Un jour, vous visitez votre site préféré… et il n’existe plus. Ou peut-être avez-vous besoin d’accéder à une version précédente d’un article, d’un site web disparu, d’un blog dont vous voulez retrouver le contenu supprimé, ou encore de vérifier l’historique d’une page pour un projet, une enquête ou un audit de contenu. Dans ces situations, archive.org devient une ressource précieuse, souvent sous-estimée. Plus particulièrement, sa fonctionnalité phare, la Wayback Machine, permet de remonter le temps numérique et d’accéder à des milliards de pages web archivées depuis 1996. Dans cet article, découvrez comment exploiter pleinement cette bibliothèque numérique géante, quels sont ses atouts, ses usages avancés et ses limites à connaître.
Comprendre la Wayback Machine et son histoire
La Wayback Machine est l’un des projets emblématiques de Internet Archive, une organisation à but non lucratif fondée en 1996 par Brewster Kahle, ingénieur et entrepreneur américain engagé dans la préservation du savoir numérique. Basée à San Francisco, en Californie, l’organisation a vu le jour avec une ambition simple mais puissante : « préserver l’histoire d’Internet pour les générations futures ». À la fin des années 1990, le web était en pleine explosion : des milliers de sites naissaient chaque jour, mais peu d’initiatives existaient pour en conserver une trace. Face à cette réalité, Brewster Kahle crée l’Internet Archive et commence à collecter des copies de pages web à une époque où le stockage était encore très limité et coûteux. Le nom Wayback Machine fait référence à une machine à voyager dans le temps fictive issue du dessin animé « The Rocky and Bullwinkle Show », appelée la « WABAC Machine ».
Officiellement lancée en octobre 2001, la Wayback Machine a commencé par proposer des archives datant de 1996. Depuis, elle a évolué pour devenir la plus grande base de données d’archives web au monde, avec plus de 800 milliards de pages web archivées à ce jour, consultables gratuitement.
Définition et fonctionnement de archive.org
Une archive web est une capture ou une copie enregistrée d’une page Internet à un moment donné. Ces copies sont appelées des « snapshots » (instantanés). Elles incluent généralement le code HTML de la page, ses images, ses fichiers CSS et parfois même ses fichiers JavaScript ou ses vidéos intégrées. L’objectif est de recréer le plus fidèlement possible l’état d’une page à une date précise. La Wayback Machine effectue ces captures de deux manières :
- Automatiquement, via des robots d’indexation (ou crawlers) qui parcourent régulièrement les sites publics ;
- Manuellement, lorsqu’un utilisateur utilise l’outil « Save Page Now » pour forcer l’archivage immédiat d’une page
Ces snapshots sont ensuite accessibles via une interface de navigation temporelle très intuitive : une frise chronologique accompagnée d’un calendrier. Elle permet à n’importe qui de choisir une année, un mois et un jour pour visualiser l’état d’un site web à une date passée.
Les utilisations pratiques de la Wayback Machine
Les applications de la Wayback Machine sont nombreuses, allant de la simple curiosité personnelle à des usages professionnels très spécialisés. Voici quelques exemples concrets :
- Retrouver un contenu disparu : Un blog effacé, une page d’entreprise supprimée, un lien mort… tout cela peut être restauré ou consulté via l’archive ;
- Analyser l’évolution d’un site web : Utile pour le design, le référencement (SEO), le branding ou les stratégies éditoriales ;
- Vérifier l’authenticité d’une citation ou d’une source : Dans le journalisme ou la recherche, c’est un outil précieux pour contrer les modifications ou suppressions postérieures à une publication ;
- Étudier des campagnes marketing antérieures : Particulièrement utile pour les professionnels du marketing ou les analystes concurrentiels ;
- Documenter un contenu pour un contexte légal, académique ou patrimonial : Les archives web peuvent servir de trace ou de preuve dans certains dossiers
Le fonctionnement automatique et l’archivage manuel sur archive.org
La majorité des contenus sont archivés de façon automatique par les robots d’Internet Archive, similaires aux robots de Google. Cependant, il est également possible de contribuer activement à la sauvegarde du web. En utilisant le bouton « Save Page Now », chaque internaute peut capturer manuellement une page web, à condition qu’elle soit publique et accessible. Cette fonctionnalité est très appréciée pour :
- Garder une trace d’un contenu susceptible d’être supprimé ou modifié ;
- Enregistrer une ressource utile pour un travail de veille ou de documentation ;
- Créer une version stable d’un site pour la partager de façon pérenne
À noter : les sites web peuvent, s’ils le souhaitent, empêcher leur archivage en configurant leur fichier robots.txt. De plus, les propriétaires de sites peuvent demander le retrait de certaines archives, bien que cette démarche soit encadrée par des critères stricts de l’organisation.
