À mesure que les entreprises renforcent leur dépendance aux systèmes numériques, la moindre panne peut entraîner des conséquences importantes : Interruption d’activité, pertes financières, indisponibilité des services ou encore dégradation de l’image de marque. Entre les cyberattaques, les erreurs humaines, les défaillances matérielles et les catastrophes naturelles, les infrastructures informatiques sont exposées à de multiples risques. Face à ces menaces, une notion s’impose progressivement dans les stratégies technologiques modernes : La résilience informatique. La résilience informatique ne se limite pas à la simple sauvegarde des données ou à la cybersécurité. Elle représente la capacité globale d’un système d’information à continuer de fonctionner malgré les incidents, tout en retrouvant rapidement un niveau de performance normal. Cette approche englobe aussi bien la prévention que la réaction et la reprise après un événement perturbateur. Comprendre la résilience informatique devient aujourd’hui indispensable pour toutes les organisations, qu’il s’agisse de PME, de grandes entreprises, d’administrations ou de plateformes numériques. Découvrons ensemble sa définition, ses composantes essentielles et les bonnes pratiques permettant de construire une infrastructure numérique robuste et fiable.
Une définition de la résilience informatique
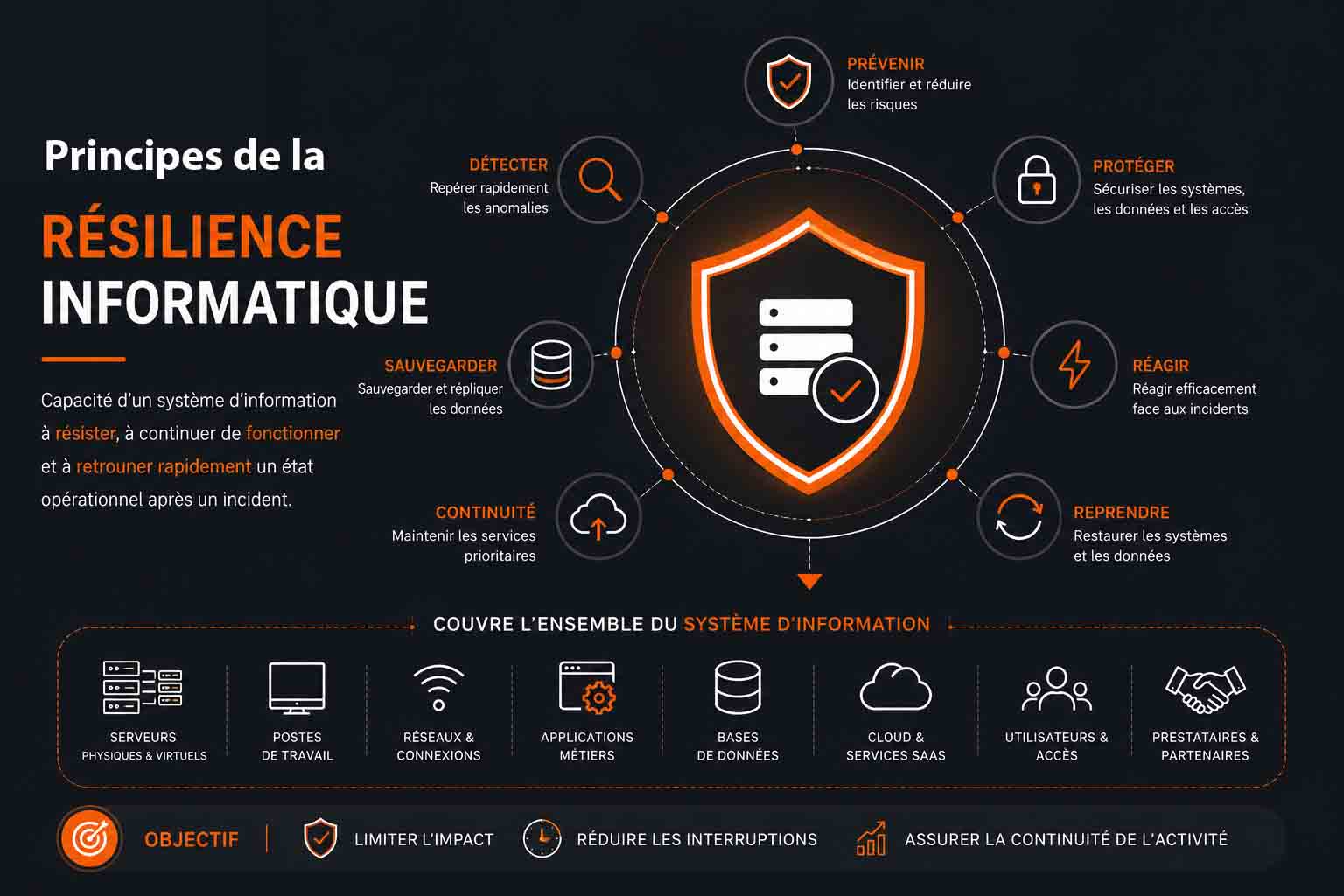
La résilience informatique désigne la capacité d’un système d’information, d’un réseau, d’une application ou d’une infrastructure numérique à résister à des perturbations, à continuer de fonctionner pendant un incident et à retrouver rapidement un état opérationnel après une panne, une erreur, une attaque ou tout autre événement susceptible d’interrompre l’activité. Cette notion dépasse largement la simple idée de “réparer après une panne”. Elle consiste à concevoir, organiser et piloter l’informatique de manière à absorber les chocs, limiter les interruptions, protéger les données, maintenir les services prioritaires et reprendre les opérations dans des délais acceptables pour l’entreprise. Contrairement à une approche uniquement basée sur la protection, la résilience informatique part d’un principe réaliste : Aucun système n’est totalement invulnérable. Même avec des pare-feu, des antivirus, des solutions de sauvegarde, des politiques d’accès strictes et des outils de supervision avancés, une organisation peut subir une défaillance technique, une cyberattaque, une erreur humaine ou une indisponibilité d’un prestataire externe. L’objectif n’est donc pas seulement d’empêcher les incidents. Il s’agit aussi de réduire leur probabilité, de limiter leur impact, d’assurer la continuité des activités essentielles et de permettre un retour maîtrisé à la normale. Une entreprise résiliente n’est pas une entreprise qui ne connaît jamais d’incident, mais une organisation capable de continuer à fonctionner malgré l’imprévu. La résilience informatique repose sur plusieurs piliers complémentaires :
- la prévention des risques informatiques ;
