Lorsqu’un site web commence à grandir, une partie importante du travail ne se voit pas à l’écran. Pendant que les utilisateurs naviguent, commandent, remplissent des formulaires ou consultent leur espace client, le serveur doit parfois gérer des opérations plus discrètes : recalculer des statistiques, synchroniser des données, nettoyer une base, générer des exports, mettre à jour des statuts ou préparer des notifications. Ces opérations ne nécessitent pas toujours une intervention humaine immédiate. Elles gagnent même souvent à être exécutées en arrière-plan, à un rythme maîtrisé, sans ralentir l’expérience utilisateur. C’est précisément le rôle d’un traitement batch en PHP. Contrairement à un script exécuté directement lors d’une requête web, un batch est pensé pour traiter un volume de données, souvent par lots, de manière autonome. Il peut être lancé manuellement, déclenché par une tâche planifiée ou intégré dans une logique d’automatisation plus large. Dans un précédent sujet consacré à l’envoi d’emails automatiques avec CRON et PHP, le principe était déjà présent : stocker des actions à réaliser, puis laisser un script PHP les traiter au bon moment. Ici, l’objectif est plus large. Il ne s’agit pas seulement d’envoyer des emails, mais de comprendre comment PHP peut devenir un véritable outil d’exécution de tâches serveur.
Le rôle des traitements batch en PHP expliqué
Un traitement batch désigne une opération exécutée sans interaction directe avec l’utilisateur, généralement sur un ensemble de données. Le script ne répond pas à une demande immédiate depuis une page web. Il travaille en arrière-plan, selon une logique métier définie à l’avance. Cela peut concerner quelques dizaines d’enregistrements comme plusieurs centaines de milliers, selon la taille du projet. Cette capacité à traiter des volumes importants sans dépendre d’une requête utilisateur est précisément ce qui rend le batch indispensable dans une architecture moderne. Dans une la création d’une application web classique, chaque requête HTTP est contrainte par plusieurs limites : temps d’exécution, mémoire disponible, latence acceptable côté utilisateur. Dès qu’un traitement devient trop long ou trop coûteux, il dégrade l’expérience globale. Le batch permet de contourner ces contraintes en déplaçant les opérations lourdes hors du cycle de réponse. On parle alors de traitement asynchrone ou différé. L’utilisateur déclenche une action (création, mise à jour, commande), mais le traitement complet est exécuté plus tard, dans un contexte maîtrisé. En PHP, ce type de traitement est souvent exécuté en ligne de commande grâce à PHP CLI. Cette approche permet de sortir du cycle classique navigateur → serveur → réponse HTML. Le script n’a pas besoin d’afficher une page. Il charge ses dépendances (autoload, configuration, services), initialise ses connexions (base de données, API externes), traite les éléments concernés, écrit des logs, puis s’arrête proprement. Cette exécution en CLI (voir aussi notre sujet sur WP CLI) offre plusieurs avantages techniques :
- absence de timeout HTTP imposé par le serveur web ;
- contrôle plus fin de la mémoire avec
memory_limitajustable ; - possibilité de passer des arguments en ligne de commande ;
- meilleure intégration avec les outils système (CRON, logs, monitoring) ;
- exécution silencieuse sans dépendance à une interface utilisateur.
Un script batch PHP est donc conçu comme un programme autonome. Il peut être structuré autour de services métiers, utiliser un conteneur de dépendances (dans un framework comme Symfony ou Laravel), et s’appuyer sur des composants robustes pour la gestion des erreurs, du logging ou des accès aux données. Contrairement à un contrôleur web, il doit être capable de fonctionner même en cas de données partielles, d’erreurs externes ou de volumes importants. Sur le plan technique, un batch repose souvent sur un cycle de traitement bien défini :
- récupération d’un ensemble de données à traiter (requête SQL, file d’attente, API) ;
- itération sur les éléments avec traitement unitaire ;
- gestion des exceptions sans interrompre l’ensemble du processus ;
- mise à jour d’un statut pour éviter les doublons ;
- journalisation des résultats pour audit et supervision.