Quelques chiffres clés pour mieux situer l’impact
| Élément | Détail |
|---|---|
| Année de création | 1996 (Internet Archive), 2001 (Wayback Machine) |
| Fondateur | Brewster Kahle |
| Siège de l’organisation | San Francisco, Californie, États-Unis |
| Nombre de pages archivées | Plus de 800 milliards (en 2025) |
| Type d’organisation | Organisation à but non lucratif |
Grâce à sa mission de préservation et d’accessibilité universelle, la Wayback Machine est aujourd’hui un outil de mémoire collective numérique incontournable. Son accès libre et gratuit participe à la démocratisation de l’information et à la protection du patrimoine numérique mondial.
Un tutoriel complet : Comment utiliser archive.org étape par étape
Que vous soyez curieux ou que vous ayez un objectif professionnel, voici un guide pratique pour bien exploiter la Wayback Machine.
1. Rechercher une URL sur archive.org
La première étape pour consulter une archive est de vous rendre sur la page d’accueil de la Wayback Machine, disponible à l’adresse suivante : https://archive.org/web/.
Une fois sur le site, vous verrez en haut une barre de recherche simple, mais très puissante. Dans ce champ, vous devez saisir l’URL complète (l’adresse web) de la page que vous souhaitez explorer. Il est important d’entrer l’adresse exacte, y compris le protocole https:// ou http://, et d’éviter les erreurs de frappe, car même une légère variation (comme un slash oublié à la fin) peut renvoyer un résultat vide si l’URL exacte n’a pas été archivée.
Exemple : si vous cherchez une ancienne version d’une page produit, d’un article de blog ou d’un site qui a disparu, tapez l’URL complète, comme par exemple :
https://www.monsite.com/ancienne-pageLa recherche fonctionne aussi bien pour des pages individuelles que pour des pages d’accueil entières (par exemple https://www.monsite.com), ce qui peut être utile si vous ne connaissez pas l’URL précise mais souhaitez explorer les différentes sections archivées d’un site au fil des années. Une fois l’URL saisie, validez avec la touche Entrée ou en cliquant sur le bouton de recherche. Si des archives existent, vous accéderez immédiatement à une interface visuelle montrant les dates disponibles. Dans le cas contraire, un message vous indiquera qu’aucune archive n’a été trouvée pour cette adresse.
Ce simple point d’entrée vous ouvre potentiellement des années, voire des décennies d’historique numérique. Que ce soit pour retrouver un site disparu, retracer l’évolution d’une page ou valider une information ancienne, cette recherche est la clé de votre voyage dans le web du passé.
