Au delà des autres moteurs de recherche, référencer son site Internet sur Google apparaît comme une priorité pour n’importe quel webmaster. A tel point que la création mais surtout la mise en production du site Web revêt un caractère particulier : Google va-t-il sonder mon site, le robot va t-il crawler l’ensemble des pages du site pour opérer son classement ? Pour s’en assurer, il existe plusieurs points à vérifier. Voici une petite check-list de ce qu’il faut prendre en compte.
- Qu’est-ce que l’indexation dans Google ?
- Vérifiez que GoogleBot peut accéder au site
- Vérifiez les balises meta index de vos pages
- Installez la Google Search Console
- S’assurer que le bot vient faire un tour sur vos contenus (analyse des logs)
- Principes d’indexation de base au lancement d’un site
- 1. Inscrire le site dans des annuaires de qualité
- 2. Utiliser les réseaux sociaux pour signaler l’existence du site
- 3. Créer et soumettre un sitemap XML
- 4. Solutions d’indexation massive (indexation de lots de pages)
- 5. Ajouter le site dans Google Search Console et Bing Webmaster Tools
- 6. Penser à la hiérarchisation du maillage interne
- 7. Cas des sites multilingues ou multi-domaines
- 8. Et si rien ne fonctionne ?
Qu’est-ce que l’indexation dans Google ?
Lorsque l’on évoque le référencement naturel, on pense dans le langage courant avant tout à l’optimisation pour les moteurs de recherche. Nous vous laissons consulter ici une définition du SEO. Mais dans la pratique, il s’agit bien simplement de permettre aux différents moteurs de recherche :
Lors de la mise en ligne du site Internet, l’ensemble de ces principes est généralement appelée « opération de mise à l’index ». La mise à l’index consiste donc à définir les permissions et les restrictions d’accès à tout ou partie d’un site par des robots. Ce faisant, on utilise plusieurs outils et protocoles pour réussir l’opération.
Vérifiez que GoogleBot peut accéder au site
GoogleBot est le robot d’exploration principal de Google, aussi appelé « crawler » ou « spider ». Son rôle est fondamental dans le processus d’indexation : il parcourt le Web à la recherche de nouvelles pages à ajouter à l’index du moteur. Mais attention, ce n’est pas le seul robot que possède la firme de Mountain View. D’autres bots spécialisés comme Googlebot-Image (pour les images), Googlebot-News (pour Google Actualités) ou encore Googlebot-Mobile interviennent également selon la nature du contenu à explorer.
Avant même de penser à l’optimisation SEO ou au contenu, il est essentiel de vous assurer que GoogleBot a bien le droit d’entrer. Et pour cela, tout commence par un petit fichier situé à la racine de votre site : le robots.txt.
Ce fichier contrôle les accès aux ressources pour les robots d’indexation. S’il est mal configuré, il peut empêcher totalement GoogleBot de visiter votre site, même si tout le reste est parfaitement optimisé. Voici un exemple classique de blocage complet à éviter :
User-agent: googlebot
Disallow: /Ce code signifie : « À l’intention de GoogleBot, l’accès à toutes les pages (représentées par /) est interdit ». C’est une consigne de non-crawl totale. Résultat : GoogleBot ne verra rien, et vous n’existerez pas dans son index. Pour rétablir la situation, il suffit de supprimer ou commenter cette directive, ou mieux encore, de l’ouvrir à tous les bots :
User-agent: *
Disallow:Cette configuration indique à tous les robots (l’astérisque * est un joker) qu’ils peuvent accéder à l’intégralité du site. Mais attention, ouvrir toutes les portes ne signifie pas qu’il faut tout montrer.
Astuce : pensez à restreindre l’accès à certaines zones sensibles comme les back-offices, les pages de connexion (
/wp-admin,/login, etc.) ou les interfaces d’administration, que Google n’a aucune raison de crawler.
Voici un exemple d’exclusion partielle correcte :
User-agent: *
Disallow: /admin/
Disallow: /wp-login.phpEnfin, n’oubliez pas de vérifier que le fichier robots.txt est bien accessible à l’adresse suivante :
https://www.votre-site.fr/robots.txtUn fichier inexistant ou mal formé peut engendrer des erreurs d’exploration, visibles dans la Google Search Console. C’est aussi dans cet outil que vous pourrez tester la validité de votre fichier robots.txt via la section « Outils d’inspection d’URL » ou « Statistiques sur l’exploration ».