La gestion du volume est un point central. Traiter 10 éléments ou 100 000 ne se fait pas de la même manière. Pour éviter les surcharges, il est recommandé d’utiliser des techniques comme :
- le traitement par lots (batch processing) avec des limites SQL (
LIMIT) ; - les curseurs ou itérations paresseuses (lazy loading) pour réduire la mémoire ;
- la pagination basée sur un identifiant plutôt qu’un offset (plus performant) ;
- la segmentation des traitements par priorité ou type ;
- l’utilisation de files d’attente (queues) pour lisser la charge.
Les usages sont nombreux. Un site e-commerce peut utiliser un batch pour recalculer les stocks, générer des factures PDF, relancer des commandes en attente ou synchroniser un catalogue fournisseur. Une plateforme SaaS peut s’en servir pour vérifier les abonnements expirés, produire des statistiques quotidiennes ou archiver certaines données. Un site éditorial peut automatiser la publication différée, l’indexation interne ou la génération de rapports SEO.
| Type de traitement batch | Exemple d’usage | Intérêt principal |
|---|---|---|
| Nettoyage de données | Suppression de sessions expirées | Alléger la base de données |
| Synchronisation | Mise à jour d’un catalogue produit | Maintenir les informations à jour |
| Calcul différé | Génération de statistiques | Éviter de ralentir les pages web |
| Export | Création d’un fichier CSV quotidien | Automatiser les rapports |
| Notification | Préparation d’emails ou d’alertes | Centraliser les communications |
Sur des projets plus avancés, les traitements batch peuvent également interagir avec des systèmes distribués. PHP peut par exemple consommer une file de messages (RabbitMQ, Kafka), déclencher des appels API vers des microservices ou répartir les traitements sur plusieurs workers. Dans ce cas, le batch devient un composant d’une architecture plus large orientée événements. Le lien avec l’automatisation des emails est donc naturel. L’envoi automatique d’emails avec CRON et PHP déjà évoqué est un cas particulier de traitement batch. Le script récupère une file d’attente, traite les messages en attente, met à jour les statuts et conserve une trace de l’exécution. Ce mécanisme repose exactement sur les mêmes principes techniques : découpler la production de la consommation, limiter le débit, gérer les erreurs et garantir l’idempotence (éviter d’envoyer deux fois le même message). Plus largement, un bon traitement batch doit être conçu comme un système fiable et reproductible. Cela implique :
- une logique idempotente (un même traitement peut être rejoué sans effet de bord) ;
- une gestion des retries en cas d’échec temporaire ;
- un système de logs détaillé et exploitable ;
- une supervision pour détecter les anomalies ;
- une capacité à reprendre là où le traitement s’est arrêté.
Ainsi, les traitements batch en PHP ne sont pas simplement des scripts exécutés en différé. Ils constituent une brique essentielle de l’architecture applicative. Bien conçus, ils permettent de découpler les responsabilités, d’améliorer les performances globales et de rendre le système plus résilient face aux volumes et aux imprévus.
