Dans les réseaux informatiques, certains termes reviennent souvent sans que l’on sache toujours exactement ce qu’ils recouvrent. C’est le cas d’IPv4, une norme omniprésente qui constitue la base du fonctionnement d’Internet depuis ses origines. Derrière cet acronyme se cache un protocole indispensable à la communication entre machines, serveurs et utilisateurs. Mais que signifie précisément IPv4 ? Comment fonctionne-t-il, et pourquoi joue-t-il encore un rôle clé alors même qu’IPv6 est déjà en place pour prendre le relais ? Plongeons ensemble dans la définition et le fonctionnement d’IPv4, afin de comprendre pourquoi cette norme technique est au cœur de l’infrastructure du web depuis plus de quarante ans. Nous terminons l’article en étudiant également les impacts sur Google et en SEO.
- La définition de l’adresse IPv4 et son rôle dans les réseaux informatiques
- Le fonctionnement technique d’une adresse IPv4
- Les limites d’IPv4 et le passage progressif à IPv6
- L’impact des adresses IPv4 sur le SEO (référencement naturel)
- L’importance de la géolocalisation des adresses IPv4 pour les sites Internet
La définition de l’adresse IPv4 et son rôle dans les réseaux informatiques
IPv4 est l’acronyme d’Internet Protocol version 4. Il s’agit de la quatrième version du protocole Internet, publiée officiellement en septembre 1981 dans la RFC 791, rédigée par Jon Postel, ingénieur du Information Sciences Institute de l’Université de Californie du Sud. Ce protocole succède aux premières versions expérimentales de l’Internet Protocol (IPv0, IPv1, IPv2 et IPv3) développées dans les années 1970 dans le cadre du projet ARPANET, financé par la DARPA (Defense Advanced Research Projects Agency). À l’époque, l’objectif d’IPv4 était clair : Définir une méthode standardisée pour adresser et acheminer les données à travers des réseaux hétérogènes en pleine expansion. Il s’agissait de permettre à des centaines, puis à des milliers de machines connectées à travers le monde de communiquer entre elles selon un langage commun.
Concrètement, IPv4 attribue à chaque machine une adresse unique, appelée adresse IP. Cette adresse permet d’identifier sans ambiguïté un ordinateur, un serveur ou tout autre périphérique connecté à un réseau. C’est grâce à elle que les données peuvent circuler d’un point A à un point B, en empruntant un chemin optimisé à travers les routeurs et les commutateurs. Une adresse IPv4 se compose de 32 bits. Pour en simplifier la lecture, elle est représentée sous la forme de quatre nombres séparés par des points, chaque nombre (appelé octet) pouvant aller de 0 à 255. Par exemple :
192.168.0.1
En réalité, cette adresse est une suite binaire comme : 11000000.10101000.00000000.00000001. Le passage en notation décimale pointée (192.168.0.1) permet aux administrateurs et aux utilisateurs de manipuler plus facilement ces informations. Dès ses premières spécifications, IPv4 introduisait plusieurs notions fondamentales :
- L’identification : Chaque appareil d’un réseau se voit attribuer une adresse IPv4 unique, qui fonctionne comme une véritable carte d’identité numérique. Cette adresse permet de distinguer un ordinateur, un smartphone, une imprimante réseau ou un serveur parmi des millions d’autres machines connectées. Sans ce mécanisme d’identification, il serait impossible de garantir que les paquets de données envoyés atteignent la bonne destination. L’adresse joue donc un rôle central dans la communication réseau, à la fois au sein des réseaux privés (LAN) et sur l’ensemble d’Internet ;
- Le routage : Au-delà de son rôle d’identifiant, l’adresse IPv4 fournit également les informations nécessaires pour déterminer le chemin qu’un paquet de données doit emprunter pour atteindre sa destination. Chaque paquet contient une adresse source (l’émetteur) et une adresse de destination (le récepteur). Lorsqu’un paquet traverse plusieurs routeurs, chacun d’eux lit l’adresse de destination et consulte sa table de routage pour choisir le prochain saut (next hop). Ce processus d’acheminement dynamique, combiné à des protocoles comme OSPF, BGP ou RIP, permet à Internet de fonctionner comme un réseau mondial interconnecté ;