- la détection rapide des anomalies et des comportements suspects ;
- la protection des systèmes, des données et des accès ;
- la capacité de réaction face aux incidents ;
- la continuité des services numériques les plus sensibles ;
- la reprise rapide des opérations après une interruption ;
- la restauration fiable des données ;
- la redondance des infrastructures techniques ;
- la documentation des procédures d’urgence ;
- l’amélioration continue après chaque incident ou exercice de test.
La prévention consiste à identifier les risques avant qu’ils ne se transforment en incidents. Elle passe par des audits de sécurité, des mises à jour régulières, une bonne gestion des correctifs, une architecture maîtrisée, des contrôles d’accès adaptés et une sensibilisation des utilisateurs. Plus les vulnérabilités sont connues et traitées en amont, plus le système d’information devient robuste. La détection joue également un rôle central. Une anomalie repérée rapidement permet souvent d’éviter une interruption majeure. Les outils de supervision, les journaux d’événements, les solutions de détection d’intrusion, les alertes de performance et les plateformes de surveillance permettent d’identifier une activité inhabituelle, une saturation de serveur, une tentative d’accès non autorisée ou une dégradation progressive d’un service. La réaction correspond à la capacité de l’organisation à agir efficacement lorsqu’un incident survient. Cela suppose des procédures claires, des responsabilités définies, des canaux de communication identifiés et des équipes préparées. En cas d’attaque par ransomware, par exemple, il faut savoir quels systèmes isoler, qui prévenir, quelles sauvegardes vérifier et quelles applications relancer en priorité. La continuité d’activité vise à maintenir les fonctions essentielles de l’entreprise, même en mode dégradé. Toutes les applications n’ont pas le même niveau de priorité. Un outil de paiement, une plateforme de production, un logiciel de gestion des commandes ou un système de relation client peuvent être considérés comme prioritaires, tandis que d’autres services peuvent être temporairement interrompus sans bloquer l’activité principale. La reprise après incident consiste ensuite à restaurer progressivement les systèmes, les données et les services touchés. Cette étape doit être organisée, testée et documentée. Une reprise mal préparée peut allonger l’interruption, provoquer des pertes de données ou réintroduire une menace dans l’environnement informatique. La résilience informatique concerne l’ensemble du système d’information. Elle ne s’applique pas uniquement aux serveurs ou aux sauvegardes. Elle englobe notamment :
- les serveurs physiques et virtuels ;
- les postes de travail des collaborateurs ;
- les réseaux internes et externes ;
- les connexions internet ;
- les applications métiers ;
- les bases de données ;
- les environnements cloud ;
- les services SaaS ;
- les équipements de sécurité ;
- les sauvegardes ;
- les comptes utilisateurs ;
- les droits d’accès ;
- les prestataires informatiques ;
- les procédures internes.