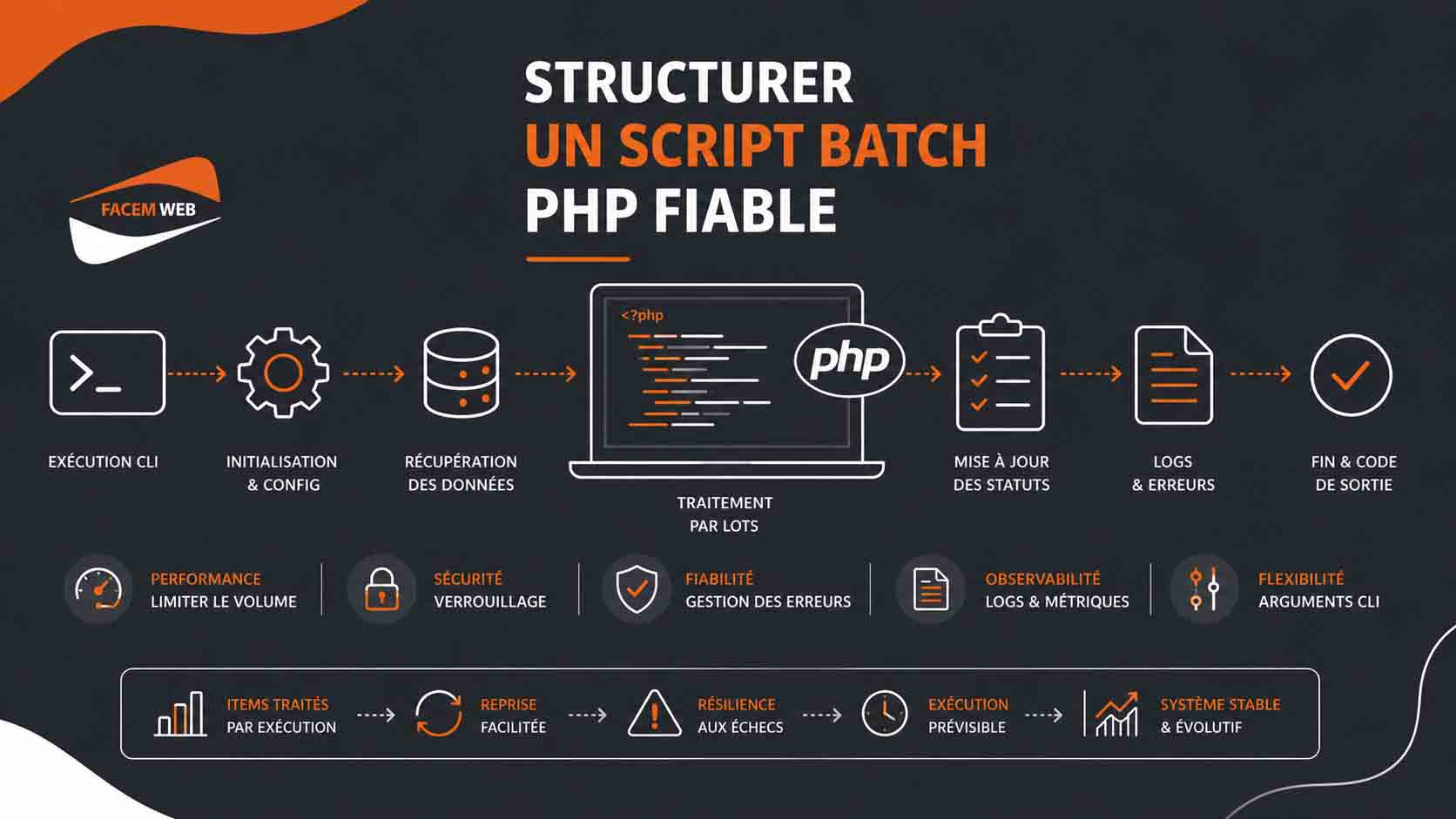
Structurer un script batch PHP fiable
Un bon script batch PHP doit être pensé comme un outil autonome, capable de fonctionner sans navigateur, sans session utilisateur et sans dépendance implicite à l’environnement HTTP. Cela suppose une structure claire, mais aussi une réflexion globale sur la robustesse, la maintenabilité et la capacité à traiter des volumes importants dans la durée.Contrairement à un contrôleur web, un batch n’a pas de retour immédiat à fournir à un utilisateur. Il peut donc être plus strict, plus verbeux dans ses logs et plus exigeant dans sa gestion des erreurs. Il doit également être prévisible : un même traitement exécuté deux fois ne doit pas produire d’effets incohérents. On parle ici d’idempotence, une propriété importante dès que l’on manipule des données sensibles ou critiques. La première étape consiste à séparer la logique métier du déclenchement. Le fichier exécuté en ligne de commande doit idéalement se contenter d’initialiser l’environnement, d’appeler un service ou une classe dédiée, puis de retourner un code de sortie compréhensible. Cette organisation facilite les tests unitaires, permet d’isoler les responsabilités et rend le code plus évolutif.
