Dans l’univers des technologies web, chaque interaction entre un client (navigateur, robot, application) et un serveur s’appuie sur un ensemble d’informations techniques. L’une des plus fondamentales, mais souvent méconnue du grand public, est le User-Agent. Présent dans chaque requête HTTP, ce petit fragment de texte joue un rôle déterminant dans la manière dont un site web perçoit, analyse et répond à la demande du visiteur. Que cache exactement cette chaîne appelée User-Agent ? Comment fonctionne-t-elle ? Et pourquoi est-elle si importante pour les développeurs, référenceurs ou administrateurs système ? Cet article vous plonge dans les coulisses de cette donnée essentielle du protocole web.
- Historique, évolutions et impact SEO du User-Agent dans l’écosystème web
- Le fonctionnement du User-Agent : Communication, adaptation et détection
- 1. Communication initiale avec un user-agent : L’échange client-serveur
- 2. Adaptation du contenu : UX, performance et accessibilité
- 3. Détection et filtrage d’un user-agent : Une barrière technique contre les robots indésirables
- 4. L’exploitation statistique : Analyser l’audience par terminal
- 5. Conséquences SEO : un élément technique à surveiller
- Des exemples de User-Agents : navigateurs, bots, et périphériques
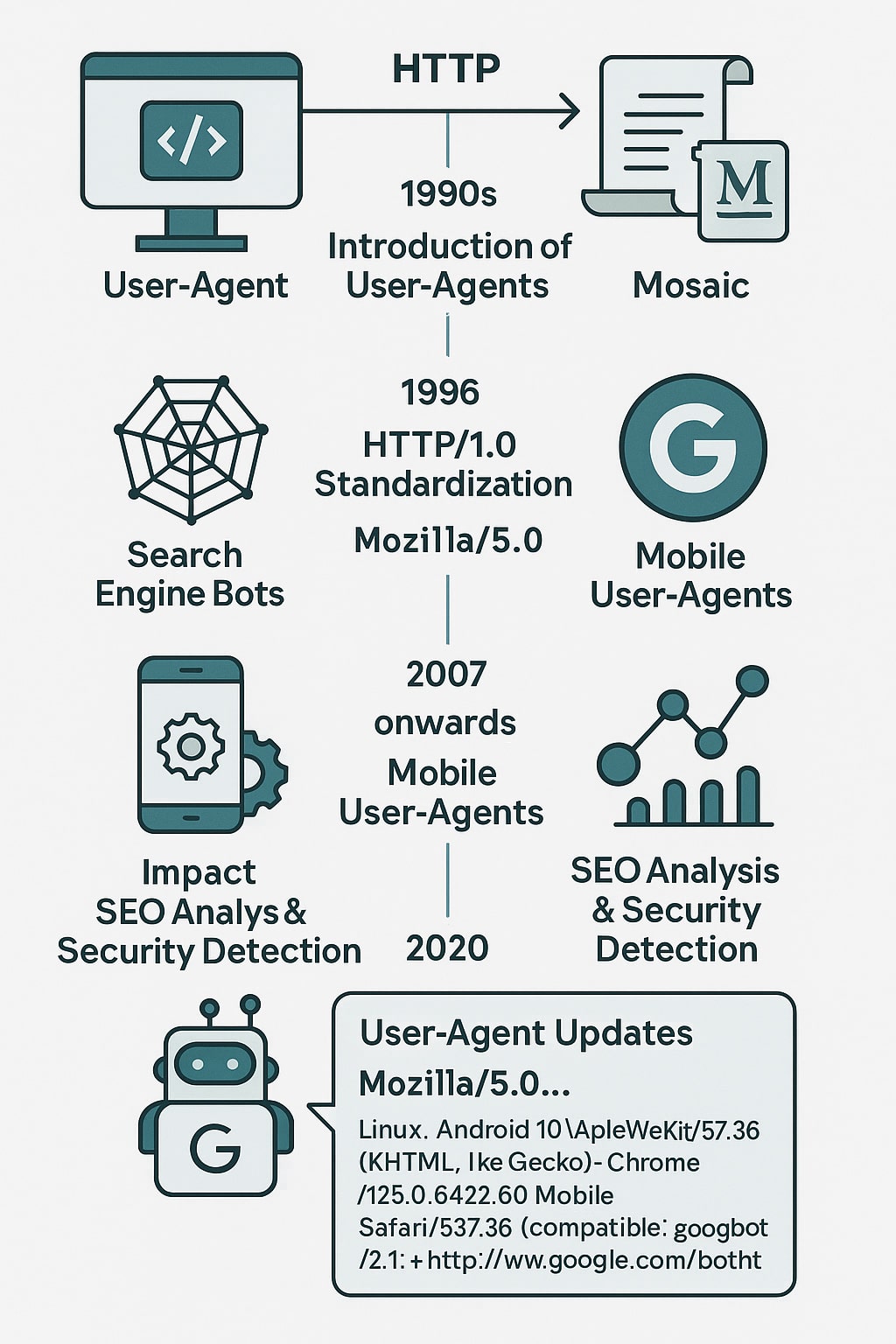
Historique, évolutions et impact SEO du User-Agent dans l’écosystème web
La notion de User-Agent est intimement liée à l’histoire du web et à l’évolution des protocoles de communication entre clients et serveurs. Dès les débuts du Web dans les années 1990, alors que Tim Berners-Lee posait les bases du World Wide Web au CERN, la nécessité de distinguer les types de clients accédant aux ressources en ligne s’est imposée. Le protocole HTTP/1.0, publié officiellement en 1996 par le W3C, a introduit les en-têtes de requête comme moyen de contextualiser la communication. L’un d’eux, le User-Agent, permettait alors d’identifier le navigateur utilisé (principalement Mosaic, puis Netscape Navigator, pionnier du web graphique fondé en 1994 à Mountain View).