Elle implique donc une vision globale de la sécurité, de la disponibilité et de la performance du système d’information. Une entreprise peut disposer d’une excellente solution de sauvegarde, mais rester vulnérable si ses procédures ne sont pas testées, si ses accès administrateurs sont mal protégés ou si ses équipes ne savent pas comment réagir en cas d’incident. Pour bien comprendre la résilience informatique, il est utile de la distinguer de notions proches. La cybersécurité cherche principalement à protéger les systèmes contre les menaces. La continuité d’activité vise à maintenir les opérations essentielles. Le plan de reprise d’activité organise le redémarrage après un sinistre. La haute disponibilité cherche à réduire les interruptions. La résilience informatique regroupe toutes ces dimensions dans une stratégie cohérente.
| Concept | Description | Rôle dans la résilience informatique |
|---|---|---|
| Cybersécurité | Protection contre les attaques, les intrusions, les logiciels malveillants et les accès non autorisés | Réduit la probabilité d’un incident et limite l’exposition aux menaces |
| Continuité d’activité | Maintien des opérations essentielles lorsqu’un incident perturbe le fonctionnement normal | Permet à l’entreprise de poursuivre ses missions prioritaires |
| Plan de reprise d’activité | Organisation du redémarrage des systèmes après une panne, une cyberattaque ou un sinistre | Structure le retour à la normale et limite la durée d’interruption |
| Haute disponibilité | Mise en place de mécanismes techniques pour réduire les interruptions de service | Assure une meilleure disponibilité des applications et infrastructures sensibles |
| Gestion des risques | Identification, évaluation et réduction des menaces pouvant affecter le système d’information | Aide à prioriser les investissements et les actions de protection |
| Sauvegarde informatique | Copie des données afin de pouvoir les restaurer en cas de perte, de corruption ou de suppression | Permet de récupérer les informations indispensables à l’activité |
| Supervision informatique | Surveillance continue des performances, des alertes, des journaux et des événements techniques | Favorise une détection rapide des incidents et une réaction plus efficace |
Un exemple concret permet de mieux visualiser cette notion. Une entreprise victime d’une attaque par ransomware ne sera pas jugée résiliente uniquement parce qu’elle possède des sauvegardes. Elle le sera si elle parvient à détecter rapidement l’intrusion, à isoler les machines compromises, à empêcher la propagation de l’attaque, à maintenir certains services indispensables, à restaurer ses données depuis des copies saines et à reprendre son activité dans un délai compatible avec ses contraintes métier. Dans ce type de situation, plusieurs questions permettent d’évaluer le niveau de résilience informatique :
- l’entreprise sait-elle identifier rapidement l’origine de l’incident ?
- les équipes savent-elles quels systèmes couper ou isoler en priorité ?
- les sauvegardes sont-elles récentes, complètes et exploitables ?
- les données restaurées sont-elles fiables ?
- les applications critiques peuvent-elles être relancées rapidement ?
- les utilisateurs disposent-ils de consignes claires ?
- les clients et partenaires peuvent-ils être informés correctement ?
- l’organisation peut-elle fonctionner temporairement en mode dégradé ?
La résilience informatique s’évalue aussi à travers deux indicateurs très utilisés : Le RTO et le RPO. Le RTO, ou objectif de temps de reprise, correspond au délai maximal acceptable pour remettre un service en fonctionnement après un incident. Le RPO, ou objectif de point de reprise, correspond à la quantité maximale de données que l’entreprise accepte de perdre entre la dernière sauvegarde exploitable et l’incident. Par exemple, si une entreprise fixe un RTO de quatre heures pour son logiciel de gestion commerciale, cela signifie que ce service doit être de nouveau disponible dans les quatre heures suivant une interruption. Si elle fixe un RPO de quinze minutes pour sa base de données clients, elle ne doit pas perdre plus de quinze minutes de données en cas de restauration. Ces indicateurs permettent d’adapter les moyens techniques aux besoins réels de l’activité. Une application stratégique nécessitera souvent des sauvegardes fréquentes, une réplication des données, une infrastructure redondante et une surveillance renforcée. À l’inverse, un outil secondaire pourra accepter un délai de reprise plus long.
La résilience informatique doit également prendre en compte les dépendances externes. De nombreuses entreprises s’appuient sur des fournisseurs cloud, des éditeurs SaaS, des hébergeurs, des opérateurs télécoms ou des prestataires de maintenance. Une panne chez l’un de ces acteurs peut avoir des conséquences directes sur l’activité. Il est donc nécessaire d’identifier ces dépendances, de vérifier les engagements de service et de prévoir des solutions alternatives lorsque cela est possible. Enfin, la résilience informatique n’est pas un état figé. Elle doit évoluer avec l’entreprise, ses usages, ses outils, ses risques et ses obligations. L’arrivée d’une nouvelle application métier, le développement du télétravail, la migration vers le cloud, l’ouverture d’un site e-commerce ou l’intégration d’objets connectés peuvent modifier le niveau d’exposition de l’organisation. C’est pourquoi une stratégie de résilience informatique doit être régulièrement réévaluée. Les tests de restauration, les exercices de crise, les audits techniques, les retours d’expérience et la mise à jour des procédures permettent d’améliorer progressivement la capacité de l’entreprise à faire face aux incidents. La résilience informatique se situe donc au croisement de plusieurs disciplines techniques et organisationnelles. Elle associe cybersécurité, continuité d’activité, architecture système, gouvernance des données, gestion des risques, supervision, sauvegarde et formation des utilisateurs. Son but est simple : garantir que l’entreprise puisse continuer à fonctionner, même lorsque son environnement informatique est perturbé.
