Une panne serveur en pleine journée, un ransomware qui chiffre l’ensemble des fichiers critiques ou encore un incendie dans une salle informatique : ces scénarios ne relèvent plus de la fiction. Dans un environnement où les systèmes d’information sont au cœur des opérations, chaque minute d’indisponibilité peut engendrer des pertes importantes et désorganiser toute une activité. C’est dans cette réalité que le plan de reprise d’activité, plus connu sous l’acronyme PRA, s’impose comme un levier incontournable de résilience numérique. En tant qu’expert en informatique et en infogérance, il est évident que le PRA ne doit jamais être perçu comme une simple formalité. Il s’agit d’un dispositif structuré, pensé en amont, qui permet de restaurer rapidement les services essentiels après un incident majeur. Son efficacité repose autant sur la rigueur technique que sur l’anticipation des risques métiers.
La définition du PRA et son rôle dans l’entreprise
Le plan de reprise d’activité (PRA) est un dispositif structuré qui combine des procédures documentées, des architectures techniques spécifiques et des mécanismes d’orchestration permettant de restaurer un système d’information après une interruption majeure. Cette interruption peut être liée à une défaillance matérielle (panne serveur, stockage défectueux), logicielle (bug critique, corruption de base de données), humaine (erreur de manipulation) ou malveillante (cyberattaque, ransomware). Le PRA ne se limite donc pas à la simple restauration de données : il vise à reconstruire un environnement opérationnel complet, cohérent et fonctionnel. D’un point de vue technique, un PRA s’appuie généralement sur plusieurs briques fondamentales. On retrouve notamment les systèmes de sauvegarde (backup), les mécanismes de réplication (synchrone ou asynchrone), les infrastructures de secours (site secondaire, datacenter distant ou cloud), ainsi que des outils d’automatisation permettant de piloter la reprise. Ces composants doivent être interopérables et testés régulièrement pour garantir leur efficacité en situation réelle.
La différence majeure entre une sauvegarde classique et un PRA réside dans la notion de reprise globale. Une sauvegarde permet de récupérer des fichiers ou des bases de données, mais ne garantit pas la disponibilité immédiate des applications, des réseaux ou des dépendances systèmes. Le PRA, quant à lui, intègre la remise en service des machines virtuelles, des conteneurs, des services réseau (DNS, Active Directory, firewall), ainsi que des applications métiers dans un ordre de priorité défini. Deux indicateurs structurent la conception d’un PRA : Le RTO (Recovery Time Objective) et le RPO (Recovery Point Objective). Le RTO représente le délai maximal acceptable pour restaurer un service après un incident. Il influence directement les choix d’architecture, notamment le niveau d’automatisation et le type d’infrastructure de secours. Un RTO de quelques minutes nécessitera par exemple des solutions de réplication en temps réel et de bascule automatique (failover). Le RPO, quant à lui, définit la quantité maximale de données que l’entreprise est prête à perdre. Il est étroitement lié à la fréquence des sauvegardes ou à la latence de réplication. Un RPO proche de zéro implique une réplication synchrone ou quasi temps réel, avec un impact sur les coûts et la complexité technique. Ces deux métriques doivent être définies en collaboration avec les métiers afin de trouver un équilibre entre exigences opérationnelles et contraintes budgétaires.
Le rôle du PRA dépasse largement la dimension technique. Il constitue un élément clé de la stratégie de continuité d’activité (PCA/PRA). Il permet de maintenir les fonctions critiques de l’entreprise, de réduire les pertes financières liées à l’interruption de service et de garantir le respect des engagements contractuels (SLA). Dans certains contextes réglementaires, comme les environnements bancaires, assurantiels ou de santé, des normes imposent des niveaux précis de disponibilité et de reprise. Sur le plan opérationnel, le PRA définit également les rôles et responsabilités des intervenants. Il précise qui déclenche la procédure, qui supervise la reprise, et quelles équipes sont mobilisées (administrateurs systèmes, réseau, sécurité, métiers). Cette organisation est essentielle pour éviter toute confusion lors d’un incident, où chaque minute compte. En environnement virtualisé ou cloud, le PRA s’appuie souvent sur des technologies avancées comme la réplication de machines virtuelles, les snapshots cohérents applicatifs, ou encore les solutions de Disaster Recovery as a Service (DRaaS). Ces approches permettent d’industrialiser la reprise et de réduire considérablement les délais d’indisponibilité. Dans le cadre de l’infogérance, le PRA devient un engagement contractuel fort. Les prestataires doivent concevoir des architectures résilientes, souvent basées sur des datacenters géographiquement distincts, avec des mécanismes de bascule automatisée et des tests réguliers. Ils doivent également fournir des garanties de performance via des SLA intégrant les RTO et RPO définis avec le client.
