utilisation d’un balisage JSON-LD (recommandé par Google) : Ce format, inséré dans l’en-tête ou le corps de la page, est plus propre et plus maintenable que le balisage microdata intégré aux balises HTML ;
- Validation du balisage via les outils officiels : L’outil de test des résultats enrichis de Google (Rich Results Test) permet de s’assurer que les données sont bien interprétées, et la Search Console propose une vue synthétique de la couverture et des éventuelles erreurs ;
- Maintenance et mise à jour régulière : Des balisages incorrects, obsolètes ou en double peuvent être ignorés par Google, voire pénalisés. Il est donc important de maintenir la cohérence entre les données visibles à l’utilisateur et les données déclarées dans le balisage.
Les types de données structurées les plus utilisés en SEO avancé incluent :
ProductetOfferpour les fiches produits ;CourseetEventpour les offres de formation ;ReviewetAggregateRatingpour les avis clients ;FAQPagepour les sections questions/réponses ;BreadcrumbListpour le fil d’Ariane ;OrganizationetLocalBusinesspour la structure de l’entreprise ;Article,NewsArticle,HowToouRecipepour les contenus éditoriaux spécialisés.
Ces balises ne garantissent pas automatiquement l’apparition de résultats enrichis dans les SERP, mais elles augmentent considérablement les chances qu’un contenu soit mis en avant sous forme de snippets étoilés, carrousels, encadrés d’événements, ou d’autres formats visuellement distinctifs. Cela se traduit généralement par :
- Une amélioration du taux de clic (CTR) sur les pages balisées, grâce à leur visibilité accrue ;
- Une meilleure compréhension du contexte sémantique par les moteurs, notamment pour les entités complexes ;
- Un renforcement des signaux de qualité et de confiance (notamment avec les avis, les prix, les durées, etc.) ;
- Une meilleure compatibilité avec Google Discover, la recherche vocale et les assistants intelligents.