Pourquoi la résilience informatique est devenue indispensable
Les systèmes informatiques modernes sont plus complexes que jamais. Les entreprises utilisent désormais des infrastructures hybrides mêlant cloud public, cloud privé, applications SaaS, serveurs internes, postes de travail, équipements mobiles, objets connectés, API, outils collaboratifs et plateformes métiers. Cette interconnexion permanente offre davantage de souplesse, mais elle augmente aussi les points de fragilité. Une panne isolée peut rapidement produire un effet domino. Un serveur indisponible peut bloquer une application métier, une application inaccessible peut ralentir le service client, un réseau instable peut perturber la production, et une base de données compromise peut empêcher la facturation ou la livraison. La résilience informatique est donc devenue une condition de stabilité pour les organisations. Autrefois, l’informatique était souvent perçue comme un support technique. Aujourd’hui, elle est directement liée au fonctionnement quotidien de l’entreprise. Les ventes, la production, la comptabilité, les ressources humaines, la logistique, la relation client, la communication et la prise de décision reposent sur des outils numériques. Lorsqu’ils s’arrêtent, c’est souvent toute l’activité qui ralentit, voire s’interrompt. Plusieurs facteurs expliquent pourquoi la résilience informatique est devenue une priorité stratégique pour les organisations.
La multiplication des cyberattaques
Les cyberattaques représentent l’une des principales raisons pour lesquelles les entreprises renforcent leur résilience informatique. Ransomwares, phishing, vols d’identifiants, attaques DDoS, intrusions ciblées, compromissions de messagerie, exploitation de failles logicielles ou attaques sur la chaîne d’approvisionnement peuvent toucher toutes les structures, quelle que soit leur taille. Les ransomwares sont particulièrement redoutés, car ils peuvent chiffrer les fichiers, bloquer les serveurs, rendre les applications inutilisables et paralyser l’activité en quelques minutes. Dans certains cas, les attaquants menacent également de publier les données volées, ce qui ajoute un risque juridique, financier et réputationnel. Les attaques DDoS, quant à elles, visent à rendre un site web, une application ou un service en ligne indisponible en le saturant de requêtes. Pour une plateforme e-commerce, une banque, un service public ou un fournisseur SaaS, quelques heures d’indisponibilité peuvent entraîner des pertes importantes et une forte insatisfaction des utilisateurs. Le phishing reste aussi une menace majeure. Un simple courriel frauduleux peut permettre à un attaquant de récupérer des identifiants, d’accéder à une messagerie professionnelle, de détourner des paiements ou de pénétrer dans le système d’information. La résilience informatique doit donc intégrer la protection technique, mais aussi la sensibilisation des collaborateurs. Même les organisations bien équipées restent exposées. Un antivirus, un pare-feu ou une solution de détection ne garantissent pas une protection absolue. La résilience informatique permet alors de limiter les conséquences d’une attaque : isoler les systèmes touchés, éviter la propagation, restaurer les données, maintenir les services prioritaires et reprendre l’activité dans un délai maîtrisé.
La dépendance aux services numériques
La transformation numérique a profondément modifié le fonctionnement des entreprises. De nombreuses opérations qui étaient autrefois manuelles ou locales dépendent désormais d’applications, de bases de données, de connexions réseau et de services cloud. Aujourd’hui, une interruption informatique peut bloquer :
- les ventes en ligne ;
- les commandes clients ;
- les paiements ;
- la facturation ;
- la production industrielle ;
- la gestion des stocks ;
- la chaîne logistique ;
- la relation client ;
- les communications internes ;
- les outils collaboratifs ;
- les accès aux documents ;
- les services de support ;
- les prises de rendez-vous ;
- les plateformes de réservation ;
- les tableaux de bord de pilotage.
Cette dépendance rend les interruptions plus visibles et plus coûteuses. Un site e-commerce indisponible perd des ventes. Une usine privée de son logiciel de pilotage peut ralentir sa production. Un cabinet médical sans accès à son logiciel patient rencontre des difficultés d’organisation. Une entreprise de services sans messagerie ni outil collaboratif voit ses équipes perdre en efficacité. La résilience informatique permet de définir les services réellement prioritaires. Toutes les applications n’ont pas le même poids dans l’activité. Certaines doivent être restaurées en quelques minutes, d’autres peuvent attendre plusieurs heures. Cette hiérarchisation permet d’investir intelligemment dans les sauvegardes, la redondance, la supervision et les plans de reprise.
Les exigences réglementaires
Les organisations doivent aussi composer avec des exigences réglementaires de plus en plus fortes. La protection des données, la sécurité des systèmes, la continuité des services et la capacité à gérer les incidents sont devenues des sujets encadrés dans de nombreux secteurs. Les entreprises manipulant des données personnelles doivent veiller à leur confidentialité, leur intégrité et leur disponibilité. Les secteurs sensibles, comme la santé, la finance, l’énergie, les télécommunications, les transports ou les services publics, sont soumis à des attentes encore plus élevées en matière de sécurité et de continuité. Les réglementations et référentiels peuvent imposer ou encourager :
- des politiques de sauvegarde documentées ;
- des plans de continuité d’activité ;
- des plans de reprise d’activité ;
- des mesures de cybersécurité adaptées ;
- une gestion stricte des accès ;
- une traçabilité des opérations ;
- une notification des incidents ;
- des audits réguliers ;
- des tests de restauration ;
- une maîtrise des prestataires et sous-traitants.
