Un moteur de recherche fonctionne comme un lecteur particulièrement rigoureux et lorsqu’il analyse une page web, il ne se contente pas d’identifier des mots isolés. Il cherche à saisir les concepts, à relier les termes entre eux et à interpréter les subtilités du langage. C’est dans cette logique que le champ lexical et le champ sémantique prennent toute leur importance : Deux notions complémentaires, au cœur d’une stratégie SEO efficace. Analyser le champ lexical SEO d’une page revient à bien plus qu’une simple détection de mots-clés. Il s’agit de décortiquer l’ensemble des mots et expressions qui entourent un sujet, d’évaluer leur pertinence et de comprendre comment ils contribuent à une structure sémantique cohérente. Pour cela, il est utile de s’appuyer sur des techniques issues du traitement automatique du langage, comme la lemmatisation, la racinisation ou encore l’analyse des cooccurrences.
Ce guide vous accompagne étape par étape dans cette démarche, afin d’optimiser le contenu de vos pages pour un référencement naturel plus structuré, plus intelligent et plus pérenne.
Comprendre la différence entre champ lexical et champ sémantique
Avant d’entrer dans les méthodologies d’analyse, il est fondamental de bien différencier deux concepts linguistiques souvent confondus dans les stratégies SEO : Le champ lexical et le champ sémantique. Ces deux notions jouent un rôle complémentaire dans la manière dont les moteurs de recherche évaluent la pertinence et la cohérence d’une page web par rapport à une intention de recherche :
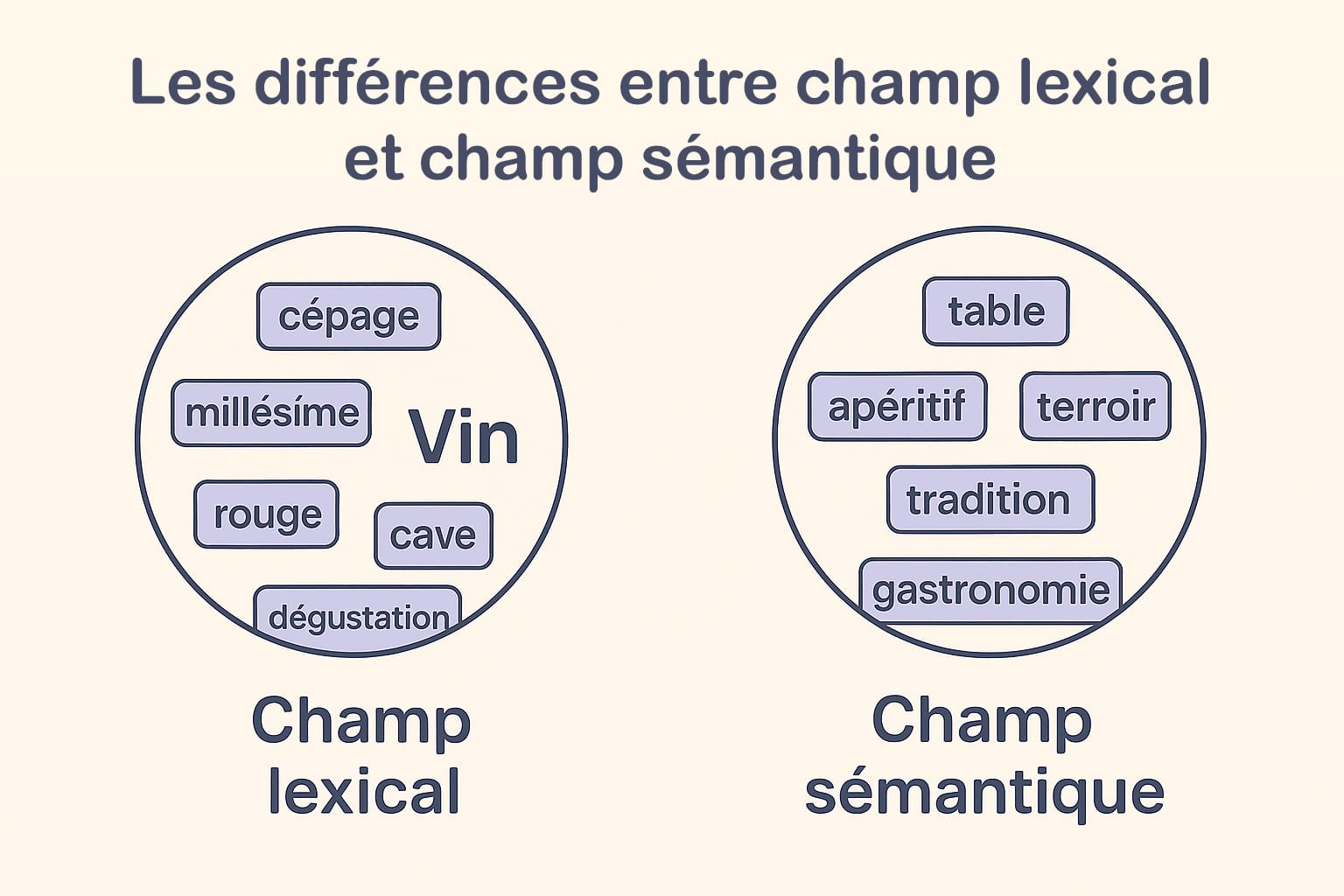
- Le champ lexical désigne un ensemble de mots appartenant à une même catégorie thématique, directement associés à un sujet central. Il repose sur une relation de proximité linguistique formelle. Prenons l’exemple du thème « vin » : les termes « cépage », « cave », « millésime », « dégustation », « rouge », « blanc », « tannique » relèvent du champ lexical. Ils partagent une appartenance directe à l’univers œnologique et peuvent être facilement catégorisés selon leur usage dans des corpus spécialisés. Le champ lexical peut inclure des noms, des adjectifs, des verbes et des expressions figées qui se rattachent concrètement à un même domaine ;