À cette époque, les chaînes User-Agent étaient simples, souvent composées uniquement du nom du navigateur et de son numéro de version. Mais très vite, la compétition entre navigateurs a forcé les éditeurs à intégrer des informations supplémentaires (parfois même trompeuses) pour maximiser la compatibilité des sites. Ainsi, même des navigateurs modernes comme Google Chrome ou Microsoft Edge conservent aujourd’hui la mention Mozilla/5.0 dans leur User-Agent, pour assurer la compatibilité avec les serveurs mal configurés ou anciens scripts de détection.
Au début des années 2000, l’essor des robots d’indexation (comme Googlebot (lancé en 1998), Slurp (Yahoo) ou Bingbot) a donné une nouvelle importance au User-Agent dans les pratiques du référencement naturel (SEO). En effet, ces bots identifient clairement leur nature via une chaîne dédiée, ce qui permet aux administrateurs de sites de :
- Vérifier le comportement de ces robots dans les logs serveurs
- Adapter l’affichage ou la structure du site (version « light », suppression de scripts bloquants, etc.)
- Restreindre ou autoriser l’accès à certaines ressources via le fichier
robots.txtou des règles spécifiques côté serveur
Avec l’arrivée des smartphones (notamment après 2007 avec le lancement de l’iPhone), les User-Agents se sont enrichis de paramètres spécifiques aux appareils mobiles. Cela a été déterminant pour le développement du responsive design, et pour les stratégies SEO orientées mobile, en particulier après l’annonce du Mobile First Index de Google en 2018. Depuis cette date, Googlebot Mobile est le principal User-Agent utilisé pour explorer les sites, ce qui impose une compatibilité totale avec les versions mobiles des pages web. En SEO, l’analyse des User-Agents dans les journaux de logs permet d’auditer finement le comportement des bots :
- Quelle fréquence de crawl pour Googlebot ?
- Le site est-il correctement exploré sur mobile ?
- Des bots inconnus ou malveillants tentent-ils un accès illégitime ?
Mais l’usage du User-Agent ne se limite pas au SEO. De nombreux faux bots ou scripts automatisés se font passer pour des agents légitimes afin de scraper des contenus, contourner des restrictions ou tester la sécurité d’un site. Cela pose un défi croissant pour les systèmes de détection, poussant les éditeurs à combiner l’analyse du User-Agent avec d’autres paramètres comme l’adresse IP, le comportement de navigation ou les entêtes supplémentaires (comme Accept-Language ou Referer). En 2020, Google a annoncé une évolution de ses propres User-Agents, avec une nouvelle nomenclature plus explicite, incluant la mention Mobile ou Desktop et la version du moteur de rendu utilisé (basé sur Chrome). Exemple :
Mozilla/5.0 (Linux; Android 10) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.6422.60 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)Enfin, notons que l’évolution vers HTTP/2 et bientôt HTTP/3 ne remet pas en cause l’usage du User-Agent, mais incite à sa rationalisation : certaines chaînes très longues ou mal structurées sont désormais considérées comme obsolètes. Des projets comme User-Agent Client Hints visent à décomposer l’information utilisateur en plusieurs champs distincts, plus faciles à contrôler, sécuriser et personnaliser côté navigateur.