Par ailleurs, un PRA efficace repose sur une documentation précise et maintenue à jour. Celle-ci inclut les procédures techniques détaillées, les schémas d’architecture, les dépendances applicatives et les scénarios de reprise. Sans cette rigueur documentaire, même les meilleures infrastructures peuvent échouer lors d’une crise.
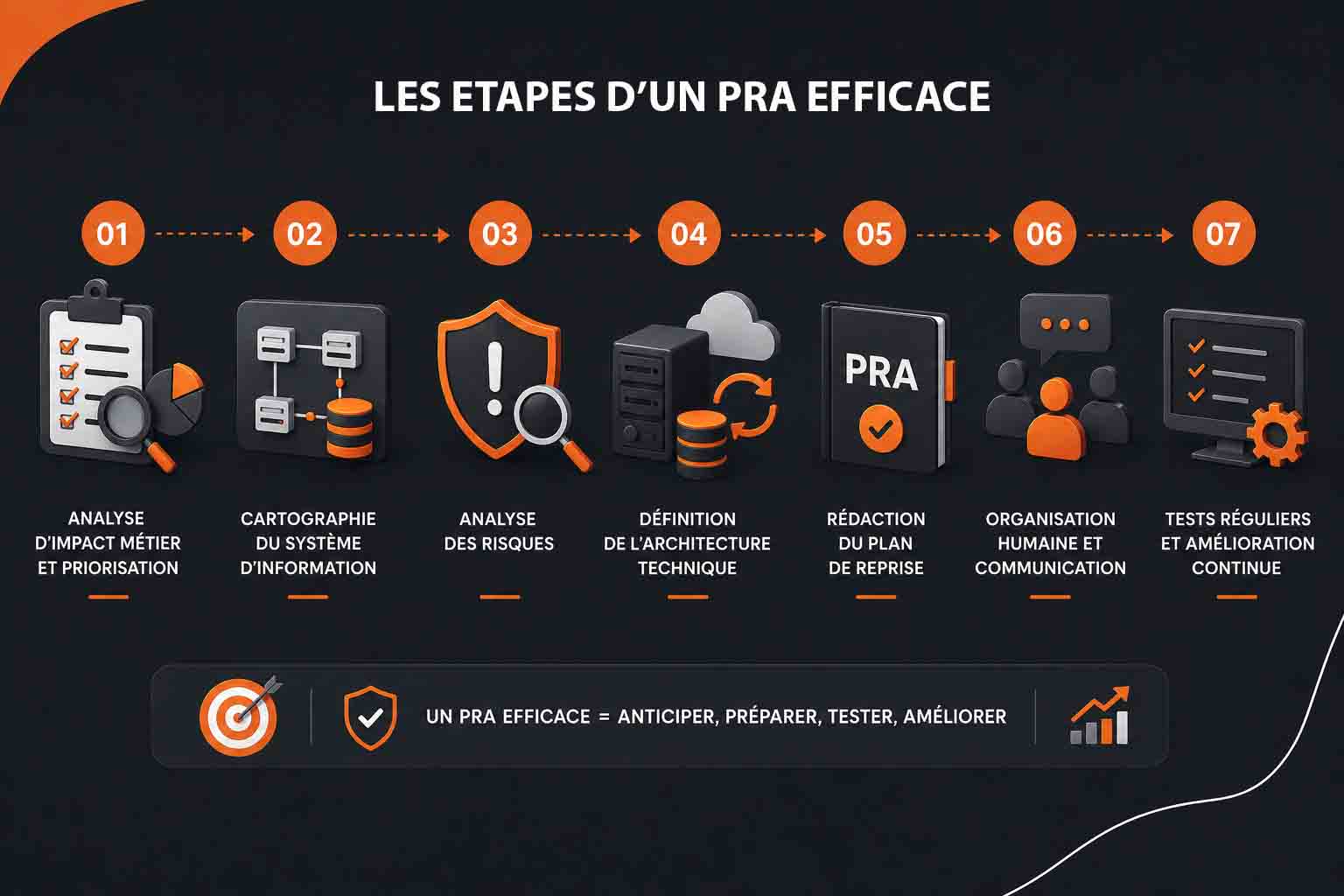
Les étapes clés pour mettre en place un PRA efficace
La mise en place d’un plan de reprise d’activité ne s’improvise pas. Un PRA efficace repose sur une méthodologie précise, une vision complète du système d’information et une compréhension fine des enjeux métiers. Il ne s’agit pas uniquement de sauvegarder des données ou de prévoir quelques serveurs de secours, mais de construire une stratégie opérationnelle capable de remettre en route les services essentiels dans un délai maîtrisé après un incident majeur :
- La première étape consiste à réaliser une analyse d’impact métier, aussi appelée BIA pour Business Impact Analysis. Cette analyse permet d’identifier les processus indispensables au fonctionnement de l’entreprise : production, facturation, relation client, messagerie, outils collaboratifs, ERP, CRM, applications métiers, accès aux fichiers partagés ou encore services d’authentification. Pour chaque processus, il faut évaluer les conséquences d’une interruption : pertes financières, blocage opérationnel, impact juridique, dégradation de l’image de marque ou rupture d’engagement contractuel. Cette analyse doit ensuite être traduite en priorités techniques. Toutes les applications n’ont pas le même niveau de criticité. Un serveur Active Directory, un serveur DNS, une base de données de production ou une plateforme e-commerce peuvent nécessiter une reprise très rapide, tandis qu’un environnement de test ou une application secondaire peut tolérer une indisponibilité plus longue. Cette classification permet de hiérarchiser les ressources et d’éviter de concevoir un PRA trop coûteux ou mal dimensionné. À ce stade, il est indispensable de définir les objectifs de reprise. Le RTO, ou Recovery Time Objective, correspond au délai maximal acceptable pour remettre un service en fonctionnement. Le RPO, ou Recovery Point Objective, désigne la quantité maximale de données que l’entreprise accepte de perdre. Par exemple, une application comptable peut accepter une perte de données de quelques heures, tandis qu’une plateforme transactionnelle nécessitera un RPO proche de zéro. Ces indicateurs orientent directement les choix techniques : fréquence des sauvegardes, réplication synchrone ou asynchrone, haute disponibilité, bascule automatique ou restauration manuelle ;
- La deuxième étape consiste à cartographier précisément le système d’information. Cette cartographie doit inclure les serveurs physiques, les machines virtuelles, les bases de données, les équipements réseau, les liens télécoms, les services cloud, les dépendances applicatives et les flux critiques. Une application métier peut dépendre d’un serveur de base de données, d’un annuaire LDAP, d’un service DNS, d’un certificat SSL, d’une passerelle VPN ou d’une API externe. Si l’une de ces dépendances est