La résilience informatique aide les organisations à répondre à ces attentes. Elle permet de démontrer que l’entreprise ne se contente pas de réagir dans l’urgence, mais qu’elle a prévu des procédures, des responsabilités, des moyens techniques et des scénarios de reprise. Au-delà de la conformité, cette démarche renforce la confiance. Les clients, partenaires, investisseurs et fournisseurs sont plus rassurés lorsqu’une entreprise est capable d’expliquer comment elle protège ses systèmes, comment elle sauvegarde ses données et comment elle maintient son activité en cas d’incident.
Les risques liés aux erreurs humaines
Toutes les menaces ne proviennent pas d’attaques externes. Les erreurs humaines figurent parmi les causes fréquentes d’incidents informatiques. Une mauvaise manipulation, une suppression accidentelle, une configuration incorrecte, un mauvais paramétrage de droits d’accès ou une mise à jour mal préparée peuvent avoir des conséquences importantes. Un administrateur peut supprimer par erreur une base de données. Un collaborateur peut partager un document sensible avec le mauvais destinataire. Une équipe technique peut déployer une nouvelle version applicative contenant un dysfonctionnement. Un mot de passe faible ou réutilisé peut ouvrir la porte à une compromission. La résilience informatique permet de réduire l’impact de ces erreurs grâce à plusieurs mécanismes :
- des sauvegardes régulières et testées ;
- des droits d’accès limités selon les besoins réels ;
- des environnements de test avant mise en production ;
- des procédures de validation ;
- des journaux d’activité ;
- des contrôles de configuration ;
- des formations utilisateurs ;
- des plans de retour arrière en cas de déploiement défectueux.
L’objectif n’est pas de considérer l’humain comme une faiblesse, mais de construire un système capable d’absorber les erreurs inévitables. Une organisation résiliente accepte que des incidents puissent se produire et met en place des garde-fous pour éviter qu’une simple erreur ne devienne une crise majeure.
Les incidents techniques et environnementaux
Les infrastructures numériques peuvent également être touchées par des incidents techniques ou environnementaux. Une panne matérielle, une coupure électrique, une défaillance réseau, une saturation de serveur, une climatisation défectueuse dans une salle informatique, un incendie, une inondation ou une catastrophe naturelle peuvent interrompre brutalement les services. Ces risques concernent aussi bien les infrastructures internes que les services externalisés. Une entreprise peut subir l’indisponibilité d’un hébergeur, d’un fournisseur cloud, d’un opérateur télécom ou d’un éditeur SaaS. Même lorsque l’infrastructure n’est pas hébergée dans les locaux de l’entreprise, la responsabilité de la continuité doit être anticipée. La résilience informatique prévoit des solutions de secours pour éviter l’arrêt complet des services. Cela peut inclure :
- la redondance des serveurs ;
- la réplication des données ;
- des connexions internet de secours ;
- des alimentations électriques protégées ;
- des onduleurs ;
- des sites de secours ;
- des sauvegardes externalisées ;
- des architectures multi-cloud ou hybrides ;
- des procédures de bascule vers un environnement alternatif.
Ces dispositifs permettent de maintenir tout ou partie de l’activité même lorsqu’un composant technique devient indisponible.
La protection de l’image et de la confiance
Une panne informatique ne produit pas seulement des effets techniques. Elle peut aussi affecter l’image de l’entreprise. Des clients qui ne peuvent plus accéder à leur compte, passer commande, obtenir une assistance ou consulter leurs données peuvent rapidement perdre confiance. Lorsqu’un incident devient public, la qualité de la réaction compte autant que la cause du problème. Une communication confuse, une reprise trop lente ou une perte de données mal gérée peuvent aggraver la situation. À l’inverse, une entreprise capable d’informer clairement, de restaurer ses services et de limiter les impacts renforce sa crédibilité. La résilience informatique contribue donc directement à la réputation de l’organisation. Elle montre que l’entreprise anticipe les risques, protège ses utilisateurs et dispose d’une stratégie sérieuse pour faire face aux imprévus.
La maîtrise des coûts liés aux interruptions
Les interruptions informatiques ont un coût souvent sous-estimé. Elles peuvent provoquer une perte de chiffre d’affaires, une baisse de productivité, des pénalités contractuelles, des frais de réparation, des coûts d’expertise, des dépenses de communication, des indemnisations clients ou encore des investissements d’urgence. Plus l’interruption dure, plus les conséquences financières augmentent. Une entreprise qui n’a pas testé ses sauvegardes ou documenté ses procédures peut perdre un temps précieux au moment de restaurer ses services. À l’inverse, une organisation préparée sait quelles actions mener en priorité. La résilience informatique permet donc de réduire le coût global des incidents. Elle nécessite des investissements, mais ceux-ci sont généralement plus maîtrisables que les pertes provoquées par une interruption longue, une restauration impossible ou une crise mal gérée.

