Dans le vaste écosystème du développement web, certains outils ont profondément transformé les méthodes de travail des développeurs. Parmi eux, Node.js occupe une place de choix. Né au croisement du JavaScript côté client et des exigences de performance côté serveur, Node.js a bouleversé les architectures traditionnelles en introduisant une approche asynchrone, légère et hautement scalable. Mais qu’est-ce que Node.js exactement ? À quoi sert-il ? Et comment fonctionne-t-il en coulisses ? Ce guide détaillé vous propose une immersion complète dans l’univers de cette technologie incontournable du web moderne.
La définition de Node.js et ses origines historiques
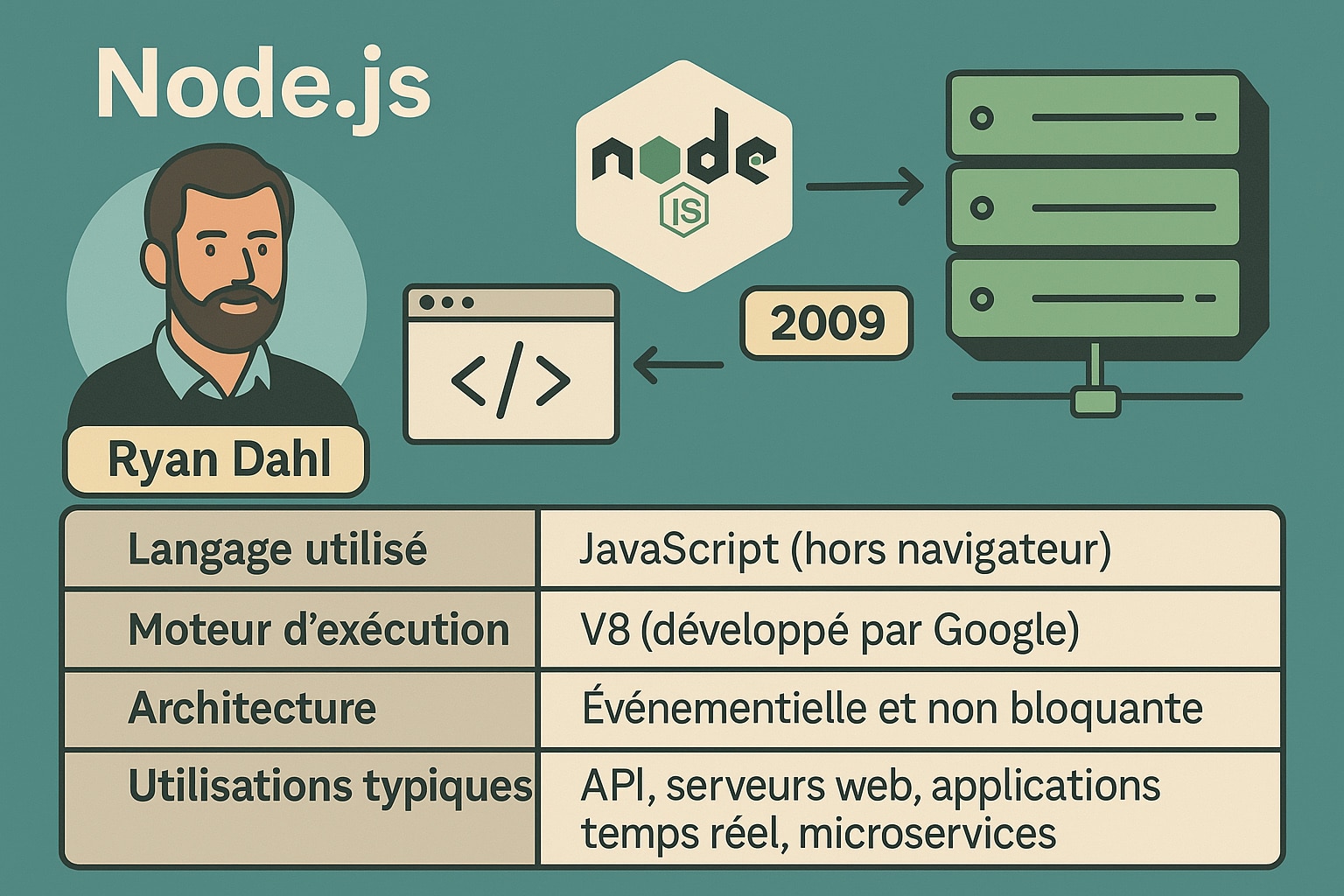
Node.js est un environnement d’exécution JavaScript open-source, multiplateforme, qui permet d’exécuter du code JavaScript en dehors du navigateur, notamment côté serveur. Sa création en 2009 par Ryan Dahl, un ingénieur logiciel américain, a marqué un tournant dans l’histoire du développement web. L’objectif initial de Dahl était clair : proposer une solution efficace et légère pour gérer des milliers de connexions simultanées, sans les blocages fréquents observés avec les technologies serveur classiques comme Apache ou PHP. Pour comprendre l’émergence de Node.js, il faut se replacer dans le contexte technologique du début des années 2000. À cette époque, les applications web reposaient sur des architectures dites « bloquantes », où chaque requête effectuée au serveur était traitée séquentiellement. Si une opération prenait du temps (comme lire un fichier ou interroger une base de données), l’ensemble du processus était ralenti, provoquant un effet de goulot d’étranglement. Ce modèle ne convenait plus à l’évolution rapide du web, notamment avec l’apparition d’applications nécessitant une réactivité en temps réel.
À l’époque, JavaScript était cantonné au navigateur. Il servait principalement à rendre les interfaces web interactives en manipulant le DOM, c’est-à-dire la structure des éléments HTML. Bien que puissant et largement répandu grâce à son universalité, JavaScript était perçu comme un langage client, incapable de rivaliser avec des langages serveur comme PHP, Ruby ou Java.