2. Utiliser la frise chronologique proposée par archive.org
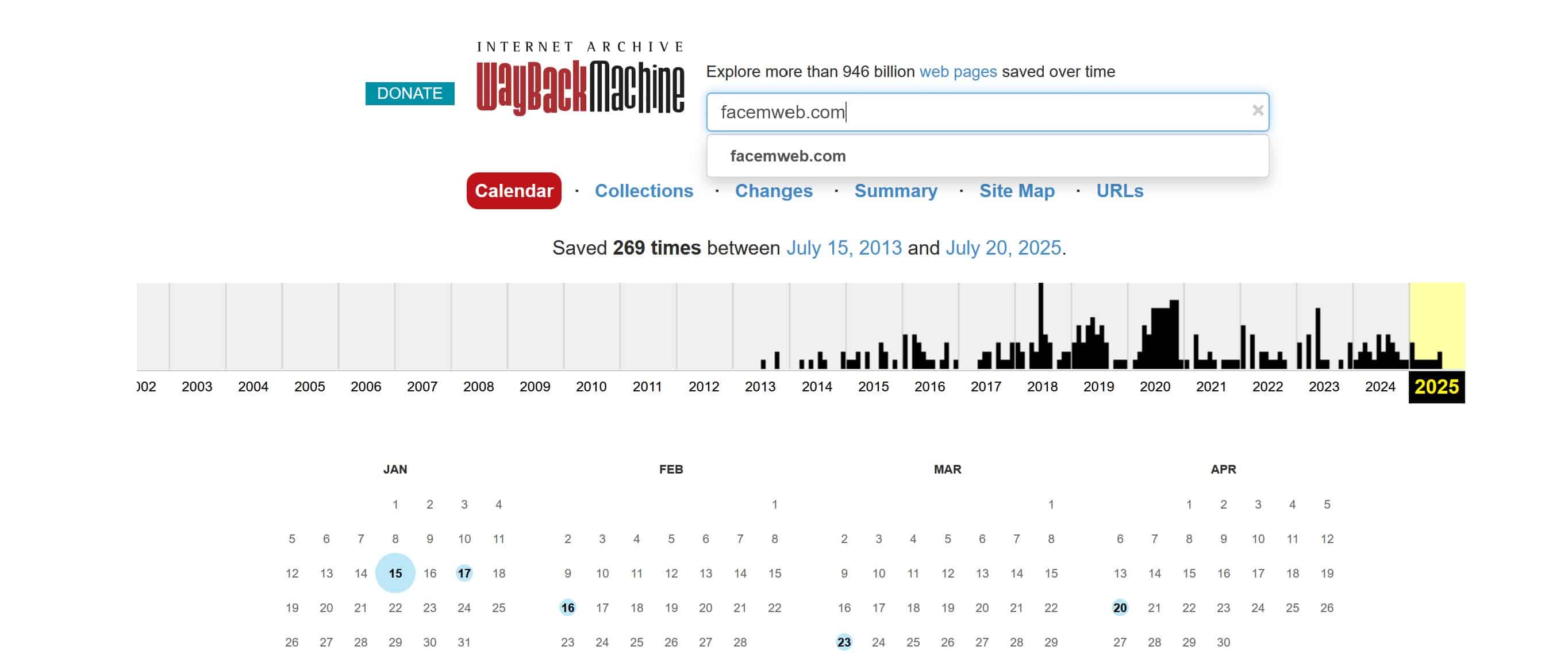
Une fois que vous avez saisi l’URL d’un site et que des archives sont disponibles, la Wayback Machine vous affiche automatiquement une frise chronologique interactive. Cette visualisation est l’un des éléments les plus emblématiques de l’outil. Elle représente l’historique des captures de la page sur plusieurs années, parfois depuis les tout débuts du site si celui-ci existe depuis longtemps.