Comment mettre en place une stratégie de résilience informatique
Construire une infrastructure résiliente demande une approche globale mêlant technologies, organisation, gouvernance et anticipation des risques. La résilience informatique ne repose pas sur un unique outil ou une simple sauvegarde, en particulier lorsque l’on parle de réglementation DORA par exemple. Elle implique une combinaison de mesures techniques, de procédures opérationnelles et de bonnes pratiques destinées à maintenir la continuité des activités même en cas d’incident majeur. Pour être efficace, une stratégie de résilience informatique doit être pensée sur le long terme. Elle doit prendre en compte les besoins métiers, les applications critiques, les dépendances techniques, les contraintes réglementaires et les menaces susceptibles d’affecter l’organisation. L’objectif est de réduire les interruptions, protéger les données, accélérer la reprise et limiter les impacts financiers et opérationnels. Plusieurs actions permettent d’améliorer concrètement la résilience informatique d’une entreprise.
| Bonne pratique | Objectif et bénéfices |
|---|---|
| Mettre en place des sauvegardes fiables | Garantir la restauration des données et limiter les pertes en cas de panne, d’erreur humaine, de suppression accidentelle ou de cyberattaque. |
| Automatiser les sauvegardes | Éviter les oublis humains et assurer une protection continue des données critiques de l’entreprise. |
| Externaliser une partie des sauvegardes | Préserver les données en cas d’incident physique touchant les locaux, comme un incendie, une inondation ou un vol. |
| Tester régulièrement les restaurations | Vérifier que les sauvegardes sont exploitables et que les données peuvent être récupérées rapidement. |
| Déployer des infrastructures redondantes | Assurer la continuité des services grâce à des systèmes capables de prendre automatiquement le relais. |
| Mettre en place une redondance réseau | Maintenir les communications et l’accès aux applications même en cas de panne d’un équipement ou d’un fournisseur internet. |
| Utiliser des alimentations électriques de secours | Limiter les interruptions liées aux coupures électriques grâce aux onduleurs et groupes électrogènes. |
| Répliquer les données sur plusieurs sites | Réduire les risques de perte totale des informations et améliorer la disponibilité des applications. |
| Élaborer un plan de reprise d’activité | Organiser le redémarrage des services après un incident majeur afin de réduire les interruptions. |
| Définir les applications prioritaires | Concentrer les efforts de reprise sur les services indispensables au fonctionnement de l’entreprise. |
| Créer des scénarios de crise | Préparer les équipes à réagir rapidement face à différents types d’incidents informatiques. |
| Documenter les procédures d’urgence | Faciliter les interventions techniques et réduire les pertes de temps pendant une situation critique. |
| Superviser les infrastructures en continu | Détecter rapidement les anomalies, les pannes ou les comportements suspects avant qu’ils ne deviennent critiques. |
| Mettre en place des alertes automatiques | Informer immédiatement les équipes techniques lorsqu’un incident ou une activité inhabituelle est détecté. |
| Analyser les journaux d’événements | Identifier les tentatives d’intrusion, les erreurs techniques et les dysfonctionnements récurrents. |
| Utiliser des outils de détection d’intrusion | Repérer les comportements suspects et limiter les risques de compromission du système d’information. |
| Former les collaborateurs | Réduire les erreurs humaines et améliorer les réactions face aux incidents de sécurité. |
| Sensibiliser au phishing | Limiter les risques liés aux courriels frauduleux et aux tentatives de vol d’identifiants. |
| Former aux bonnes pratiques de cybersécurité | Encourager des comportements plus sûrs dans l’utilisation quotidienne des outils numériques. |
| Organiser des exercices de simulation | Préparer les équipes à réagir efficacement lors d’une cyberattaque ou d’une panne importante. |
| Segmenter les réseaux et les accès | Limiter la propagation d’une attaque ou d’un dysfonctionnement à l’ensemble du système d’information. |
| Appliquer le principe du moindre privilège | Réduire les risques liés aux accès excessifs en attribuant uniquement les droits nécessaires aux utilisateurs. |
| Mettre en place l’authentification multifacteur | Renforcer la sécurité des comptes et réduire les risques de compromission des accès sensibles. |
| Contrôler les accès distants | Protéger les connexions externes utilisées dans le cadre du télétravail ou des interventions à distance. |
| Tester régulièrement les procédures | Vérifier que les sauvegardes, les plans de reprise et les dispositifs de secours fonctionnent réellement. |
| Simuler des scénarios de panne | Identifier les faiblesses organisationnelles et techniques avant qu’un incident réel ne survienne. |
| Tester les plans de bascule | Valider la capacité des systèmes de secours à prendre le relais rapidement. |
| Réaliser des audits de sécurité | Détecter les vulnérabilités techniques et améliorer la posture globale de sécurité. |
| Mettre à jour les systèmes | Réduire les vulnérabilités exploitables par des cyberattaquants ou des logiciels malveillants. |
| Appliquer les correctifs de sécurité rapidement | Limiter les risques liés aux failles connues des logiciels et des équipements. |