C’est ici que Ryan Dahl a eu une intuition fondatrice : utiliser JavaScript pour exécuter du code côté serveur, en dehors du navigateur. Pour cela, il s’appuie sur le moteur V8 développé par Google pour son navigateur Chrome. Ce moteur, écrit en C++, est conçu pour compiler JavaScript en code machine natif à la volée (grâce à la technique du just-in-time compilation), ce qui le rend extrêmement rapide. V8 offrait ainsi une base idéale pour faire tourner JavaScript de façon indépendante, avec une performance suffisante pour envisager des cas d’usage complexes côté serveur.
En combinant ce moteur avec une approche de programmation événementielle et non bloquante, Node.js a été conçu pour répondre aux besoins des applications web modernes. Contrairement aux modèles synchrones, l’architecture de Node.js repose sur une boucle d’événements (event loop) qui permet de traiter plusieurs requêtes sans attendre que les précédentes soient terminées. C’est cette capacité à gérer des flux simultanés avec une grande légèreté qui fera de Node.js une technologie de choix pour les applications en temps réel.
Les débuts d’une révolution silencieuse
Le premier prototype de Node.js est dévoilé lors de la conférence JSConf Europe 2009 à Berlin. Ce jour-là, Ryan Dahl présente un petit serveur web écrit en quelques lignes de code JavaScript capable de gérer des milliers de requêtes simultanées sans fléchir. L’impact est immédiat : les développeurs comprennent que JavaScript peut désormais être utilisé pour créer des applications web de bout en bout (du front-end au back-end) avec un seul et même langage. Le succès de Node.js est d’autant plus rapide qu’il répond à un besoin précis, dans un contexte où les applications temps réel (comme les chats, les jeux en ligne, les systèmes de messagerie ou de monitoring) deviennent de plus en plus populaires. Avec Node.js, il devient possible de développer ces services de manière simple, rapide et performante, tout en capitalisant sur l’écosystème JavaScript déjà bien établi côté client.
Très vite, de grandes entreprises s’y intéressent. En 2011, LinkedIn décide de réécrire une partie de son architecture mobile en Node.js, ce qui lui permet de diviser par dix le nombre de serveurs nécessaires. La même année, Netflix, confronté à une croissance exponentielle de ses utilisateurs, adopte également Node.js pour sa plateforme de diffusion. D’autres géants du web comme PayPal, eBay ou Uber suivront le mouvement, convaincus par les promesses de performance et de simplicité offertes par cet environnement.