- Le champ sémantique, quant à lui, est plus vaste et plus souple. Il englobe tous les mots, expressions ou concepts qui entretiennent une relation de sens (explicite ou implicite) avec l’idée centrale. Il s’agit d’un ensemble sémantique élargi, qui intègre non seulement les synonymes et antonymes, mais aussi les associations culturelles, les connotations, les implicites contextuels, les relations hyponymiques (du général au particulier), hyperonymiques (du particulier au général), et les cooccurrences. Pour le thème « vin », le champ sémantique pourrait inclure « gastronomie », « terroir », « convivialité », « apéritif », « table », ou encore « tradition », autant de notions périphériques qui enrichissent la compréhension globale du sujet sans être lexicalement rattachées au vocabulaire technique du vin.
En SEO, cette distinction a des implications importantes. Le champ lexical est utile pour ancrer un contenu dans une thématique spécifique à l’aide de termes précis et attendus. Le champ sémantique, lui, permet d’enrichir le discours pour couvrir l’ensemble des attentes potentielles d’un internaute ou d’un moteur de recherche sur un sujet donné. Plus un texte est capable d’intégrer ces deux dimensions, plus il gagne en pertinence, en profondeur et en lisibilité algorithmique.
Les moteurs de recherche modernes, notamment Google avec des technologies comme BERT (Bidirectional Encoder Representations from Transformers) et MUM (Multitask Unified Model), ne s’appuient plus uniquement sur la densité ou la répétition de mots-clés. Ces modèles de traitement du langage naturel (NLP) analysent le contenu selon sa richesse sémantique, c’est-à-dire sa capacité à évoquer un sujet dans toute sa complexité linguistique, tout en maintenant une logique de sens fluide. Cela signifie qu’un texte bien optimisé ne doit pas uniquement « parler » d’un sujet, mais le « déployer » dans toutes ses dimensions lexicales et contextuelles.
Pour le rédacteur ou l’analyste SEO, cela implique une nouvelle approche : il ne suffit plus d’intégrer quelques mots-clés bien choisis. Il faut construire un univers lexical cohérent, capable de répondre à une intention de recherche tout en s’inscrivant dans l’ensemble sémantique qui gravite autour du thème ciblé. Cette démarche suppose une analyse linguistique approfondie, des outils adaptés, et une compréhension fine des relations entre les mots, leurs usages et leurs significations dans un environnement donné.
Les techniques d’analyse linguistique appliquées au SEO
Pour analyser le champ lexical et sémantique d’une page, on s’appuie sur plusieurs techniques issues du traitement automatique du langage (NLP). Voici les principales méthodes à connaître pour mener une analyse SEO de qualité.
