À l’heure où les environnements numériques soutiennent la majorité des activités professionnelles, assurer la fiabilité des infrastructures informatiques est devenu indispensable. Une panne soudaine de serveurs, en pleine journée, peut suffire à paralyser l’accès aux données, interrompre les applications métiers et dégrader l’expérience client. Les conséquences peuvent être lourdes, tant sur le plan financier que sur l’image de l’entreprise. C’est précisément dans ce contexte que la supervision d’infrastructure informatique s’impose comme un levier clé. Elle dépasse largement la simple surveillance en offrant des capacités d’anticipation, de détection et de résolution des incidents avant qu’ils n’affectent le fonctionnement global. Aujourd’hui, la supervision informatique adopte une approche résolument proactive. Elle ne se limite plus à constater les anomalies : elle les analyse, déclenche des alertes pertinentes et peut même automatiser certaines corrections. Mais que signifie réellement superviser une infrastructure ? Quels en sont les objectifs, les mécanismes et les bénéfices pour les systèmes d’information ? Cet article vous propose d’explorer en profondeur cette pratique devenue incontournable pour garantir performance et continuité.
Une définition de la supervision d’infrastructure informatique pour commencer
La supervision d’infrastructure informatique désigne l’ensemble des méthodes, outils, protocoles et processus utilisés pour observer en continu l’état de santé d’un système d’information. Elle permet de contrôler la disponibilité, les performances, la capacité et le comportement des composants techniques qui soutiennent les services numériques d’une organisation. Cela concerne notamment les serveurs physiques ou virtuels, les équipements réseau, les systèmes de stockage, les bases de données, les hyperviseurs, les conteneurs, les applications, les services cloud et les postes critiques. Sur le plan technique, superviser une infrastructure revient à collecter des données mesurables, appelées métriques, afin de comprendre le fonctionnement réel du système. Ces métriques peuvent concerner l’usage du processeur, la mémoire vive, l’espace disque, les entrées-sorties, la latence réseau, le taux de perte de paquets, le nombre de connexions simultanées, le temps de réponse d’une application ou encore le taux d’erreur d’un service web. Ces informations sont ensuite centralisées, analysées et comparées à des seuils définis à l’avance. Lorsque l’un de ces seuils est dépassé, l’outil de supervision déclenche une alerte. Celle-ci peut être envoyée par e-mail, SMS, messagerie instantanée, outil ITSM ou système de ticketing. L’objectif est de permettre aux équipes informatiques d’intervenir rapidement, avant qu’un dysfonctionnement ne provoque une interruption de service visible par les utilisateurs. Une supervision bien conçue ne se limite donc pas à constater une panne : elle aide à l’anticiper, à en identifier la cause probable et à accélérer sa résolution.
Historiquement, la supervision informatique s’est développée avec la montée en complexité des systèmes d’information. Dans les années 1960 et 1970, les environnements étaient principalement centrés sur les mainframes. La surveillance était alors très liée aux consoles d’exploitation et aux journaux systèmes. Les opérateurs contrôlaient manuellement l’état des traitements, des files d’attente et des ressources matérielles. Dans les années 1980 et 1990, avec la généralisation des réseaux locaux, des architectures client-serveur et d’Internet, la supervision a pris une nouvelle dimension. Le protocole SNMP, défini à la fin des années 1980, a joué un rôle majeur dans cette évolution. Il a permis d’interroger des équipements réseau comme les routeurs, les commutateurs, les pare-feu ou les imprimantes, afin de récupérer des informations standardisées sur leur état et leurs performances. C’est à cette période que la supervision réseau s’est imposée comme une discipline à part entière. À partir des années 2000, l’essor de la virtualisation, des applications web et des architectures distribuées a rendu les infrastructures plus dynamiques. Il ne suffisait plus de savoir si un serveur était allumé ou si une interface réseau répondait. Il fallait aussi mesurer la qualité de service, la disponibilité applicative, le comportement des bases de données, les dépendances entre composants et l’expérience utilisateur. Les outils de supervision ont alors évolué vers des tableaux de bord plus complets, des systèmes d’alerting plus fins et des analyses historiques permettant d’identifier les tendances.