Le fonctionnement du User-Agent : Communication, adaptation et détection
Lorsqu’un utilisateur accède à un site web, son navigateur (ou client HTTP) envoie une requête HTTP au serveur. Cette requête contient des en-têtes (ou headers) qui apportent des informations techniques sur l’environnement du client. Parmi ces en-têtes figure le fameux User-Agent, une chaîne de caractères qui agit comme une carte d’identité numérique du terminal émetteur.
1. Communication initiale avec un user-agent : L’échange client-serveur
Le processus commence par une communication standard entre le client et le serveur :</
- Le navigateur ou robot envoie une requête HTTP, incluant un en-tête
User-Agent. - Le serveur web reçoit cette requête et analyse les headers.
- En fonction du User-Agent détecté, le serveur peut répondre avec un contenu adapté (HTML, CSS, JS…), ou rediriger le client vers une version spécifique du site.
Par exemple, un site peut proposer une version mobile à un User-Agent de type Android ou iPhone, tandis qu’un User-Agent de type Googlebot entraînera un rendu optimisé pour le crawl SEO.
2. Adaptation du contenu : UX, performance et accessibilité
Le User-Agent permet d’ajuster dynamiquement l’expérience utilisateur. C’est un outil puissant pour adapter :
- Le design : chargement d’une version mobile ou responsive avec des boutons plus larges, un menu simplifié, moins d’animations lourdes.
- Les ressources : limitation ou modification des scripts, images allégées, désactivation de fonctionnalités non compatibles (ex : WebGL sur navigateur obsolète).
- La langue ou la géolocalisation : en complément du User-Agent, le serveur peut combiner les données pour proposer un contenu adapté à la zone géographique ou à la langue présumée du visiteur.
Cette logique est souvent gérée côté serveur (via PHP, Node.js, etc.) ou à travers des outils comme les CDN (Content Delivery Networks) qui filtrent le trafic selon les User-Agents pour distribuer intelligemment le contenu le plus performant selon le terminal.
3. Détection et filtrage d’un user-agent : Une barrière technique contre les robots indésirables
Le User-Agent constitue l’un des premiers éléments d’identification d’un visiteur sur un site web, et il est régulièrement exploité pour mettre en place des mécanismes de détection et de filtrage automatisé. En analysant la chaîne User-Agent, les administrateurs peuvent détecter si la requête provient d’un navigateur humain standard (comme Chrome ou Safari), d’un robot d’indexation bienveillant (comme Googlebot ou Bingbot), ou d’un outil d’automatisation ou de scraping plus douteux. Cela permet par exemple de bloquer l’accès aux navigateurs obsolètes qui ne prennent pas en charge les dernières normes de sécurité, comme Internet Explorer 10, afin d’éviter les failles connues. Cette mesure améliore à la fois la protection du site et l’uniformité de l’expérience utilisateur. À l’inverse, certains User-Agents peuvent être autorisés et même traités avec des optimisations spécifiques, comme les bots SEO légitimes ou les prévisualisateurs de réseaux sociaux (Slackbot, Discordbot, etc.).
Les outils de cybersécurité, en particulier les WAF (Web Application Firewalls) et les systèmes de protection anti-DDoS, intègrent des modules spécifiques pour surveiller et filtrer les User-Agents suspects. Des listes de User-Agents malveillants connus (maintenues par des communautés de sécurité ou des prestataires spécialisés) sont consultées en temps réel pour bloquer automatiquement les comportements anormaux. Ces filtres sont particulièrement utiles pour contrer des menaces courantes comme les brute force attacks, les crawlers agressifs qui tentent d’aspirer le contenu d’un site, ou les requêtes destinées à identifier des failles techniques. Cependant, il faut noter que le filtrage par User-Agent ne suffit pas à lui seul : De nombreux bots usurpent des User-Agents valides (par exemple celui de Googlebot), ce qui oblige les administrateurs à croiser ces données avec l’analyse des adresses IP, la fréquence des requêtes ou les schémas de comportement pour affiner la détection et éviter les faux positifs.
4. L’exploitation statistique : Analyser l’audience par terminal
Les outils de mesure d’audience, comme Google Analytics ou Matomo, utilisent également les User-Agents pour analyser les habitudes de navigation. Cela permet de :
- Savoir quelle proportion de visiteurs utilisent un mobile, une tablette ou un ordinateur de bureau.
- Identifier les navigateurs dominants (Chrome, Safari, Firefox…) pour orienter les choix de compatibilité.
- Suivre l’évolution des systèmes d’exploitation (Windows, macOS, Android, iOS, Linux).
Cette analyse fine est essentielle pour prendre des décisions stratégiques sur les formats de contenu, les performances attendues ou les priorités de développement (par exemple : faut-il encore prendre en charge Internet Explorer 11 ?).