1. La lemmatisation
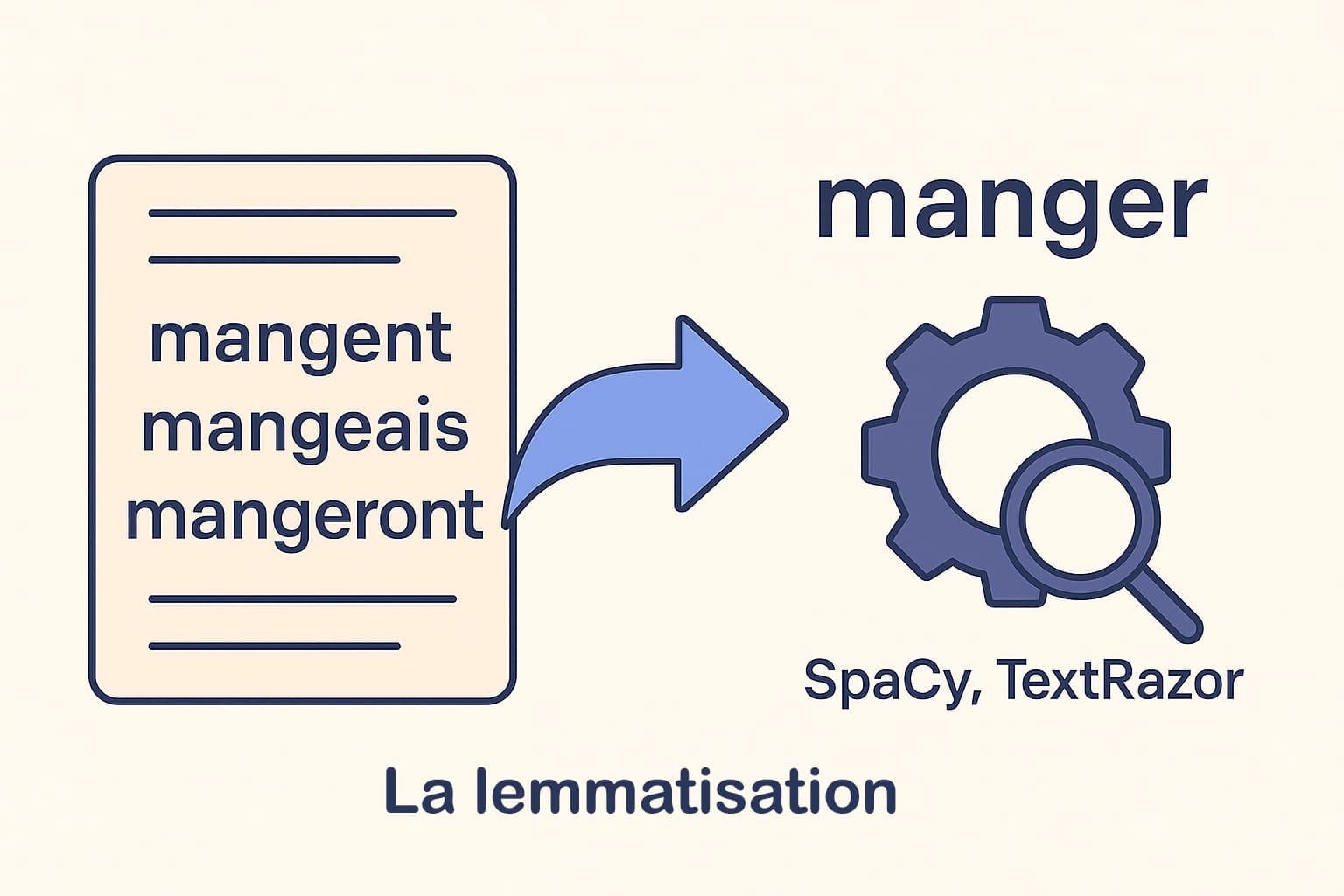
La lemmatisation est un processus linguistique qui consiste à ramener chaque mot à sa forme de base, appelée lemme. Le lemme représente l’unité lexicale de référence dans les dictionnaires. Par exemple, les mots « mangent », « mangeais », « mangeront », « mangeons » ou « mangé » partagent tous le même lemme : « manger ». Contrairement à une simple analyse basée sur les mots bruts (tokens), la lemmatisation permet d’unifier toutes les variantes grammaticales d’un mot sous une seule et même forme. Dans le cadre d’une analyse SEO, cette normalisation est précieuse. Elle permet d’éviter une distorsion des données due aux flexions verbales, aux accords en genre et en nombre, ou aux conjugaisons. Sans lemmatisation, un outil d’analyse pourrait considérer « mange », « mangé » et « mangent » comme trois mots différents, alors qu’ils expriment le même concept. Cela fausse les résultats de fréquence et dilue la perception réelle du champ lexical.
Les moteurs de traitement du langage naturel comme SpaCy ou TextRazor intègrent des modules de lemmatisation avancés, capables de gérer les subtilités linguistiques en français (et dans d’autres langues). Ces outils s’appuient sur des modèles linguistiques entraînés pour identifier le lemme en fonction du contexte syntaxique. En SEO, leur utilisation permet d’obtenir une vision plus fine et plus fidèle du vocabulaire réellement utilisé sur une page. Appliquer la lemmatisation dans une analyse lexicale permet donc de :
- consolider les occurrences d’un même concept malgré les variations morphologiques ;
- améliorer la qualité des statistiques lexicales (fréquences, cooccurrences, TF-IDF) ;
- renforcer la pertinence des recommandations sémantiques pour la réécriture SEO ;
- aligner les résultats sur la logique de compréhension des moteurs de recherche modernes.