| Maintenir un inventaire des équipements | Identifier plus facilement les systèmes obsolètes ou non sécurisés. |
| Remplacer les technologies obsolètes | Réduire les risques liés aux systèmes qui ne bénéficient plus de mises à jour ou de support technique. |
| Documenter les processus critiques | Faciliter les interventions et accélérer la reprise des activités lors d’une situation de crise. |
| Centraliser les procédures techniques | Permettre aux équipes de retrouver rapidement les informations nécessaires en cas d’urgence. |
| Maintenir une cartographie du système d’information | Visualiser les dépendances techniques et mieux anticiper les impacts d’un incident. |
| Évaluer régulièrement les risques | Adapter les mesures de protection à l’évolution des usages, des menaces et des infrastructures. |
| Identifier les actifs critiques | Concentrer les ressources de sécurité sur les systèmes et données les plus sensibles. |
| Analyser les dépendances fournisseurs | Anticiper les conséquences d’une panne ou d’un incident chez un prestataire externe. |
| Suivre les indicateurs de disponibilité | Mesurer les performances des infrastructures et améliorer continuellement la résilience informatique. |
| Mettre en œuvre une politique de gestion des accès | Contrôler précisément qui peut accéder aux ressources sensibles et dans quelles conditions. |
| Chiffrer les données sensibles | Protéger les informations stratégiques contre le vol, l’interception ou les accès non autorisés. |
| Prévoir un site de secours | Maintenir l’activité de l’entreprise même si le site principal devient totalement indisponible. |
| Mettre en place une gouvernance de crise | Coordonner les décisions, la communication et les actions techniques pendant un incident majeur. |
| Contrôler les équipements mobiles | Réduire les risques liés aux ordinateurs portables, smartphones et appareils utilisés hors du réseau interne. |
| Utiliser des solutions EDR/XDR | Détecter plus rapidement les comportements malveillants sur les postes de travail et les serveurs. |
| Limiter les dépendances techniques uniques | Éviter qu’un seul composant ou fournisseur puisse provoquer l’arrêt complet de l’activité. |
| Surveiller les performances applicatives | Identifier les ralentissements et prévenir les interruptions avant qu’elles n’impactent les utilisateurs. |
| Définir une politique de continuité d’activité | Structurer les priorités de l’entreprise afin de maintenir les fonctions essentielles pendant une crise. |
| Contrôler les prestataires et sous-traitants | Réduire les risques liés aux services externalisés et aux dépendances cloud. |
| Réaliser une veille sur les menaces | Anticiper les nouvelles vulnérabilités, techniques d’attaque et tendances en cybersécurité. |
Mettre en place des sauvegardes fiables
Les sauvegardes représentent l’un des fondements de la résilience informatique. Lorsqu’une entreprise subit une panne, une suppression accidentelle de données, un incident matériel ou une attaque par ransomware, la capacité à restaurer rapidement les informations devient déterminante. Une sauvegarde efficace ne consiste pas uniquement à copier des fichiers sur un disque dur externe. Elle doit répondre à plusieurs exigences :
- être automatisée afin d’éviter les oublis ;
- être réalisée régulièrement ;
- couvrir les données critiques ;
- être stockée sur plusieurs supports ;
- être isolée du système principal ;
- être protégée contre les logiciels malveillants ;
- être testée fréquemment ;
- permettre une restauration rapide.
La règle du “3-2-1” reste une référence largement utilisée :
- 3 copies des données ;
- 2 supports différents ;
- 1 sauvegarde externalisée hors site.
Certaines organisations ajoutent même une quatrième exigence : une copie totalement déconnectée du réseau afin d’éviter qu’un ransomware ne chiffre également les sauvegardes. Les tests de restauration sont essentiels. Une sauvegarde non testée peut se révéler inutilisable au moment où l’entreprise en a besoin. Les équipes doivent donc vérifier régulièrement :
- l’intégrité des données sauvegardées ;
- la rapidité de restauration ;
- la compatibilité des fichiers ;
- la disponibilité des environnements de secours ;
- la cohérence des applications restaurées.
Déployer des infrastructures redondantes
La redondance consiste à dupliquer certains composants afin qu’un système de secours prenne automatiquement ou manuellement le relais lorsqu’un équipement devient indisponible. Cette approche limite les interruptions de service et améliore la disponibilité globale des applications critiques. Elle peut concerner :
- les serveurs ;
- les baies de stockage ;
- les équipements réseau ;
- les bases de données ;
- les alimentations électriques ;
- les connexions internet ;
- les centres de données ;
- les systèmes de refroidissement ;
- les services cloud.
Les architectures cloud modernes facilitent fortement cette redondance grâce à la réplication géographique, aux environnements multi-zones et aux infrastructures distribuées. Par exemple, une entreprise peut héberger ses applications sur plusieurs centres de données afin qu’un site secondaire prenne automatiquement le relais si le site principal rencontre un problème. La redondance ne doit toutefois pas être limitée à la technique. Les compétences humaines représentent aussi un élément important. Une seule personne ne devrait jamais être la seule à maîtriser un système critique.