- Les classes d’adresses : A ses débuts, IPv4 utilisait un découpage rigide de l’espace d’adressage en classes (A, B, C, D et E). Chaque classe correspondait à une taille de réseau spécifique : la classe A pour les très grands réseaux (jusqu’à 16 millions d’hôtes), la classe B pour les réseaux moyens, et la classe C pour les petits réseaux (jusqu’à 254 hôtes). La classe D était réservée au multicast et la classe E à la recherche expérimentale. Cependant, ce système a rapidement montré ses limites, car il entraînait un gaspillage d’adresses. Dans les années 1990, l’introduction du CIDR (Classless Inter-Domain Routing) a remplacé ce découpage rigide par une notation plus flexible, permettant d’attribuer des blocs d’adresses en fonction des besoins réels, et d’optimiser la durée de vie de l’espace IPv4 ;
- Le masque de sous-réseau : Le masque est un élément essentiel pour comprendre la logique d’IPv4. Il sert à distinguer la partie de l’adresse qui identifie le réseau de celle qui identifie l’hôte. Par exemple, dans l’adresse
192.168.1.10avec un masque255.255.255.0, les trois premiers octets définissent le réseau (192.168.1), et le dernier octet (.10) identifie la machine. Le masque de sous-réseau permet donc de diviser un réseau en plusieurs sous-réseaux (subnetting), afin de mieux organiser l’infrastructure, d’optimiser l’utilisation des adresses IP disponibles et de renforcer la sécurité en cloisonnant les segments réseau.
En pratique, le rôle d’IPv4 est donc double :
- L’identification : Chaque machine connectée à un réseau, qu’il s’agisse d’un ordinateur, d’un smartphone, d’un serveur ou d’un objet connecté, reçoit une adresse IPv4 unique. Cette adresse permet de l’identifier de manière fiable au sein du réseau local (LAN) ou d’Internet. Elle joue ainsi le rôle d’une véritable carte d’identité numérique : sans elle, les données envoyées parviendraient à la mauvaise machine ou se perdraient dans le réseau. L’identification via IPv4 assure également la traçabilité des échanges et permet la gestion des droits d’accès, car un serveur peut savoir avec quel appareil il communique en se basant sur son adresse IP ;
- Le routage : Au-delà de l’identification, l’adresse IPv4 est indispensable pour organiser le transport des données. Chaque paquet IP contient deux informations essentielles : l’adresse source (l’expéditeur) et l’adresse de destination (le destinataire). Les routeurs situés entre ces deux points analysent l’adresse de destination et consultent leur table de routage pour déterminer le chemin le plus adapté à l’instant T. Ce processus tient compte des protocoles de routage (BGP, OSPF, RIP) et des conditions du réseau (charge, disponibilité, latence). Grâce à ce mécanisme, un paquet peut traverser des dizaines de nœuds intermédiaires à l’échelle mondiale et tout de même parvenir à la bonne machine, en quelques millisecondes seulement. Le routage est donc la fonction qui transforme Internet en un réseau global interconnecté et résilient.
Depuis sa mise en place au début des années 1980, IPv4 a accompagné toutes les grandes étapes de l’évolution d’Internet : De la connexion des premières universités américaines à la généralisation du web dans les années 1990, jusqu’à l’explosion des usages mobiles et des objets connectés. Son rôle fondateur et sa simplicité d’implémentation expliquent pourquoi, plus de quarante ans après, il reste encore massivement utilisé, malgré les limites d’adressage qui ont conduit à l’introduction d’IPv6.
Le fonctionnement technique d’une adresse IPv4
Pour comprendre le fonctionnement d’IPv4, il faut s’intéresser à la manière dont les adresses sont construites et interprétées dans les réseaux informatiques. Chaque adresse n’est pas une simple suite de chiffres : elle encode à la fois des informations sur le réseau et sur la machine (ou hôte) qui y est connectée. Une adresse IPv4 se divise en deux parties principales :
- Le préfixe réseau : Il désigne le réseau auquel appartient la machine. C’est l’information que les routeurs utilisent pour savoir par où diriger les paquets de données ;
- Le suffixe hôte : Il identifie de manière unique la machine à l’intérieur du réseau. C’est grâce à cette partie que le paquet arrive sur le bon périphérique.
Cette séparation est rendue possible grâce au masque de sous-réseau, une suite de 32 bits (comme l’adresse IP) qui indique quelle portion correspond au réseau et laquelle correspond à l’hôte. Par exemple :
Adresse IPv4 : 192.168.1.10 Masque : 255.255.255.0
Dans cet exemple, les trois premiers octets (192.168.1) identifient le réseau, tandis que le dernier octet (10) désigne la machine dans ce réseau. On dit ici qu’il s’agit d’un réseau en /24 (car 24 bits sont réservés au préfixe réseau).