La lemmatisation est ainsi une étape incontournable lorsqu’on souhaite analyser en profondeur le langage utilisé dans un contenu web, et le comparer efficacement à celui des concurrents ou aux attentes sémantiques d’un mot-clé donné.
2. La racinisation (stemming)
La racinisation, ou stemming en anglais, est une méthode de traitement du langage naturel qui consiste à réduire les mots à leur racine morphologique, c’est-à-dire à un tronc commun qui ne correspond pas nécessairement à un mot existant. Contrairement à la lemmatisation, qui tient compte du contexte grammatical pour restituer une forme lexicale correcte, la racinisation applique des règles simples de découpage ou de suppression de suffixes afin d’identifier une base partagée.
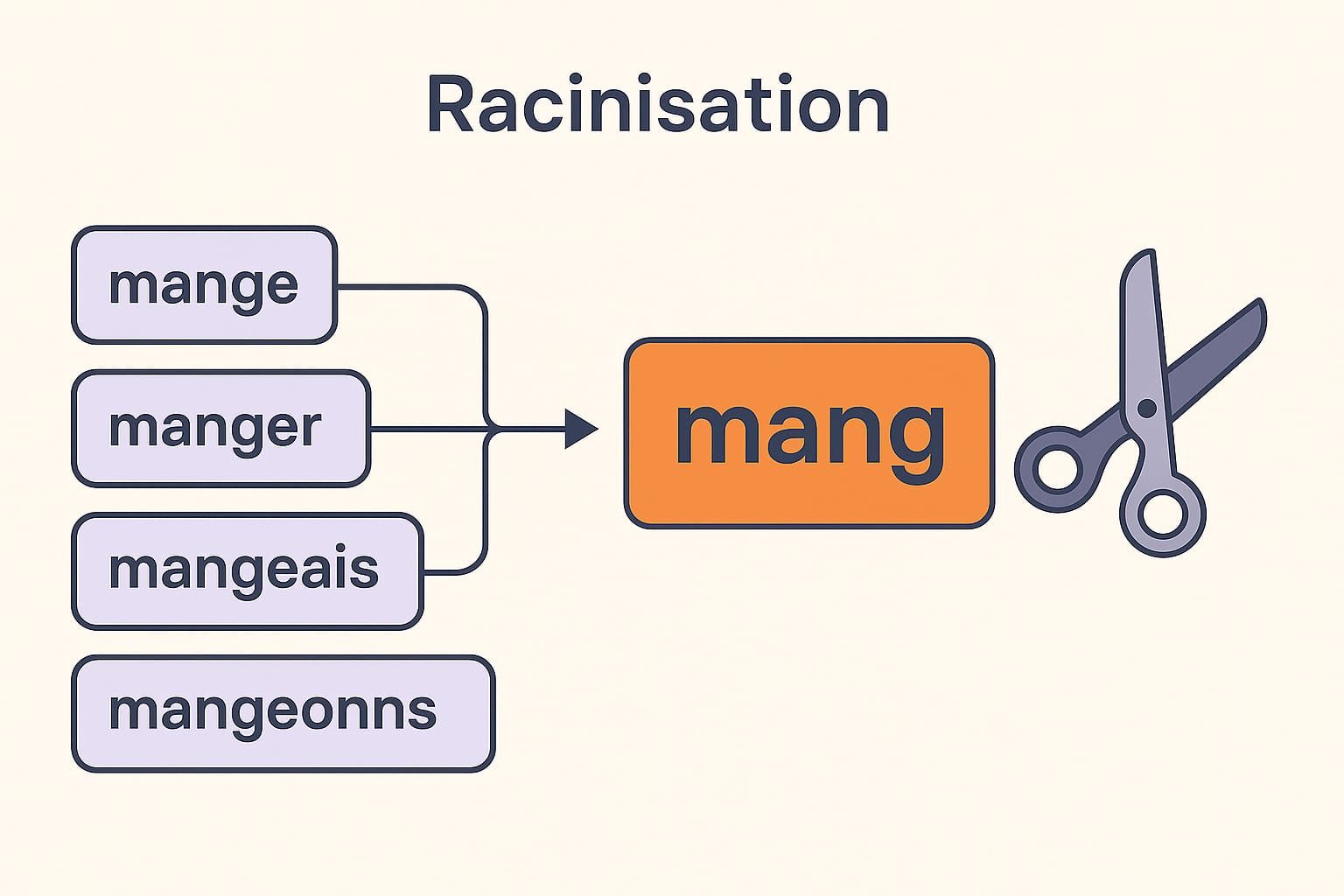
Par exemple, les formes « mange », « manger », « mangeais », « mangeons », « mangé » peuvent être toutes réduites à une racine commune telle que « mang ». Cette opération permet de regrouper rapidement des variantes lexicales dans une seule catégorie, facilitant ainsi l’analyse statistique sur des corpus volumineux.
