Dans l’univers du SEO technique, chaque ligne de code peut influencer la visibilité d’un site web sur les moteurs de recherche. Parmi les outils mis à disposition des webmasters pour dialoguer avec les robots d’indexation, le fichier robots.txt tient une place centrale. C’est dans ce fichier que l’on retrouve l’instruction Allow, un mot simple mais doté d’un rôle stratégique. Bien que moins connue que sa contrepartie Disallow, l’instruction Allow joue un rôle déterminant dans la gestion fine du crawl des contenus web. Dans cet article, nous allons explorer en détail ce qu’est l’instruction Allow, comment elle fonctionne, à quoi elle sert, et dans quels cas l’utiliser pour optimiser la manière dont votre site est exploré et indexé par les moteurs de recherche.
Définir précisément l’instruction Allow dans un contexte SEO
Pour bien comprendre la portée de l’instruction Allow, il est essentiel de la replacer dans le contexte plus large de l’histoire du robots.txt et de la manière dont le web a tenté, au fil des années, de réguler la circulation des robots d’indexation. L’instruction Allow n’est pas apparue de manière isolée, mais comme un prolongement logique de la volonté de mieux contrôler l’exploration des sites web par des entités automatisées. Pour rappel, le fichier robots.txt a été introduit en 1994 par Martijn Koster, un ingénieur néerlandais qui travaillait à l’époque sur le moteur de recherche Aliweb, l’un des tout premiers moteurs avant même l’arrivée de Yahoo ou Google. Il constatait déjà un problème : Les premiers robots (souvent mal programmés) surchargeaient les serveurs et visitaient des zones inappropriées. C’est dans ce contexte qu’il publia la première version du Robots Exclusion Protocol, un standard non contraignant permettant aux propriétaires de sites de signaler aux robots les zones à ne pas explorer.
À cette époque, la directive Disallow suffisait pour bloquer des répertoires entiers. Mais à mesure que les sites devenaient plus dynamiques et hiérarchisés (notamment à partir du début des années 2000 avec la montée en puissance des CMS comme WordPress, Joomla ou Drupal), il est vite devenu évident qu’un contrôle plus granulaire était nécessaire. C’est ainsi qu’est apparue l’instruction Allow, permettant d’introduire des exceptions à une règle générale de blocage. Bien qu’elle ne fasse pas officiellement partie d’une norme RFC, elle est devenue largement acceptée et interprétée correctement par les principaux moteurs de recherche, notamment Google, Bing et Yandex.
D’un point de vue technique, Allow est interprétée comme une directive de permission explicite. Elle est particulièrement puissante lorsqu’elle est combinée avec des chemins complexes, des filtres d’URL ou des paramètres dynamiques. Par exemple, sur un site d’e-commerce disposant de milliers de filtres générés par URL (comme ?couleur=bleu ou ?tri=prix), l’instruction Allow peut permettre d’autoriser uniquement les fiches produits tout en bloquant l’accès aux pages de navigation filtrée, qui créent du contenu dupliqué ou diluent le budget de crawl.
Voici une illustration typique dans un contexte technique :
User-agent: Googlebot Disallow: /boutique/ Allow: /boutique/produit-
Dans cet exemple, toutes les pages du répertoire /boutique/ sont bloquées, sauf celles qui commencent par /boutique/produit-, correspondant vraisemblablement aux fiches produits individuelles. Cela permet de ne pas gaspiller le budget de crawl sur des catégories, filtres ou pages peu stratégiques. Il faut également comprendre que les robots d’indexation ne lisent pas le fichier robots.txt de manière contextuelle, mais syntaxique : ils évaluent chaque directive indépendamment, et utilisent souvent la règle la plus spécifique. C’est ici que la précision de l’instruction Allow prend toute sa valeur. Plus le chemin spécifié est précis, plus il a de chances d’être pris en compte comme prioritaire dans l’interprétation des règles contradictoires.
Cette logique a poussé Google, dès 2010, à publier des recommandations détaillées sur l’usage des directives de crawl. Bien que la directive Allow ne soit pas toujours indispensable, elle permet d’éviter des erreurs courantes, comme l’interdiction accidentelle de contenus importants lorsque l’on utilise des règles de blocage trop larges. C’est notamment le cas lors de refontes de sites, où une seule ligne de Disallow: / non suivie d’exceptions pourrait empêcher tout index des pages essentielles.