Enfin, il est important d’intégrer les données structurées dans une logique de cohérence globale : Les informations fournies dans le balisage doivent correspondre strictement à celles affichées à l’écran. Toute divergence perçue par les moteurs peut entraîner l’exclusion du contenu des résultats enrichis. Cette rigueur est le gage d’une intégration avancée, durable et bénéfique pour la performance organique d’un site web.
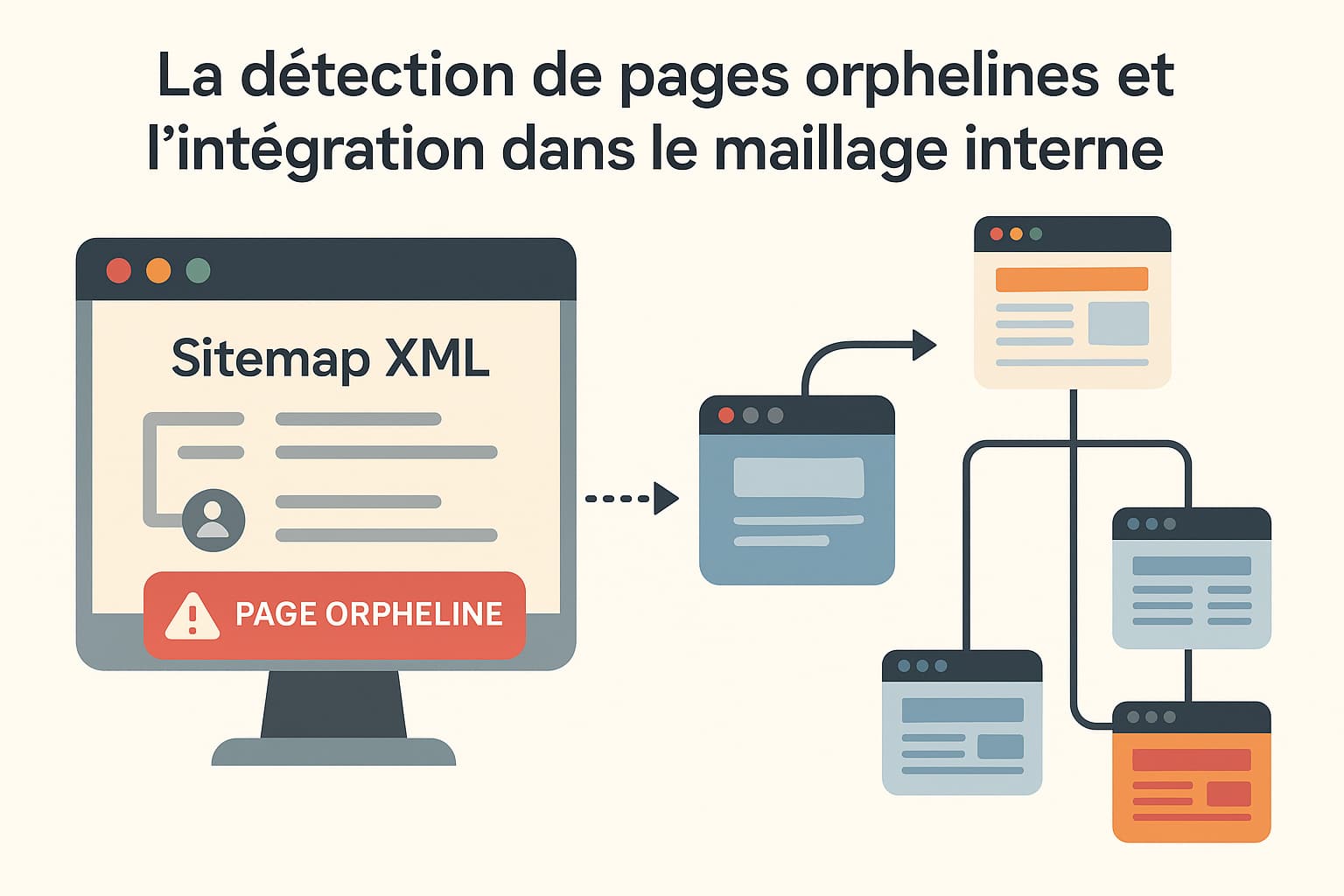
La détection de pages orphelines et l’intégration dans le maillage interne
Les pages orphelines sont des pages présentes sur un site web, parfois même indexables et légitimes du point de vue SEO, mais qui ne sont reliées à aucune autre page du site par un lien interne. Autrement dit, elles ne font partie d’aucun chemin de navigation naturel pour les utilisateurs comme pour les robots d’indexation. Si ces pages sont également absentes du sitemap XML, elles deviennent très difficiles à découvrir pour les moteurs de recherche, qui peuvent alors choisir de ne jamais les explorer ou de les désindexer avec le temps. Dans une logique de SEO technique efficace, la détection et la réintégration des pages orphelines dans le maillage interne constitue une action essentielle. Elle permet de remettre en lumière des contenus existants, parfois oubliés, qui peuvent répondre à des intentions de recherche spécifiques et enrichir la profondeur éditoriale du site.
Comment identifier les pages orphelines d’un site Internet
La détection des pages orphelines nécessite de croiser plusieurs sources de données :
- Le crawl interne du site, effectué à l’aide d’outils comme Screaming Frog, OnCrawl, Sitebulb ou JetOctopus. Ces outils ne trouvent que les pages accessibles depuis les liens internes.
- Le sitemap XML, qui liste (théoriquement) toutes les pages que l’on souhaite faire indexer, même si elles ne sont pas reliées dans la navigation.
- La Search Console (ou les logs serveur), qui peut montrer des pages explorées ou indexées par Google mais non liées au maillage visible.
En comparant ces trois ensembles, on identifie facilement les URLs présentes dans le sitemap ou dans l’index de Google, mais absentes du crawl interne. Ce sont ces pages qu’on qualifie d’orphelines.