Cette approche est particulièrement utile pour :
- accélérer le traitement de grandes quantités de textes ;
- réaliser des analyses exploratoires où la précision linguistique est moins prioritaire ;
- détecter les tendances lexicales générales dans un domaine donné ;
- préparer un prétraitement avant une étape de classification ou de clustering de documents.
Des algorithmes de racinisation bien connus comme le Porter Stemmer, Snowball Stemmer ou Lancaster Stemmer sont souvent utilisés dans des bibliothèques NLP telles que NLTK, SpaCy (via des extensions), ou dans des moteurs de recherche comme ElasticSearch.
Cependant, cette technique présente également des limites importantes en SEO :
- Elle peut produire des « racines » qui ne correspondent à aucun mot réel, rendant l’interprétation plus complexe (ex. : « relation », « relationnel », « relatif » → « rel ») ;
- Elle ne prend pas en compte les relations grammaticales ou syntaxiques, ce qui peut entraîner des pertes de sens ou des confusions sémantiques ;
- Elle est moins adaptée aux analyses de contenus où la précision linguistique est essentielle, notamment lorsqu’on cherche à affiner le champ sémantique ou à comparer des pages de qualité éditoriale élevée.
3. L’analyse des cooccurrences
L’analyse des cooccurrences est une technique de linguistique quantitative qui mesure la fréquence avec laquelle deux mots apparaissent à proximité l’un de l’autre dans un même corpus, une phrase, un paragraphe ou une unité textuelle définie. Cette méthode est largement utilisée dans le traitement automatique du langage naturel (NLP) pour détecter des associations lexicales fortes, souvent révélatrices de relations sémantiques ou thématiques sous-jacentes. En SEO, cette analyse permet d’identifier les groupes de mots régulièrement associés dans les contenus bien positionnés sur un sujet donné. Elle met en évidence les termes qui, au-delà de leur présence individuelle, participent ensemble à la construction d’un champ lexical cohérent et pertinent aux yeux des moteurs de recherche.
