Lorsqu’il est question de traitement automatique du langage en SEO, la lemmatisation est souvent mise en avant pour sa capacité à ramener les mots à leur forme canonique. Cette approche, fondée sur une analyse grammaticale fine, permet une compréhension précise des contenus par les moteurs de recherche. Pourtant, il existe une méthode plus rapide, plus légère, mais aussi plus radicale dans son fonctionnement : La racinisation. Contrairement à la lemmatisation, qui prend en compte le contexte linguistique, la racinisation se contente d’extraire le radical du mot, sans s’interroger sur son rôle syntaxique ou sa validité lexicale. Cette simplification algorithmique offre un avantage majeur : la performance. Elle est largement utilisée dans des systèmes où la vitesse de traitement prime sur la précision linguistique, comme dans certains outils d’indexation, de recherche interne ou d’analyse sémantique basique. Mais que signifie concrètement “raciniser” un mot ? En quoi cette méthode diffère-t-elle de la lemmatisation ? Et surtout, quelle est sa valeur ajoutée dans une stratégie de référencement naturel ? Dans cet article, nous explorons les principes techniques de la racinisation, ses cas d’usage concrets en SEO, et la manière dont elle peut compléter d’autres méthodes linguistiques pour améliorer la lisibilité algorithmique de vos contenus web.
La définition de la racinisation et son fonctionnement
La racinisation (ou stemming en anglais) est une technique de traitement automatique du langage naturel (TAL ou NLP pour Natural Language Processing) qui vise à réduire un mot fléchi à sa forme radicale. Cette forme radicale, appelée stem ou racine, n’est pas nécessairement un mot valide du dictionnaire, mais elle permet de regrouper différentes variantes morphologiques d’un même mot sous une entité commune. L’objectif est de simplifier l’analyse lexicale, en particulier dans les contextes de recherche d’information, d’indexation documentaire ou d’analyse de texte. La racinisation fonctionne en supprimant les affixes (préfixes et surtout suffixes) selon des règles morphologiques déterministes. Contrairement à la lemmatisation, qui s’appuie sur une analyse grammaticale approfondie (catégorie du mot, conjugaison, accord, etc.) et sur des dictionnaires linguistiques, la racinisation applique des règles de découpe formelles et fixes. Elle ne tient pas compte du contexte grammatical ni du sens du mot. Voici quelques exemples illustrant ce processus :
- marcher, marcherait, marchaient, marchons → march
- joue, jouer, jouaient, jouait → jou
- création, créatif, créer, créant → cré
Dans chacun de ces cas, les mots sont réduits à une forme tronquée. Le résultat peut ne pas être une entrée du dictionnaire. Par exemple, “cré” n’est pas un mot reconnu en tant que tel, mais il permet de regrouper toutes les variantes de la même famille lexicale. Cette normalisation approximative permet d’améliorer le rappel lors d’une recherche d’information, c’est-à-dire la capacité à retrouver tous les documents pertinents, même si les termes exacts ne correspondent pas à ceux de la requête. La racinisation repose sur des algorithmes de découpe morphologique, généralement basés sur des heuristiques. Ces algorithmes sont souvent codés manuellement sous forme de règles linguistiques (ex : suppression du suffixe -ment, -ion, -er, -ait, etc.) et peuvent différer d’une langue à l’autre. Parmi les algorithmes de stemming les plus connus :
- Porter Stemmer : Développé en 1980 par Martin Porter, il repose sur une série de règles séquentielles de suppression de suffixes. Il est largement utilisé dans les systèmes de recherche anglophones comme Lucene ou ElasticSearch ;
- Snowball Stemmer : Parfois appelé « Porter2 », il s’agit d’une version plus moderne, plus claire et plus facilement extensible du Porter Stemmer. Il est disponible pour plusieurs langues, dont le français ;
- Lovins Stemmer : Plus ancien et plus agressif, cet algorithme peut raccourcir les mots jusqu’à des racines très réduites, ce qui augmente le risque de confusion entre mots non apparentés ;
- Lancaster Stemmer : Encore plus agressif que Lovins, il est utilisé dans des contextes où la vitesse est prioritaire sur la précision linguistique.
Il est important de noter que la racinisation est généralement non réversible : une fois un mot racinisé, il est impossible de revenir à sa forme originale sans contexte ou dictionnaire. Cela limite son usage dans les systèmes nécessitant une restitution linguistique correcte.