En résumé : ouvrir le site aux robots est la toute première brique d’un SEO efficace. Mais même si GoogleBot peut « rentrer », cela ne signifie pas qu’il verra tout, ni qu’il indexera tout. D’autres éléments entrent en jeu, comme les directives meta, les balises canonicals ou encore la structure du site. Ce n’est que la première étape, mais elle est indispensable. Et pourtant… parfois cela ne suffit pas.
Vérifiez les balises meta index de vos pages
Vous avez supprimé les éventuels Disallow dans votre fichier robots.txt ? Bravo, Googlebot peut désormais visiter les pages de votre site. Mais attention : visiter ne veut pas dire indexer. Un autre garde-fou peut encore bloquer la mise en avant de vos pages dans les résultats de recherche : la balise meta « robots », et notamment sa redoutable valeur noindex.
Cette balise, très puissante, peut littéralement invisibiliser une page entière dans les SERP. Voici sa syntaxe la plus classique :
<meta name="robots" content="noindex">Et sa variante ciblée uniquement sur Googlebot :
<meta name="googlebot" content="noindex">Ces instructions HTML, généralement placées dans la balise <head> du document, indiquent au robot : « Je te vois, mais tu ne me classes pas ». Résultat ? Votre page ne s’affichera jamais dans les résultats du moteur… même si elle est parfaitement construite, riche, optimisée et promue par toute la blogosphère. Un vrai coup d’épée dans l’eau.
CMS : Attention aux réglages par défaut
Sur WordPress (et d’autres CMS), cette balise peut être activée sans même que vous le sachiez, notamment dans les cas suivants :
- Mode maintenance ou préproduction activé (souvent coché via « Visibilité pour les moteurs de recherche »)
- Extensions SEO mal paramétrées (Yoast, Rank Math, SEOPress…)
- Modèles de page ou types de contenu exclus (archives, catégories, tags, etc.)
Il est donc impératif, surtout lors du passage en production, de vérifier systématiquement la présence ou non de cette balise sur les pages stratégiques. Et par stratégique, comprenez : toutes les pages que vous voulez voir dans Google.
Ajouter ou supprimer la balise : où et comment ?
Si vous avez accès au code source, cette balise se situe généralement entre les balises <head> et </head>. Si vous utilisez WordPress avec un plugin SEO, elle est générée dynamiquement selon les paramètres définis dans l’interface. Exemple avec Yoast :
- Éditez une page ou un article
- Faites défiler vers le bloc « Avancé » de l’extension
- Assurez-vous que l’option « Autoriser les moteurs de recherche à afficher ce contenu dans les résultats » est bien sur « Oui »
Et si je veux bloquer certaines pages ?
Ne vous jetez pas sur un noindex global, mais réfléchissez : certaines pages peuvent (et doivent) être volontairement exclues de l’indexation. C’est notamment le cas :
- des pages de connexion ou back-office
- des mentions légales ou CGV
- des pages de remerciement (post-formulaire)
- de certains filtres ou versions alternatives (tri, pagination excessive, etc.)
Vous pouvez également combiner noindex avec nofollow pour signaler à Google que vous ne souhaitez pas non plus qu’il suive les liens présents sur la page :
<meta name="robots" content="noindex, nofollow">Dans ce cas, le bot ignore à la fois le classement de la page, mais aussi tous les liens sortants. Cette directive doit être utilisée avec prudence, car elle limite fortement l’impact SEO de vos contenus, y compris en interne.
Googlebot est capricieux : l’intention ne fait pas tout
Gardez bien à l’esprit que la suppression d’une balise noindex n’implique pas un index immédiat. Le robot doit revenir sur la page, reparser son contenu, et prendre en compte cette nouvelle directive. Pour accélérer le processus :
- Demandez l’indexation manuelle via la Search Console (« Inspection de l’URL »)
- Ajoutez un lien interne vers la page (maillage)
- Partagez-la sur vos réseaux sociaux (Google explore aussi via les signaux sociaux)
Petite astuce SEO pour les furieux du noindex
Si vous êtes du genre à vouloir tout contrôler, vous pouvez aussi attribuer la directive noindex uniquement à certains bots, par exemple :
<meta name="bingbot" content="noindex">Résultat : Bing ignorera la page, mais pas Google. Parfait pour les tests ou les expérimentations. À manier toutefois avec précaution, car le cloaking de directives peut vite devenir un bazar technique si vous oubliez ce que vous avez bloqué… et pour qui. Et surtout : n’attendez pas que Google devine votre intention. Faites-lui clairement comprendre ce que vous voulez… avec les bons outils et une balise bien placée. Sinon, votre contenu brillera dans l’ombre, et ce serait dommage pour votre référencement.