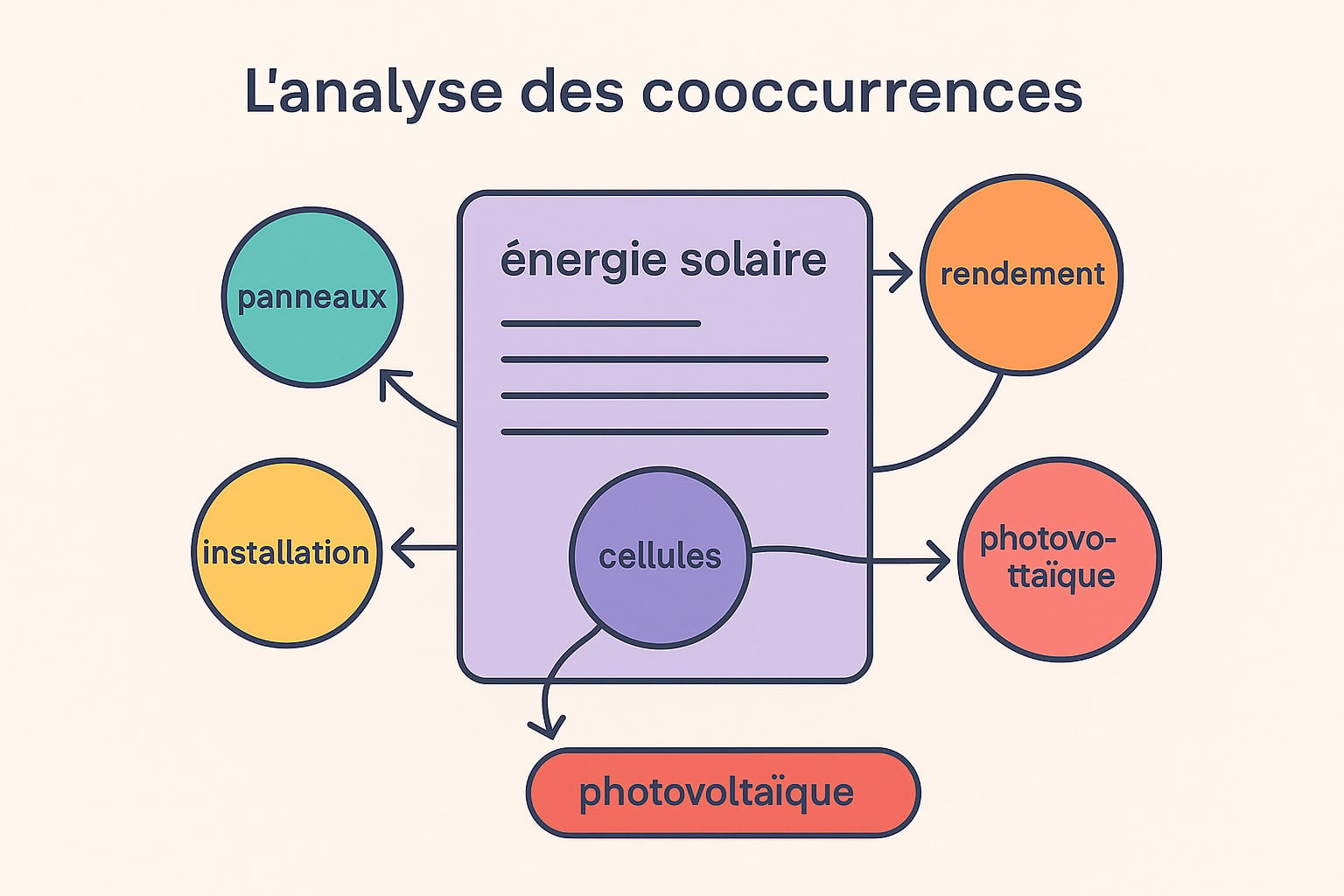
Par exemple, sur une page ciblant le mot-clé « énergie solaire », on attend la présence de cooccurrences telles que : « photovoltaïque », « panneaux », « cellules », « rendement », « autonomie », « installation », « production », « orientation ». Ce faisceau de termes permet de renforcer la cohérence lexicale du contenu. Leur fréquence conjointe et leur proximité contextuelle indiquent aux moteurs que la page développe réellement le sujet dans sa globalité. Cette méthode présente plusieurs avantages dans une stratégie SEO :
- elle révèle les attentes lexicales implicites autour d’un mot-clé principal ;
- elle permet de détecter les manques sémantiques dans un contenu existant ;
- elle aide à structurer des contenus plus riches et alignés avec les pratiques rédactionnelles des pages bien classées ;
- elle oriente l’optimisation fine des paragraphes, titres et intertitres en fonction des combinaisons de termes attendues.
Techniquement, l’analyse des cooccurrences peut se faire à l’aide d’outils spécialisés ou via des scripts personnalisés utilisant des bibliothèques comme NLTK, SpaCy ou Gensim. Certains outils SEO avancés tels que SEOQuantum, 1.fr ou YourText.Guru intègrent des analyses sémantiques reposant sur des modèles de cooccurrence pondérés (par exemple avec les algorithmes PMI, PPMI ou Word2Vec).
Il est également possible de visualiser ces relations à l’aide de graphes lexicaux, où les nœuds représentent les mots et les arêtes leur fréquence de cooccurrence. Ces représentations aident à cartographier l’univers sémantique d’un sujet et à identifier les termes « isolés » qui mériteraient d’être renforcés par des associations contextuelles plus denses.
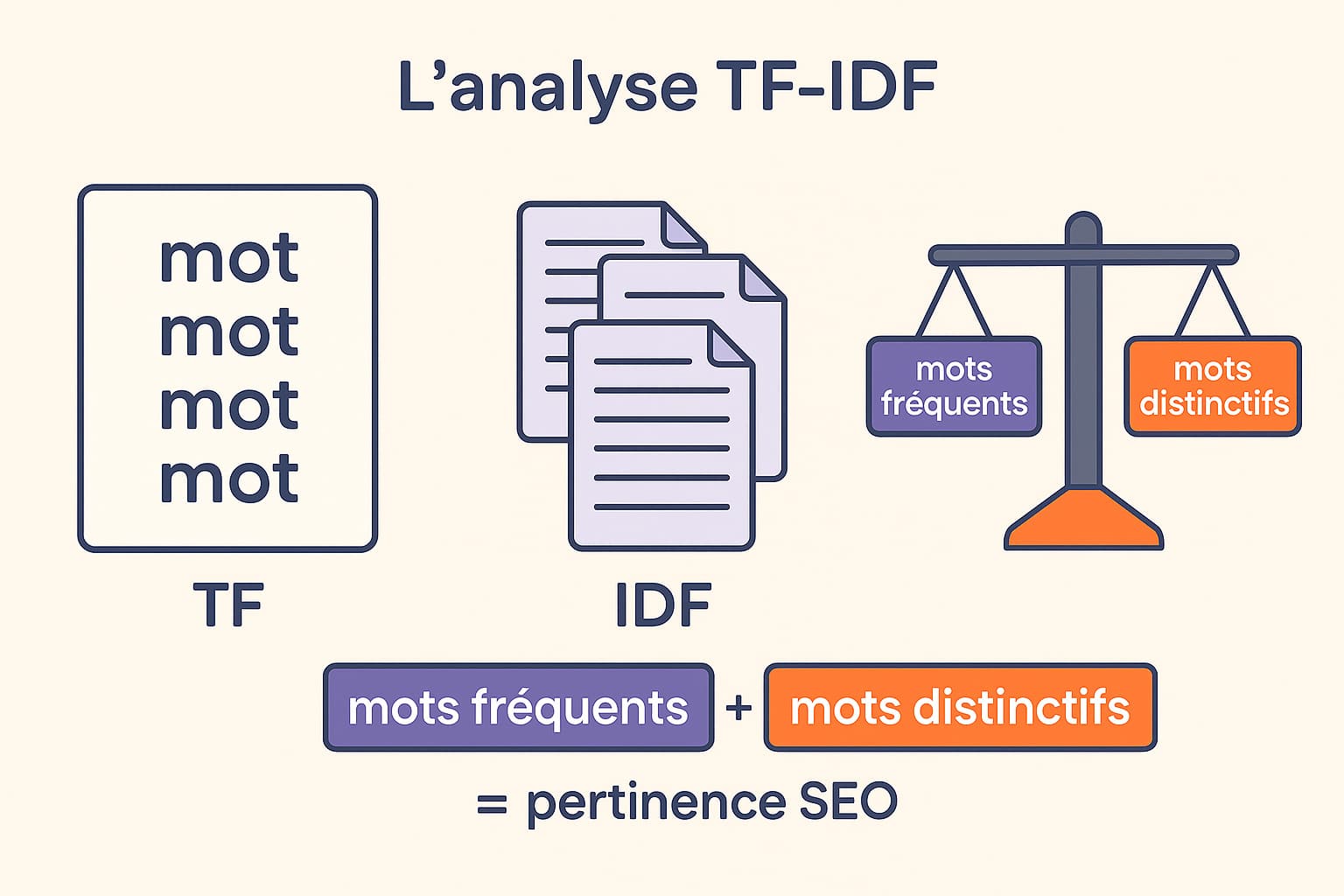
4. L’analyse TF-IDF
La méthode TF-IDF (Term Frequency – Inverse Document Frequency) est une technique d’analyse textuelle issue de la recherche en traitement de l’information. Elle vise à évaluer le poids relatif d’un mot dans un document donné, en prenant en compte sa fréquence d’apparition dans le document (TF) et sa rareté à l’échelle d’un ensemble de documents de référence (IDF). Concrètement :