Comment réintégrer les pages orphelines dans le maillage interne
Une fois identifiées, les pages orphelines doivent être réintégrées dans le circuit de navigation logique du site. Cela peut se faire de plusieurs façons selon la nature du contenu et la structure existante :
- Ajout de liens contextuels dans les articles de blog ou les pages similaires, en identifiant des passages pertinents pour introduire un lien naturel vers la page orpheline ;
- Insertion dans les blocs de contenus associés ou les carrousels dynamiques (ex. : « à lire aussi », « autres sujets », « voir également ») ;
- Intégration dans les menus contextuels ou les sous-menus de catégories, si la page a une valeur stratégique suffisante ;
- Ajout dans le sitemap HTML si la réintégration dans le maillage contextuel est difficile (utile notamment pour les pages utilitaires, les archives ou les documents PDF indexés) ;
- Création de hubs sémantiques ou pages piliers qui regroupent plusieurs contenus autour d’un même thème, et vers lesquels on peut mailler efficacement les pages isolées.
L’objectif est de replacer ces pages dans un écosystème de navigation fluide, non seulement pour permettre leur (re)découverte par les robots, mais aussi pour renforcer leur intégration thématique via des liens en contexte, ce qui est un facteur important d’optimisation sémantique.
Pourquoi cette action est-elle stratégique en SEO technique ?
En SEO, chaque page utile doit être intégrée dans le maillage interne SEO, non seulement pour des raisons d’exploration, mais aussi pour :
- Distribuer le PageRank : une page orpheline ne reçoit aucune popularité interne, ce qui limite fortement son potentiel de classement ;
- Renforcer la cohérence sémantique globale du site, en liant les pages les unes aux autres selon des logiques de proximité éditoriale ;
- Faciliter l’indexation : une page bien reliée est explorée plus fréquemment, surtout si elle reçoit des liens depuis des pages stratégiques ;
- Améliorer l’expérience utilisateur en offrant des parcours de navigation plus complets et pertinents ;
- Réactiver le potentiel SEO de contenus anciens, souvent négligés mais toujours valables d’un point de vue informationnel.
Détecter et réintégrer les pages orphelines dans le maillage interne est une optimisation technique à forte valeur ajoutée, surtout sur les sites volumineux ou anciens. Elle permet de restaurer la connexion entre les contenus, de réactiver des pages potentiellement rentables, et d’améliorer la couverture globale du site dans les index des moteurs de recherche.
La suppression des paramètres d’URL inutiles dans la Search Console
Sur de nombreux sites, notamment e-commerce ou à forte dynamique de filtrage, des paramètres d’URL sont utilisés pour modifier l’affichage d’un même contenu. Il peut s’agir de filtres de tri (prix, popularité, nouveauté), de déclinaisons produits (taille, couleur, stock), ou encore de paramètres de session, de langue ou de pagination. Ces variantes techniques génèrent des URLs différentes pour une seule et même intention de recherche, créant ainsi un risque de duplication de contenu ou, pire encore, une dispersion du budget crawl sur des pages sans intérêt SEO. Par exemple, les URLs suivantes peuvent toutes renvoyer vers le même contenu visuel, tout en étant perçues comme distinctes par les moteurs :
/chaussures-running/chaussures-running?tri=prix-desc/chaussures-running?couleur=noir&taille=42/chaussures-running?utm_source=newsletter
Ces variantes, si elles ne sont pas correctement gérées, peuvent générer :
- une duplication algorithmique du contenu (même page, URLs différentes) ;
- une dilution des signaux SEO (backlinks, partage, engagement) sur plusieurs versions d’une même page ;
- une saturation du budget crawl par l’exploration de centaines ou milliers d’URLs sans valeur ;
- une confusion dans le choix de l’URL canonique à indexer ;
- une indexation de pages pauvres, incomplètes ou inaccessibles à la navigation classique.
Comment traiter les paramètres d’URL efficacement ?
