Vous ouvrez une page web de votre site Internet, et là… catastrophe : des points d’interrogation à la place des accents, des caractères chinois improbables, ou encore des symboles « � » qui ne devraient pas être là. Ces petits signes d’incompréhension ne sont pas dus à une simple faute de frappe : ce sont les symptômes d’un problème d’encodage des caractères. Sur un site existant, surtout s’il a été migré, modifié ou maintenu par plusieurs mains, les erreurs d’encodage sont fréquentes et souvent difficiles à isoler. Heureusement, il existe une méthode rigoureuse pour diagnostiquer ces anomalies et les corriger durablement. Voici un guide complet pour les repérer, les comprendre et les éliminer avec des outils adaptés.
- Les aspects classiques d’un encodage défaillant
- Les outils indispensables pour diagnostiquer les erreurs d’encodage
- Les étapes pour corriger les erreurs d’encodage du site Web
- 1. Vérifier ou ajouter la balise <meta charset= »UTF-8″> dans le HTML
- 2. Aligner l’encodage serveur HTTP
- 3. Corriger l’encodage des fichiers sources
- 4. Modifier l’encodage des tables ou colonnes de la base de données
- 5. Vérifier les connexions entre l’application et la base
- 6. Vider le cache navigateur et serveur
Les aspects classiques d’un encodage défaillant
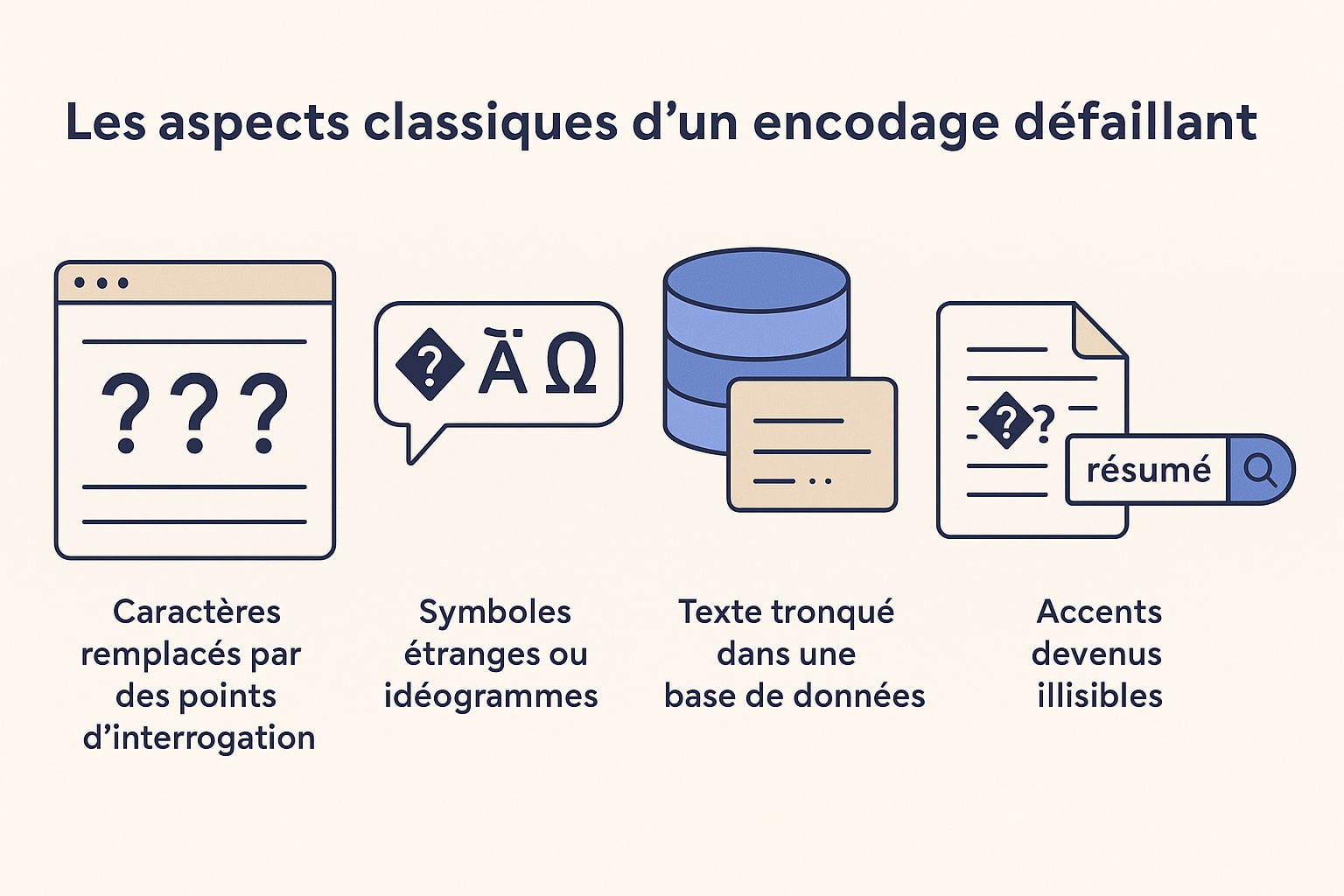
Avant toute chose, il faut savoir reconnaître une erreur dans le code source, car ce type de dysfonctionnement peut passer inaperçu si l’on ne sait pas en lire les signes. Pourtant, une page web dont l’encodage est incorrect donne des signaux assez explicites une fois qu’on sait les repérer. Ces erreurs peuvent se manifester de différentes manières, parfois discrètes, parfois flagrantes, sur le front-end ou dans les systèmes en coulisse.
- Affichage de caractères remplacés par des points d’interrogation, des losanges ou le symbole « � » : c’est le signe typique d’un caractère que le navigateur ou l’application ne parvient pas à interpréter selon l’encodage attendu ;
- Texte contenant des glyphes étranges, idéogrammes asiatiques ou signes mathématiques là où il devrait y avoir des caractères latins : cela peut arriver lorsque du texte encodé en UTF-8 est interprété comme de l’ISO-8859-1 ou du Windows-1252, ou l’inverse. L’octet binaire est lu de travers, produisant un caractère inattendu ;
- Chaînes tronquées dans une base de données, en particulier après un caractère accentué ou un emoji : cela se produit quand l’encodage ne permet pas de stocker l’ensemble du jeu de caractères. Par exemple, un champ en `utf8` dans MySQL ne supporte que jusqu’à 3 octets, ce qui peut poser problème avec certains symboles Unicode (qui en nécessitent 4) ;
- CSV, fichiers XML ou JSON mal exportés, avec des accents devenus illisibles : ce cas est fréquent lorsqu’un script d’export utilise un encodage différent de celui des données sources. L’utilisateur ouvrant le fichier dans Excel ou dans un éditeur texte voit alors des caractères altérés ;
- Résultats de recherche internes erronés ou incohérents : Un mot-clé accentué (comme « résumé ») pourrait ne pas trouver les résultats attendus s’il est mal encodé au moment de l’indexation ou de la requête SQL. Cela peut impacter l’expérience utilisateur de façon significative sans que l’erreur ne soit immédiatement visible dans l’interface.
Ces symptômes ne viennent pas nécessairement d’une seule erreur isolée. Ils sont bien souvent la conséquence d’un enchaînement de traitements incohérents entre les différentes couches techniques de votre site web :
- HTML : Balise
<meta charset="UTF-8">absente ou mal placée ; - Serveur HTTP : Absence de déclaration explicite du charset dans les entêtes envoyés aux navigateurs ;
- Base de données : Colonnes texte enregistrées dans un encodage trop limité (comme `latin1` ou `utf8` au lieu de `utf8mb4`) ;
- Scripts PHP ou JS : Encodage non précisé lors des échanges avec la base ou avec des fichiers ;
- Éditeurs de code : Fichiers enregistrés en ISO-8859-1, Windows-1252 ou UTF-8 avec BOM, sans que cela ne soit remarqué ;
- CMS ou plugins : Extensions mal développées introduisant des contenus ou des templates dans un encodage incohérent avec le reste du site
La difficulté, c’est que ces erreurs peuvent apparaître de manière sporadique. Une page affichera correctement ses accents, mais une autre non. Une phrase sera lisible côté visiteur, mais mal enregistrée dans la base. D’où l’importance d’une démarche structurée pour identifier chaque point de rupture dans la chaîne d’encodage.
Un site peut fonctionner « en apparence » pendant des mois avec un encodage partiellement incorrect, sans que personne ne s’en rende compte… jusqu’au jour où l’on veut y insérer un emoji, publier un contenu multilingue, ou exporter un flux RSS. Mieux vaut donc prévenir que guérir, en s’assurant que chaque couche repose sur une base saine et cohérente : UTF-8 sans ambiguïté.