Les classes d’adresses IPv4
Lors de sa conception, IPv4 introduisait un système de classes permettant de catégoriser les réseaux selon leur taille. Bien que ce système ait été remplacé dans les années 1990 par le CIDR (Classless Inter-Domain Routing), il reste fondamental pour comprendre la logique historique d’IPv4.
| Classe et plage d’adresses | Utilisation |
|---|---|
| Classe A 0.0.0.0 à 127.255.255.255 |
Réservée aux très grands réseaux. Chaque réseau peut contenir jusqu’à 16 millions d’hôtes. Utilisée historiquement par les premières grandes organisations connectées à ARPANET puis à Internet. |
| Classe B 128.0.0.0 à 191.255.255.255 |
Destinée aux réseaux de taille moyenne. Chaque réseau peut accueillir environ 65 000 hôtes. Ce type de plage a longtemps été attribué aux universités et grandes entreprises. |
| Classe C 192.0.0.0 à 223.255.255.255 |
Réservée aux petits réseaux, jusqu’à 254 hôtes par réseau. C’est la classe la plus répandue dans les usages quotidiens et dans les réseaux locaux (LAN). |
| Classe D 224.0.0.0 à 239.255.255.255 |
Non utilisée pour l’adressage classique des hôtes. Réservée aux communications en multicast, c’est-à-dire l’envoi d’un paquet à plusieurs destinataires en même temps (visioconférences, diffusion de flux vidéo en direct, etc.). |
| Classe E 240.0.0.0 à 255.255.255.255 |
Réservée à des fins expérimentales et à la recherche. Elle n’est pas utilisée dans les réseaux de production. |
Les adresses réservées et privées
En complément des classes générales, certaines plages IPv4 ont été réservées à des usages spécifiques :
- Les adresses privées : Non routées sur Internet, elles servent dans les réseaux internes (LAN). Parmi elles :
10.0.0.0/8,172.16.0.0/12et192.168.0.0/16. Ce sont ces adresses que vous retrouvez généralement chez vous, derrière votre box Internet ; - L’adresse loopback :
127.0.0.1correspond à l’adresse de bouclage, utilisée pour tester la pile réseau d’un ordinateur sans sortir sur le réseau ; - Les adresses réservées au broadcast : comme
255.255.255.255, utilisées pour envoyer un message à toutes les machines d’un même réseau.
Ces distinctions illustrent la flexibilité d’IPv4, qui a permis de soutenir la croissance exponentielle d’Internet pendant plusieurs décennies. Toutefois, avec seulement 4,3 milliards d’adresses possibles, ce système atteint aujourd’hui ses limites, ce qui explique l’émergence et la généralisation progressive d’IPv6.