Par ailleurs, le comportement de l’instruction Allow a évolué avec les capacités croissantes des moteurs de recherche à gérer des contenus JavaScript, à explorer les URLs complexes, ou à intégrer des signaux supplémentaires comme les balises meta robots ou les entêtes HTTP. Si autrefois le fichier robots.txt suffisait pour bloquer efficacement une page, aujourd’hui il agit surtout comme un premier filtre de surface. Les crawlers avancés peuvent utiliser d’autres critères, comme les plans de site (sitemaps), les fichiers canonicals ou les données structurées, pour affiner leur indexation. Enfin, il convient de noter que Allow n’est pas universellement reconnu par tous les types de robots. Si les moteurs de recherche grand public la respectent globalement, ce n’est pas toujours le cas des robots moins connus, spécialisés dans le scraping ou l’analyse concurrentielle. D’où l’intérêt de coupler cette directive à d’autres moyens de contrôle comme les headers HTTP, les protections par authentification ou encore l’utilisation de règles côté serveur via le fichier .htaccess ou les règles Nginx.
Le fonctionnement de l’instruction Allow dans le fichier robots.txt
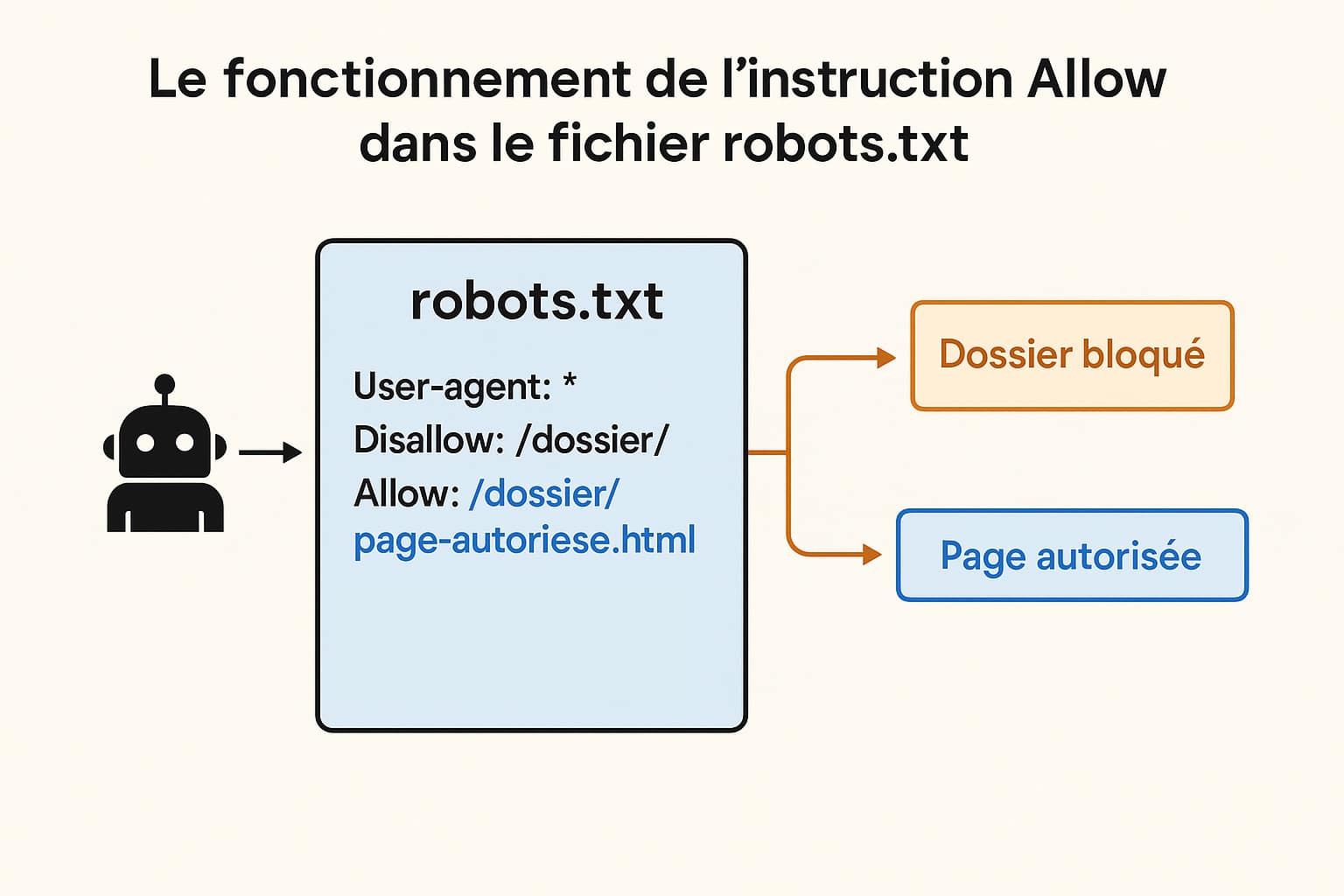
Le fonctionnement de l’instruction Allow s’inscrit dans une mécanique précise et hiérarchisée qui repose sur la lecture séquentielle des directives contenues dans le fichier robots.txt. Ce fichier, placé à la racine d’un domaine, est conçu pour transmettre des consignes d’exploration aux robots d’indexation, en leur indiquant ce qui peut ou ne peut pas être exploré sur le site. Dès qu’un crawler accède à une URL, il commence par consulter ce fichier, s’il existe, avant de poursuivre son exploration. Contrairement à ce que l’on pourrait penser, les robots d’indexation n’analysent pas le site de manière intuitive, mais suivent des règles définies ligne par ligne. C’est pourquoi l’ordre, la précision des chemins, et la spécificité des directives ont un impact direct sur la manière dont un site est exploré. L’instruction Allow permet d’ouvrir explicitement certaines sections du site à l’exploration, même lorsqu’une directive plus globale tend à les bloquer. Elle est donc utilisée comme un outil de finesse dans la gestion de l’indexabilité.
Par exemple, si un webmaster souhaite empêcher l’accès à l’ensemble d’un dossier mais autoriser une seule page située dans ce dossier, l’instruction Allow devient incontournable. Voici un exemple type :
User-agent: * Disallow: /dossier/ Allow: /dossier/page-autorisee.html