La première étape consiste à réaliser un audit des paramètres générés sur le site, à l’aide de :
- l’outil d’exploration (Screaming Frog, Sitebulb) pour identifier les URLs à paramètres crawlées ;
- la Search Console, section « Paramètres d’URL », pour consulter les paramètres détectés automatiquement par Googlebot ;
- les logs serveur, qui montrent la réalité de l’exploration des paramètres par les robots ;
- les statistiques de pages indexées, afin de repérer les doublons ou les URLs à faible intérêt SEO.
Ensuite, une configuration spécifique doit être appliquée dans la Search Console (dans l’ancienne interface, pour les propriétés domaine ou préfixe d’URL) :
- Chaque paramètre détecté peut être marqué comme « n’affecte pas le contenu » ou « modifie le contenu », selon son impact réel sur la page ;
- Pour les paramètres inutiles (ex. :
utm_,sessionid,tracking,trisans modification de fond), on peut demander explicitement à Google de ne pas les crawler ; - Pour les filtres utiles mais trop nombreux, il est recommandé de limiter leur indexation via
noindex, ou d’ajouter une balisecanonicalpointant vers la version principale de la page ; - Enfin, dans certains cas critiques, le blocage complet via
robots.txtdes paramètres sans valeur peut être envisagé, en veillant à ne pas empêcher l’accès aux versions importantes du contenu.
Consolider les signaux SEO autour des URLs principales
L’un des enjeux majeurs de cette optimisation SEO technique est de faire converger tous les signaux de performance (liens, partages, clics, historique de visite) vers une seule version de chaque page. Pour cela :
- les liens internes doivent pointer exclusivement vers la version canonique (sans paramètre) ;
- les campagnes marketing doivent inclure des paramètres propres, mais ces versions doivent être désindexées (
noindexou blocagerobots.txt) ; - les sitemaps XML ne doivent référencer que les URLs principales, épurées de tout paramètre technique ;
- les balises
canonicaldoivent être renseignées sur toutes les pages variantes, pointant vers l’URL propre.
Enfin, cette optimisation technique permet également de fluidifier l’exploration du site. En réduisant le nombre de variantes inutiles, on améliore le ratio entre crawl et pages stratégiques, on évite la saturation des quotas d’exploration, et on permet à Googlebot de revenir plus régulièrement sur les pages importantes (produits, catégories, articles, landing pages).
La suppression ou le traitement ciblé des paramètres d’URL inutiles est donc une mesure de fond, souvent invisible pour l’utilisateur, mais hautement bénéfique pour la performance SEO à grande échelle. Elle participe à la consolidation de l’autorité thématique du site, à l’optimisation du budget crawl, et à une meilleure maîtrise des signaux envoyés aux moteurs de recherche.

Création d’une page 404 optimisée avec rebond interne
La page 404, affichée lorsqu’un utilisateur ou un robot tente d’accéder à une URL inexistante ou supprimée, est souvent négligée dans les stratégies SEO. Pourtant, c’est une page clé pour limiter les pertes de trafic, préserver l’expérience utilisateur et renforcer la cohérence du maillage interne. Une page 404 vide, froide ou générique interrompt brutalement la navigation, génère de la frustration et augmente le taux de rebond. À l’inverse, une page 404 optimisée peut devenir un point de rebond vers d’autres contenus pertinents, et même contribuer indirectement à la performance SEO globale.
Pourquoi optimiser la page 404 ?
Une page 404 bien conçue permet de transformer une impasse en opportunité de réengagement. Cela concerne :
- les erreurs de frappe ou de copier-coller d’URL ;
- les liens internes ou externes obsolètes (suite à une refonte, une suppression de page ou une mauvaise redirection) ;
- les erreurs techniques générant des URLs erronées côté client ou côté serveur ;
- les anciennes URLs encore référencées par Google ou d’autres sites, mais qui ne correspondent plus à un contenu actif.
Plutôt que d’abandonner l’utilisateur, l’objectif est de lui proposer une continuité de navigation logique et utile. C’est aussi une manière d’éviter qu’un visiteur quitte immédiatement le site — ce qui peut envoyer un signal négatif à Google en cas de forte récurrence.