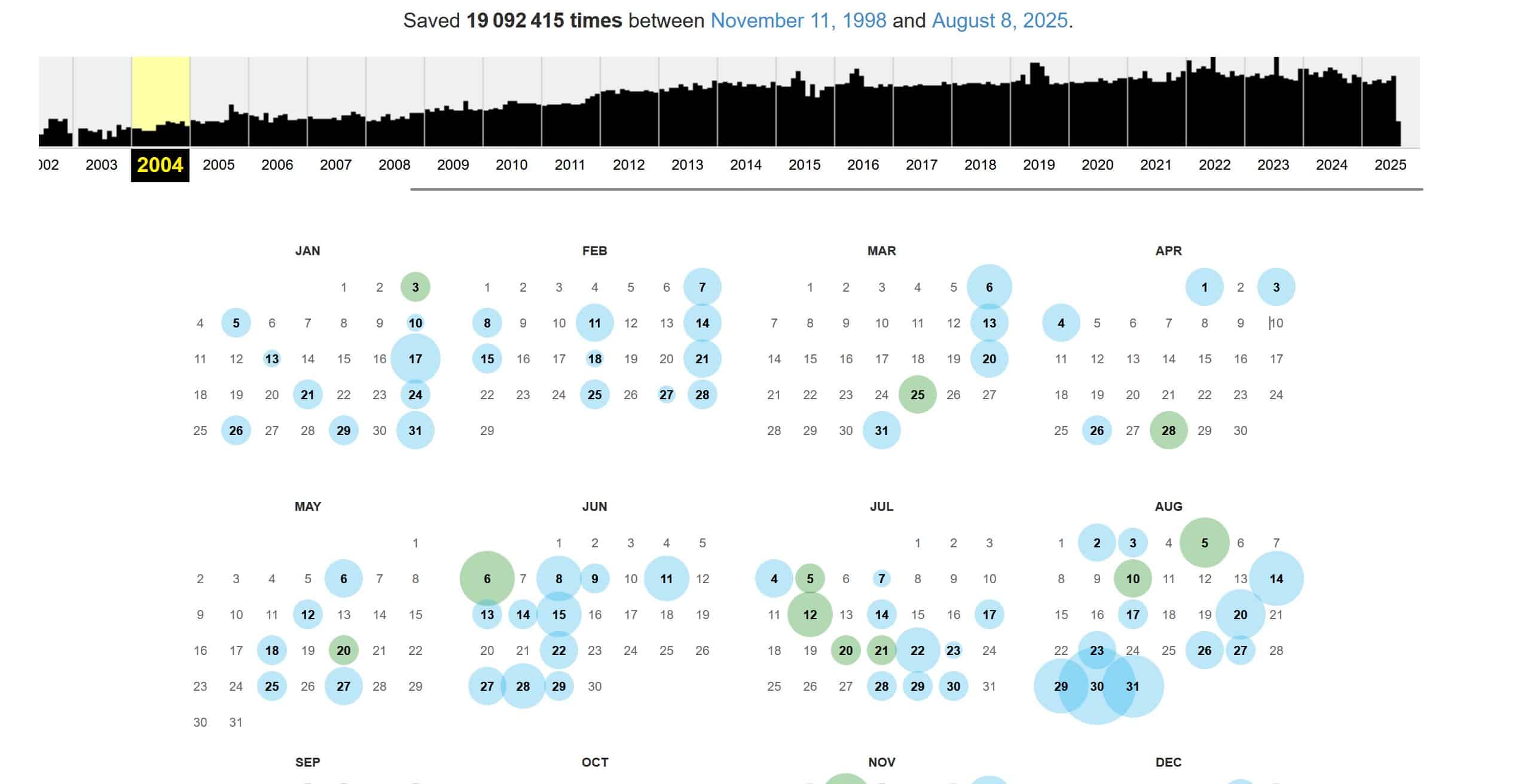
La frise est structurée par années civiles, généralement de gauche à droite. Chaque segment représente une année, et en dessous, vous trouverez un calendrier détaillé correspondant à celle que vous avez sélectionnée. Vous pouvez cliquer sur une année pour zoomer sur son contenu, puis explorer le mois et le jour souhaités.
Les jours contenant des captures d’écran ou des sauvegardes sont signalés par un petit cercle coloré :
- Bleu : généralement une capture automatique par les robots d’archive.org ;
- Vert : souvent une capture manuelle faite via la fonction « Save Page Now ».
En passant votre curseur sur une date, vous verrez apparaître une infobulle indiquant l’heure exacte de la capture disponible ce jour-là. Si plusieurs captures existent pour une même journée, plusieurs horaires seront affichés, vous permettant de sélectionner précisément la version souhaitée.
Il suffit alors de cliquer sur l’une de ces horodatations pour charger la version archivée du site ou de la page à ce moment précis. En quelques secondes, vous êtes transporté dans le passé, avec la possibilité de naviguer dans le site comme s’il s’agissait d’un instant figé dans le temps.
Cette fonctionnalité est particulièrement utile pour observer l’évolution progressive d’un site web : design, structure de menu, contenu éditorial, offres commerciales ou encore mentions légales. Vous pouvez ainsi comparer des versions distantes dans le temps et constater, par exemple, comment un discours d’entreprise ou une politique tarifaire a évolué.