Depuis les années 2010, l’arrivée massive du cloud, des conteneurs, des microservices et des pratiques DevOps a encore transformé la supervision. Les infrastructures sont devenues plus éphémères, automatisées et réparties entre plusieurs environnements : Datacenters internes, clouds publics, clouds privés et services SaaS. Cette évolution a fait émerger la notion d’observabilité, qui complète la supervision traditionnelle en s’appuyant sur trois grands piliers : les métriques, les logs et les traces. L’objectif n’est plus seulement de savoir qu’un incident existe, mais de comprendre précisément pourquoi il se produit dans un système complexe. Il faut donc distinguer plusieurs notions proches, mais complémentaires. La supervision consiste à surveiller des indicateurs connus et à déclencher des alertes lorsque des seuils sont dépassés. Le monitoring désigne souvent cette même démarche de mesure continue, avec une connotation plus technique et opérationnelle. L’observabilité, elle, va plus loin : elle cherche à rendre le système compréhensible de l’intérieur, même lorsqu’un problème n’a pas été prévu à l’avance. Enfin, l’alerting (que l’on retrouve particulièrement avec des solutions pour auditer un serveur web) correspond au mécanisme de notification qui transforme une anomalie détectée en action pour les équipes d’exploitation. Dans une infrastructure moderne, plusieurs formes de supervision coexistent :
- La supervision système : Elle surveille les serveurs, machines virtuelles, systèmes d’exploitation, ressources CPU, mémoire, disque et processus ;
- La supervision réseau : Elle contrôle la disponibilité des équipements, la bande passante, la latence, les erreurs d’interface, les routes et la connectivité ;
- La supervision applicative : elle mesure les temps de réponse, les erreurs, les transactions, les API, les services web et les dépendances logicielles ;
- La supervision base de données : Elle analyse les requêtes lentes, les verrous, les connexions, les index, la réplication et la consommation de ressources ;
- La supervision cloud : Elle suit les instances, services managés, coûts, quotas, performances et événements provenant des plateformes cloud ;
- La supervision métier : Elle vérifie que les processus essentiels fonctionnent correctement, comme une commande en ligne, un paiement, une synchronisation ou un traitement automatisé.
Cette diversité montre que la supervision d’infrastructure informatique ne se limite pas à une simple vérification technique. Elle constitue une couche de pilotage indispensable pour comprendre l’état réel du système d’information, réduire les interruptions, fiabiliser les services et améliorer la qualité perçue par les utilisateurs. Plus l’infrastructure est complexe, plus la supervision devient un moyen de garder une vision claire, exploitable et centralisée de l’ensemble de l’écosystème numérique.