Éléments à intégrer dans une page 404 optimisée
Une page 404 ne doit jamais se contenter d’un message du type « Page non trouvée ». Elle doit être pensée comme un outil de réorientation, à la fois fonctionnel, éditorial et graphique. Voici les éléments à inclure :
- Un message clair, rassurant et rédigé sur un ton adapté à l’image de marque du site. Exemples : « Oups, cette page n’existe plus » ou « Vous avez pris un mauvais tournant ».
- Une barre de recherche interne, pour permettre à l’utilisateur de retrouver rapidement ce qu’il cherchait.
- Des liens vers les contenus les plus populaires ou les plus récents : cela redirige vers des articles à forte valeur ou des pages de destination bien travaillées.
- Un menu contextuel ou des catégories principales, pour orienter le visiteur selon ses centres d’intérêt ou l’architecture éditoriale du site.
- Un bouton de retour à la page d’accueil ou à une page de catégorie, pour relancer la navigation générale.
- Un design cohérent avec l’univers graphique du site, pour ne pas créer une rupture visuelle brutale et maintenir la confiance.
Dans certains cas, on peut aussi aller plus loin :
- Proposer un formulaire de signalement d’erreur, pour améliorer la qualité des liens internes ;
- Afficher les dernières publications ou les promotions en cours ;
- Suivre les performances de la page 404 dans les outils d’analytique, afin d’identifier les URLs les plus souvent en erreur et les points d’amélioration du maillage.
Impact SEO indirect et bonnes pratiques techniques
Une bonne page 404 ne doit pas être redirigée vers une page 200 (ce qui tromperait les moteurs), ni renvoyer une erreur 200 par défaut. Elle doit répondre avec le code HTTP 404 ou, dans le cas d’un contenu supprimé de manière volontaire, un 410 Gone si l’on souhaite indiquer que la suppression est permanente.
Voici quelques bonnes pratiques complémentaires :
- Surveiller les erreurs 404 dans la Search Console, pour détecter les URLs les plus touchées et mettre en place des redirections 301 vers des pages pertinentes lorsque c’est justifié ;
- Éviter les chaînes de redirections aboutissant à une 404, ce qui gaspille le budget crawl et peut affecter l’exploration globale du site ;