<?php
require __DIR__ . '/bootstrap.php';
$batch = new App\Batch\ProductSyncBatch();
try {
$result = $batch->run(limit: 200);
echo sprintf(
"[%s] Traitement terminé : %d éléments traités, %d erreurs\n",
date('Y-m-d H:i:s'),
$result->processed,
$result->errors
);
exit(0);
} catch (Throwable $e) {
error_log($e->getMessage());
exit(1);
}Dans cet exemple, le script reste lisible et découplé. Toute la logique métier est encapsulée dans une classe dédiée. Le point d’entrée (le fichier CLI) agit comme un orchestrateur minimal. Cette approche permet également d’injecter des dépendances (connexion base de données, services externes, configuration) via un conteneur ou un bootstrap centralisé. Un autre aspect souvent négligé concerne la configuration de l’environnement d’exécution. Un batch PHP peut nécessiter des ajustements spécifiques :
- augmenter la limite mémoire (
memory_limit) pour gérer de gros volumes ; - désactiver le timeout (
set_time_limit(0)) si nécessaire ; - configurer le fuseau horaire pour garantir la cohérence des dates ;
- charger des variables d’environnement (via
.envou système).
Un autre point important consiste à limiter le nombre d’éléments traités à chaque exécution. Vouloir tout traiter d’un seul coup peut entraîner des temps d’exécution trop longs, une consommation mémoire élevée ou des blocages en base de données. Le traitement par lots permet de mieux contrôler la charge et de rendre le système plus résilient.
SELECT id, reference, updated_at
FROM products
WHERE sync_status = 'pending'
ORDER BY updated_at ASC
LIMIT 200;Cette requête récupère uniquement une partie des éléments en attente. Le script peut ensuite les traiter un par un, mettre à jour leur statut, puis laisser une prochaine exécution poursuivre le travail. Pour aller plus loin, il est recommandé d’éviter les offsets sur de gros volumes et de préférer une pagination basée sur un identifiant (par exemple WHERE id > last_id) afin d’améliorer les performances. La gestion de la mémoire est également un point technique important. Lorsqu’un batch traite un grand nombre d’objets, il peut rapidement saturer la mémoire disponible. Pour limiter cet effet, plusieurs stratégies existent :
- libérer explicitement certaines variables avec
unset(); - éviter de stocker tous les résultats en mémoire ;
- utiliser des générateurs (
yield) pour itérer de manière progressive ; - fermer et rouvrir certaines connexions longues si nécessaire.
Il faut également prévoir une gestion sérieuse des erreurs. Un traitement batch ne doit pas s’arrêter définitivement au premier élément invalide. Si une ligne pose problème, elle peut être marquée en erreur, documentée dans les logs, puis le script peut continuer avec les éléments suivants. Cette logique évite qu’un seul enregistrement corrompu bloque toute une file de traitement. Dans une approche avancée, on distingue souvent :
- les erreurs bloquantes (connexion base indisponible, configuration invalide) ;
- les erreurs métier (données incohérentes, champ manquant) ;
- les erreurs temporaires (API externe indisponible).
Chaque type d’erreur peut être traité différemment : arrêt immédiat, mise en attente, tentative de retry ou simple journalisation.
| Bonne pratique | Pourquoi l’appliquer |
|---|---|
| Limiter le volume par exécution | Réduire la charge serveur et faciliter la reprise |
| Utiliser des statuts | Suivre les éléments en attente, traités ou en erreur |
| Écrire des logs clairs | Comprendre rapidement ce qui s’est passé |
| Prévoir un verrouillage | Éviter deux exécutions simultanées du même batch |
| Retourner des codes de sortie | Faciliter la supervision technique |
Les logs jouent un rôle central. Un batch sans logs exploitables devient rapidement difficile à maintenir. Il est conseillé d’utiliser une bibliothèque dédiée (comme Monolog) afin de structurer les messages (niveau info, warning, error), horodater précisément les événements et éventuellement envoyer des alertes en cas de problème critique. Le verrouillage est particulièrement utile. Si un batch dure dix minutes alors qu’il est planifié toutes les cinq minutes, deux instances peuvent se chevaucher. Selon le traitement, cela peut générer des doublons, des conflits de mise à jour ou des incohérences. Une solution simple consiste à utiliser un fichier de verrouillage ou un verrou en base de données.