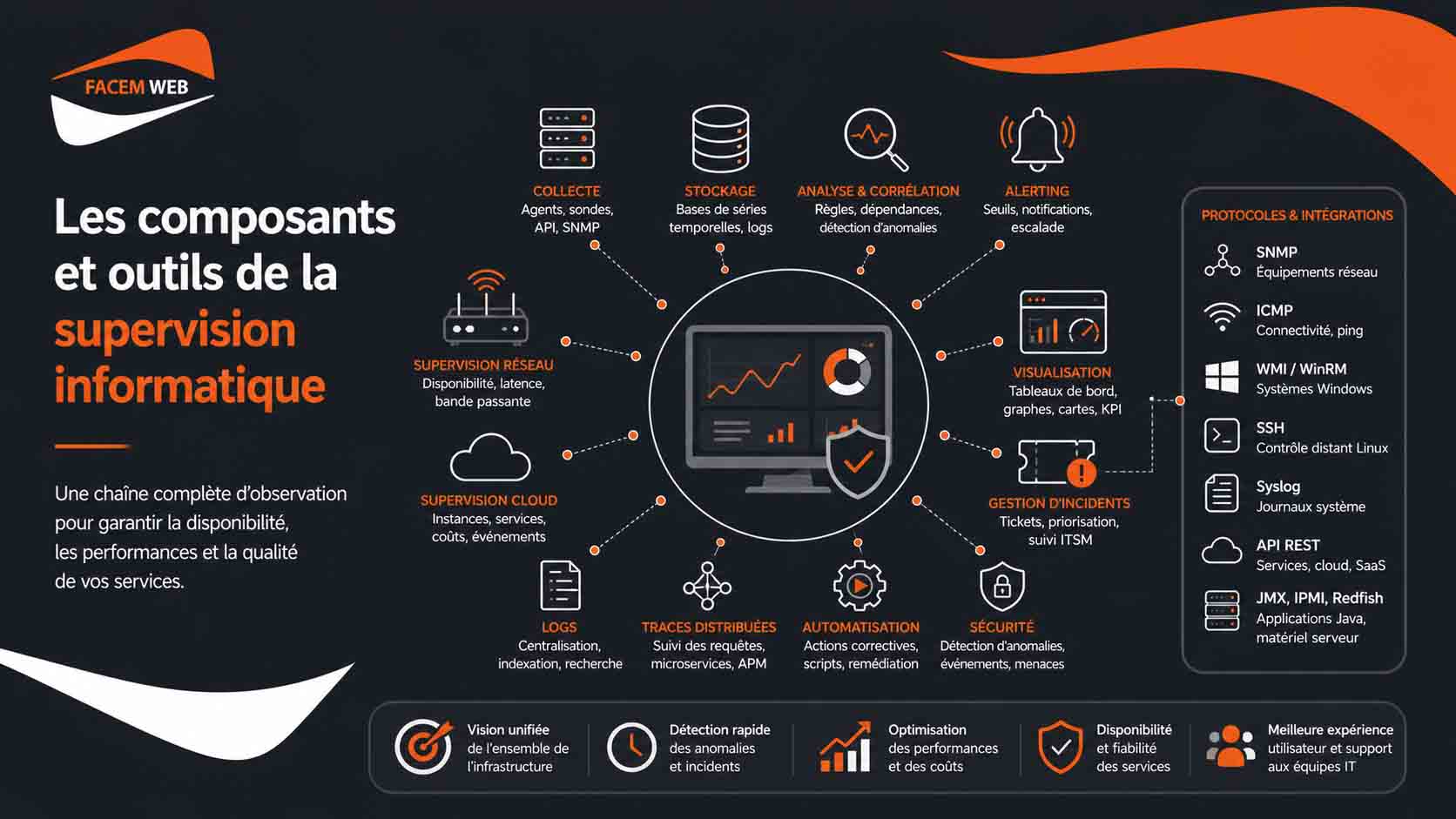
Les composants et outils de la supervision informatique
La mise en place d’une supervision informatique fiable repose sur un ensemble de briques techniques qui travaillent ensemble : collecte des données, stockage, analyse, visualisation, alerting, corrélation et automatisation. Une plateforme de supervision ne se résume donc pas à un tableau de bord. Elle constitue une chaîne complète d’observation et de traitement, depuis la remontée d’une métrique brute jusqu’à l’ouverture d’un ticket d’incident ou au déclenchement d’une action corrective. Le premier composant est le mécanisme de collecte. Il peut prendre la forme d’un agent installé sur un serveur, d’une sonde réseau, d’un exporteur de métriques, d’un collecteur de logs ou d’une connexion directe à une API. L’agent interroge le système local et transmet des informations vers une plateforme centrale. Sur un serveur Linux, il peut remonter la charge CPU, l’utilisation mémoire, l’espace disque, les processus actifs ou les journaux système. Sur un serveur Windows, il peut collecter les compteurs de performance, les événements système et l’état des services. Dans un environnement cloud, il récupère plutôt des données issues de services comme Amazon CloudWatch, Azure Monitor ou Google Cloud Operations. La collecte peut aussi fonctionner sans agent, en s’appuyant sur des protocoles standards. C’est le cas de SNMP, très utilisé pour les équipements réseau comme les routeurs, commutateurs, pare-feu, onduleurs ou baies de stockage. Le protocole ICMP, à travers des tests de type ping, permet de vérifier qu’un hôte répond sur le réseau. WMI est fréquemment utilisé dans les environnements Windows pour accéder à des informations système à distance. Les API REST, quant à elles, sont devenues incontournables pour superviser des services modernes, des plateformes SaaS, des orchestrateurs Kubernetes ou des services cloud.
Une fois collectées, les données sont centralisées dans un moteur de traitement. Celui-ci agrège les informations, les normalise, les horodate et les compare à des règles de supervision. Ces règles peuvent être simples, par exemple déclencher une alerte lorsque l’espace disque dépasse 90 %, ou plus avancées, comme détecter une augmentation progressive de la latence sur une application critique. Les outils modernes permettent aussi de définir des dépendances entre composants afin d’éviter les cascades d’alertes inutiles. Par exemple, si un routeur principal devient indisponible, il n’est pas pertinent d’envoyer des dizaines d’alertes pour tous les serveurs situés derrière ce routeur.