Installez la Google Search Console
Pour s’assurer que tout va bien, rien de tel que la mise en place d’une propriété sur la Google Search Console. Cette dernière permet de vérifier que Googlebot est bien en mesure d’indexer vos contenus. Un petit tour dans la section robots.txt pour lui dire qu’il a bien la permission de venir puis rendez-vous donc sur le webmaster tools, section « index Google » :
 Petit état de la situation à un instant « t » : Le nombre total de pages indexées étant ici nul, vous pouvez demander à Google d’aller explorer vos contenus. D’ailleurs, la search console vous guide en premier lieu en vous proposant par exemple de faire un sitemap : Section « Exploration » -> sitemaps -> »Ajouter/tester » un sitemap. Encore faut-il avoir configuré un fichier sitemap sur votre site 🙂
Petit état de la situation à un instant « t » : Le nombre total de pages indexées étant ici nul, vous pouvez demander à Google d’aller explorer vos contenus. D’ailleurs, la search console vous guide en premier lieu en vous proposant par exemple de faire un sitemap : Section « Exploration » -> sitemaps -> »Ajouter/tester » un sitemap. Encore faut-il avoir configuré un fichier sitemap sur votre site 🙂
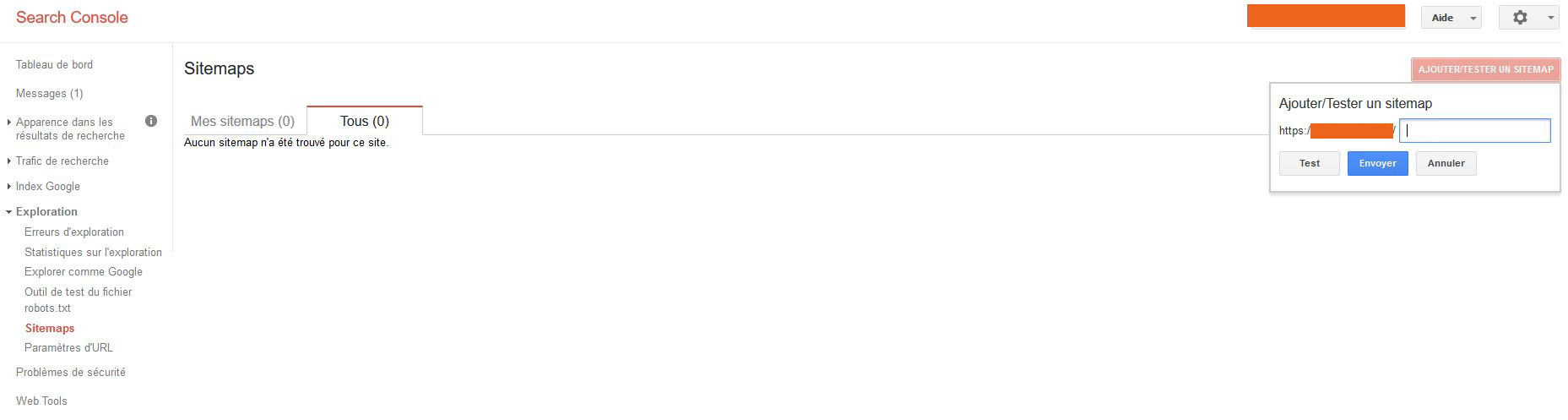 Le sitemap peut aider, mais c’est toujours à la discrétion des moteurs (Sur Bing également, faites l’opération). Ce qui nous conduit donc à un autre outil « d’insistance », « Explorer comme Google« . Dans le même onglet « Exploration », vous trouverez ceci :
Le sitemap peut aider, mais c’est toujours à la discrétion des moteurs (Sur Bing également, faites l’opération). Ce qui nous conduit donc à un autre outil « d’insistance », « Explorer comme Google« . Dans le même onglet « Exploration », vous trouverez ceci :

En pratique, mettre le chemin d’un contenu et explorer puis dans une seconde fenêtre demander l’indexation, ça marche très bien (pour peu que les principes évoqués plus haut le permettent). Vous pouvez le faire pour ordinateur et pour mobile. Nous voilà bien. Sauf que :
- Il va falloir dans le cadre d’une création indexer l’ensemble des pages créées,
- Se heurter donc à un ras-le-bol du moteur qui vous le fait savoir en vous proposant des captchas plus compliqués à mesure que vous lui demandez d’indexer les pages,
- Google va vous indexer votre page mais rien n’exclut qu’il la retire… avec le temps
S’assurer que le bot vient faire un tour sur vos contenus (analyse des logs)
Il ne suffit pas que votre site soit joli, responsive ou même rapide pour qu’il soit bien positionné sur Google. Le premier prérequis à tout référencement est simple : le passage du robot crawler, plus précisément Googlebot. S’il ne vient pas visiter vos pages, aucune chance qu’elles soient indexées. Et s’il ne les visite pas régulièrement, il ne peut pas non plus les mettre à jour dans l’index. C’est là qu’intervient un allié précieux : l’analyse des logs serveur.
Dans la Google Search Console, vous pouvez avoir une vision partielle du crawl via l’onglet « Statistiques sur l’exploration ». Mais pour vraiment comprendre ce qui se passe en coulisses, vous devez consulter vos fichiers logs d’accès Apache ou Nginx (par exemple : /var/log/apache2/access.log). Ces fichiers enregistrent chaque requête HTTP reçue par votre serveur, y compris celles des bots comme Googlebot, Bingbot, AhrefsBot ou Screaming Frog (si vous faites vos audits).