- Limiter l’apparition de liens cassés à travers un audit de maillage interne régulier ;
- Mettre à jour régulièrement la 404 pour refléter l’actualité du site (offres en cours, nouveaux articles, contenus saisonniers, etc.).
Une page 404 réalisée (en vue d’une redirection future) est un levier de réengagement, un garde-fou technique, et un outil au service de la cohérence éditoriale du site. Elle participe à la rétention du trafic, améliore l’exploration du site par les robots, et contribue à la qualité globale de l’expérience utilisateur. Dans une stratégie SEO complète, elle ne doit jamais être laissée au hasard.

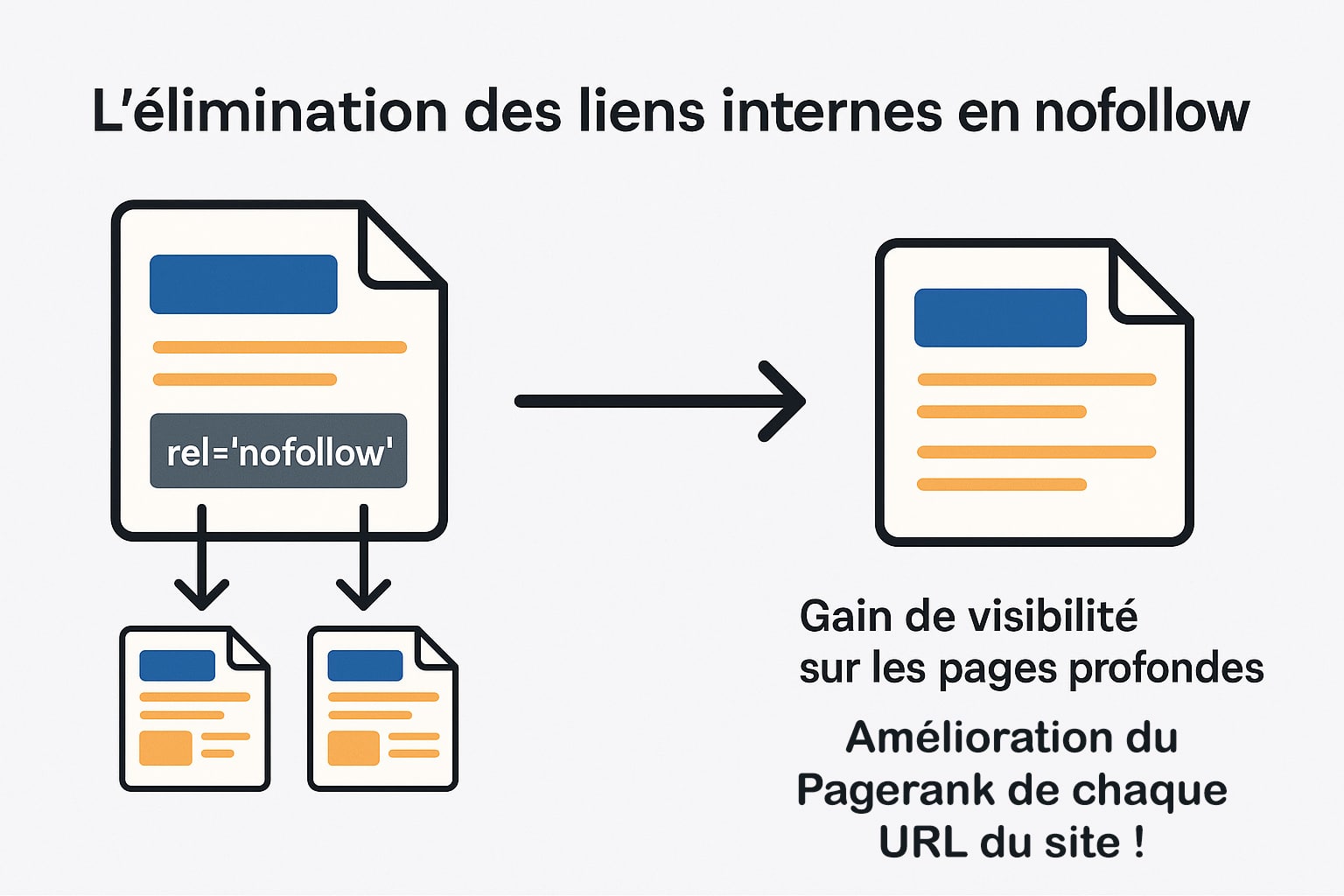
L’élimination des liens internes en nofollow
Le maillage interne est l’un des piliers fondamentaux du SEO technique. Il permet non seulement de structurer la navigation d’un site, mais aussi de répartir efficacement la popularité entre les différentes pages via la circulation du PageRank. Dans ce contexte, l’usage de l’attribut rel="nofollow" sur les liens internes est une pratique à manier avec une extrême prudence, car elle peut entraver la diffusion naturelle de l’autorité interne et nuire à l’exploration du site par les robots. L’attribut nofollow a historiquement été conçu pour signaler aux moteurs de ne pas suivre un lien, notamment dans les cas de liens sponsorisés, de commentaires non modérés, ou de contenus que l’éditeur du site ne souhaite pas cautionner. Son application sur des liens internes, en revanche, prive volontairement les pages ciblées de signaux SEO essentiels. Utilisé de manière excessive, ce balisage peut générer des effets contre-productifs :
- Les pages liées en
nofollowpeuvent ne jamais être explorées ni indexées correctement, en particulier si elles ne reçoivent pas d’autres liens endofollow; - Le PageRank interne cesse de circuler vers ces pages, qui peuvent alors devenir invisibles dans les SERP ;
- La structure de site devient artificiellement fermée, limitant la découverte de contenus profonds ou stratégiques ;
- Les efforts de contenu sur certaines pages (produits, articles, guides) peuvent rester sans effet SEO, faute de transmission d’autorité.