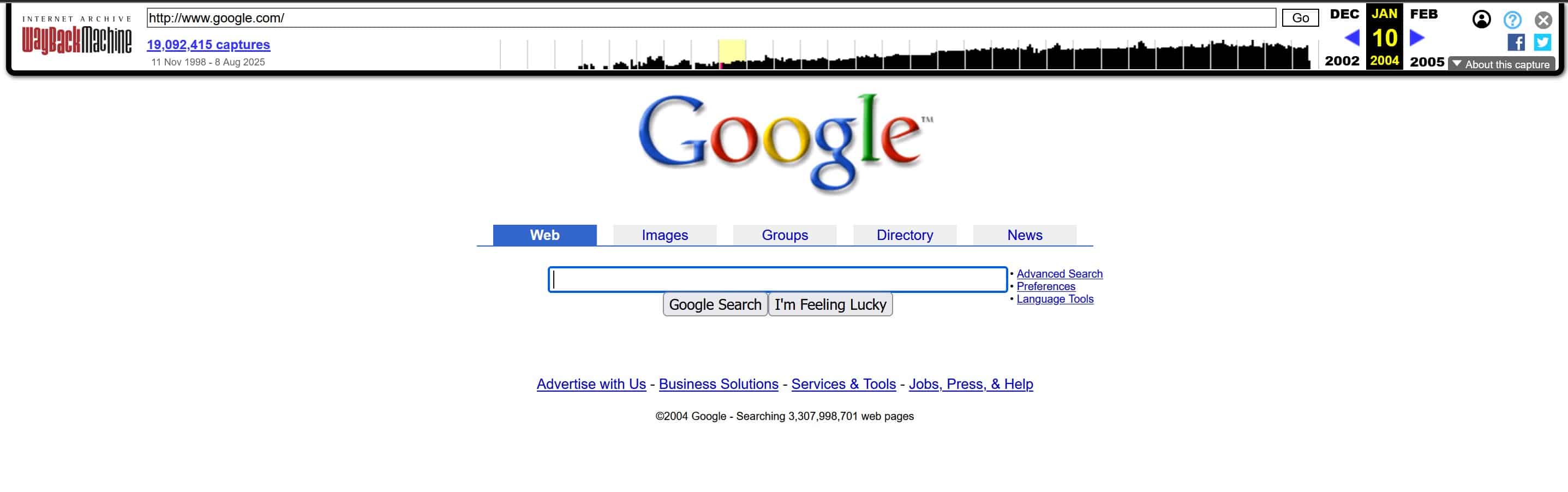
Après avoir sélectionné une date et un horaire depuis le calendrier de la Wayback Machine, vous êtes redirigé vers une version archivée de la page web telle qu’elle existait à ce moment précis. Ce processus se fait généralement en quelques secondes, et vous voilà face à un instantané fidèle du site Internet tel qu’il apparaissait dans le passé. À ce stade, l’expérience est assez immersive. Vous pouvez cliquer sur les liens internes de la page archivée, explorer les sections, les articles, les menus ou même les pages de contact. Si ces pages ont elles aussi été sauvegardées à la même période, la navigation se poursuit sans interruption, vous offrant une plongée quasi complète dans l’univers du site à une date donnée.
La Wayback Machine reproduit non seulement le texte et la structure HTML, mais aussi une grande partie des éléments visuels : images, couleurs, logos, typographies… Cela vous permet d’étudier l’esthétique, l’ergonomie ou encore l’identité graphique d’un site à une époque révolue. Toutefois, certaines limites sont à prendre en compte. Comme l’outil n’archive pas toujours l’intégralité des ressources associées à une page, il arrive que des images soient manquantes, que des scripts JavaScript ne se chargent pas correctement ou que des vidéos intégrées ne soient plus disponibles. Cela est particulièrement fréquent pour les contenus dynamiques, les formulaires interactifs ou les éléments externes hébergés sur des plateformes tierces (comme YouTube, Vimeo ou des serveurs CDN).