Les outils indispensables pour diagnostiquer les erreurs d’encodage
Pour identifier l’origine du problème, il faut interroger le site à plusieurs niveaux. Voici les outils recommandés pour inspecter efficacement chaque couche :
1. Google Chrome DevTools ou Firefox Developer Tools
Les outils de développement intégrés aux navigateurs comme Chrome ou Firefox sont des alliés précieux pour analyser le comportement de votre site en temps réel. L’une des premières vérifications à effectuer concerne l’encodage réellement utilisé lors du chargement d’une page web. Pour cela, il faut inspecter les en-têtes HTTP envoyés par le serveur. Voici comment procéder :
- Ouvrez votre site dans Google Chrome (ou Firefox).
- Faites un clic droit n’importe où sur la page et sélectionnez « Inspecter » ou appuyez sur
F12. - Accédez à l’onglet « Réseau » (Network) dans la barre d’outils.
- Rafraîchissez la page avec
Ctrl + RouCmd + Rpour relancer toutes les requêtes réseau. - Repérez la ligne correspondant à la page principale (généralement l’URL de la page visitée, en haut de la liste).
- Cliquez dessus, puis ouvrez l’onglet « En-têtes » (Headers).
Dans la section « En-têtes de réponse » (Response Headers), recherchez la directive suivante :
Content-Type: text/html; charset=UTF-8Ce paramètre indique explicitement à votre navigateur dans quel encodage le contenu doit être interprété. Si le charset est absent, ou s’il est différent de UTF-8 (par exemple ISO-8859-1 ou Windows-1252), cela peut entraîner une mauvaise lecture des caractères accentués ou spéciaux. Il est important de noter que l’en-tête HTTP prime sur la balise meta dans le HTML. Si vous avez correctement déclaré <meta charset="UTF-8"> dans votre fichier HTML mais que le serveur envoie un en-tête contradictoire, le navigateur risque d’ignorer la balise et de suivre l’instruction du serveur. Ce désalignement est une source fréquente d’erreurs d’affichage.
À ce stade, si vous constatez un charset incorrect dans les en-têtes, vous avez déjà une piste sérieuse à explorer. Il faudra alors intervenir sur la configuration du serveur (voir section correspondante plus bas) pour garantir la cohérence entre le contenu HTML et les instructions envoyées au navigateur.
Si vous suspectez que le problème est intermittent ou lié à un cache, ouvrez une fenêtre de navigation privée ou videz le cache (clic droit sur le bouton de rechargement → « Vider le cache et effectuer un rechargement complet »).

2. curl (terminal)
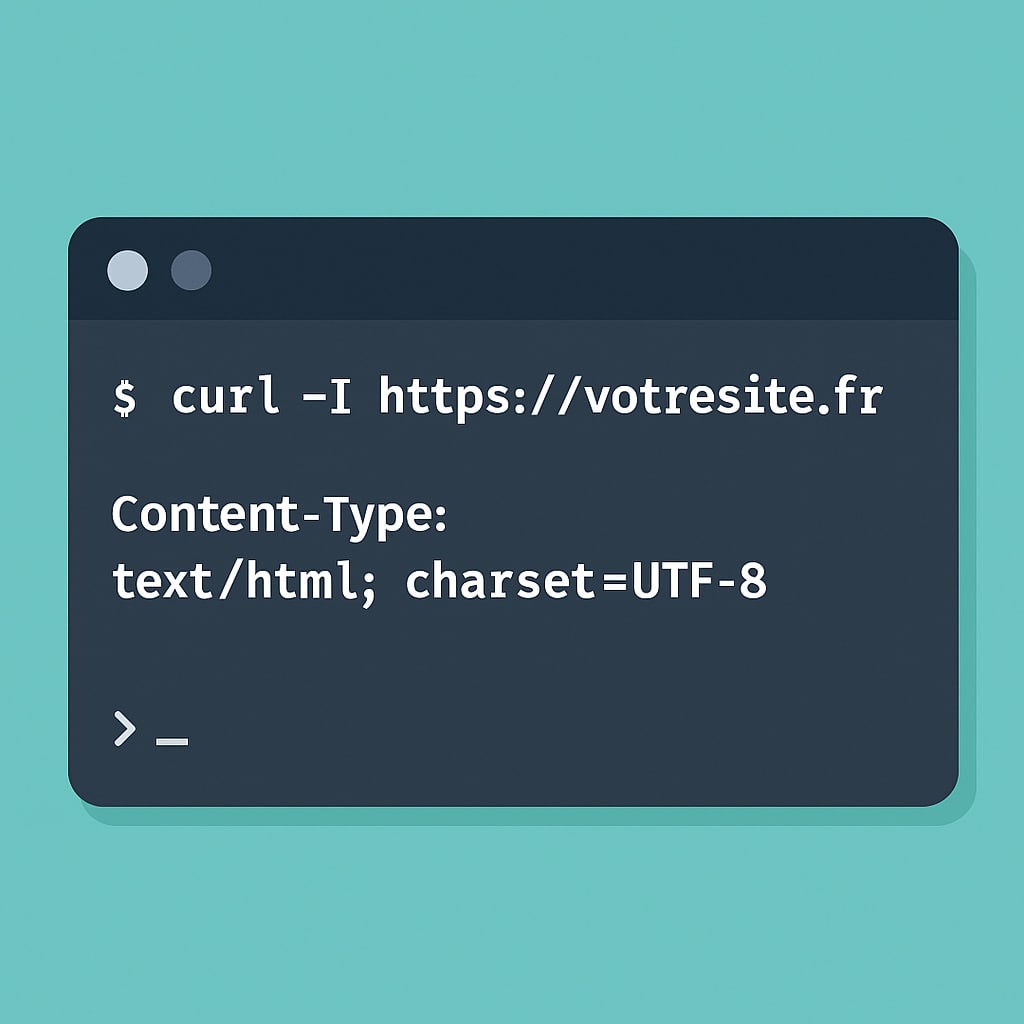
Si vous préférez travailler en ligne de commande ou que vous souhaitez inspecter un site distant rapidement sans passer par un navigateur graphique, curl est l’outil idéal. Il permet d’interroger directement un serveur web et d’afficher les en-têtes HTTP renvoyés, y compris le type de contenu et l’encodage utilisé. Pour effectuer un diagnostic simple, ouvrez votre terminal (sur Linux, macOS ou Windows avec WSL ou Git Bash) et tapez la commande suivante :
curl -I https://votresite.frLe paramètre -I (ou --head) indique à curl de ne récupérer que les en-têtes de réponse (et non le contenu HTML complet). Vous obtiendrez un résultat ressemblant à ceci :
HTTP/1.1 200 OK
Date: Sun, 31 Aug 2025 11:27:54 GMT
Server: Apache
Content-Type: text/html; charset=UTF-8
Connection: closeLa ligne clé à observer est :
Content-Type: text/html; charset=UTF-8Comme avec les DevTools du navigateur, cet en-tête déclare le type MIME (ici, HTML) ainsi que le charset utilisé pour interpréter les caractères du document. Si vous y voyez charset=ISO-8859-1, Windows-1252 ou même aucun charset du tout, cela peut expliquer l’apparition de caractères illisibles dans le navigateur ou lors de l’exploitation d’un flux (JSON, RSS, API).
L’intérêt de curl va au-delà de la vérification visuelle : il permet aussi d’automatiser les tests via des scripts ou de tester des sites hébergés à distance sans interface graphique. Cela peut être particulièrement utile pour inspecter des pages dans le cadre d’un audit technique ou lorsque vous dépannez un site par SSH.
Astuce : pour inspecter les en-têtes d’une page spécifique (autre que la page d’accueil), précisez simplement l’URL complète :
curl -I https://votresite.fr/article/erreur-encodageEt si vous souhaitez visualiser tous les échanges (requêtes + réponses), utilisez l’option -v (verbose) :
curl -v https://votresite.frEnfin, si vous suspectez une redirection qui masque le véritable charset, ajoutez -L pour suivre les redirections :
curl -IL https://votresite.frAvec ces commandes simples, curl vous offre une vue directe sur les informations essentielles transmises par le serveur — un point de départ souvent décisif dans la résolution des problèmes d’encodage.