Qu’est-ce qu’un log serveur et pourquoi l’analyser ?
Un log d’accès contient des informations précises sur chaque requête :
- L’adresse IP source
- Le user-agent (nom du bot ou du navigateur)
- La date et l’heure
- Le statut HTTP (200, 301, 404, 500…)
- L’URL demandée
Exemple typique d’entrée de log Apache :
66.249.66.1 - - [20/Apr/2025:14:21:53 +0200] "GET /categorie/article.html HTTP/1.1" 200 5323 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"Ici, vous voyez que Googlebot est venu chercher une page spécifique et qu’elle a bien retourné un code 200. C’est une excellente nouvelle. Mais que se passe-t-il si vous avez 500 pages dans votre site et que Googlebot n’en visite que 20 ?
Le concept de « crawl budget »
Google attribue à chaque site un budget de crawl, défini par deux facteurs principaux :
- La capacité de votre serveur à supporter des requêtes (Google évite de surcharger les serveurs lents ou instables)
- L’intérêt perçu par Google (pages populaires, fraîches, mises à jour régulièrement…)
Ce budget n’est pas infini. Si votre site est mal structuré, trop lent, ou si certaines pages génèrent des erreurs (404, 500…), vous dilapidez ce budget inutilement. Résultat : certaines pages profondes ou isolées ne seront jamais crawlées, et donc jamais indexées.
Techniques pour favoriser le crawl (vraiment)
- Optimisez votre code HTML pour la lisibilité : Évitez les sites full-JavaScript sans fallback HTML, car Googlebot (malgré ses progrès en rendering) n’est pas toujours fiable sur les frameworks comme Angular, React ou Vue. L’idéal reste une architecture HTML-CSS propre, avec un rendu serveur ou un rendu statique (SSG) en cas d’utilisation de JS ;
- Limitez le poids des ressources : Des images en 24 MP, des vidéos embarquées sur la home, un DOM de 10 000 lignes… et vous voilà avec des temps de chargement monstrueux qui peuvent ralentir voire bloquer le crawl. Pensez à la compression Gzip, au lazy loading des images et au preloading des ressources critiques ;
- Structurez votre arborescence intelligemment : Plus une page est proche de la racine (home), plus elle a de chances d’être explorée fréquemment. Évitez les URL du type
/categorie/2023/archives/articles/page12/et limitez la profondeur à 3 ou 4 niveaux maximum ; - Soignez le maillage interne : Les pages orphelines, c’est-à-dire sans aucun lien pointant vers elles, sont souvent oubliées par les bots. Chaque nouvelle page doit être liée à au moins une autre page existante. Idéalement, placez ces liens dans le corps du contenu (et non dans le footer uniquement) ;
- Créez un plan de site HTML et XML : Le sitemap XML est un guide pour les moteurs. Le plan de site HTML améliore l’expérience utilisateur. Les deux ont leur utilité ;
- Réduisez les erreurs 404 et 500 : Ces pages dilapident votre budget de crawl. Corrigez les liens cassés, redirigez proprement les URL obsolètes avec des
301et surveillez vos logs régulièrement pour repérer les erreurs techniques ; - Encouragez l’arrivée de bots externes (backlinks) : Chaque lien depuis un site tiers est un point d’entrée potentiel pour Googlebot. Les backlinks, en plus d’augmenter votre autorité, stimulent directement le crawl sur votre site.