- TF (Term Frequency) mesure le nombre de fois qu’un terme apparaît dans un document. Plus un mot est fréquent, plus il est considéré comme représentatif du contenu.
- IDF (Inverse Document Frequency) pondère cette fréquence en fonction du nombre de documents où le mot apparaît. Si un mot est très courant dans l’ensemble du corpus (ex. : « le », « et », « produit »), sa valeur IDF sera faible. En revanche, un mot rare dans le corpus aura un IDF élevé.
La combinaison des deux donne un score TF-IDF qui met en avant les termes à la fois fréquents dans une page et distinctifs par rapport au reste du corpus. Cela en fait un excellent outil pour identifier les mots véritablement porteurs de sens dans un contenu donné.
Dans une approche SEO, TF-IDF présente plusieurs avantages stratégiques :
- il permet de repérer les termes sous-utilisés dans une page par rapport aux contenus bien positionnés sur la même thématique ;
- il aide à détecter les mots surutilisés qui pourraient signaler une suroptimisation (keyword stuffing) ;
- il facilite l’ajustement lexical d’un contenu en vue d’atteindre une meilleure couverture sémantique ;
- il offre une comparaison objective avec les pages concurrentes, fondée sur des données quantitatives.
Cette méthode est aujourd’hui intégrée dans plusieurs outils SEO avancés, comme Textfocus, Seolyzer, SEOQuantum, ou encore YourText.Guru, qui permettent de visualiser les écarts lexicaux entre votre page et celles en haut des résultats Google. Ces plateformes génèrent des tableaux comparatifs de scores TF-IDF, soulignant les mots à renforcer, à ajouter ou à modérer.
Certains outils vont encore plus loin en intégrant des modèles vectoriels (comme Word2Vec ou BERT) pour compléter l’analyse TF-IDF par une interprétation sémantique des mots. Cela permet d’identifier non seulement les mots-clés manquants, mais aussi les concepts proches ou les termes synonymes qui enrichiraient la pertinence thématique du contenu.