3. Notepad++ ou VS Code
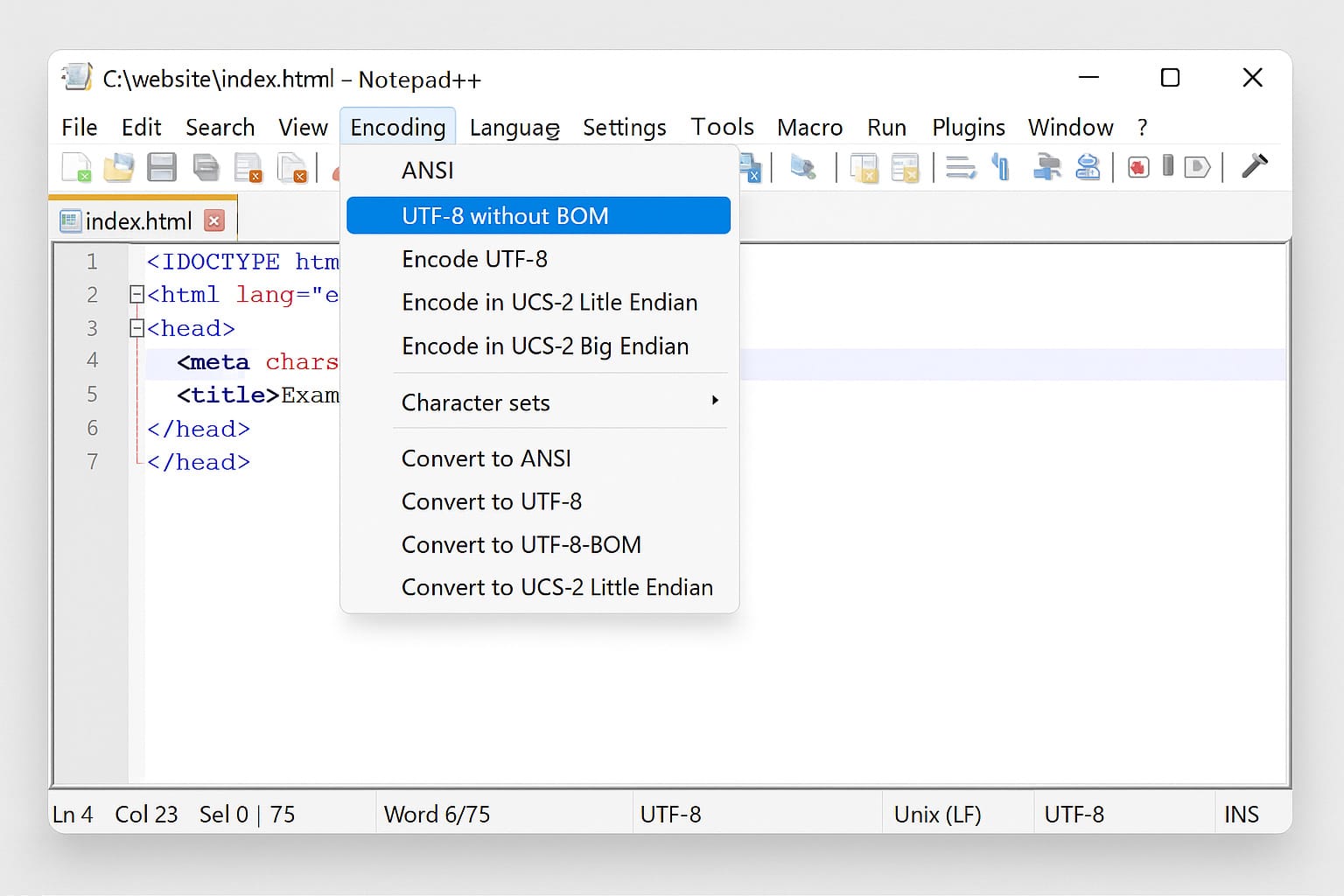
Lorsqu’un problème d’encodage provient directement du fichier source lui-même (HTML, PHP, JavaScript, etc.), il est essentiel de s’assurer que le fichier a bien été enregistré dans le bon format. Pour cela, des éditeurs de texte comme Notepad++ ou Visual Studio Code (VS Code) sont des outils particulièrement efficaces, car ils permettent à la fois de détecter et de corriger l’encodage d’un fichier en quelques clics. Dans Notepad++, l’encodage du fichier actuellement ouvert est affiché en bas à droite de la fenêtre (ex. : UTF-8, UTF-8-BOM, ANSI, etc.). Vous pouvez également accéder à ces informations en haut, via le menu :
Encodage > Encodage en UTF-8 (sans BOM)Si le fichier est en ANSI ou ISO-8859-1, cela signifie qu’il n’est pas dans un format Unicode et qu’il risque de produire des caractères incorrects dès qu’il contient des lettres accentuées ou d’autres symboles multilingues. Pire encore, si vous ouvrez un fichier déjà mal encodé sans vous en rendre compte, vous risquez de sauvegarder le contenu avec ces erreurs, les rendant définitives.
Voici les étapes recommandées dans Notepad++ :
- Ouvrez le fichier HTML, PHP ou texte suspect.
- Allez dans le menu « Encodage ».
- Si l’encodage n’est pas déjà
UTF-8 (sans BOM), choisissez « Convertir en UTF-8 (sans BOM) ». - Enregistrez immédiatement le fichier après conversion (
Ctrl + S).
Attention : le choix de « convertir » (et non « encoder ») est important. Notepad++ fait la distinction entre :
- Encoder en UTF-8 : interprète le contenu actuel avec un nouvel encodage, sans changer les octets. Risque de corrompre le texte s’il était mal lu à l’origine.
- Convertir en UTF-8 : réécrit le contenu en Unicode en adaptant correctement les caractères.
Dans VS Code, la méthode est tout aussi simple. Cliquez sur l’encodage affiché en bas à droite (par exemple « UTF-8 » ou « Windows 1252 »), puis choisissez :
- « Reopen with encoding » pour rouvrir un fichier en le forçant à utiliser un encodage spécifique (utile si les caractères sont corrompus à l’ouverture).
- « Save with encoding » pour réenregistrer le fichier dans un nouvel encodage, idéalement
UTF-8 without BOM.
Évitez si possible le format UTF-8 avec BOM : ce préfixe invisible au début du fichier peut perturber certains navigateurs ou interpréteurs (notamment en PHP), provoquant l’apparition de caractères parasites ou empêchant l’envoi correct des en-têtes HTTP.
Si votre projet web est collaboratif ou utilise un système de versioning (comme Git), pensez à vérifier l’encodage global des fichiers à chaque ajout ou modification. Des outils comme file (sous Linux/macOS) ou des extensions VS Code comme « EditorConfig for VS Code » peuvent vous aider à uniformiser les encodages dans un projet entier.
4. iconv (outil en ligne de commande)
iconv est un utilitaire en ligne de commande extrêmement utile lorsqu’il s’agit de convertir des fichiers texte d’un encodage vers un autre. Il est disponible nativement sur la plupart des systèmes Unix (Linux, macOS) et peut être installé sur Windows via des outils comme Git Bash, Cygwin ou le sous-système Linux (WSL).
Cet outil est particulièrement efficace pour traiter en masse des fichiers encodés dans des formats obsolètes, ou pour corriger des fichiers mal affichés sans avoir à les rouvrir un par un dans un éditeur. Il s’utilise aussi bien dans des scripts automatisés que dans des contextes de dépannage ponctuels.
La syntaxe de base est la suivante :
iconv -f [encodage source] -t [encodage cible] fichier_original.txt -o fichier_converti.txtPar exemple, pour convertir un fichier enregistré en ISO-8859-1 vers UTF-8 :
iconv -f ISO-8859-1 -t UTF-8 fichier.txt -o fichier_utf8.txtVous pouvez remplacer les valeurs de -f (from) et -t (to) par n’importe quel encodage reconnu par iconv, comme :
ISO-8859-1(Europe de l’Ouest)Windows-1252(souvent utilisé sur Windows)UTF-8UTF-16UTF-8//IGNOREouUTF-8//TRANSLITpour gérer les erreurs de conversion
Voici quelques exemples concrets :
# Conversion simple
iconv -f Windows-1252 -t UTF-8 page-contact.html -o page-contact-utf8.html
# Ignorer les caractères non convertibles (évite les erreurs)
iconv -f ISO-8859-1 -t UTF-8//IGNORE contenu.txt -o contenu-nettoye.txt
# Remplacer les caractères non convertibles par des approximations
iconv -f ISO-8859-1 -t UTF-8//TRANSLIT ancien.txt -o translit.txtConseil : si vous n’êtes pas certain de l’encodage d’origine d’un fichier, vous pouvez essayer de le détecter avec la commande file (sous Unix) :
file -i fichier.txtCette commande retournera un résultat comme :
fichier.txt: text/plain; charset=iso-8859-1ou encore :
fichier.txt: text/plain; charset=utf-8Précautions à prendre :
- Faites toujours une copie de sauvegarde de vos fichiers avant de les convertir, surtout en cas de traitement en lot.
- Ne forcez pas une conversion si le fichier est déjà en UTF-8 : vous risquez de le corrompre. Utilisez
fileou un éditeur pour identifier l’encodage avant d’appliquericonv. - Lors de la conversion vers UTF-8, privilégiez toujours
UTF-8 sans BOM, sauf cas très spécifiques (certains formats comme UTF-16 ou certains éditeurs Windows peuvent exiger un BOM).