oubliée, la reprise peut échouer malgré la restauration apparente de l’application principale. La cartographie doit également préciser l’ordre de redémarrage des composants. Dans un environnement d’entreprise, il est rarement possible de relancer les services dans n’importe quel ordre. Les services d’infrastructure doivent généralement être restaurés en premier : réseau, pare-feu, routage, DNS, DHCP, annuaire Active Directory, stockage, hyperviseurs, puis serveurs applicatifs et bases de données. Cette séquence de reprise doit être documentée avec rigueur afin d’éviter les blocages lors d’une situation de crise ;
- La troisième étape repose sur l’analyse des risques. Il convient d’identifier les scénarios susceptibles d’interrompre l’activité : panne matérielle, défaillance de baie de stockage, perte d’un hyperviseur, corruption de données, erreur humaine, cyberattaque, ransomware, incendie, inondation, coupure électrique, indisponibilité d’un fournisseur cloud, rupture de lien internet ou défaillance d’un prestataire critique. Chaque scénario doit être évalué selon sa probabilité, son impact et les moyens disponibles pour y répondre. Cette analyse permet de choisir les mécanismes de protection adaptés. Pour un risque de ransomware, les sauvegardes immuables, les copies hors ligne et la segmentation réseau sont particulièrement importantes. Pour une panne de datacenter, il faut prévoir un site de secours ou une infrastructure cloud capable d’héberger les workloads prioritaires. Pour une coupure réseau, des liens opérateurs redondants ou une solution SD-WAN peuvent être envisagés. Le PRA doit donc être pensé comme une réponse concrète à des scénarios réalistes, et non comme un document générique ;
- La quatrième étape consiste à définir l’architecture technique du PRA. Plusieurs approches sont possibles selon les exigences de disponibilité, le budget et la maturité informatique de l’entreprise. Une architecture minimale peut reposer sur des sauvegardes régulières externalisées et une restauration manuelle sur une infrastructure de secours. Une architecture plus avancée peut intégrer une réplication continue des machines virtuelles vers un second site, avec possibilité de bascule rapide. Les environnements les plus exigeants utilisent parfois des architectures actives-actives ou actives-passives avec automatisation du basculement. Les solutions de sauvegarde doivent être conçues avec soin. Une bonne stratégie repose souvent sur le principe 3-2-1 : Disposer d’au moins trois copies des données, stockées sur deux supports différents, dont une copie externalisée. Dans un contexte de cybersécurité, il est recommandé d’y ajouter des sauvegardes immuables, protégées contre la modification ou la suppression pendant une durée définie. Cette approche limite fortement les risques de perte totale en cas de compromission du système d’information. La réplication constitue une autre brique importante du PRA. Elle peut être synchrone, lorsque les données sont écrites simultanément sur deux environnements, ou asynchrone, lorsqu’elles sont répliquées avec un léger décalage. La réplication synchrone permet de réduire fortement le RPO, mais elle