Un écosystème riche et une communauté très active
Depuis ses débuts, Node.js a connu une évolution rapide. Il a bénéficié d’une forte adoption par la communauté open-source, ce qui a favorisé l’émergence d’un écosystème très dynamique. En parallèle de Node.js, l’outil npm (Node Package Manager) est développé pour gérer les dépendances et les bibliothèques. Aujourd’hui, npm est devenu le plus grand gestionnaire de paquets au monde, toutes technologies confondues, avec des millions de modules disponibles pour étendre les fonctionnalités de Node.js. Voici une synthèse des caractéristiques principales de Node.js :
| Caractéristique | Description |
|---|---|
| Langage utilisé | JavaScript (hors navigateur) |
| Moteur d’exécution | V8 (développé par Google) |
| Architecture | Événementielle et non bloquante |
| Utilisations typiques | API, serveurs web, applications temps réel, microservices |
Node.js a également donné naissance à toute une série de frameworks et de bibliothèques devenues incontournables : Express.js pour la création de serveurs web, Socket.io pour les connexions en temps réel, ou encore NestJS pour structurer des projets back-end à grande échelle. Ces outils viennent enrichir les possibilités offertes par Node.js et facilitent son adoption dans des projets de toute taille.
Le fonctionnement de Node.js expliqué
Le fonctionnement interne de Node.js est ce qui fait toute sa singularité et son efficacité dans la gestion d’applications web modernes. Contrairement à des environnements d’exécution classiques tels que PHP, Python ou Ruby, qui utilisent une architecture dite « bloquante » (chaque requête est traitée séquentiellement ou à l’aide de threads multiples), Node.js adopte une approche événementielle et non bloquante. Cela signifie qu’il peut gérer des milliers de connexions simultanées en consommant peu de ressources système, sans créer de nouveaux threads à chaque requête.
Ce modèle est particulièrement adapté aux applications à forte charge concurrente, comme les serveurs d’API, les applications temps réel (chat, notifications, jeux en ligne) ou encore les services de streaming. Là où d’autres langages peuvent vite atteindre des limites de performance en multipliant les threads, Node.js mise sur une boucle d’événements légère et une programmation asynchrone qui réduit considérablement les temps d’attente.
Le modèle asynchrone et la boucle d’événements avec Node.js
Au cœur de cette architecture se trouve l’event loop : une boucle d’événements qui intercepte, planifie et exécute les opérations du programme de manière non séquentielle. Lorsqu’une tâche prend du temps (accès à un fichier, appel à une base de données, requête HTTP), elle n’interrompt pas le reste du code. Elle est simplement mise en attente pendant que Node.js continue d’exécuter d’autres instructions.
Cette manière de fonctionner repose sur les callbacks, les promises ou encore les async/await, des outils qui permettent de définir le comportement à suivre une fois qu’une tâche asynchrone est terminée.
Voici un schéma simplifié de ce processus :
- L’utilisateur effectue une requête (par exemple, un clic sur un bouton qui appelle une API).
- Node.js reçoit cette requête et la place dans une file d’attente.
- La boucle d’événements (event loop) analyse cette file et exécute immédiatement les tâches simples et rapides.
- Les opérations longues (comme une requête SQL ou une lecture de fichier) sont déléguées à un thread pool interne via la bibliothèque libuv.
- Une fois terminées, ces opérations déclenchent un événement, réinjecté dans la boucle d’événements pour être traité au bon moment.
Ce modèle d’exécution, inspiré des systèmes comme Nginx ou du langage Go, permet à Node.js de fonctionner avec un seul thread principal tout en gérant efficacement des centaines, voire des milliers, de connexions actives. Cette architecture est idéale pour les applications orientées I/O (entrée/sortie), où la majorité des tâches consistent à attendre une réponse externe.