Les limites d’IPv4 et le passage progressif à IPv6
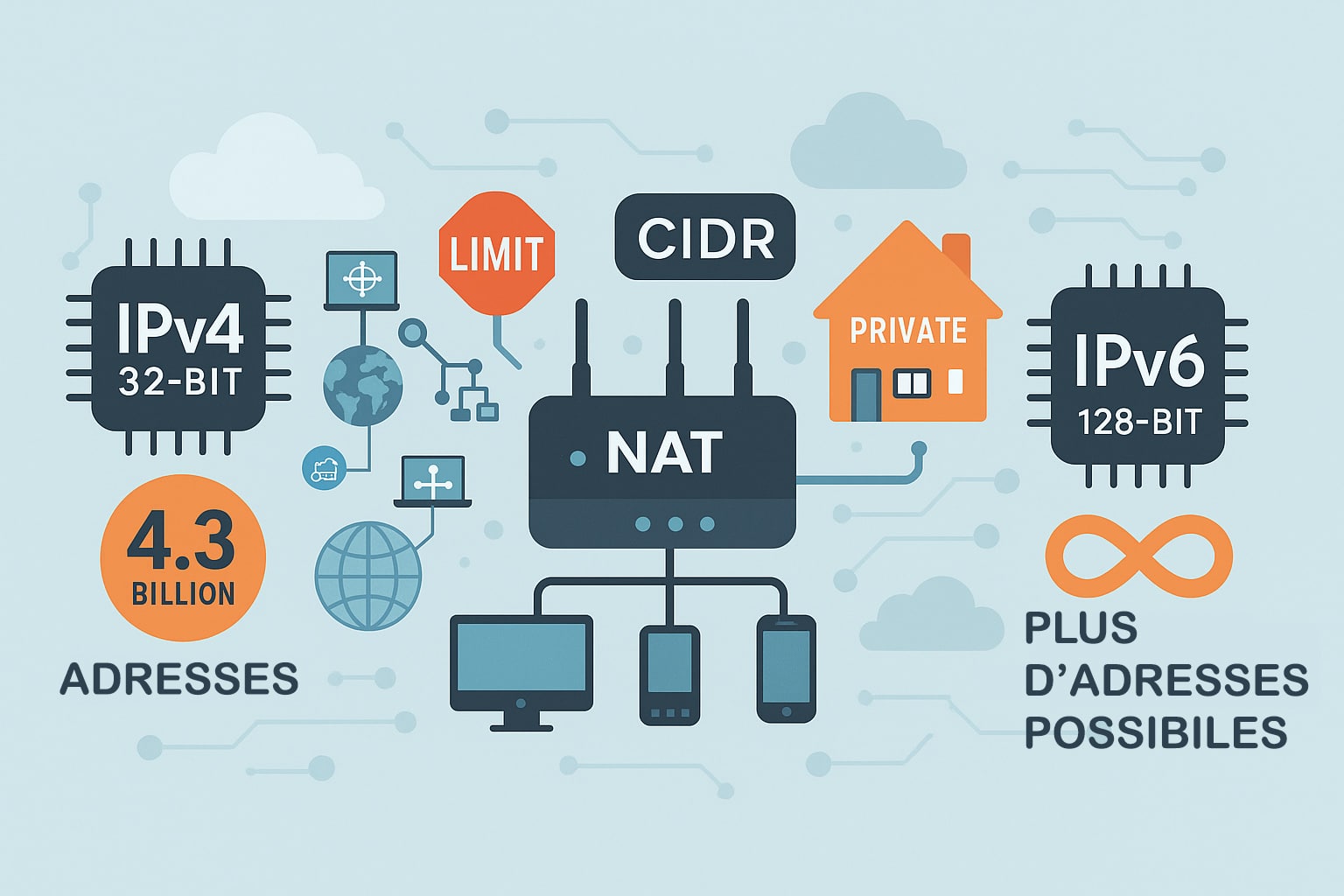
Le protocole IPv4, avec son système d’adresses sur 32 bits, permet de générer environ 4,3 milliards d’adresses uniques (2³²). Lors de sa conception au début des années 1980, ce chiffre paraissait colossal : Internet n’en était qu’à ses balbutiements, et seuls quelques milliers de machines étaient connectées via le réseau ARPANET. Cependant, l’explosion d’Internet dans les années 1990 puis 2000, combinée à la multiplication exponentielle des appareils connectés (ordinateurs personnels, smartphones, tablettes, objets connectés, serveurs cloud), a rapidement montré les limites de ce système. La pénurie d’adresses IPv4 est devenue une réalité dès la fin des années 2000. Pour pallier cette insuffisance, plusieurs solutions techniques ont été imaginées et déployées, permettant de prolonger artificiellement la durée de vie d’IPv4 :
- Le NAT (Network Address Translation) : Cette technique permet à plusieurs machines d’un même réseau local (par exemple, tous les ordinateurs d’une entreprise ou d’un foyer) de partager une seule adresse IPv4 publique. Le NAT traduit les adresses privées internes en une adresse publique unique lors des communications avec Internet. Cela a considérablement réduit la consommation d’adresses IPv4, mais a introduit des contraintes, notamment pour certaines applications nécessitant des connexions directes (jeux en ligne, visioconférences, etc.) ;
- Le CIDR (Classless Inter-Domain Routing) : Introduit en 1993, ce mécanisme a remplacé le système rigide des classes A, B et C. Le CIDR permet d’attribuer des blocs d’adresses plus flexibles, en fonction des besoins réels des réseaux, grâce à une notation basée sur le nombre de bits utilisés pour le préfixe réseau (par exemple,
/24pour 256 adresses). Ce changement a optimisé l’utilisation des plages d’adresses disponibles et limité le gaspillage ; - Les adresses privées : Certaines plages d’adresses (comme
192.168.x.x,10.x.x.x,172.16.x.x à 172.31.x.x) ont été réservées pour un usage interne aux réseaux locaux (LAN). Elles ne sont pas routées sur Internet et permettent de créer de vastes réseaux internes sans consommer d’adresses publiques rares.