Astuce pour traiter plusieurs fichiers d’un dossier :
for f in *.txt; do iconv -f ISO-8859-1 -t UTF-8 "$f" -o "utf8_$f"; doneCette boucle Bash permet de convertir tous les fichiers .txt d’un dossier vers UTF-8 en créant des copies préfixées. Pratique pour des lots de fichiers d’archives, d’exports ou de traductions reçus dans un encodage hétérogène.

5. Base de données MySQL ou MariaDB
Une base de données mal configurée en termes d’encodage peut être une source persistante d’erreurs invisibles… jusqu’au moment où vous insérez un caractère accentué, un emoji ou un mot dans une langue non latine. MySQL et MariaDB, bien qu’ayant évolué vers une meilleure prise en charge d’UTF-8, utilisent encore parfois des encodages obsolètes ou limités si aucune configuration explicite n’a été faite lors de l’installation ou du développement initial.
Pour diagnostiquer l’encodage en place, connectez-vous à votre base de données via un terminal (ou un outil comme phpMyAdmin ou Adminer) et exécutez la commande suivante :
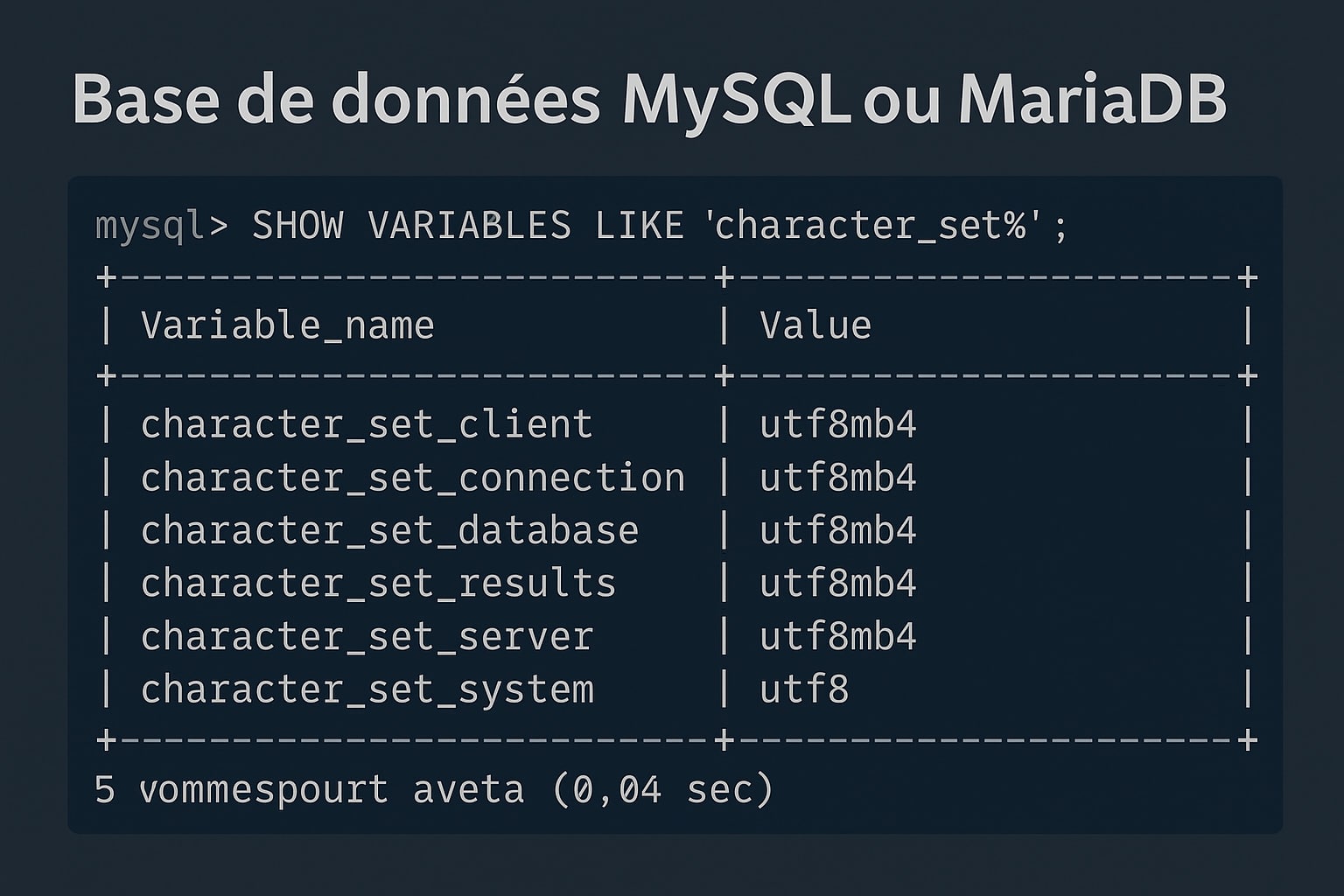
SHOW VARIABLES LIKE 'character\_set%';Vous obtiendrez une sortie qui ressemble à ceci :
character_set_client | utf8mb4
character_set_connection | utf8mb4
character_set_database | utf8mb4
character_set_results | utf8mb4
character_set_server | utf8mb4
character_set_system | utf8
Ces lignes indiquent les encodages utilisés pour :
- Le client : le charset utilisé par les requêtes SQL envoyées au serveur
- La connexion : l’encodage attendu pour le dialogue entre client et serveur
- La base en cours : encodage par défaut utilisé pour les nouvelles tables
- Les résultats : encodage utilisé pour envoyer les résultats au client
- Le serveur : charset global appliqué par défaut en l’absence de précision
Vous devez vous assurer que l’ensemble de ces paramètres est réglé sur utf8mb4 pour une prise en charge complète des caractères Unicode, y compris les emojis, symboles scientifiques, scripts asiatiques, etc.
Attention : dans MySQL, le charset nommé simplement utf8 est en réalité un encodage limité à 3 octets, et ne couvre pas tous les caractères du standard Unicode. Ce charset ne permet donc pas de stocker des caractères comme :
- Les émojis (
,) - Certains caractères chinois étendus (CJK)
- Des caractères spéciaux utilisés dans certains formats JSON ou scientifiques
Pour éviter toute mauvaise surprise, il faut toujours utiliser utf8mb4, la version étendue et complète d’UTF-8 (jusqu’à 4 octets par caractère).
Vérifier l’encodage des tables et colonnes
Une base de données peut être déclarée en utf8mb4 tout en contenant des tables ou des colonnes enregistrées dans un autre encodage, par exemple latin1 ou utf8. Pour le vérifier, vous pouvez exécuter la commande suivante :
SHOW TABLE STATUS FROM nom_de_la_base;La colonne Collation vous indique l’encodage actif sur chaque table (ex. : utf8mb4_unicode_ci ou latin1_swedish_ci).
Vous pouvez également inspecter une table en détail :
SHOW FULL COLUMNS FROM nom_table;La colonne Collation de cette requête vous permettra d’identifier si certaines colonnes texte (VARCHAR, TEXT, etc.) utilisent un encodage incohérent.
Convertir une base ou une table en utf8mb4
Si vous découvrez que certaines tables ou colonnes sont encore en latin1 ou utf8, vous pouvez les convertir en toute sécurité (après une sauvegarde !) :
ALTER TABLE nom_table CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;Pour toute une base :
ALTER DATABASE nom_de_la_base CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;Conseil : pour convertir une base entière, il est recommandé de traiter table par table, surtout si votre base contient des données multilingues ou a connu des insertions dans différents encodages au fil du temps.
Configurer la connexion côté application
Il ne suffit pas que la base soit en utf8mb4. L’application (PHP, Node.js, Python, etc.) qui dialogue avec la base doit aussi déclarer explicitement le charset lors de la connexion.
Par exemple, en PHP (mysqli) :
$mysqli->set_charset("utf8mb4");Dans WordPress, assurez-vous que cette ligne figure bien dans wp-config.php :
define('DB_CHARSET', 'utf8mb4');Et que votre base a été créée dès le départ avec le bon encodage. Sinon, même avec cette ligne, les nouvelles données seront bien encodées, mais les anciennes resteront potentiellement corrompues.
Pourquoi l’encodage de la base est fondamental
Un mauvais encodage en base peut provoquer :
- Des caractères accentués corrompus lors de l’enregistrement
- Des résultats de recherche tronqués ou non pertinents
- Des exports CSV ou JSON contenant des caractères illisibles
- Des erreurs d’insertion SQL (ex : « Incorrect string value »)
- Des problèmes SEO si les métadonnées encodées sont mal interprétées
Corriger l’encodage de la base de données est donc un levier essentiel pour garantir la qualité, la portabilité et la pérennité de vos données textuelles sur le web.