Dans ce cas, tous les robots seront invités à ne pas explorer le dossier entier, sauf la page spécifiée. Ce type d’usage est fréquent dans des contextes où certaines ressources doivent rester privées ou peu pertinentes pour les moteurs, tandis que d’autres doivent absolument être accessibles pour des raisons de SEO ou de trafic organique. Il faut également noter que la granularité des chemins spécifiés influe fortement sur l’interprétation par les robots. Une directive Allow trop large peut annuler involontairement un blocage précis. À l’inverse, une directive trop restreinte pourrait laisser de côté des pages importantes. C’est pour cette raison que l’on recommande toujours d’effectuer des tests, notamment via les outils mis à disposition par les moteurs de recherche. Google Search Console, par exemple, propose un simulateur qui permet d’anticiper le comportement du robot Googlebot en fonction des règles définies dans le fichier.
Un autre point technique à retenir est que le fichier robots.txt n’est pas un outil de sécurité. Il ne bloque pas l’accès réel à une ressource, mais indique seulement aux robots ce qu’ils doivent ou non explorer. Cela signifie que même si une URL est exclue de l’indexation par ce biais, elle reste accessible à quiconque dispose de son adresse. Pour véritablement restreindre l’accès à un fichier ou un répertoire, il faut mettre en place des mécanismes complémentaires comme l’authentification, les permissions serveur ou l’ajout d’en-têtes HTTP spécifiques. Dans la pratique, la directive Allow est souvent utilisée conjointement avec des fichiers sitemaps, qui listent de façon exhaustive les URLs que l’on souhaite faire indexer. Cela permet de guider les robots tout en s’assurant qu’ils ne s’égarent pas sur des parties inutiles du site, ce qui est particulièrement utile lorsque l’on gère des sites volumineux avec des milliers de pages. Elle joue ainsi un rôle indirect mais efficace dans la gestion du budget de crawl, en évitant que des ressources serveur soient consacrées à des pages non stratégiques.
Enfin, l’interprétation de la directive Allow peut différer légèrement selon les moteurs. Google accorde une priorité à la directive la plus spécifique, c’est-à-dire celle dont le chemin correspond le plus précisément à l’URL analysée. D’autres moteurs, comme Microsoft Bing, suivent un comportement similaire, mais certains robots moins répandus ou moins sophistiqués peuvent ne pas gérer correctement les conflits entre Allow et Disallow. C’est une autre raison pour laquelle il est recommandé de rédiger des directives simples, logiques, et bien structurées.