Le stockage des données joue également un rôle majeur. Les métriques sont généralement enregistrées dans des bases de données temporelles, capables de conserver des valeurs associées à des dates précises. Cela permet de consulter l’historique d’un serveur, d’analyser une tendance de consommation mémoire, de repérer une saturation récurrente ou de prévoir un besoin d’augmentation de capacité. Des solutions comme Prometheus, InfluxDB, Graphite ou VictoriaMetrics sont souvent utilisées pour ce type de stockage orienté séries temporelles. Les logs constituent une autre source d’information essentielle. Contrairement aux métriques, qui donnent une mesure chiffrée, les logs décrivent des événements : erreur applicative, tentative de connexion, redémarrage d’un service, échec de sauvegarde ou anomalie de sécurité. Des outils comme Elasticsearch, Logstash, Kibana, OpenSearch, Graylog, Splunk ou Loki permettent de centraliser, indexer et analyser ces journaux. Dans une infrastructure complexe, la corrélation entre métriques et logs permet souvent d’identifier plus rapidement la cause d’un incident. La supervision moderne intègre aussi les traces distribuées. Elles permettent de suivre le parcours d’une requête à travers plusieurs services, API, bases de données et microservices. Cette approche est particulièrement utile dans les architectures cloud-native, où une transaction utilisateur peut traverser de nombreux composants avant d’aboutir. Des outils comme Jaeger, Zipkin, OpenTelemetry, Datadog APM ou New Relic permettent d’analyser ces traces et de localiser les ralentissements dans une chaîne applicative.
La visualisation est un autre pilier de la supervision informatique. Les tableaux de bord transforment des données techniques en informations lisibles. Ils affichent des graphiques, jauges, courbes de tendance, cartes réseau, indicateurs de disponibilité, taux d’erreur ou temps de réponse applicatif. Grafana est l’un des outils les plus utilisés pour construire ces tableaux de bord, notamment avec Prometheus, Loki, InfluxDB ou Elasticsearch. Kibana est souvent associé à la recherche et à l’analyse de logs. D’autres solutions, comme Centreon, Zabbix, PRTG Network Monitor, Nagios XI, Checkmk, Datadog, Dynatrace ou New Relic, proposent leurs propres interfaces de visualisation. L’alerting transforme l’observation en action. Il consiste à prévenir les bonnes personnes lorsqu’un seuil est dépassé ou qu’un comportement anormal est détecté. Une alerte efficace doit être précise, contextualisée et priorisée. Elle doit indiquer le composant concerné, la nature de l’anomalie, son niveau de gravité, son heure de détection et, si possible, une piste de diagnostic. Les notifications peuvent être envoyées vers des outils comme PagerDuty, Opsgenie, ServiceNow, Jira Service Management, GLPI, Microsoft Teams, Slack ou une boîte mail d’exploitation. L’un des enjeux majeurs consiste à éviter la fatigue d’alerte. Lorsque les équipes reçoivent trop de notifications non pertinentes, elles finissent par perdre en réactivité. Pour limiter ce phénomène, les plateformes avancées proposent de la déduplication, de la corrélation d’événements, des fenêtres de maintenance, des règles d’escalade et des niveaux de criticité. Une alerte sur un serveur de test n’a pas le même impact qu’une alerte sur une base de données de production utilisée par l’ensemble de l’entreprise.