Les étapes pour corriger les erreurs d’encodage du site Web
Une fois les causes identifiées, il faut corriger chaque niveau potentiellement fautif. Voici les étapes à suivre :
1. Vérifier ou ajouter la balise <meta charset= »UTF-8″> dans le HTML
La balise <meta charset="UTF-8"> est l’un des éléments fondamentaux pour indiquer au navigateur l’encodage des caractères d’un document HTML. Sans cette indication explicite, le navigateur peut deviner un encodage erroné (comme ISO-8859-1 ou Windows-1252), ce qui entraîne souvent des erreurs d’affichage dès que la page contient des caractères accentués, des symboles ou du texte multilingue. Cette balise doit impérativement se trouver dans la section <head> du document HTML, et idéalement :
- être l’une des toutes premières lignes du fichier HTML,
- précédée uniquement de la déclaration
<!DOCTYPE html>, - et placée avant toute autre balise susceptible d’introduire du texte ou de déclencher un traitement (ex :
<title>,<style>,<script>, etc.).
Exemple correct et minimaliste :
<!DOCTYPE html>
<html lang="fr">
<head>
<meta charset="UTF-8">
<title>Page exemple</title>
</head>
<body>
<p>Bonjour à tous !</p>
</body>
</html>
Attention : si cette balise est absente ou mal placée, certains navigateurs peuvent commencer à analyser la page avec un encodage par défaut (souvent ISO-8859-1), ce qui peut entraîner une mauvaise lecture des premiers caractères du fichier. Une fois cette mauvaise interprétation enclenchée, le navigateur ne revient pas en arrière, même si la balise meta apparaît plus bas dans le code. C’est pourquoi sa position dans les premiers 1024 octets du fichier est fortement recommandée.
Comparaison avec l’ancienne syntaxe :
Avant HTML5, l’encodage se déclarait de cette manière :
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">Cette méthode est aujourd’hui considérée comme obsolète et plus verbeuse. Elle est encore supportée par les navigateurs pour compatibilité descendante, mais il est fortement conseillé d’utiliser la syntaxe plus concise et plus rapide de HTML5 :
<meta charset="UTF-8">Astuce : dans certains CMS ou générateurs de sites (comme WordPress, Jekyll, Hugo, etc.), la balise meta charset est générée automatiquement dans les templates ou thèmes. Cependant, si vous développez un thème personnalisé ou intégrez un fichier HTML statique manuellement, assurez-vous que cette balise est bien présente et correctement positionnée.
Bonnes pratiques supplémentaires :
- Veillez à ce que vos fichiers HTML soient eux-mêmes enregistrés en UTF-8 (voir la section sur les éditeurs de texte) ;
- Évitez l’ajout du BOM (Byte Order Mark), sauf si vous savez ce que vous faites. Il peut perturber l’interprétation de la balise meta ou provoquer des caractères parasites ;
- Vérifiez que les en-têtes HTTP envoyés par le serveur ne contredisent pas la balise
meta. En cas de conflit, c’est l’en-tête HTTP qui sera prioritaire.

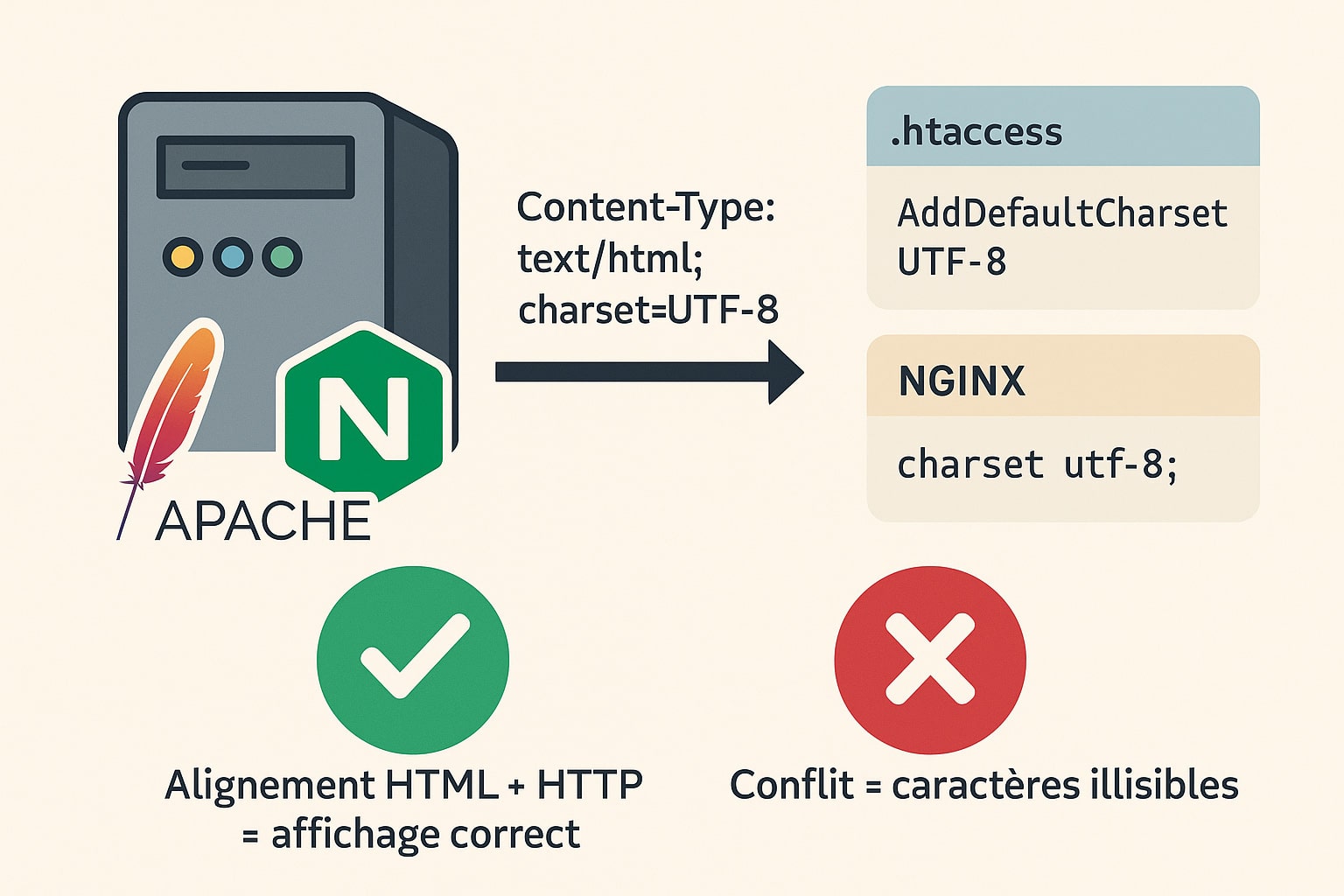
2. Aligner l’encodage serveur HTTP
Déclarer l’encodage dans le HTML est indispensable, mais cela ne suffit pas à garantir une interprétation correcte des caractères. En effet, les navigateurs modernes accordent une priorité plus élevée aux en-têtes HTTP envoyés par le serveur. Si le serveur web (Apache, NGINX, LiteSpeed, etc.) transmet un encodage différent de celui déclaré dans le code HTML, ce sont les en-têtes HTTP qui l’emportent. Ce décalage est une source fréquente de conflits et d’affichages erronés.
Il est donc essentiel d’aligner la configuration du serveur avec celle du document, en forçant explicitement l’usage de UTF-8 à tous les niveaux.
Pour les serveurs Apache
Sur un hébergement Apache (classique en mutualisé ou en VPS), vous pouvez définir l’encodage par défaut en modifiant le fichier .htaccess situé à la racine de votre site web. Il suffit d’y ajouter la ligne suivante :
AddDefaultCharset UTF-8Ce paramètre indique à Apache d’ajouter automatiquement l’en-tête suivant dans toutes les réponses HTML :
Content-Type: text/html; charset=UTF-8Cette directive peut être placée dans le fichier .htaccess, dans un bloc <Directory> ou directement dans le fichier de configuration global d’Apache (httpd.conf). Elle s’applique à tous les fichiers HTML, PHP ou statiques servis sans entête spécifique. Cela permet d’éviter que le serveur utilise un encodage par défaut comme ISO-8859-1, encore présent dans certaines configurations historiques.