Malgré ces imperfections, la plupart des pages restent lisibles, exploitables et suffisamment complètes pour reconstituer le contenu d’origine, y compris les titres, les textes, les liens hypertextes, les balises SEO, et parfois même les commentaires ou les métadonnées de publication. En bas de l’écran, un bandeau gris ou noir affiché par la Wayback Machine indique la date exacte de la capture ainsi que d’autres options utiles, comme :
- le lien vers les autres versions archivées du même site ;
- la possibilité de partager l’URL de la version archivée ;
- un raccourci vers l’option « About this capture » pour plus d’informations techniques.
Cette fonctionnalité de navigation dans les captures vous permet donc de remonter le fil du temps numérique avec une précision étonnante, que ce soit pour retrouver un article disparu, analyser des versions précédentes d’une page web, ou documenter une évolution de contenu dans un cadre professionnel ou académique.
Un exemple avec Google de janvier 2004 :
4. Sauvegarder une page du site Internet
Outre la consultation d’archives anciennes, la Wayback Machine offre également une fonctionnalité très pratique : la possibilité de créer vous-même une capture d’une page web en temps réel. Cette option s’appelle « Save Page Now », et elle est accessible directement depuis la page d’accueil de la Wayback Machine. Concrètement, il vous suffit de coller l’URL de la page que vous souhaitez archiver dans le champ prévu à cet effet, situé sous le texte « Save Page Now », puis de cliquer sur le bouton « Save Page ». En quelques instants, une capture de la page est générée et enregistrée dans la base de données d’Internet Archive. Cette sauvegarde manuelle présente de nombreux avantages, notamment :
- Préserver une preuve : Si vous avez besoin de documenter un contenu en ligne avant qu’il ne soit modifié ou supprimé (exemple : un article polémique, une fiche produit, une publication d’un tiers), cette capture servira d’élément de référence ;
- Archiver du contenu temporaire : Newsletters, promotions, publications événementielles ou posts de blogs qui risquent de disparaître rapidement peuvent être conservés de manière durable ;
- Créer une version figée d’un site : Utile pour les portefeuilles de freelance, les portfolios, les rapports clients ou les audits de sites web avant refonte.
Une fois la page archivée, l’outil vous redirige automatiquement vers sa version enregistrée, avec une URL unique contenant la date et l’heure de capture. Cette URL peut ensuite être partagée, citée dans un document, ou utilisée comme élément de veille.
À noter : certaines pages peuvent ne pas être archivables, notamment si le site restreint l’accès aux robots via le fichier robots.txt, ou si le contenu est protégé par un login ou généré dynamiquement (ex. : applications web, sites en JavaScript pur).
La fonction « Save Page Now » est particulièrement utile dans des contextes sensibles : veille concurrentielle, archivage juridique, journalisme d’investigation, ou encore conservation de traces dans un cadre académique. C’est un moyen simple, rapide et accessible à tous de contribuer à la mémoire du web, en enrichissant les archives avec des contenus souvent éphémères.

5. Explorer les options avancées
Pour les utilisateurs souhaitant aller au-delà de la simple consultation ou de l’archivage manuel, la Wayback Machine propose plusieurs fonctionnalités avancées. Ces options permettent d’exploiter plus finement la richesse des archives disponibles, que ce soit pour de la recherche, de l’analyse comparative ou de l’automatisation.
- Comparer deux versions : En sélectionnant deux captures archivées d’une même page à des dates différentes, il est possible de visualiser les changements intervenus entre ces versions. Cela peut être fait manuellement en accédant à chaque snapshot et en les comparant visuellement, ou via des outils tiers de « diff » (comparaison de texte ou de code HTML). C’est particulièrement utile pour :
- analyser les évolutions de contenu éditorial (modifications de texte, ajouts, suppressions)
- suivre des ajustements de design, de navigation ou de structure
- repérer des suppressions de mentions légales ou de conditions commerciales
- API pour développeurs : Internet Archive met à disposition une API Wayback Machine qui permet d’interagir automatiquement avec les archives. Grâce à cette interface de programmation, les développeurs peuvent :
- vérifier la date de la capture la plus récente d’un site
- récupérer les différentes versions archivées d’une page
- intégrer ces données dans des systèmes de veille, des outils d’audit SEO, ou des tableaux de bord personnalisés
Cette API est gratuite et bien documentée, ce qui en fait un atout pour les professionnels du numérique, chercheurs, journalistes ou experts en cybersécurité.