exige une faible latence réseau et une infrastructure robuste. La réplication asynchrone est souvent plus souple et moins coûteuse, mais elle implique une perte potentielle de données correspondant au décalage de réplication. Le choix de l’environnement de secours est également déterminant. Il peut s’agir d’un second datacenter, d’une salle informatique distante, d’une infrastructure cloud publique, d’un cloud privé ou d’une solution de reprise après sinistre managée, aussi appelée DRaaS pour Disaster Recovery as a Service. En infogérance, cette dernière approche est fréquente, car elle permet de mutualiser les ressources, de bénéficier d’une supervision continue et de déléguer une partie des opérations de reprise à un prestataire spécialisé ;
- La cinquième étape consiste à formaliser le plan lui-même. Le document de PRA doit être clair, structuré et exploitable en situation de crise. Il doit contenir le périmètre couvert, les applications concernées, les objectifs de RTO et de RPO, les contacts d’urgence, les procédures de déclenchement, les étapes de restauration, les prérequis techniques, les accès nécessaires, les procédures de validation et les modalités de retour à la normale. Un PRA trop théorique ou trop dispersé devient difficile à appliquer lorsque les équipes travaillent sous pression. Chaque procédure doit être rédigée de manière opérationnelle. Il faut éviter les formulations vagues et privilégier des actions vérifiables : restaurer telle machine virtuelle, reconnecter tel volume de stockage, modifier tel enregistrement DNS, valider telle connexion applicative, contrôler l’intégrité de telle base de données, vérifier l’accès des utilisateurs pilotes. Cette précision réduit les risques d’erreur et permet à plusieurs administrateurs de suivre le même processus avec cohérence. La gestion des droits d’accès doit également être anticipée. En cas d’incident majeur, les équipes doivent pouvoir accéder aux consoles d’administration, aux coffres-forts de mots de passe, aux outils de sauvegarde, aux plateformes cloud, aux équipements réseau et aux documents techniques. Ces accès doivent être protégés, mais disponibles même si l’annuaire principal, la messagerie ou le VPN habituel sont indisponibles. Un PRA efficace prévoit donc des accès d’urgence sécurisés et régulièrement contrôlés ;
- La sixième étape concerne l’organisation humaine. Un PRA ne repose pas uniquement sur la technique. Il doit préciser les rôles de chacun : direction, responsable informatique, administrateurs systèmes, administrateurs réseau, référent cybersécurité, prestataire d’infogérance, métiers prioritaires et cellule de communication. La chaîne de décision doit être connue à l’avance afin de déterminer rapidement qui peut déclencher le PRA, qui valide la bascule et qui autorise le retour en production. La communication doit être intégrée au dispositif. Lors d’un incident, les utilisateurs, les clients, les partenaires et parfois les autorités doivent être informés avec des messages adaptés. Une mauvaise communication peut aggraver la crise, même si la reprise technique est maîtrisée. Le PRA doit donc prévoir des modèles de messages, des canaux alternatifs et une procédure d’escalade ;