Quelques outils d’analyse des logs
Pour éviter de lire vos logs ligne à ligne, vous pouvez utiliser des outils comme :
- Botify (payant, très complet),
- OnCrawl (payant, data-driven),
- Screaming Frog Log Analyzer (outil complémentaire à Screaming Frog SEO Spider),
- GoAccess (outil open-source en ligne de commande).
Ces outils vous permettent de visualiser :
- La fréquence de passage des bots,
- Les URL crawlées (et celles oubliées !),
- Les codes de réponse HTTP,
- La profondeur d’accès,
- Les user-agents actifs.
Ces analyses vous aident à identifier les pages qui ne reçoivent pas de visites bot, à réorienter votre maillage, à remonter des pages dans la hiérarchie ou à corriger des erreurs serveur invisibles autrement.
Le crawl, c’est la base pour tout référenceur !
Avant même de vous demander si une page est bien positionnée, demandez-vous si elle est vue par les moteurs. Sans crawl, pas d’indexation. Et sans indexation, pas de trafic organique. Surveillez vos logs, anticipez le comportement des bots, optimisez vos structures, et vous poserez les vraies fondations du SEO technique. Et si un jour vous ne dormez pas, relisez vos logs avec une bonne tisane : ça vous aidera à repérer des failles insoupçonnées.
Principes d’indexation de base au lancement d’un site
Lorsque l’on met un site en ligne pour la première fois, ou après une refonte, l’enjeu immédiat est de s’assurer que ses pages soient explorées, comprises et, surtout, indexées par les moteurs de recherche. Il ne s’agit pas simplement d’être « en ligne », mais bien de devenir visible dans les SERP (résultats de recherche). Voici les bonnes pratiques fondamentales et les techniques avancées pour initier une indexation rapide, fiable et durable.
1. Inscrire le site dans des annuaires de qualité
La soumission à des annuaires reste un levier d’indexation initial. Bien que cette stratégie soit souvent jugée obsolète ou risquée en SEO moderne, elle conserve un intérêt quand elle est pratiquée intelligemment. Il s’agit ici non pas de chercher à obtenir du jus SEO, mais d’envoyer des signaux de présence :
- Choisissez des annuaires thématiques ou régionaux réputés (ex. : Webwiki, Wannu, El-annuaire, IndexWeb…)
- Rédigez des descriptions uniques (pas de duplicata !)
- Évitez les fermes de liens ou les réseaux automatiques à faible modération
Les robots de Google, Bing ou Yandex visitent encore régulièrement ces plateformes. Une fiche bien structurée, avec un lien dofollow ou nofollow, peut déclencher le premier crawl de votre site.
2. Utiliser les réseaux sociaux pour signaler l’existence du site
Créer une activité minimale sur des plateformes comme LinkedIn, X (Twitter), Facebook ou Pinterest permet d’envoyer des signaux de vie. Les crawlers passent sur les profils et les publications publiques, notamment via les API indexables. L’intérêt ? Générer des URL d’origine multiple qui pointent vers votre site et accélérer ainsi sa prise en compte.
Astuce : partagez différentes pages (et non uniquement la page d’accueil) avec des ancres variées dans vos publications.