- Navigation directe dans les versions antérieures : Il est également possible d’accéder directement à une version spécifique d’une page web archivée en modifiant l’URL manuellement. La structure d’une URL de la Wayback Machine suit le format suivant :
https://web.archive.org/web/AAAAMMJJhhmmss/https://www.exemple.comPar exemple, pour accéder à une version archivée de
https://www.monsite.comle 1er janvier 2020 à minuit, l’URL sera :https://web.archive.org/web/20200101000000/https://www.monsite.comCe type de navigation est très utile pour créer des liens directs vers des versions précises, notamment dans le cadre de publications universitaires, de rapports d’audit, ou d’analyses de contenu archivées.
Ces options avancées offrent une maîtrise plus poussée de l’outil, et permettent de transformer la Wayback Machine en un véritable laboratoire d’étude du web, avec des possibilités allant bien au-delà de la simple exploration nostalgique.
6. Limites et précautions avec la Wayback Machine
La Wayback Machine est un outil impressionnant par son envergure et son accessibilité, mais comme toute technologie, elle présente certaines limites techniques et juridiques qu’il est important de connaître avant de s’y fier pleinement. Comprendre ces contraintes permet d’éviter les mauvaises interprétations et d’utiliser l’archive de façon pertinente et responsable.
- Les captures ne sont pas systématiques : Bien que des milliards de pages aient été archivées, la fréquence des captures varie selon la popularité du site, sa structure, son accessibilité et la fréquence de ses mises à jour. Certains sites très consultés peuvent être capturés plusieurs fois par jour, tandis que d’autres n’apparaîtront que quelques fois par an, voire pas du tout. Il peut donc y avoir des trous dans la chronologie ou des périodes sans aucune archive.
- Les sites avec restrictions techniques ne sont pas archivés : De nombreux sites web utilisent un fichier
robots.txtpour restreindre l’accès aux robots d’indexation, y compris ceux d’Internet Archive. Si ce fichier interdit le crawling, la Wayback Machine ne peut pas accéder ni archiver le site concerné. De même, les sites protégés par mot de passe, les plateformes payantes ou les systèmes de sécurité renforcée sont généralement inaccessibles à l’archivage. - Les contenus dynamiques sont partiellement ou mal enregistrés : Avec l’évolution des technologies web, une grande partie des sites modernes s’appuie sur des frameworks JavaScript, des applications SPA (Single Page Application), des contenus chargés dynamiquement via AJAX, ou encore des médias embarqués depuis des plateformes externes. Ces éléments ne sont pas toujours bien pris en charge par l’outil, ce qui entraîne :
- l’absence de vidéos
- des formulaires inopérants
- des images manquantes
- ou une navigation altérée dans les menus ou les carrousels
- L’archivage ne constitue pas une preuve légale formelle dans tous les contextes : Bien que les captures de la Wayback Machine soient parfois utilisées comme éléments de preuve dans des contextes juridiques ou administratifs (notamment aux États-Unis), leur validité n’est pas universellement reconnue. En France, par exemple, une capture d’écran archivée ne remplace pas une constatation d’huissier ou une preuve électronique certifiée. Il convient donc de faire preuve de prudence si l’on souhaite invoquer une archive dans un cadre légal.
Il faut également noter que les propriétaires de sites web peuvent demander la suppression d’archives spécifiques en justifiant leur demande auprès d’Internet Archive. Dans ce cas, certaines captures peuvent être volontairement retirées de la base publique, et ne plus être consultables, même si elles ont existé à un moment donné. Enfin, certains pays restreignent ou censurent l’accès à la Wayback Machine. Des utilisateurs peuvent rencontrer des restrictions géographiques ou des blocages de la part de leur fournisseur d’accès à Internet. L’utilisation d’un VPN ou d’un proxy peut parfois contourner ces limites, mais cela reste à la discrétion de chaque utilisateur.

0 commentaires