- La septième étape consiste à tester le PRA régulièrement. Un plan non testé reste une hypothèse. Les tests permettent de vérifier que les sauvegardes sont exploitables, que les machines virtuelles peuvent être redémarrées, que les dépendances applicatives sont bien prises en compte et que les délais de reprise annoncés sont réalistes. Ces exercices peuvent prendre plusieurs formes : Test de restauration ponctuel, test applicatif, simulation de panne, exercice de bascule partielle ou test complet de reprise sur site secondaire. Après chaque test, un compte rendu doit être produit. Il doit mentionner les écarts constatés, les temps réellement mesurés, les erreurs rencontrées, les actions correctives et les responsabilités associées. Cette démarche d’amélioration continue est indispensable, car un système d’information évolue en permanence : Nouvelles applications, changements d’architecture, migrations cloud, mises à jour de sécurité, renouvellement matériel ou modification des flux réseau.
Le PRA doit être maintenu dans le temps. Il doit être révisé après chaque évolution significative du système d’information, après chaque incident majeur et à intervalles réguliers. Un PRA obsolète peut donner un faux sentiment de sécurité. Pour rester fiable, il doit être intégré aux processus d’exploitation, de supervision, de cybersécurité et de gouvernance informatique.
Les bonnes pratiques et les conseils d’expert pour un PRA performant
Un PRA performant repose avant tout sur un principe fondamental souvent sous-estimé : La maîtrise opérationnelle. Dans de nombreux environnements, la tentation est grande de concevoir des architectures très sophistiquées, intégrant des technologies avancées et des scénarios multiples. Pourtant, un plan trop complexe devient difficile à activer en situation de crise. Il est donc préférable de privilégier une approche pragmatique, basée sur des procédures claires, reproductibles et testées régulièrement. La fiabilité d’un PRA dépend davantage de sa capacité à être exécuté rapidement que de son niveau théorique de perfection. L’automatisation constitue un levier majeur pour améliorer l’efficacité d’un PRA. Elle permet de réduire les interventions humaines, souvent sources d’erreurs en contexte de stress, et d’accélérer les délais de reprise. Les technologies modernes permettent aujourd’hui d’automatiser la réplication des données, le démarrage des machines virtuelles, la reconfiguration réseau, la mise à jour des enregistrements DNS ou encore l’orchestration complète d’un scénario de bascule. Ces mécanismes sont particulièrement pertinents dans des environnements virtualisés ou cloud, où les infrastructures sont pilotables via API. La mise en place de scénarios de failover automatisés doit toutefois être accompagnée de contrôles rigoureux. Il est essentiel de vérifier la cohérence applicative après la bascule : intégrité des bases de données, disponibilité des services métiers, fonctionnement des authentifications, connectivité réseau et accès utilisateur. L’automatisation ne dispense pas d’une validation fonctionnelle, notamment pour les applications critiques.