Voici un schéma logique des composants en interaction dans l’environnement Node.js :
- Event loop : boucle principale qui gère le cycle de vie des événements.
- Callback queue : file d’attente des fonctions à exécuter.
- Libuv : bibliothèque C qui permet l’exécution des tâches en arrière-plan.
- Thread pool : ensemble de threads secondaires pour traiter les opérations longues.
- V8 : moteur JavaScript qui exécute le code utilisateur.
Les modules et le système de paquets (npm)
Un autre pilier fondamental du fonctionnement de Node.js est son système modulaire. Plutôt que de créer une grosse application monolithique, Node.js incite à segmenter le code en modules réutilisables, chacun stocké dans un fichier distinct. Cela favorise une meilleure organisation, une meilleure maintenabilité, et une grande évolutivité des projets.
Node.js est livré avec plusieurs modules natifs prêts à l’emploi, comme :
http: pour créer des serveurs web.fs: pour manipuler le système de fichiers.path: pour gérer les chemins de fichiers.events: pour créer et gérer des événements personnalisés.
Mais la véritable puissance de Node.js réside dans son écosystème de paquets grâce à npm (Node Package Manager). Lancé en parallèle de Node.js, npm est devenu aujourd’hui le plus vaste registre de bibliothèques JavaScript au monde, avec plus de deux millions de paquets disponibles. Il permet d’installer facilement des modules créés par d’autres développeurs pour étendre les fonctionnalités des applications. Voici quelques exemples de bibliothèques populaires disponibles sur npm :
- Express : framework rapide et minimaliste pour créer des serveurs web et des APIs REST ;
- Socket.io : outil pour créer des applications temps réel (chat, notifications, etc.) ;
- Axios : client HTTP très utilisé pour effectuer des appels API, même côté serveur ;
- Mongoose : bibliothèque pour gérer les interactions avec une base de données MongoDB en définissant des schémas de données.
Grâce à npm, les développeurs peuvent construire des applications complexes en assemblant des modules performants, testés et mis à jour par une communauté très active.
Un exemple de code simple avec Node.js
Voici un exemple minimaliste de serveur HTTP écrit en Node.js :
const http = require('http');
const server = http.createServer((req, res) => {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Bonjour depuis Node.js !');
});
server.listen(3000, () => {
console.log('Serveur en écoute sur le port 3000');
});
Ce code fait appel au module http de Node.js pour créer un serveur. À chaque requête, celui-ci renvoie un message en texte brut. En seulement quelques lignes, ce serveur est capable de répondre à des connexions entrantes, sans besoin de serveur externe comme Apache ou Nginx. Ce modèle est extensible : vous pouvez y ajouter des routes, des middlewares ou des connexions à des bases de données selon les besoins.
Quel est l’impact de Node.js sur le SEO ? Performances, indexation et bonnes pratiques
Node.js s’est imposé ces dernières années comme une solution incontournable pour le développement d’applications web modernes. Plébiscité pour sa rapidité d’exécution, sa capacité à gérer un grand nombre de connexions simultanées et son environnement JavaScript unifié, il est largement utilisé dans des projets d’envergure. Mais lorsqu’on aborde la question du SEO, c’est-à-dire l’optimisation du référencement sur les moteurs de recherche, la technologie révèle aussi certaines limites. Si ses performances côté serveur sont indéniables, son impact sur la visibilité naturelle d’un site mérite une analyse plus nuancée.
Dans cet article, nous vous proposons un regard critique sur l’usage de Node.js dans un contexte SEO. Quels sont ses avantages réels ? Quels sont les pièges à éviter ? Et surtout, dans quels cas est-il judicieux — ou non — de le choisir pour un site qui vise un bon positionnement dans les résultats de Google ?
Les défis SEO posés par les applications Node.js
Le principal problème rencontré avec Node.js en matière de SEO ne provient pas directement de l’environnement lui-même, mais de l’architecture applicative qu’il favorise : les applications JavaScript dynamiques, souvent de type SPA (Single Page Application). Dans ces architectures, le contenu de la page est généré côté client, c’est-à-dire après que le navigateur a chargé une coquille HTML vide ou très légère. Résultat : lorsque les robots d’indexation (comme Googlebot) parcourent le site, ils ne trouvent pas immédiatement de contenu exploitable.