En français, le processus de racinisation est plus complexe qu’en anglais en raison des nombreuses terminaisons et flexions grammaticales. Par exemple, les verbes du premier groupe (comme parler) se conjuguent en des dizaines de formes, les noms et adjectifs varient en genre et en nombre, et les suffixes dérivationnels sont fréquents (acteur → action → activité → activation, etc.). Pour répondre à cette complexité morphologique, certains outils NLP proposent des stemmers spécifiquement conçus pour la langue française, intégrant des règles plus fines ou des exceptions. On peut citer notamment :
- TreeTagger : Plus orienté lemmatisation mais intégrant des modules de segmentation morphologique utiles pour le stemming ;
- Spacy : Via des pipelines multilingues, il permet l’application de stemmers ou de lemmatiseurs selon les besoins ;
- NLTK (Natural Language Toolkit) : Cette bibliothèque Python intègre plusieurs stemmers pour l’anglais, et permet d’ajouter des règles personnalisées pour d’autres langues.
Enfin, des solutions plus récentes combinent les approches statistiques et les méthodes traditionnelles de stemming pour créer des stemmers hybrides, capables d’adapter leur comportement en fonction des corpus traités. Ces méthodes sont notamment utilisées dans les moteurs de recherche contextuels ou les outils d’analyse sémantique avancée.

Les avantages et inconvénients de la racinisation en SEO (en particulier pour la rédaction Web)
En référencement naturel, et notamment en ce qui concerne la rédaction WEB SEO, la racinisation est une solution pragmatique pour le traitement rapide de corpus textuels étendus. Grâce à son approche algorithmique directe, elle permet de réduire considérablement la charge computationnelle liée à l’analyse morphologique. Au lieu d’analyser chaque mot dans son contexte syntaxique, comme le ferait une lemmatisation, elle tronque les mots jusqu’à leur racine la plus commune, permettant ainsi de regrouper différentes formes flexionnelles d’un même terme. Cette méthode s’avère particulièrement utile dans des environnements techniques où la performance est prioritaire, ou dans des cas où une granularité linguistique fine n’est pas indispensable. Voici quelques situations où la racinisation présente un intérêt concret en SEO :
- Optimisation des moteurs internes de recherche : Lorsqu’un internaute saisit une requête approximative ou partiellement incorrecte (par exemple, faute de frappe, verbe mal conjugué, accord erroné), la racinisation permet de retrouver les contenus associés en identifiant les racines communes. Cela améliore l’expérience utilisateur tout en renforçant la pertinence des suggestions de recherche ;
- Indexation de contenus à grande échelle : Dans le cadre d’un audit SEO massif, d’un crawl de site ou d’une analyse sémantique automatisée, la racinisation facilite le regroupement des variantes lexicales sans nécessiter de ressources linguistiques complexes. Elle permet de traiter des millions de tokens en un temps réduit, ce qui est déterminant dans les pipelines de traitement de données volumineuses ;
- Évaluation de la densité sémantique : Lors de l’optimisation d’un contenu, la racinisation aide à identifier les occurrences proches d’un même mot-clé sous ses différentes formes. En regroupant ces déclinaisons autour d’une racine unique, on obtient une vision plus homogène du champ lexical abordé dans la page, utile pour vérifier la cohérence sémantique par rapport à l’intention de recherche ciblée.
Comme toute méthode algorithmique, la racinisation comporte toutefois des limites. Elle privilégie la performance au détriment de la précision linguistique. En l’absence d’analyse contextuelle, elle peut générer des résultats ambigus, voire contre-productifs si elle est utilisée seule pour piloter une stratégie sémantique. Voici un tableau comparatif des principaux avantages et inconvénients de la racinisation en SEO :
| Avantages | Limites |
|---|---|
| Très rapide à exécuter, même sur des corpus volumineux. | Peut produire des racines non compréhensibles (ex : cré). |
| Réduit la complexité lexicale pour regrouper les formes proches d’un mot. | Ignore le contexte grammatical ou sémantique, ce qui peut fausser l’interprétation. |
| Facile à implémenter dans des scripts ou outils SEO personnalisés (Python, ElasticSearch…). | Peut générer des regroupements erronés (faux positifs) entre mots sans lien sémantique réel. |
| Compatible avec les outils d’analyse sémantique basique ou de text mining. | Moins adaptée aux langues à morphologie complexe comme le français, où la précision est cruciale. |
Dans une stratégie SEO, il est donc important de considérer la racinisation comme un outil complémentaire plutôt qu’une solution unique. Elle trouve pleinement sa place dans les phases d’analyse exploratoire, d’audit ou de prétraitement de texte. En revanche, pour la génération ou l’optimisation de contenus à forte valeur ajoutée, une lemmatisation plus fine, combinée à une analyse des cooccurrences ou des entités nommées, sera préférable.