Les outils de supervision modernes intègrent aussi des fonctions d’automatisation. Il devient possible de redémarrer automatiquement un service bloqué, d’augmenter une capacité cloud, de vider un cache, de lancer un script de diagnostic ou d’ouvrir un ticket enrichi avec les métriques utiles. Cette approche s’inscrit dans les pratiques d’AIOps et de remédiation automatique. L’objectif n’est pas de remplacer les équipes informatiques, mais de leur faire gagner du temps sur les incidents répétitifs et bien identifiés. Voici les principaux composants que l’on retrouve dans une architecture de supervision informatique :
| Composant | Rôle dans la supervision de l’infrastructure informatique |
|---|---|
| Agent de collecte | Installé sur un serveur, une machine virtuelle ou un conteneur, il collecte en continu les métriques système (CPU, mémoire, disque), les processus, les journaux locaux et l’état des services afin de fournir une vision détaillée du fonctionnement interne. |
| Sonde réseau | Surveille les équipements réseau via ICMP, SNMP ou NetFlow afin de mesurer la latence, la disponibilité, la bande passante, les erreurs d’interface et d’identifier les anomalies de connectivité. |
| Exporteur de métriques | Expose des données techniques spécifiques (bases de données, systèmes Linux, Kubernetes, applications) dans un format standardisé pour ingestion par des outils comme Prometheus. |
| Collecteur de logs | Centralise et agrège les journaux provenant de multiples sources (serveurs, applications, sécurité, équipements réseau) pour faciliter la recherche, la corrélation et l’analyse des événements. |
| Base de séries temporelles | Stocke les métriques horodatées avec une forte capacité d’ingestion et de compression afin de permettre l’analyse historique, la détection d’anomalies et la planification de capacité. |
| Moteur d’alerting | Analyse les métriques et événements en temps réel, compare avec des seuils ou modèles et déclenche des alertes contextualisées vers les équipes concernées. |
| Tableau de bord | Offre une visualisation synthétique et interactive des données via des graphiques, jauges et indicateurs clés pour un pilotage rapide de l’infrastructure. |
| Gestionnaire d’incidents | Convertit les alertes en tickets exploitables, facilite la priorisation, l’escalade, le suivi et la documentation des incidents dans une logique ITSM. |
| Moteur de corrélation | Analyse les relations entre événements multiples pour identifier une cause racine, réduire le bruit d’alerte et améliorer la pertinence des diagnostics. |
| Module d’automatisation | Déclenche des actions correctives automatiques (scripts, redémarrage de services, ajustement de ressources cloud) pour réduire le temps de résolution des incidents. |
| Collecteur de traces distribuées | Suit le parcours des requêtes dans les architectures microservices afin d’identifier les latences, les erreurs et les dépendances entre composants applicatifs. |
| Orchestrateur de supervision | Coordonne l’ensemble des composants de supervision, gère les configurations, les politiques de collecte et les règles d’alerte à grande échelle. |
| Connecteur API | Interroge des services cloud, SaaS ou applications tierces via API REST pour collecter des données spécifiques non accessibles via des agents traditionnels. |
| Système de notification | Diffuse les alertes via différents canaux (email, SMS, Slack, Teams, PagerDuty) en fonction de la criticité et des politiques de notification. |
| Gestionnaire de dépendances | Cartographie les relations entre composants (applications, serveurs, réseau) afin de mieux comprendre l’impact d’une panne sur l’ensemble du système. |
| Module de reporting | Génère des rapports périodiques sur la disponibilité, la performance, les incidents et les tendances pour aider à la prise de décision stratégique. |
| Analyseur prédictif | Utilise des modèles statistiques ou du machine learning pour anticiper les pannes, détecter des comportements anormaux et proposer des actions préventives. |
| Supervision de sécurité | Surveille les événements liés à la sécurité (tentatives d’intrusion, anomalies réseau, accès suspects) et contribue à la détection des menaces. |
| Supervision cloud | Suit les ressources cloud (instances, stockage, réseau, coûts) et garantit leur disponibilité dans des environnements distribués et dynamiques. |
Le choix des outils dépend du contexte technique, de la taille de l’organisation, du niveau d’exigence et du budget. Certaines solutions sont open source, d’autres commerciales, et beaucoup d’environnements combinent plusieurs outils spécialisés. Nagios, apparu à la fin des années 1990, reste une référence historique pour la supervision d’hôtes et de services. Zabbix est apprécié pour son approche complète et son interface intégrée. Centreon est très présent dans les environnements francophones et les grandes infrastructures. Checkmk propose une découverte automatique efficace et une supervision détaillée des services. PRTG Network Monitor est souvent utilisé pour les réseaux et les environnements Windows. Dans les architectures orientées DevOps et cloud-native, Prometheus s’est imposé comme une solution majeure pour la collecte de métriques, notamment avec Kubernetes. Grafana est largement utilisé pour la visualisation. Loki permet de centraliser les logs dans une logique proche de Prometheus. OpenTelemetry apporte un standard ouvert pour collecter métriques, logs et traces. Dans les environnements d’entreprise où l’on recherche une plateforme intégrée, des solutions comme Datadog, Dynatrace, New Relic ou Splunk offrent des fonctionnalités avancées d’observabilité, d’analyse applicative, de corrélation et parfois d’intelligence artificielle appliquée aux opérations IT.