<?php
$lockFile = __DIR__ . '/batch.lock';
if (file_exists($lockFile)) {
echo "Un traitement est déjà en cours\n";
exit(0);
}
file_put_contents($lockFile, getmypid());
try {
// Exécution du traitement batch
} finally {
unlink($lockFile);
}Dans une architecture plus avancée, ce verrouillage peut être géré via :
- une table dédiée en base de données avec timestamp ;
- un système de cache partagé (Redis, Memcached) ;
- un composant de lock fourni par un framework ;
- un orchestrateur externe qui garantit l’unicité d’exécution.
Enfin, un script batch fiable doit être testable et observable. Il est recommandé de prévoir :
- un mode simulation (dry-run) pour tester sans impacter les données ;
- des arguments CLI (
--limit,--offset,--force) pour ajuster le comportement ; - des métriques simples (temps d’exécution, nombre d’éléments traités) ;
- une documentation claire pour faciliter la reprise par un autre développeur.
Structurer correctement un batch PHP, ce n’est donc pas seulement écrire un script fonctionnel. C’est concevoir un outil capable de s’intégrer dans un environnement de production, de gérer les imprévus et de évoluer sans remettre en cause l’ensemble du système.
Industrialiser les traitements batch avec PHP
Automatiser un batch ne consiste pas seulement à écrire un script et à le lancer avec CRON. Il faut penser au cycle de vie complet du traitement : déclenchement, exécution, suivi, erreurs, reprise, sécurité et maintenance. C’est ce qui fait la différence entre un script pratique et un véritable composant de production capable de fonctionner de manière fiable dans le temps. Dans une logique industrielle, un traitement batch doit être conçu comme un processus autonome, observable et maîtrisé. Il ne doit pas dépendre d’un contexte fragile ou implicite. Cela implique notamment une configuration explicite, une gestion rigoureuse des dépendances, ainsi qu’un comportement prévisible quel que soit l’environnement (développement, staging, production). CRON reste l’un des moyens les plus simples pour planifier un script PHP. Une ligne suffit pour exécuter un batch toutes les heures, chaque nuit ou à une fréquence plus fine.
0 * * * * /usr/bin/php /home/site/scripts/sync-products.php >> /home/site/logs/sync-products.log 2>&1Cette commande exécute le script toutes les heures et redirige la sortie standard ainsi que les erreurs vers un fichier de log. C’est une base efficace, mais elle doit être accompagnée d’une vraie stratégie de supervision. En production, un batch peut échouer pour de nombreuses raisons : modification des identifiants d’accès, indisponibilité d’un service externe, changement de configuration PHP, problème de permissions, saturation disque ou timeout sur une ressource distante. Sans mécanisme de surveillance, ces incidents peuvent rester invisibles pendant plusieurs jours. Pour aller plus loin, il est recommandé d’intégrer des outils de monitoring. Cela peut passer par des solutions simples comme des alertes email en cas d’échec, ou des outils plus avancés capables de suivre les métriques d’exécution (temps, volume traité, taux d’erreur). Certains environnements utilisent également des systèmes comme supervisord ou systemd pour garantir qu’un processus critique reste actif ou redémarre automatiquement en cas de panne. Pour professionnaliser l’approche, il est conseillé de conserver des traces structurées. Une table de suivi peut enregistrer chaque exécution avec sa date de début, sa date de fin, son statut, le nombre d’éléments traités et le détail des erreurs. Cette méthode permet de suivre l’historique depuis une interface d’administration ou un tableau de bord interne, mais aussi d’analyser les performances dans le temps.