Pourquoi certaines équipes utilisent encore nofollow en interne ?
Par le passé, certaines recommandations ont circulé autour de la « concentration » du PageRank sur les pages principales d’un site, en empêchant sa diffusion vers les pages jugées secondaires (mentions légales, CGV, filtres, comptes clients, etc.). Cette stratégie, appelée PageRank sculpting, est aujourd’hui considérée comme obsolète, car Google ne redistribue plus le PageRank uniquement entre les liens dofollow. Les liens en nofollow sont simplement exclus du calcul, ce qui peut créer des pertes nettes de potentiel SEO.
Comment corriger une mauvaise utilisation du nofollow en interne ?
Une optimisation technique efficace consiste à :
- Auditer l’ensemble des liens internes à l’aide d’outils comme Screaming Frog ou Sitebulb, pour repérer ceux comportant l’attribut
rel="nofollow"; - Identifier la justification initiale de ces balisages : s’agit-il de liens de navigation, de pagination, de filtres, ou de vrais contenus stratégiques ?
- Supprimer l’attribut
nofollowsur tous les liens menant à des pages utiles pour l’utilisateur et pour le SEO (fiches produits, catégories, articles, pages à longue traîne, etc.) ; - Réorganiser le maillage interne en priorisant les liens contextuels (intégrés dans les paragraphes) plutôt que les liens globaux ou répétés (menus, footers, blocs latéraux) ;
- Ne conserver le
nofollowque dans des cas très spécifiques et justifiés (par exemple, liens vers des pages de déconnexion, ou des URLs techniques sans intérêt SEO).
Quels bénéfices attendre de cette optimisation ?
La remise en dofollow des liens internes vers des pages profondes permet :
- une meilleure exploration par les robots, notamment des contenus anciens ou moins accessibles via la navigation principale ;
- une redistribution plus naturelle du PageRank, favorisant les pages à fort potentiel de conversion ou de réponse aux intentions de recherche ;
- un gain de visibilité sur les requêtes de longue traîne, souvent portées par des pages périphériques mais pertinentes ;
- un renforcement de la cohérence sémantique interne du site, via une interconnexion plus fluide des contenus liés entre eux ;
- une expérience utilisateur enrichie, car les visiteurs accèdent à davantage de contenus utiles sans rupture dans le parcours de navigation.
Éliminer l’usage non justifié de nofollow sur les liens internes permet de restaurer la fluidité naturelle du maillage, d’optimiser l’exploration et l’indexation du site, et de donner à chaque page la possibilité de capter son potentiel SEO réel. Cette optimisation technique, discrète mais puissante, constitue une étape clé dans la construction d’un écosystème SEO solide et évolutif.
L’amélioration du code HTML et la suppression du JavaScript bloquant
Dans l’univers du SEO technique, la qualité du code source joue un rôle fondamental pour garantir l’accessibilité, l’exploration et l’indexation des contenus par les moteurs de recherche. Lorsqu’un site repose massivement sur JavaScript pour afficher ses informations principales — titres, paragraphes, listes, boutons, menus, etc. — il devient plus complexe à interpréter pour les robots, en particulier si ces contenus ne sont pas présents dans le HTML initial.
Bien que Google soit capable d’exécuter le JavaScript dans une large mesure, ce rendu n’est ni instantané ni systématique. Il intervient dans un second temps après le crawl, ce qui introduit un décalage dans l’indexation et une incertitude sur la visibilité réelle du contenu.
Les effets négatifs du JavaScript bloquant
Un site fortement dépendant de JavaScript pour afficher des sections clés peut rencontrer plusieurs types de problèmes (Voir notre sujet sur Ajax) :
- Contenu non indexé ou partiellement lu si Googlebot ne parvient pas à exécuter correctement les scripts (temps trop long, erreurs JS, blocages de ressources) ;
- Allongement du temps de rendu, ce qui affecte à la fois les Core Web Vitals et la capacité de crawl ;
- Perte d’opportunités SEO : une page perçue comme vide ou incomplète ne peut pas se positionner efficacement, même si son contenu est pertinent ;
- Problèmes de compatibilité mobile si le rendu JS diffère entre les navigateurs ou plateformes, avec un risque accru d’erreurs de structure ou de mise en page ;
- Diminution du budget de rendu : Google alloue un volume limité de ressources à chaque site pour le rendu JavaScript, ce qui pénalise les sites peu optimisés ou trop complexes.