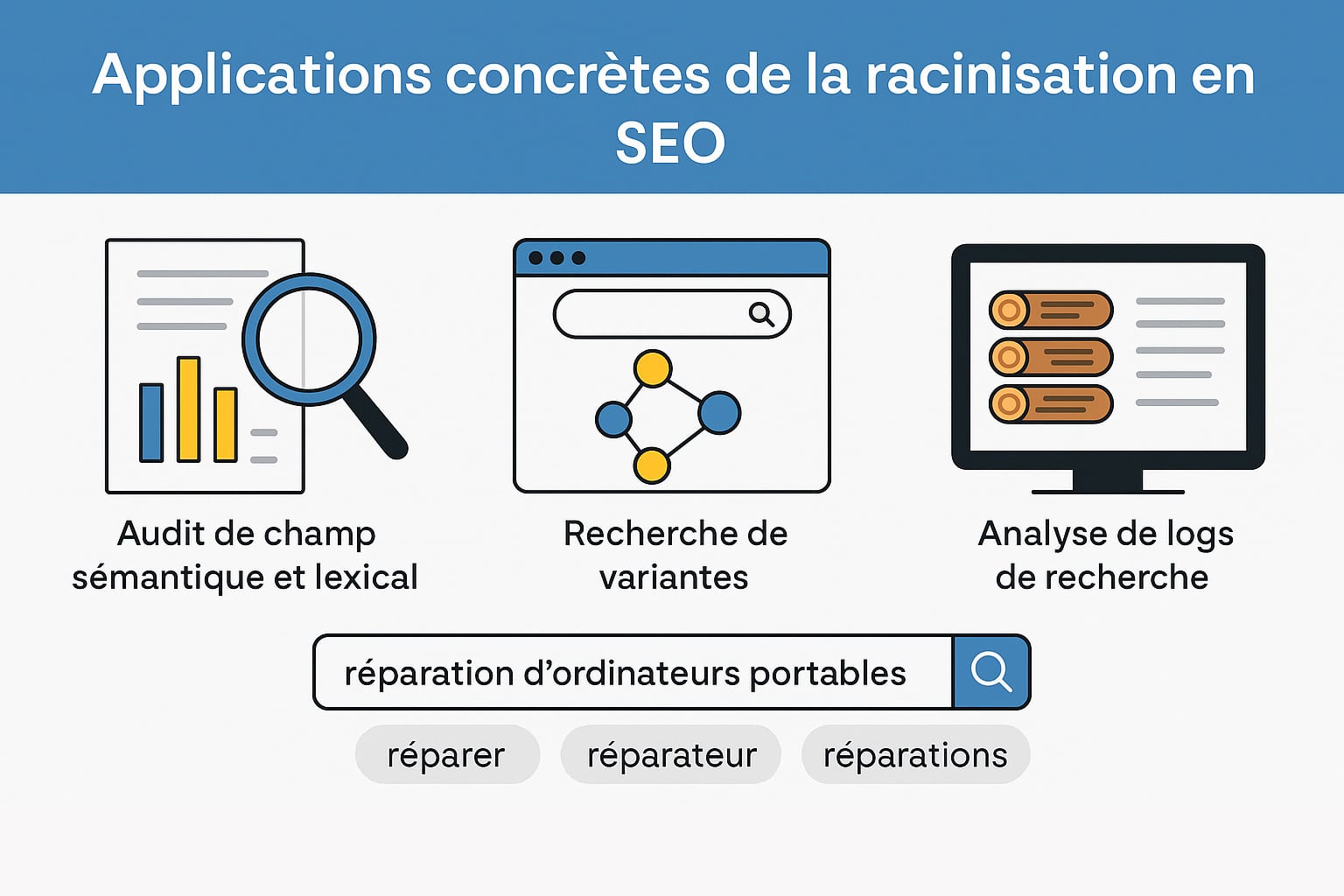
Les applications concrètes de la racinisation en référencement naturel
Dans une stratégie SEO moderne, la racinisation intervient comme un outil d’analyse linguistique capable de simplifier le traitement de larges volumes de texte tout en conservant une cohérence lexicale utile à l’optimisation sémantique. Cette méthode trouve sa place aussi bien dans les phases techniques de prétraitement que dans les actions de production ou d’enrichissement de contenu. Elle permet de détecter rapidement les racines communes entre plusieurs formes d’un même mot, sans recourir à une analyse syntaxique poussée, ce qui en fait un levier efficace dans de nombreuses tâches SEO. Voici plusieurs domaines dans lesquels la racinisation peut être intégrée avec pertinence dans un workflow de référencement naturel :
- Audit de champ sémantique et lexical : Lors de l’analyse d’un contenu existant, un algorithme de stemming peut extraire les radicaux les plus fréquemment utilisés. Cela permet d’évaluer si le champ lexical mobilisé est bien aligné avec les objectifs sémantiques de la page (mot-clé cible, intention de recherche, thème global). Cette approche est particulièrement utile pour les audits automatisés de contenus à grande échelle, comme lors de la refonte SEO d’un site comportant des centaines ou des milliers d’URLs.