| Champ | Rôle |
|---|---|
| id | Identifiant de l’exécution |
| batch_name | Nom du traitement lancé |
| started_at | Date de début |
| ended_at | Date de fin |
| status | Succès, erreur ou partiel |
| processed_items | Nombre d’éléments traités |
| error_message | Message d’erreur principal |
Au-delà du simple stockage, ces données permettent de mettre en place des indicateurs : Durée moyenne d’exécution, nombre d’éléments traités par heure, taux d’échec, fréquence des relances. Ces métriques sont particulièrement utiles pour anticiper les problèmes de montée en charge ou détecter des anomalies (augmentation soudaine des erreurs, ralentissement du traitement, accumulation d’éléments en attente). Cette logique est particulièrement pertinente lorsque plusieurs batchs coexistent : synchronisation de produits, exports comptables, nettoyage de fichiers temporaires, calcul de statistiques, relances commerciales ou préparation d’emails. Chaque traitement peut alors être suivi de manière indépendante, avec ses propres règles, ses priorités et ses contraintes. Dans des architectures plus avancées, on peut aller au-delà de CRON en utilisant des systèmes de file d’attente (queues). PHP peut alors consommer des jobs depuis Redis, RabbitMQ ou une base dédiée. Cette approche permet de répartir la charge sur plusieurs workers, d’augmenter la scalabilité et de gérer plus finement les priorités. Un batch devient alors une série de tâches distribuées plutôt qu’un script monolithique exécuté périodiquement. La gestion des erreurs doit également être pensée de manière robuste. Il est recommandé de distinguer :
- les erreurs temporaires (API indisponible, timeout réseau) qui peuvent être rejouées ;
- les erreurs définitives (données invalides) qui doivent être isolées ;
- les erreurs critiques (problème système) qui doivent interrompre le traitement.
Un bon batch met en place une stratégie de retry avec un nombre maximal de tentatives, souvent stocké en base. Cela évite les boucles infinies tout en permettant de récupérer automatiquement certaines erreurs transitoires. La sécurité ne doit pas être négligée. Un script batch manipule parfois des données sensibles : informations clients, commandes, factures, adresses email ou fichiers privés. Il faut donc éviter de rendre ces scripts accessibles depuis le web. Ils doivent être placés hors du répertoire public lorsque c’est possible. Les identifiants de connexion doivent être stockés dans un fichier de configuration protégé ou dans des variables d’environnement, jamais directement exposés dans le code versionné. Il est également recommandé de contrôler les accès système. Le script doit être exécuté avec un utilisateur disposant uniquement des permissions nécessaires. Cela limite les risques en cas de faille ou de mauvaise manipulation. Dans certains contextes, l’utilisation de conteneurs (Docker) permet aussi d’isoler les traitements et de garantir un environnement stable. Enfin, le batch doit rester prévisible. Un traitement automatisé ne doit pas modifier des milliers de lignes sans garde-fou. Il est préférable de prévoir des limites, des statuts, des logs et parfois un mode simulation. Ce mode permet d’exécuter le script sans appliquer les modifications, simplement pour vérifier ce qui serait traité.
php sync-products.php --dry-run --limit=100Ce type d’option est particulièrement utile lors des phases de test ou après une évolution du code. Il permet de valider la logique sans impacter les données réelles. Dans une logique encore plus avancée, on peut intégrer des flags supplémentaires : Environnement cible, niveau de verbosité, type de traitement ou segmentation des données. Avec cette approche, le développeur PHP garde le contrôle. Il peut tester, observer, corriger et ajuster avant de laisser le traitement s’exécuter automatiquement en production. L’industrialisation des batchs ne repose pas uniquement sur l’automatisation, mais sur la capacité à rendre chaque exécution fiable, traçable et reproductible, même dans des contextes complexes ou à forte volumétrie.

0 commentaires