Remarques :
- Certains hébergements mutualisés peuvent restreindre l’usage de certaines directives dans
.htaccess. SiAddDefaultCharsetne fonctionne pas, contactez le support ou utilisez des directives PHP (voir ci-dessous). - Pour les scripts PHP, vous pouvez aussi envoyer l’encodage dans le code :
<?php
header('Content-Type: text/html; charset=UTF-8');
?>Pour les serveurs NGINX
Sur NGINX, l’ajout de l’encodage se fait dans le fichier de configuration principal (nginx.conf) ou dans le bloc server correspondant à votre site :
charset utf-8;Cette ligne suffit à indiquer à NGINX de renvoyer l’en-tête HTTP suivant :
Content-Type: text/html; charset=utf-8Vous pouvez également cibler plus précisément les types de fichiers :
location ~ \.html$ {
charset utf-8;
}
Après toute modification de la configuration NGINX, pensez à redémarrer le service pour que les changements soient pris en compte :
sudo systemctl restart nginxPour les autres serveurs
Sur des serveurs comme LiteSpeed, Caddy ou des services cloud (Vercel, Netlify, etc.), la gestion de l’encodage peut se faire via des interfaces d’administration ou des fichiers de configuration JSON, YAML ou TOML. L’objectif reste le même : s’assurer que l’en-tête HTTP Content-Type précise charset=UTF-8.
Comment vérifier que l’encodage HTTP est bien envoyé ?
Utilisez les outils suivants pour contrôler que l’en-tête est correctement transmis :
- Chrome DevTools : Onglet Réseau → sélectionnez la requête principale → onglet « En-têtes » → repérez la ligne
Content-Type. - Terminal : utilisez
curl -Ipour obtenir les en-têtes HTTP :
curl -I https://votresite.frSi vous ne voyez pas de charset, ou si un encodage autre que UTF-8 est indiqué, vous devrez ajuster votre configuration serveur comme décrit ci-dessus.
Pourquoi cette étape est importante ?
Sans en-tête HTTP cohérent avec le HTML, le navigateur peut :
- commencer à interpréter le contenu dans un encodage erroné,
- ne jamais repérer la balise
meta charsetsi elle arrive trop tard dans le fichier, - mettre en cache une version mal encodée de la page (ce qui prolonge le problème même après correction).
Aligner l’encodage serveur HTTP est donc une étape indispensable pour garantir que tout le contenu textuel (même généré dynamiquement ou envoyé en réponse API) sera bien compris, affiché et indexé comme prévu.
3. Corriger l’encodage des fichiers sources
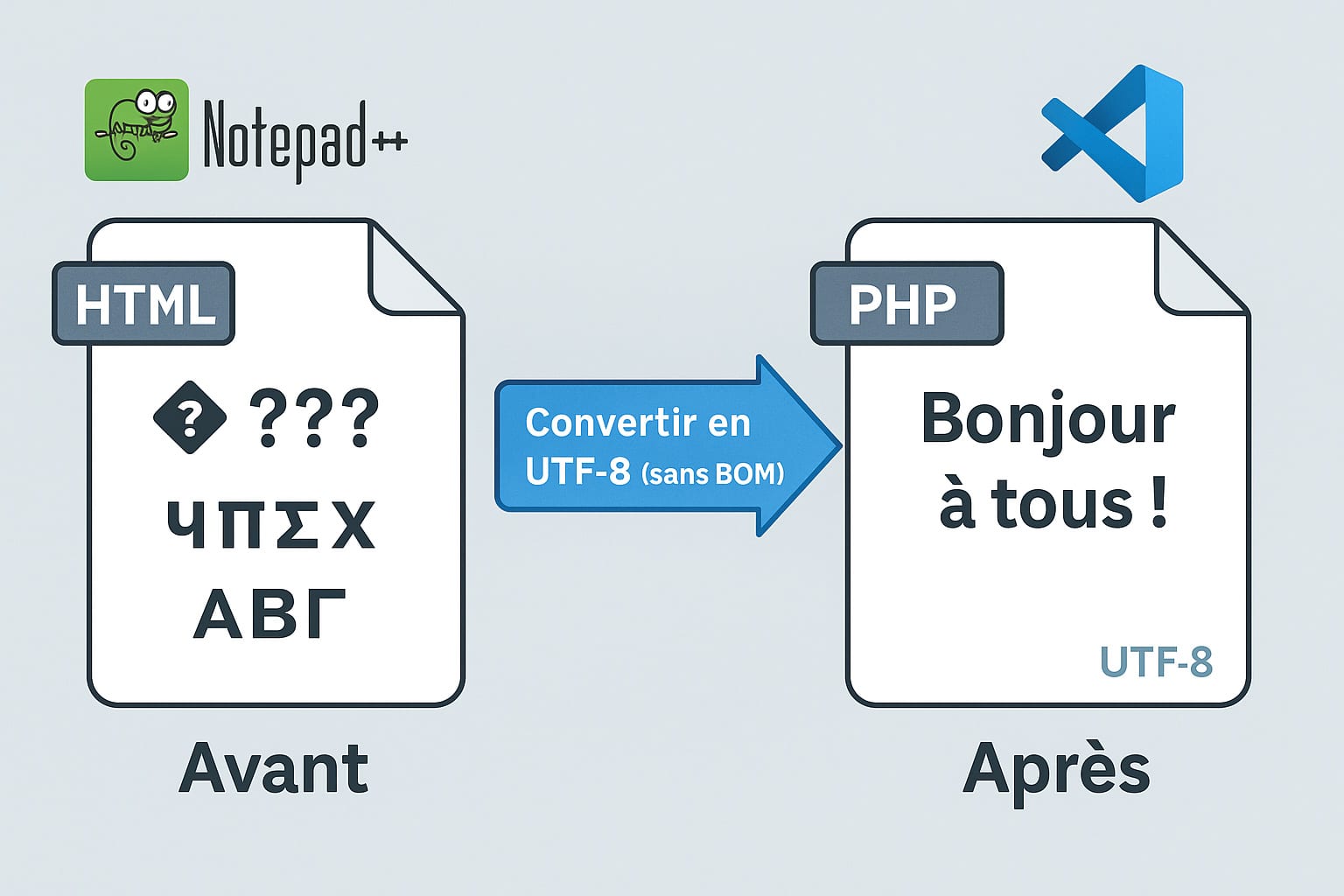
Une bonne configuration côté serveur et dans le HTML n’aura aucun effet si vos fichiers eux-mêmes — HTML, PHP, JS, JSON, CSS ou même TXT — sont enregistrés dans un encodage incorrect. C’est souvent le cas des fichiers anciens, ou de ceux provenant de systèmes d’exploitation configurés en Windows-1252 ou ISO-8859-1. Même un seul fichier mal encodé peut introduire des erreurs d’affichage sur tout un site.
Dans Notepad++, ouvrez chaque fichier suspect. En haut de l’interface, le menu « Encodage » vous indiquera dans quel format le fichier est actuellement enregistré :
- UTF-8 (sans BOM) : format recommandé
- UTF-8 avec BOM : à éviter sauf cas particuliers (peut poser problème en PHP)
- ANSI, Windows-1252, ISO-8859-1 : encodages à convertir
Pour corriger cela :
- Allez dans Encodage > Convertir en UTF-8 (sans BOM)
- Enregistrez le fichier immédiatement après la conversion (
Ctrl + S)
Dans Visual Studio Code, regardez dans la barre de statut (en bas à droite). Cliquez sur l’encodage affiché, puis choisissez :
- Reopen with Encoding pour rouvrir un fichier mal interprété
- Save with Encoding pour le réenregistrer dans un format propre
Attention aux caractères déjà corrompus : si un fichier a été enregistré plusieurs fois avec un mauvais encodage, certains caractères peuvent être irrécupérables. Ils apparaissent sous forme de losanges, de points d’interrogation ou de caractères incompréhensibles. Dans ce cas, convertir le fichier ne suffit pas — il faudra :
- réécrire manuellement les portions corrompues,
- ou récupérer une version antérieure du fichier via Git, une sauvegarde, ou une copie fonctionnelle du site.
Pour éviter toute récidive :
- paramétrez votre éditeur pour enregistrer tous les nouveaux fichiers en UTF-8 par défaut,
- évitez d’ouvrir ou d’éditer vos fichiers avec des outils de traitement de texte classiques comme Word ou Excel, qui peuvent altérer l’encodage à l’ouverture ou à la sauvegarde,
- utilisez des outils de contrôle qualité ou des scripts pour scanner les encodages de fichiers dans un projet complet (ex :
file,grep, extensions VS Code, etc.).
Une fois tous les fichiers convertis et vérifiés, vous réduirez considérablement les risques d’affichage erroné, de transmission de contenu corrompu ou d’export défectueux.