Malgré ces mécanismes d’optimisation, la croissance exponentielle d’Internet a rendu inévitable la transition vers un protocole plus robuste : IPv6. Défini dès 1998 dans la RFC 2460 (puis actualisé par la RFC 8200 en 2017), IPv6 utilise des adresses sur 128 bits, soit un espace d’adressage quasi illimité : environ 340 sextillions d’adresses (2¹²⁸). Pour donner un ordre d’idée, cela correspond à 340 000 milliards de milliards de milliards d’adresses, largement suffisant pour répondre aux besoins de l’Internet des objets et au développement futur des réseaux. Au-delà de l’augmentation drastique du nombre d’adresses disponibles, IPv6 apporte aussi d’autres améliorations techniques :
- Une simplification de l’en-tête IP, facilitant le traitement des paquets par les routeurs et améliorant les performances globales ;
- L’autoconfiguration des adresses (SLAAC), permettant aux appareils de générer automatiquement leur propre adresse sans serveur DHCP ;
- Un support natif pour la sécurité avec l’intégration d’IPsec, garantissant l’intégrité et la confidentialité des communications ;
- Une meilleure gestion du multicast, optimisant la diffusion simultanée de données vers plusieurs destinataires (visioconférences, streaming, etc.).
Le déploiement d’IPv6 est progressif et coexiste aujourd’hui avec IPv4 grâce à des mécanismes de transition (double pile IPv4/IPv6, tunnels, traductions). De nombreux fournisseurs d’accès Internet, opérateurs mobiles et grandes plateformes web l’utilisent déjà en production. Cependant, IPv4 reste encore largement majoritaire, notamment en raison de la complexité des migrations et de la compatibilité avec certains équipements anciens.
L’impact des adresses IPv4 sur le SEO (référencement naturel)
Si l’IPv4 est avant tout un protocole technique destiné à faire circuler les données sur Internet, son rôle a aussi des répercussions dans le domaine du référencement naturel (SEO). L’adresse IP associée à un site web peut influencer la manière dont Google et les autres moteurs de recherche interprètent, localisent et évaluent ce site. Voici quelques aspects clés :
- La réputation d’une adresse IP : L’adresse IPv4 d’un site n’est pas seulement un identifiant technique, elle possède aussi une réputation auprès des moteurs de recherche et des services anti-spam. Sur un hébergement mutualisé, des dizaines voire des centaines de sites partagent souvent la même adresse IP. Si l’un d’entre eux diffuse du contenu spammy, du phishing ou du malware, l’ensemble de l’adresse peut être blacklistée par certains services. Même si Google évalue la qualité site par site, un serveur hébergeant une majorité de sites douteux peut envoyer des signaux négatifs. Concrètement, cela peut impacter indirectement le SEO via une perception dégradée du serveur ou en réduisant la délivrabilité des emails marketing associés au domaine ;
- Les adresses IP dédiées et SSL : Historiquement, installer un certificat SSL/TLS nécessitait une adresse IPv4 dédiée par domaine. Depuis l’arrivée du protocole SNI (Server Name Indication), plusieurs certificats peuvent coexister sur une même adresse IP. Néanmoins, certaines configurations SEO complexes (par exemple le suivi de centaines de sous-domaines via des outils de crawl automatisés, ou la gestion d’une infrastructure multi-sites à forte volumétrie) tirent encore avantage d’adresses IP dédiées. Elles permettent d’isoler chaque projet, de mieux tracer les logs et de réduire les risques d’interférences techniques entre différents sites ;
- Le crawl des moteurs : Googlebot et les autres robots d’indexation identifient un site et accèdent à ses pages via son adresse IP. Si cette IP est bloquée par un pare-feu, restreinte à une zone géographique, ou victime d’une mauvaise configuration DNS, le robot peut se voir refuser l’accès. Cela se traduit par une indexation partielle, voire inexistante de certaines pages. Par ailleurs, certains sites mettent en place des restrictions IP pour contrer le scraping ou limiter le trafic automatisé, ce qui peut accidentellement bloquer les robots de moteurs de recherche. Une mauvaise gestion de ces règles réseau peut donc ralentir la découverte de nouveaux contenus et nuire au référencement.