Les cas d’usage, les erreurs fréquentes et les bonnes pratiques avec Allow
L’instruction Allow est un levier fin de pilotage du crawl, particulièrement utile dans des contextes où la granularité du contrôle est essentielle. Contrairement à l’usage plus simple de Disallow, qui bloque l’accès à une ressource ou un répertoire, Allow s’inscrit dans une logique d’exception. Elle permet de contourner une règle de blocage pour autoriser spécifiquement certains contenus. Ce mécanisme, très puissant lorsqu’il est bien utilisé, devient rapidement source de confusion si les règles ne sont pas hiérarchisées avec rigueur.
Dans les environnements numériques complexes, l’utilisation de Allow devient incontournable. Les sites e-commerce, les portails d’actualités, les plateformes applicatives ou encore les sites à forte volumétrie de contenus s’en servent pour organiser l’accès des robots de manière stratégique. Il ne s’agit plus simplement de dire « oui » ou « non » à une URL, mais de guider les moteurs vers ce qui mérite réellement d’être indexé. Voici plusieurs exemples concrets où l’instruction Allow trouve toute sa pertinence :
- Dans le e-commerce : un site marchand peut générer automatiquement des milliers de pages de tri ou de filtres (par prix, couleur, taille, etc.). Ces pages sont souvent de faible valeur SEO et peuvent provoquer un gaspillage du budget de crawl. En revanche, les fiches produits sont cruciales. L’utilisation de Allow permet d’ouvrir l’accès aux fiches tout en bloquant les pages dynamiques inutiles ;
- Sur les blogs ou sites d’actualités : il est fréquent d’interdire le crawl des résultats de recherche interne ou des pages de tags trop génériques, tout en autorisant l’exploration des articles publiés dans des répertoires bien définis. Cela permet de concentrer l’indexation sur les contenus éditoriaux à fort potentiel tout en réduisant les risques de duplication ou de pages orphelines ;
- Dans les applications JavaScript (SPA) : certaines routes côté client doivent être explorées pour permettre une indexation correcte, notamment si les pages sont rendues via le routage interne. En revanche, les appels d’API ou les backends techniques doivent rester inaccessibles. Allow permet ici de gérer l’ouverture sélective d’URLs générées dynamiquement.
Mais cette souplesse a un revers : une simple erreur dans l’ordre des instructions ou dans la précision des chemins peut produire l’effet inverse de celui souhaité. Voici quelques pièges fréquents à éviter :
- Erreurs de syntaxe : un oubli de slash, un espace en trop ou une casse incorrecte peuvent suffire à rendre une directive inopérante. Les fichiers robots.txt ne tolèrent pas les imprécisions ;
- Hiérarchie incorrecte : si une directive Disallow est plus précise qu’un Allow, cette dernière sera ignorée. Par exemple, autoriser /blog/ tout en bloquant /blog/post/ rendra le Allow inefficace sur les articles situés dans /blog/post/ ;
- Conflits de logique : des instructions mal ordonnées ou incohérentes peuvent entraîner un comportement erratique de certains crawlers. Même si Google est capable de gérer certaines contradictions, ce n’est pas le cas de tous les robots, notamment ceux qui se basent sur une lecture stricte du fichier.
Pour éviter ces erreurs et garantir un fonctionnement optimal de vos directives, voici quelques bonnes pratiques essentielles à appliquer :
- Tester systématiquement les règles avec des outils spécialisés, comme le testeur de robots.txt intégré à Google Search Console. Cela permet d’anticiper le comportement réel de Googlebot ;
- Sauvegarder une version propre du fichier avant toute modification. Cela permet de revenir en arrière rapidement en cas de problème de crawl ou de désindexation accidentelle ;
- Utiliser des chemins aussi précis que possible pour éviter toute ambiguïté. Plus un chemin est spécifique, plus la directive sera fiable ;
- Analyser régulièrement les journaux de crawl ou les rapports d’indexation pour vérifier si les URLs stratégiques sont bien accessibles et explorées comme prévu.
Voici un exemple avancé d’utilisation de Allow dans une stratégie progressive d’ouverture :
User-agent: * Disallow: / Allow: /blog/ Allow: /produits/
Cette configuration est typique d’un site en construction ou en refonte. Elle interdit par défaut l’ensemble du domaine aux robots(voir également notre article sur quels robots bloquer), tout en autorisant deux sections précises à être explorées. Cela permet de travailler sur le reste du site sans risquer que les moteurs d’indexation n’accèdent à des contenus incomplets ou non finalisés.

0 commentaires