4. Modifier l’encodage des tables ou colonnes de la base de données
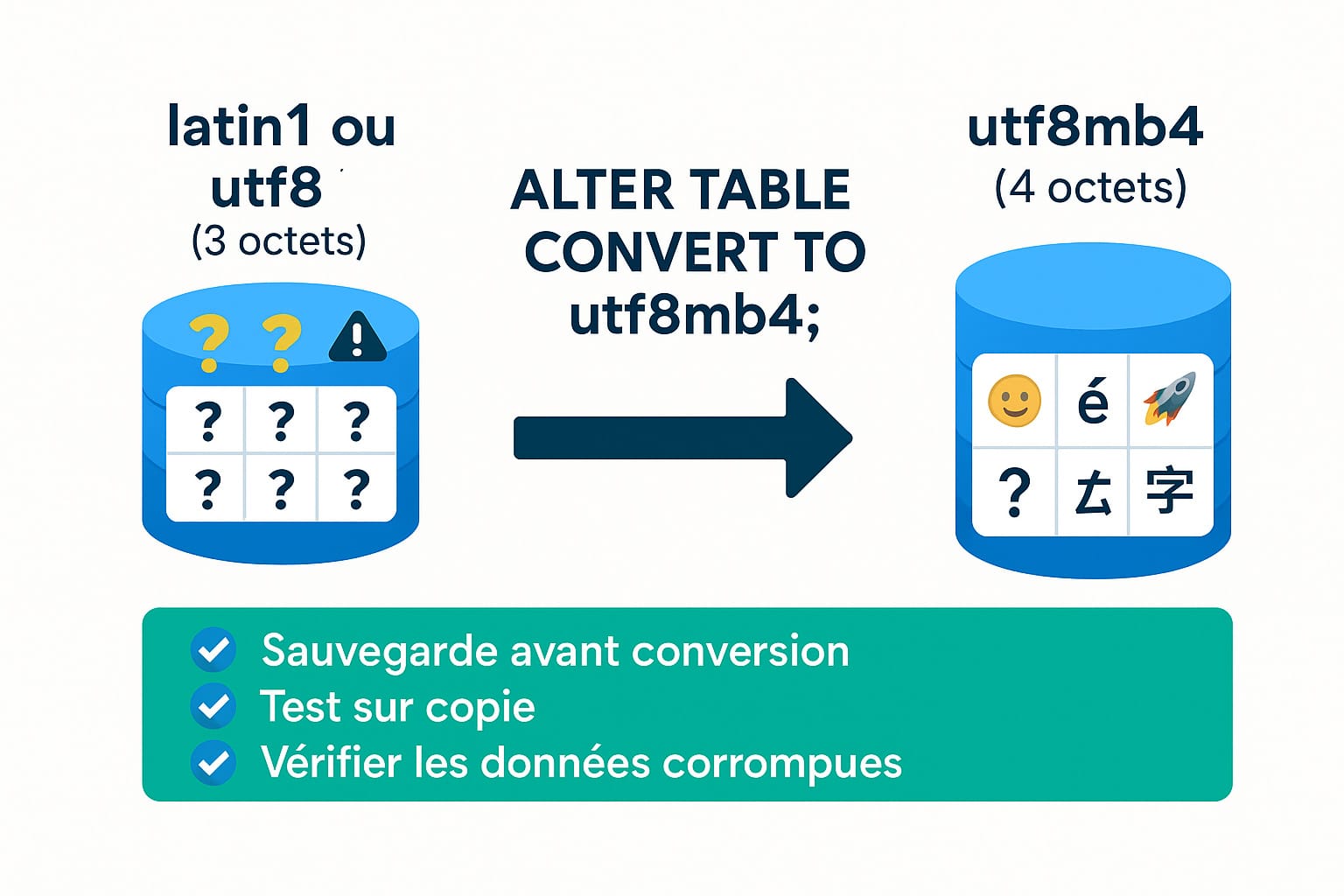
Corriger les fichiers sources ne suffit pas si la base de données est restée sur un encodage trop ancien comme latin1 ou le utf8 limité de MySQL (3 octets). Ces encodages peuvent empêcher l’enregistrement de certains caractères modernes comme les emojis, les caractères asiatiques étendus ou certains symboles spéciaux. Ils peuvent aussi tronquer des chaînes ou provoquer des erreurs SQL à l’insertion.
Pour résoudre cela, il est souvent nécessaire de convertir les tables, voire toute la base de données vers utf8mb4, l’encodage recommandé depuis plusieurs années pour une compatibilité Unicode complète (jusqu’à 4 octets).
Voici la commande de conversion pour une table :
ALTER TABLE nom_table CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;Cette commande :
- convertit toutes les colonnes texte de la table vers
utf8mb4, - modifie l’interclassement (collation) pour permettre un tri linguistiquement cohérent,
- met à jour les métadonnées de la table.
Avant toute conversion :
- effectuez une sauvegarde complète de votre base de données avec un outil comme
mysqldump, phpMyAdmin ou Adminer, - vérifiez que le contenu actuel n’est pas déjà corrompu, car la conversion ne corrigera pas les erreurs déjà présentes,
- testez sur un environnement de développement ou une copie locale avant de déployer en production.
Si vous avez plusieurs tables à convertir, vous pouvez automatiser cette tâche avec un script SQL ou une boucle en ligne de commande. Exemple en bash pour MySQL :
mysql -u user -p -e "SELECT table_name FROM information_schema.tables WHERE table_schema='ma_base';" \
| tail -n +2 \
| while read table; do \
echo "Converting $table..."; \
mysql -u user -p -e "ALTER TABLE ma_base.\`$table\` CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;"; \
doneImportant : cette conversion ne modifie pas automatiquement les données déjà mal encodées. Si du contenu a été stocké en latin1 mais interprété comme utf8, il faudra d’abord le corriger (ex : via CONVERT(... USING) dans MySQL ou via une exportation/reimportation propre en UTF-8).
Exemple de correction d’une colonne spécifique :
UPDATE nom_table SET colonne = CONVERT(BINARY CONVERT(colonne USING latin1) USING utf8mb4);Une fois toutes vos tables converties, vous bénéficierez d’une base de données capable de gérer correctement tous les caractères Unicode, y compris les plus complexes. C’est un prérequis non seulement pour éviter les erreurs d’affichage, mais aussi pour garantir une compatibilité maximale avec les exports, les API, les CMS modernes, et les besoins futurs de votre site web.
5. Vérifier les connexions entre l’application et la base
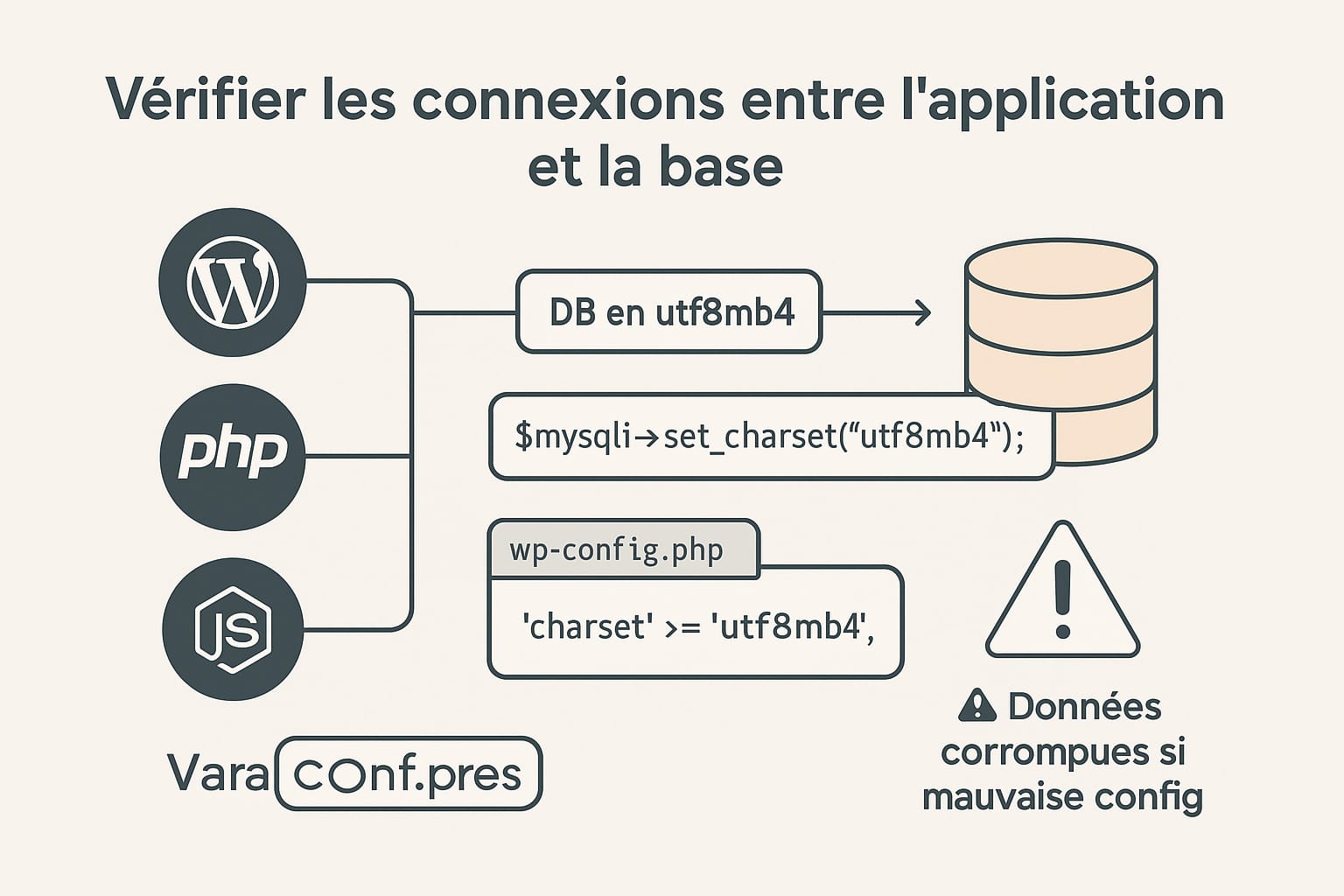
Même si votre base de données est correctement configurée en utf8mb4 et que vos fichiers sources sont bien encodés, un maillon faible peut encore introduire des erreurs d’encodage : la connexion entre l’application (PHP, CMS, framework…) et la base de données.