La stratégie de sauvegarde représente un autre pilier fondamental. Une approche robuste repose généralement sur une combinaison de sauvegardes complètes, incrémentales et différentielles, avec des fréquences adaptées aux objectifs de RPO. Il est recommandé d’appliquer la règle du 3-2-1, en y ajoutant des mécanismes de protection avancés face aux cybermenaces. Les sauvegardes immuables, par exemple, empêchent toute modification ou suppression pendant une période définie, ce qui les rend particulièrement efficaces contre les ransomwares. Les copies hors ligne, également appelées air gap, constituent une couche de sécurité supplémentaire. Elles sont physiquement ou logiquement isolées du système d’information principal, ce qui limite fortement les risques de compromission simultanée. Dans un contexte où les attaques ciblent de plus en plus les systèmes de sauvegarde, cette approche devient indispensable pour garantir une capacité de restauration fiable. Le chiffrement des sauvegardes doit également être pris en compte. Les données sauvegardées peuvent contenir des informations sensibles : données clients, informations financières, secrets industriels. Le chiffrement, combiné à une gestion sécurisée des clés, permet de protéger ces données en cas de fuite ou d’accès non autorisé. L’externalisation du PRA via un prestataire d’infogérance est une pratique courante, notamment pour les entreprises ne disposant pas de ressources internes suffisantes. Cette approche permet de bénéficier d’infrastructures redondées, souvent réparties sur plusieurs sites géographiques, ainsi que d’une expertise spécialisée en gestion de crise informatique. Les prestataires proposent généralement des services incluant la supervision 24/7, la gestion des sauvegardes, la réplication des données et l’orchestration des plans de reprise. Les solutions cloud jouent un rôle de plus en plus important dans les stratégies de PRA. Elles offrent une grande flexibilité en termes de capacité, de coûts et de déploiement. Les environnements de secours peuvent être provisionnés à la demande, ce qui permet de limiter les investissements en infrastructure tout en garantissant une capacité de reprise rapide. Les modèles hybrides, combinant infrastructure locale et cloud, sont particulièrement adaptés pour équilibrer performance, sécurité et budget.
Il est toutefois important de ne pas dépendre d’un seul fournisseur. Une stratégie multi-cloud ou hybride peut renforcer la résilience en cas de défaillance d’un prestataire. De même, les dépendances critiques doivent être identifiées : accès réseau, authentification, stockage, services tiers. Un PRA efficace anticipe ces points de fragilité et prévoit des solutions alternatives. L’implication des équipes métiers est un facteur déterminant souvent négligé. Un PRA ne concerne pas uniquement les équipes techniques. Les utilisateurs doivent être capables de reprendre leurs activités dans un environnement dégradé ou de secours. Cela implique de définir des procédures métiers adaptées, de former les équipes et de réaliser des exercices de simulation incluant les utilisateurs finaux. La communication joue également un rôle central. En situation de crise, il est indispensable de disposer de canaux alternatifs pour informer les collaborateurs, les clients et les partenaires. Le PRA doit inclure un plan de communication précisant les messages, les interlocuteurs et les supports à utiliser. Une communication claire permet de réduire l’incertitude et de maintenir la confiance. La gestion des accès en situation dégradée est un autre point critique. Les administrateurs doivent pouvoir accéder aux outils de reprise même si les systèmes d’authentification principaux sont indisponibles. Cela peut impliquer la mise en place de comptes d’urgence, de coffres-forts de mots de passe sécurisés ou de solutions d’authentification alternatives. Ces accès doivent être strictement contrôlés et régulièrement testés.
La supervision et la journalisation doivent également être intégrées au PRA. Lors d’une reprise, il est important de disposer de logs détaillés pour analyser les événements, identifier les anomalies et valider le bon fonctionnement des systèmes restaurés. Ces informations sont précieuses pour améliorer les procédures et renforcer la sécurité. Enfin, un PRA performant est nécessairement évolutif. Les infrastructures changent, les applications évoluent, les menaces se transforment et les exigences métiers se renforcent. Il est donc indispensable de mettre à jour régulièrement le plan, d’intégrer les retours d’expérience issus des tests ou des incidents réels, et d’adapter les architectures en conséquence. Cette démarche d’amélioration continue permet de maintenir un niveau de résilience cohérent avec les enjeux de l’entreprise. En pratique, les organisations les plus matures intègrent le PRA dans une démarche globale de gouvernance informatique, en lien avec la cybersécurité, la gestion des risques et la continuité d’activité. Cette vision transverse permet de ne pas traiter le PRA comme un projet isolé, mais comme un élément central de la stratégie IT.

0 commentaires