Enfin, l’analyse TF-IDF peut être utilisée en combinaison avec la lemmatisation pour obtenir des résultats encore plus fiables : En ramenant les mots à leur forme canonique avant d’évaluer leur poids, on évite les biais liés aux variations grammaticales.
Les étapes pour analyser le champ lexical SEO d’une page
L’analyse du champ lexical SEO d’une page suit une série d’étapes structurées, mêlant extraction de données, traitement linguistique et comparaison concurrentielle. Chaque phase apporte un éclairage complémentaire pour affiner la compréhension du contenu analysé, détecter les points faibles, et renforcer la pertinence sémantique d’un texte aux yeux des moteurs de recherche. Voici une méthode opérationnelle en cinq grandes étapes :
| Étape | Détails et outils recommandés |
|---|---|
| 1. Extraire le contenu | Il s’agit de récupérer le contenu textuel brut des pages web à analyser, en excluant les éléments non pertinents (menus, footers, scripts, balises inutiles). Cette extraction peut être réalisée de manière manuelle pour de petits volumes, ou automatisée à l’aide d’outils comme : — Screaming Frog : pour crawler l’ensemble des pages et extraire les blocs HTML spécifiques — Sitebulb : pour auditer en profondeur la structure et le contenu — BeautifulSoup (Python) : pour des extractions personnalisées sur mesure |
| 2. Nettoyer et lemmatiser | Une fois le contenu extrait, il est essentiel de nettoyer le texte des éléments parasites (liens de navigation, mentions légales, publicités) avant d’appliquer une lemmatisation. Cette étape permet de regrouper les variantes grammaticales sous une forme canonique commune, afin d’unifier l’analyse. Outils utiles : — SpaCy : NLP performant, idéal pour lemmatiser des corpus complets — NLTK : pour des traitements linguistiques fins — Voyant Tools : pour un nettoyage rapide et une analyse de base |
| 3. Analyser la fréquence | Cette étape vise à repérer les mots et expressions les plus utilisés dans le contenu. Le comptage des fréquences permet de dégager les thématiques principales abordées dans la page, et de détecter les champs lexicaux dominants ou absents. Pour ce faire, on utilise des outils tels que : — Excel ou Google Sheets : pour un tri manuel des mots — Voyant Tools : pour des nuages de mots et des graphes de distribution — AntConc : pour des analyses lexicales plus précises sur de grands volumes |
| 4. Comparer à la concurrence | Il est stratégique de confronter son propre champ lexical avec celui des pages qui se positionnent déjà sur les mêmes intentions de recherche. Cette comparaison permet de repérer les termes absents, les champs sémantiques non couverts, ou encore les axes thématiques exploités par les concurrents. Outils recommandés : — 1.fr : pour une note sémantique comparative et des suggestions lexicales — YourText.Guru : pour visualiser les univers lexicaux dominants sur une requête — SEOQuantum : pour comparer les contenus à grande échelle et analyser la profondeur sémantique |
| 5. Mesurer la couverture sémantique | Enfin, il est essentiel d’évaluer dans quelle mesure la page couvre les différents aspects lexicaux et sémantiques attendus. Cette mesure passe par des indicateurs comme le score TF-IDF, les clusters thématiques, ou les cooccurrences. Elle permet de juger de la richesse du contenu par rapport aux pages concurrentes. À ce stade, on peut utiliser : — Textfocus : pour détecter les manques sémantiques — Seolyzer : pour croiser les données d’analyse avec les logs SEO — outils TF-IDF intégrés dans des plateformes comme SEOQuantum ou YourText.Guru |
Une fois cette analyse terminée, plusieurs actions concrètes peuvent être engagées pour optimiser le contenu :
- La réécriture des paragraphes clés comme les descriptions de fiches produits afin d’y intégrer des termes manquants ou mal exploités tout en respectant la fluidité de lecture ;
- L’ajout de nouvelles sections pour développer des sous-thèmes détectés dans les contenus concurrents ou suggérés par les analyses de cooccurrence ;
- La révision des balises HTML stratégiques comme les balises
<title>,<meta description>, ou les balises Hn, en y intégrant un vocabulaire plus riche et mieux ciblé ; - L’optimisation du maillage interne SEO en reliant les pages traitant de thématiques proches via des ancres textuelles sémantiquement pertinentes ;
- La création de contenus complémentaires (pages piliers, FAQ, glossaires, articles associés) pour renforcer la couverture sémantique globale du site.
En suivant cette méthode rigoureuse, il devient possible de transformer une simple page informative en un contenu stratégique, bien ancré dans son champ lexical, adapté aux intentions de recherche, et apte à rivaliser avec les meilleures pages du secteur.

0 commentaires