Les protocoles et standards restent au cœur de cette architecture. SNMP permet d’interroger des équipements réseau. ICMP vérifie la connectivité de base. WMI et WinRM servent à collecter des informations sur les systèmes Windows. SSH est souvent utilisé pour exécuter des commandes de contrôle sur des serveurs Linux. Syslog permet de transmettre des journaux système. Les API REST facilitent l’intégration avec les services modernes. JMX est utilisé pour superviser des applications Java. IPMI ou Redfish permettent de surveiller certains paramètres matériels des serveurs, comme l’alimentation, les ventilateurs ou la température. Dans les environnements hybrides, la supervision doit aussi couvrir les ressources réparties entre le datacenter interne, les clouds publics, les services SaaS et les sites distants. Cette situation impose une vision unifiée. Les équipes doivent pouvoir suivre, depuis une même interface, l’état d’un cluster Kubernetes, d’une base PostgreSQL, d’un pare-feu, d’un lien VPN, d’une instance cloud, d’un stockage objet, d’une application métier et d’un service d’authentification. Sans centralisation, le diagnostic devient lent, fragmenté et dépendant de trop nombreux outils isolés. Enfin, une bonne supervision repose aussi sur une méthode : Définir les bons indicateurs, documenter les seuils, hiérarchiser les alertes, identifier les services critiques, maintenir une cartographie des dépendances et revoir régulièrement les tableaux de bord. Un outil mal configuré peut générer du bruit, masquer les vrais incidents ou donner une fausse impression de sécurité. À l’inverse, une supervision bien pensée devient un véritable poste de pilotage pour les équipes IT, capable d’améliorer la disponibilité, la performance et la qualité de service.
Le rôle stratégique de la supervision dans les systèmes d’information
La supervision d’infrastructure informatique dépasse largement la simple surveillance opérationnelle pour s’imposer comme un véritable levier de pilotage des systèmes d’information. Elle contribue directement à la continuité de service en permettant une détection précoce des anomalies, qu’il s’agisse de dégradations de performance, de saturations de ressources ou de défaillances matérielles. Dans des environnements où les architectures sont distribuées (multi-sites, cloud hybride, microservices), la supervision permet de corréler des événements provenant de différentes couches techniques afin d’identifier rapidement les causes racines. Cette capacité réduit significativement le MTTR (Mean Time To Repair) et améliore le MTBF (Mean Time Between Failures), deux indicateurs clés dans la gestion de la disponibilité des services. Sur le plan de la performance et de l’optimisation, la supervision joue un rôle central dans l’analyse fine des ressources et des flux. Grâce aux métriques collectées en continu (CPU, mémoire, I/O, latence réseau, temps de réponse applicatif), il devient possible d’identifier précisément les goulets d’étranglement et d’ajuster les capacités en fonction des besoins réels. Cette approche s’inscrit dans une logique de capacity planning et de FinOps dans les environnements cloud, où chaque ressource consommée a un impact direct sur les coûts. En parallèle, la supervision applicative (APM) permet de suivre les transactions métier de bout en bout, d’analyser les dépendances entre services et d’optimiser l’expérience utilisateur. Elle devient ainsi un outil d’aide à la décision pour dimensionner correctement une infrastructure, prioriser les investissements et aligner les performances IT avec les objectifs métiers.
La supervision constitue également un pilier dans les stratégies de sécurité et de gouvernance des systèmes d’information. En analysant les logs, les événements et les comportements anormaux, elle permet de détecter des activités suspectes, des tentatives d’intrusion ou des dérives d’usage. Intégrée à des solutions de type SIEM ou enrichie par des mécanismes d’analyse comportementale, elle participe activement à la réduction des risques. Par ailleurs, les données issues de la supervision alimentent des rapports détaillés sur la disponibilité, la performance et la qualité de service, facilitant ainsi la prise de décision stratégique. Dans une logique d’amélioration continue, ces informations permettent d’identifier les incidents récurrents, d’en analyser les causes profondes et de mettre en œuvre des actions correctives durables, contribuant à renforcer la résilience globale du système d’information.

0 commentaires