Or, bien que Google ait amélioré ses capacités de rendu JavaScript ces dernières années, l’indexation de contenu dynamique reste imparfaite et sujette à délais. Pour des pages critiques (produits, services, articles), ce décalage peut sérieusement nuire au référencement naturel.
| Limitation | Conséquence SEO |
|---|---|
| Contenu rendu côté client uniquement | Risque de non-indexation ou d’indexation partielle |
| Temps de chargement initial élevé | Impact négatif sur les Core Web Vitals |
| Absence de balises méta initiales (title, description) | Affichage incorrect dans les résultats de recherche |
| Mauvaise gestion des routes dynamiques | Erreurs 404 ou contenu dupliqué |
Ces obstacles ne sont pas anecdotiques. Dans des projets SEO à forte exigence de visibilité (e-commerce, médias, sites locaux…), un mauvais paramétrage d’une application Node.js peut anéantir des mois d’efforts en stratégie de contenu ou netlinking.
Des performances techniques intéressantes mais insuffisantes pour le SEO
Node.js est souvent vanté pour ses performances en termes de vitesse de traitement et de gestion des connexions simultanées. C’est indéniable : son architecture non bloquante basée sur la boucle d’événements (event loop) permet de réduire le temps au premier octet (TTFB) et de fluidifier l’expérience utilisateur. Cependant, les performances serveur ne suffisent pas à garantir un bon référencement. Google évalue également :
- La structure sémantique du HTML (titres, paragraphes, balises ALT…) ;
- La présence immédiate de contenu pertinent à l’affichage initial ;
- La cohérence des URLs, la hiérarchie du site et la navigation interne ;
- La lisibilité du code pour ses robots (sans avoir à « attendre » le rendu JavaScript).
Or, dans de nombreuses applications Node.js mal configurées, ces éléments sont générés dynamiquement côté client, ce qui réduit leur efficacité en SEO. À moins de mettre en place des stratégies spécifiques (comme le rendu côté serveur), Node.js n’est pas « SEO-friendly » par défaut.
Les bonnes pratiques pour rendre Node.js compatible avec le SEO
Heureusement, il est tout à fait possible d’utiliser Node.js tout en respectant les exigences du SEO, à condition d’appliquer certaines bonnes pratiques techniques dès le début du projet.
1. Mettre en place le rendu côté serveur (SSR)
Le Server Side Rendering permet de générer une version complète de la page HTML avant qu’elle ne soit envoyée au navigateur. Cela garantit que les robots de Google voient immédiatement le contenu, les balises méta et la structure HTML.
Des frameworks comme Next.js (pour React) ou Nuxt.js (pour Vue) facilitent l’implémentation du SSR tout en restant dans l’écosystème Node.js. Attention toutefois : le SSR peut complexifier l’infrastructure et augmenter la charge serveur si mal optimisé.
2. Utiliser le prerendering pour les pages critiques
Une autre approche consiste à générer une version statique des pages importantes (produits, landing pages, articles) via des outils comme Prerender.io ou Rendertron. Ces solutions interceptent les requêtes des robots d’indexation et leur servent une version HTML précalculée, tout en maintenant une navigation JavaScript pour les utilisateurs réels.
3. Bien configurer la gestion des routes
Node.js permet souvent de créer des routes dynamiques via Express ou d’autres frameworks. Mais il est impératif de s’assurer que chaque URL renvoie le bon contenu, un code HTTP 200 valide, et une structure HTML cohérente. L’usage de fichiers sitemap.xml et robots.txt est également indispensable.
4. Travailler les performances front-end
Outre les performances côté serveur, les Core Web Vitals évaluent aussi l’expérience utilisateur au chargement : vitesse d’affichage, stabilité visuelle, temps d’interaction. Il convient donc d’optimiser les bundles JavaScript, de réduire les appels API inutiles et d’utiliser un CDN pour les assets statiques.

0 commentaires