5. Conséquences SEO : un élément technique à surveiller
En SEO, le User-Agent joue un rôle souvent sous-estimé mais déterminant. Il permet notamment de :
- Vérifier si Googlebot ou Googlebot Mobile accède bien aux bonnes versions de pages.
- Contrôler les réponses serveur spécifiques selon les robots (ex : redirections, codes HTTP, contenus allégés).
- Éviter les cloaking involontaires : C’est-à-dire présenter un contenu différent aux robots et aux utilisateurs, ce qui peut être sanctionné par Google.
Les experts SEO utilisent souvent des outils de crawl comme Screaming Frog Spider, Sitebulb ou OnCrawl pour simuler des User-Agents précis et tester la manière dont le site réagit. Cela permet de valider que les bots d’indexation voient bien ce qu’il faut, et de déceler d’éventuelles erreurs de configuration ou d’optimisation.
La richesse du User-Agent réside dans la grande variété de clients qui accèdent aux serveurs web. Chaque terminal — navigateur web, robot d’indexation, application mobile ou même terminal embarqué — possède une chaîne User-Agent qui reflète ses caractéristiques. Ces chaînes sont structurées selon des conventions propres à chaque éditeur, ce qui permet aux serveurs et outils d’analyse de les classer et de réagir en conséquence. Voici un tableau présentant plusieurs exemples représentatifs de User-Agents, regroupés par type de client :
| Type de client | Exemple de User-Agent |
|---|---|
| Googlebot (robot de Google) | Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
| Bingbot (robot de Microsoft pour Bing) | Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) |
| Safari sur iPhone | Mozilla/5.0 (iPhone; CPU iPhone OS 17_0 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.0 Mobile/15E148 Safari/604.1 |
| Chrome sur Android | Mozilla/5.0 (Linux; Android 13; Pixel 6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.6422.112 Mobile Safari/537.36 |
| Firefox sur Linux | Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:124.0) Gecko/20100101 Firefox/124.0 |
| Edge sur Windows | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.6422.60 Safari/537.36 Edg/125.0.2535.67 |
| DuckDuckBot (robot du moteur DuckDuckGo) | DuckDuckBot/1.0; (+http://duckduckgo.com/duckduckbot.html) |
| AhrefsBot (outil SEO) | Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/) |
| Googlebot Mobile (indexation mobile) | Mozilla/5.0 (Linux; Android 10) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.6422.60 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
| Facebook External Hit (prévisualisation de liens) | facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php) |
| Slackbot LinkExpanding | Slackbot-LinkExpanding 1.0 (+https://api.slack.com/robots) |
| Opera sur macOS | Mozilla/5.0 (Macintosh; Intel Mac OS X 13_5_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.6422.60 Safari/537.36 OPR/110.0.5130.31 |
| TelegramBot | TelegramBot (like TwitterBot) |
| Internet Explorer 11 | Mozilla/5.0 (Windows NT 6.1; Trident/7.0; rv:11.0) like Gecko |
| Google PageSpeed Insights | Mozilla/5.0 (Linux; Android 9; SM-G960F) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.6422.112 Mobile Safari/537.36 (compatible; Google Page Speed Insights) |
Ces exemples montrent à quel point le champ des User-Agents est vaste : il ne se limite pas aux navigateurs classiques, mais inclut aussi des robots d’analyse, des crawlers d’indexation, des assistants vocaux, des services de messagerie, et des outils SEO. Chaque User-Agent a une structure spécifique qui peut indiquer :
- Le type d’appareil (mobile, desktop, tablette, bot…)
- Le système d’exploitation (Windows, macOS, Android, iOS…)
- Le moteur de rendu (WebKit, Gecko, Blink…)
- La version du navigateur ou du robot
Il est essentiel de souligner que certains scripts malveillants ou crawlers frauduleux peuvent usurper l’identité d’User-Agents connus, une pratique appelée User-Agent spoofing. Par exemple, un scraper automatisé peut se faire passer pour Googlebot pour éviter d’être bloqué. C’est pourquoi les outils professionnels de sécurité web et d’analyse serveur croisent souvent ces informations avec d’autres signaux (adresses IP officielles, comportement de navigation, fréquence d’accès) pour vérifier leur authenticité.
Dans le cadre du référencement naturel, savoir interpréter les User-Agents est indispensable pour valider la bonne indexation d’un site, identifier les robots d’audit (comme Screaming Frog ou SemrushBot), ou détecter d’éventuels abus. Cela fait partie des bonnes pratiques de log analyse en SEO technique.

0 commentaires