- Recherche de variantes lexicales : Dans une logique de cocon sémantique, la racinisation permet de regrouper sous un même radical des termes morphologiquement liés. Cela facilite la création d’un maillage interne riche et pertinent autour d’un thème donné. Par exemple, autour du radical répar, vous pouvez imaginer une arborescence sémantique contenant des pages sur réparation, réparateur, réparer un écran, coût d’une réparation, etc. Ce regroupement offre une meilleure distribution des liens internes et une densité sémantique maîtrisée sans forcer la répétition du mot-clé principal ;
- Analyse des logs de recherche : Dans les outils de recherche interne des sites e-commerce ou institutionnels, la racinisation permet d’analyser les requêtes tapées par les utilisateurs en extrayant les racines communes. Cela aide à identifier les intentions réelles de recherche même lorsque la saisie est partielle, approximative ou erronée. Par exemple, acheter, achète, achat seront tous liés au radical achet, ce qui permet de mieux structurer les pages de résultats et d’alimenter une base de données de requêtes pertinentes ;
- Enrichissement automatique de contenu : Les outils de suggestion de mots-clés, d’écriture assistée ou de réécriture sémantique intègrent souvent des modules de racinisation pour proposer des variantes pertinentes d’un mot sans doublon. Cela est utile pour produire des textes riches, éviter la suroptimisation, et générer des paragraphes diversifiés en termes lexicaux.
- Clustering de contenus : Dans des outils de veille ou d’analyse concurrentielle, la racinisation permet de regrouper des contenus traitant d’un même thème, même si les formes lexicales diffèrent. Cela facilite l’identification des sujets dominants sur un corpus de concurrents ou de blogs d’un secteur donné.
Un exemple concret : Si vous rédigez une page sur le thème “réparation d’ordinateurs portables”, un outil doté d’un module de racinisation pourra identifier automatiquement que les mots réparer, réparations, réparateur, réparé partagent une base commune (répar). Cela vous évite de devoir insérer explicitement toutes les formes fléchies de ce mot pour assurer une bonne couverture lexicale. Le texte gagne ainsi en fluidité tout en conservant une excellente pertinence sémantique aux yeux des moteurs de recherche.
Par ailleurs, la racinisation est aussi exploitée dans les solutions de suggestion de mots-clés intelligents. Lorsqu’un rédacteur saisit un terme de base, l’outil peut automatiquement proposer des variantes issues de la même racine, y compris issues d’un contexte d’usage différent (noms, verbes, adjectifs, etc.). Cela permet de mieux cibler les intentions de recherche périphériques et d’élargir le champ lexical du contenu sans se perdre dans des reformulations artificielles. Autre domaine d’application : le monitoring sémantique. En suivant l’évolution des racines utilisées dans les contenus d’un site au fil du temps, on peut détecter une dérive thématique ou une perte de cohérence avec les axes SEO initiaux. La racinisation devient alors un outil de pilotage éditorial pour garder un cap sémantique clair.
Enfin, certaines plateformes d’automatisation SEO intègrent des pipelines de traitement du langage où la racinisation intervient comme étape de nettoyage, de simplification ou de regroupement avant des opérations plus avancées comme la vectorisation de texte, l’analyse de sentiment ou la catégorisation automatique. Elle s’inscrit donc pleinement dans une approche NLP modulaire et orientée performance.

0 commentaires