Une approche technique centrée sur l’accessibilité HTML
Pour contourner ces limites, une démarche d’optimisation consiste à réduire au maximum la dépendance au JavaScript pour les contenus critiques et à s’assurer que les informations essentielles sont directement intégrées dans le HTML initial. Cette approche améliore considérablement la lisibilité algorithmique et la vitesse de chargement perçue. Voici les optimisations recommandées :
- Transformer les blocs critiques en HTML statique : les sections comme les titres, paragraphes descriptifs, boutons de navigation, contenus éditoriaux ou blocs produits doivent être visibles sans interaction ni rendu différé ;
- Déporter les scripts JavaScript en fin de page (
</body>) pour ne pas bloquer le rendu initial. Cela garantit que le HTML s’affiche en priorité, et que l’exécution JS n’interfère pas avec la lecture du contenu ; - Utiliser les attributs
deferouasyncpour les scripts non critiques, afin d’en optimiser le chargement sans retarder l’analyse du DOM ; - Mettre en place une gestion conditionnelle du JS : ne charger certains composants interactifs (carrousels, animations, filtres) qu’après l’affichage du contenu principal ;
- Vérifier la compatibilité du contenu avec Googlebot via l’outil d’inspection de la Search Console, afin de s’assurer que le contenu affiché est bien visible par le crawler.
Nettoyage et hiérarchisation du code HTML
En parallèle de l’optimisation JavaScript, une amélioration du code HTML renforce la structuration sémantique du site. Cela implique :
- Le bon usage des balises structurantes (
<header>,<main>,<article>,<section>,<footer>) ; - La hiérarchie correcte des titres (
<h1>➝<h2>➝<h3>…), sans sauts ni répétitions de niveaux ; - L’optimisation des attributs ALT pour les images, des balises
<meta>pour les descriptions, et des balises<a>pour les liens textuels internes ; - La suppression du code mort, des balises redondantes et des scripts inutilisés qui alourdissent la page sans valeur ajoutée.
Impacts positifs sur l’indexation et l’expérience utilisateur
Les effets combinés de ces optimisations techniques sont nombreux :
- Amélioration de la vitesse d’affichage, critère important pour les Core Web Vitals (LCP, FID, CLS) ;
- Meilleure accessibilité du contenu pour les moteurs de recherche, et donc une indexation plus rapide et plus complète ;
- Renforcement de la compatibilité mobile, car le rendu devient plus cohérent sur tous les appareils ;
- Réduction du taux de rebond sur les pages où l’information est visible immédiatement, sans latence ni interaction requise ;
- Stabilisation du budget de crawl et de rendu, en éliminant les obstacles techniques à l’analyse complète du site par Googlebot.
Ainsi, une architecture technique allégée, combinée à un HTML propre et bien structuré, constitue l’un des fondements d’un SEO pérenne. Cette démarche ne se résume pas à une simple correction de bugs ou à une optimisation de performance, mais à une véritable stratégie d’accessibilité algorithmique, qui favorise la compréhension du contenu, la diffusion du PageRank, et la compétitivité du site dans les résultats naturels.

Ces nombreux exemples démontrent que le SEO technique est une discipline concrète, stratégique et directement liée à la performance d’un site dans les résultats de recherche. En allant bien au-delà de la seule optimisation de la vitesse, il agit sur la structure, le code, l’architecture, la sémantique, la lisibilité algorithmique et la gestion du budget crawl. Chaque correction technique peut représenter un levier de croissance organique, à condition qu’elle soit pensée dans une logique globale et priorisée selon l’impact.

0 commentaires