Élaborer un plan de reprise d’activité
Le plan de reprise d’activité, souvent appelé PRA, définit les procédures à suivre après un incident majeur afin de remettre les systèmes en fonctionnement dans les meilleurs délais. Ce document précise notamment :
- les rôles et responsabilités des équipes ;
- les applications prioritaires ;
- les délais de reprise attendus ;
- les procédures de restauration ;
- les contacts d’urgence ;
- les scénarios de crise ;
- les solutions de secours ;
- les procédures de communication.
Un PRA efficace doit être clair, accessible et régulièrement mis à jour. Une procédure obsolète ou incomplète peut ralentir fortement la reprise des activités. Les entreprises les plus matures organisent des exercices de simulation afin de tester leurs procédures dans des conditions réalistes. Ces exercices permettent d’identifier les points faibles avant qu’un incident réel ne survienne. Les notions de RTO et de RPO sont également essentielles :
| Indicateur | Définition |
|---|---|
| RTO (Recovery Time Objective) | Délai maximal acceptable pour remettre un service en fonctionnement après un incident. |
| RPO (Recovery Point Objective) | Quantité maximale de données que l’entreprise accepte de perdre entre deux sauvegardes. |
Ces indicateurs permettent de définir les priorités techniques et les investissements nécessaires.
Surveiller les infrastructures en continu
La supervision informatique joue un rôle central dans la résilience. Plus un incident est détecté tôt, plus il est facile de limiter ses conséquences. Les outils modernes de supervision analysent en temps réel :
- les performances réseau ;
- la disponibilité des serveurs ;
- la consommation des ressources ;
- les comportements suspects ;
- les tentatives d’intrusion ;
- les journaux d’événements ;
- les erreurs applicatives ;
- les ralentissements anormaux ;
- les accès non autorisés.
Certaines solutions utilisent également l’intelligence artificielle et l’analyse comportementale afin de détecter des anomalies difficiles à identifier manuellement. Une surveillance efficace permet :
- d’anticiper certaines pannes ;
- de réagir plus rapidement ;
- de réduire les temps d’interruption ;
- d’améliorer les performances ;
- de faciliter les analyses après incident.
Former les collaborateurs
La résilience informatique ne dépend pas uniquement des technologies. Les utilisateurs jouent également un rôle majeur dans la sécurité et la continuité des systèmes. Une grande partie des incidents provient d’erreurs humaines : ouverture d’un fichier malveillant, utilisation d’un mot de passe faible, partage accidentel de données sensibles ou mauvaise manipulation technique. Les formations permettent de sensibiliser les équipes :
- aux risques de phishing ;
- aux bonnes pratiques de sécurité ;
- à la gestion des mots de passe ;
- à l’utilisation de l’authentification multifacteur ;
- aux procédures d’urgence ;
- aux comportements à adopter en cas d’incident ;
- à la protection des données ;
- à la détection des comportements suspects.
Les exercices de simulation de phishing sont également très utilisés afin d’évaluer le niveau de vigilance des collaborateurs. Une culture de cybersécurité solide améliore fortement la capacité de réaction des équipes et réduit les risques liés aux comportements imprudents.
Segmenter les réseaux et contrôler les accès
La segmentation réseau permet de limiter la propagation d’un incident. Si une machine est compromise, l’attaque ne doit pas pouvoir atteindre automatiquement l’ensemble du système d’information. Cette approche consiste à séparer les environnements selon leur niveau de sensibilité :
- réseau utilisateurs ;
- serveurs critiques ;
- objets connectés ;
- réseaux invités ;
- applications sensibles ;
- outils industriels.
Le contrôle des accès est également essentiel. Chaque utilisateur doit uniquement disposer des droits nécessaires à ses missions. Les entreprises mettent souvent en place :
- l’authentification multifacteur ;
- la gestion centralisée des identités ;
- des politiques de mots de passe robustes ;
- la journalisation des accès ;
- des contrôles d’accès conditionnels.
Tester régulièrement les dispositifs de résilience
Une stratégie de résilience informatique ne peut être efficace sans tests réguliers. Les entreprises doivent vérifier que les procédures fonctionnent réellement dans des conditions proches de la réalité. Ces tests peuvent inclure :
- des restaurations de sauvegardes ;
- des simulations de panne ;
- des exercices de crise ;
- des tests de bascule vers un site secondaire ;
- des audits de sécurité ;
- des analyses de vulnérabilités.
Ces exercices permettent d’identifier les lacunes techniques, les erreurs de procédure ou les difficultés organisationnelles avant qu’un incident réel ne survienne. Ainsi, mettre en place une stratégie de résilience informatique demande une démarche continue et structurée. Sauvegardes fiables, infrastructures redondantes, supervision, formation des utilisateurs, plans de reprise et contrôle des accès doivent fonctionner ensemble afin de garantir la stabilité et la continuité des activités numériques.

0 commentaires