3. Créer et soumettre un sitemap XML
Le sitemap XML est un fichier qui liste toutes les URL que vous souhaitez voir indexées. Il permet de :
- Indiquer les pages importantes (avec priorité et fréquence de mise à jour) ;
- Aider Googlebot et Bingbot à découvrir les pages non encore connues ;
- Surveiller l’état d’indexation depuis la Search Console ou Bing Webmaster Tools.
Ce fichier doit être automatiquement généré (via Yoast, RankMath ou des scripts maison) et accessible à l’adresse https://www.monsite.fr/sitemap.xml, tout en étant mentionné dans le robots.txt :
Sitemap: https://www.monsite.fr/sitemap.xml4. Solutions d’indexation massive (indexation de lots de pages)
Lorsqu’un site possède des centaines ou des milliers de pages (catalogue e-commerce, blog massif, base documentaire…), l’indexation manuelle ou naturelle est souvent lente. Voici quelques solutions d’indexation en masse :
- API d’indexation de Google (Indexing API) : initialement réservée aux pages d’offres d’emploi et de livestreams, cette API peut être utilisée pour signaler des pages fraîchement publiées ou mises à jour. Son usage reste limité à certains types de contenu selon les règles de Google, mais certains développeurs contournent cette restriction. À utiliser avec modération et éthique ;
- Outils de push d’indexation : des plateformes comme IndexMeNow, Instant Indexing, ou des intégrations via Zapier permettent de pousser automatiquement des lots d’URL à Google ou Bing (notamment via leur API officielle). Attention à la conformité avec les guidelines !
- Sitemaps segmentés : au lieu d’avoir un seul fichier, divisez vos sitemaps par type de contenu (produits, catégories, articles, pages…). Cela permet de mieux suivre les performances d’indexation dans la Search Console ;
- Ping automatisé : vous pouvez « pinguer » manuellement ou via cronjob les moteurs de recherche pour leur signaler l’existence d’un sitemap ou d’une nouvelle page. Exemple :
https://www.google.com/ping?sitemap=https://www.monsite.fr/sitemap.xmlhttps://www.bing.com/ping?sitemap=https://www.monsite.fr/sitemap.xml5. Ajouter le site dans Google Search Console et Bing Webmaster Tools
Ces outils sont vos tableaux de bord pour suivre l’indexation, détecter les erreurs, déclarer de nouvelles URL et optimiser vos performances. Ils permettent aussi d’exploiter l’outil « Inspection d’URL » pour soumettre manuellement une page à l’indexation.
6. Penser à la hiérarchisation du maillage interne
Lors de l’ajout d’un grand volume de pages, une erreur courante est de ne pas les relier correctement au reste du site. Une page qui n’a aucun lien entrant (page orpheline) aura peu de chances d’être indexée.
- Intégrez les nouvelles pages dans la navigation ou les blocs contextuels
- Ajoutez-les dans des pages pilier ou des clusters thématiques
- Reliez-les entre elles si elles appartiennent à la même catégorie
7. Cas des sites multilingues ou multi-domaines
Si vous avez plusieurs versions de votre site (en .fr, .com, .be, etc.) ou une structure multilingue, veillez à bien utiliser les balises hreflang et à déclarer chaque propriété individuellement dans Search Console. Un sitemap par langue peut aussi être utile pour optimiser l’indexation internationale.
8. Et si rien ne fonctionne ?
Malgré toutes les mesures précédentes, il arrive que Google n’indexe toujours pas certaines pages. Dans ce cas, faites un audit technique complet pour détecter les blocages :
- Retour à l’analyse des logs : les robots accèdent-ils vraiment à ces pages ?
- Structure HTML : les pages ont-elles des balises
canonicalerronées, desnoindexinvolontaires, des erreurs HTTP ? - Contenu : le texte est-il jugé trop pauvre, dupliqué ou peu utile ?
Un audit SEO technique et sémantique permet de répondre à ces questions. En détectant les freins d’indexation, vous gagnez un temps précieux et débloquez le potentiel de visibilité de votre site.
Conclusion : l’indexation d’un site, ce n’est pas une case à cocher mais un processus. De la déclaration à l’optimisation du crawl, chaque détail compte. Que vous soyez sur un petit site vitrine ou un mastodonte e-commerce, mettez toutes les chances de votre côté pour que vos pages ne restent pas dans l’ombre numérique.

0 commentaires