- La gestion multi-sites : Pour les entreprises gérant plusieurs sites, marques ou versions linguistiques, utiliser plusieurs adresses IP peut permettre d’isoler les projets. Cela limite les risques de confusion pour Google, en particulier lorsqu’il s’agit de sites proches thématiquement ou utilisant des contenus similaires. Par exemple, deux versions d’un même site (France et Canada) hébergées sur des IP différentes peuvent renforcer les signaux de géolocalisation, surtout si les adresses sont attribuées à des FAI locaux. Cela ne remplace pas des optimisations SEO essentielles (comme les balises
hreflangou les redirections canoniques), mais peut constituer un signal complémentaire utile dans une stratégie internationale.
L’importance de la géolocalisation des adresses IPv4 pour les sites Internet
Un autre aspect souvent méconnu de l’IPv4 concerne la géolocalisation. En effet, chaque adresse IP publique est attribuée à une organisation et à une zone géographique précise par l’un des registres régionaux (RIPE pour l’Europe, ARIN pour l’Amérique du Nord, APNIC pour l’Asie-Pacifique, LACNIC pour l’Amérique latine, AFRINIC pour l’Afrique). Grâce à ces allocations, il est possible de déterminer approximativement le pays, voire la région ou la ville d’origine d’une adresse IPv4. Cette information est exploitée à la fois par les services en ligne (plateformes de streaming, e-commerçants, sites d’actualités) et par les moteurs de recherche comme Google. Pour les sites web, la géolocalisation joue un rôle non négligeable dans le référencement local. Google peut, par exemple, mettre en avant un site hébergé en Espagne lorsqu’un internaute situé à Madrid recherche un service local, même si le site n’indique pas explicitement sa zone d’activité. L’IPv4 agit donc comme un signal supplémentaire, qui complète d’autres critères comme :
- La langue du contenu et des balises HTML,
- Les balises hreflang pour le SEO international,
- Les données structurées (schema.org),
- Et l’inscription dans Google Business Profile.
Voici quelques exemples typiques de plages IPv4 par pays et opérateurs :
| Plage IPv4 | Pays associé |
|---|---|
| 51.158.x.x | France (hébergeurs parisiens, souvent utilisés par OVH ou Scaleway) |
| 8.8.8.8 | États-Unis (Google Public DNS, très utilisé pour le test et la résolution DNS) |
| 62.156.x.x | Allemagne (Deutsche Telekom, principal opérateur historique) |
| 82.112.x.x | Espagne (Telefónica Movistar, réseau fixe et mobile) |
| 202.56.x.x | Inde (BSNL, opérateur national public) |
| 41.0.0.0 – 41.255.255.255 | Afrique (attribuées par AFRINIC, largement utilisées au Nigeria, Afrique du Sud et Égypte) |
| 177.0.0.0 – 177.255.255.255 | Amérique latine (LACNIC, souvent utilisé au Brésil et en Argentine) |
| 123.0.0.0 – 123.255.255.255 | Asie-Pacifique (APNIC, largement déployé en Chine et au Japon) |
| 203.0.113.0 – 203.0.113.255 | APNIC (plage réservée aux exemples et documentations techniques, mais géolocalisée en Asie) |
Connaître et maîtriser la localisation d’une adresse IPv4 est donc stratégique pour les sites internationaux. Par exemple :
- Un site e-commerce français ciblant les États-Unis aura tout intérêt à héberger ses pages américaines sur un serveur disposant d’une adresse IPv4 localisée aux États-Unis ou à utiliser un CDN (Content Delivery Network) pour rapprocher son contenu de ses utilisateurs ;
- Un site multilingue (ex. français et espagnol) pourra bénéficier de deux adresses IP distinctes (France et Espagne), renforçant les signaux envoyés à Google quant à la pertinence géographique ;
- Les services de streaming (Netflix, Spotify, YouTube) s’appuient largement sur cette logique pour adapter leurs catalogues selon les pays, via la reconnaissance de l’IPv4 de l’utilisateur.

Enfin, il convient de rappeler que Google ne se base pas uniquement sur l’IPv4 pour déterminer la pertinence géographique d’un site. L’adresse IP est un signal parmi d’autres, intégré à une multitude de critères (contenu, backlinks, données locales structurées). Elle doit donc être envisagée comme un indicateur complémentaire, à intégrer dans une stratégie SEO internationale bien construite.

0 commentaires