En effet, si l’application ne précise pas l’encodage à utiliser lors de l’ouverture de la connexion à la base, le système peut appliquer un encodage par défaut (souvent latin1 ou utf8 à 3 octets dans MySQL), ce qui provoque une mauvaise interprétation des caractères à l’insertion ou à la lecture des données.
Dans WordPress
WordPress gère l’encodage de la connexion à la base via le fichier wp-config.php, situé à la racine du site. Ce fichier contient les constantes de configuration, dont celle-ci, qui est essentielle :
define('DB_CHARSET', 'utf8mb4');Cette ligne indique à WordPress de communiquer avec la base en utf8mb4. Si cette directive est absente ou restée sur utf8 ou latin1, les caractères Unicode étendus ne seront pas correctement enregistrés dans la base.
Vérifiez également que l’interclassement est défini comme suit (optionnel mais recommandé) :
define('DB_COLLATE', 'utf8mb4_unicode_ci');Note : ces réglages ne modifient pas les tables existantes — ils servent à définir le comportement des nouvelles connexions ou tables créées à partir du moment où WordPress les utilise.
En PHP natif (mysqli)
Si vous utilisez du code PHP personnalisé sans CMS, vous devez explicitement définir le charset de la connexion immédiatement après la création de l’objet mysqli, sinon la connexion utilisera l’encodage par défaut du serveur, qui n’est pas forcément UTF-8.
Voici comment faire :
$mysqli = new mysqli("localhost", "utilisateur", "motdepasse", "ma_base");
if ($mysqli->connect_error) {
die("Connexion échouée : " . $mysqli->connect_error);
}
$mysqli->set_charset("utf8mb4");Cette commande est essentielle pour éviter des insertions de données tronquées ou mal encodées, notamment si vous manipulez :
- du texte multilingue (arabe, chinois, russe, etc.),
- des caractères spéciaux (accents typographiques, symboles mathématiques),
- ou des emojis et pictogrammes (qui nécessitent 4 octets en utf8mb4).
Sans cette ligne, même une base bien configurée en utf8mb4 n’empêchera pas l’introduction de données mal encodées. PHP enverra les données dans un encodage par défaut, et la base tentera de les enregistrer comme si elles étaient correctes… d’où les erreurs silencieuses, les caractères remplacés, ou les messages SQL du type Incorrect string value.
Pour les autres langages / frameworks
Si vous utilisez un autre langage ou un framework (Laravel, Symfony, Node.js, Python/Django, etc.), assurez-vous que le charset est bien précisé dans la configuration de connexion à la base. Voici quelques exemples :
- Laravel (config/database.php) :
'charset' => 'utf8mb4',
'collation' => 'utf8mb4_unicode_ci',- Node.js (mysql2 ou sequelize) :
charset: 'utf8mb4'- Python (MySQL connector) :
connection = mysql.connector.connect(
host="localhost",
user="root",
password="motdepasse",
database="ma_base",
charset="utf8mb4"
)Enfin, pensez à tester l’encodage effectif de la connexion dans vos outils de développement en affichant la variable SQL suivante :
SHOW VARIABLES LIKE 'character_set_client';Si cette variable ne renvoie pas utf8mb4, cela signifie que la connexion en cours ne respecte pas l’encodage cible, et doit être corrigée.
Une mauvaise configuration à ce niveau est insidieuse : Le site Internet peut fonctionner pendant longtemps sans erreur apparente, mais corrompre silencieusement ses données au fil du temps. En sécurisant l’encodage de vos connexions applicatives, vous garantissez l’intégrité de votre base et la fiabilité de toutes les opérations de lecture/écriture.
Une fois toutes les modifications d’encodage effectuées — dans le HTML, les fichiers source, les en-têtes HTTP, la base de données ou les connexions serveur — il reste une étape souvent négligée mais essentielle : vider les caches.
Les navigateurs modernes, les serveurs web, les CMS, les outils de cache applicatif et les CDN (Content Delivery Network) conservent temporairement les pages web en mémoire pour accélérer les chargements. Malheureusement, cela signifie qu’ils peuvent aussi conserver une ancienne version mal encodée d’une page, même après sa correction. Cela donne l’illusion que le problème persiste alors qu’il a été techniquement résolu.
Dans un premier temps, forcez le navigateur à ignorer les fichiers en cache local :
- Windows/Linux :
Ctrl + F5 - Mac :
Cmd + Shift + R
Cette action demande au navigateur de recharger entièrement la page, y compris les entêtes HTTP et les ressources HTML, CSS ou JS. Elle est très utile en phase de test après avoir modifié l’encodage.
Astuce : ouvrez la page dans une fenêtre de navigation privée (incognito) pour éviter tout résidu de cache ou de cookie pouvant fausser vos observations. Vous pouvez également utiliser l’onglet « Réseau » des DevTools pour cocher l’option « Désactiver le cache » pendant les tests.
Vider le cache serveur (Apache, NGINX, Varnish…)
Si vous utilisez un système de cache côté serveur (comme mod_cache avec Apache, FastCGI cache avec NGINX ou Varnish), pensez à vider ou invalider ces caches également. Selon la configuration de votre hébergement, vous pouvez :
- supprimer manuellement les fichiers de cache s’ils sont stockés localement,
- relancer le service web (
systemctl restart nginxouapache2), - utiliser des commandes CLI de purge si vous avez un proxy de type Varnish ou une couche de reverse proxy.
Vider le cache applicatif (CMS, plugin ou framework)
Les CMS comme WordPress, Joomla, Drupal, ou les frameworks comme Laravel, Symfony, etc., peuvent intégrer des systèmes de cache interne (opcache, cache de page, cache de vue, cache objet, etc.). Pensez à :
- vider le cache via l’interface d’administration du CMS,
- utiliser les commandes associées (ex :
php artisan cache:clearpour Laravel), - désactiver temporairement les plugins de cache (ex : WP Super Cache, W3 Total Cache, LiteSpeed Cache).
Astuce WordPress : pour invalider complètement les caches générés par des plugins, supprimez le contenu du dossier /wp-content/cache/ si autorisé par votre hébergeur.
Vider le cache des CDN (Cloudflare, Fastly, Akamai…)
Si votre site utilise un CDN comme Cloudflare pour distribuer les pages plus rapidement, il est probable que les versions HTML soient stockées en cache sur les nœuds de leur réseau mondial. Pour forcer une mise à jour :
- Connectez-vous à votre tableau de bord Cloudflare (ou équivalent),
- allez dans la section Caching,
- cliquez sur « Purge Everything » pour vider l’ensemble du cache CDN,
- ou utilisez « Custom Purge » pour ne cibler que certaines URL (si votre site est volumineux).
Note : La purge du cache CDN peut prendre quelques secondes à quelques minutes selon les services. Pendant ce temps, certains utilisateurs peuvent encore voir l’ancienne version.

Configurer des entêtes de cache plus souples temporairement
Pour faciliter les tests ou éviter les problèmes futurs liés au cache d’encodage, vous pouvez temporairement réduire la durée de vie des fichiers dans les entêtes HTTP. Par exemple, sur Apache :
Header set Cache-Control "no-store, no-cache, must-revalidate, max-age=0"Ou sur NGINX :
add_header Cache-Control "no-cache, no-store, must-revalidate";Ces directives désactivent le cache navigateur pour toutes les ressources concernées. Attention à ne pas laisser ces réglages en production trop longtemps, car ils ralentissent le site (aucune ressource n’est mise en cache côté client).

0 commentaires