Un système capable de répondre à vos questions avec la précision d’une base de données spécialisée, tout en conservant la fluidité d’un modèle de langage avancé, n’est plus une projection théorique. Un assistant qui ne se contente pas de “deviner” une réponse, mais qui va activement chercher l’information pertinente avant de vous répondre : C’est précisément ce que permet l’architecture RAG, pour Retrieval-Augmented Generation. Dans un contexte où les modèles d’intelligence artificielle générative sont de plus en plus utilisés en entreprise, la question de la fiabilité, de l’actualisation des connaissances et du contrôle des données devient centrale. L’architecture RAG s’impose alors comme une réponse technique élégante et puissante à ces enjeux. Elle permet de combiner le meilleur des deux mondes : La recherche d’information (retrieval) et la génération de texte (generation). Dans cet article, voyons ensemble ce qu’est une architecture RAG, ses principes fondamentaux, son fonctionnement détaillé ainsi que ses cas d’usage concrets dans un projet numérique. L’objectif est de vous donner une vision claire, structurée et directement exploitable de cette approche devenue incontournable dans les systèmes d’IA modernes.
- La définition d’une architecture RAG et ses fondements
- Le fonctionnement d’une architecture RAG étape par étape
- La réception de la requête utilisateur
- La préparation et le nettoyage de la requête
- La transformation en embeddings
- L’indexation préalable des documents
- Le découpage des documents en fragments
- La recherche d’information ou retrieval
- Le filtrage des résultats récupérés
- Le classement et le reranking des passages
- La construction du contexte
- La génération de la réponse par le modèle de langage
- L’ajout de références et de sources
- La restitution à l’utilisateur
- La gestion des cas sans réponse
- L’amélioration continue du pipeline RAG
- La valeur du pipeline RAG dans un contexte professionnel
- Les avantages et cas d’usage d’une architecture RAG (Exemples)
La définition d’une architecture RAG et ses fondements
Une architecture RAG (Retrieval-Augmented Generation) désigne un modèle hybride combinant un système de recherche d’information et un modèle génératif. Elle se distingue des approches classiques en intégrant une capacité à interroger des sources externes en temps réel afin d’enrichir les réponses produites.
| Composante | Rôle et fonctionnement |
|---|---|
| Système de retrieval | Permet de rechercher et récupérer les informations les plus pertinentes depuis une base documentaire, souvent via des embeddings stockés dans une base vectorielle. Cette étape repose sur des algorithmes de similarité capables d’identifier rapidement les contenus les plus proches de la requête. |
| Modèle génératif (LLM) | Utilise les informations récupérées comme contexte pour générer une réponse cohérente, précise et adaptée à la requête utilisateur, tout en conservant une fluidité naturelle dans la formulation. |
| Principe fondamental | Ne pas tout mémoriser, mais savoir où chercher afin d’améliorer la qualité, la pertinence et la fiabilité des réponses produites. |
| Différence avec un modèle classique | Un modèle traditionnel repose uniquement sur ses données d’entraînement, tandis qu’une architecture RAG interroge des sources externes en temps réel, ce qui permet d’intégrer des informations non présentes lors de l’entraînement initial. |
| Réduction des limites | Diminue les hallucinations, permet l’accès à des données actualisées et améliore la pertinence des réponses en s’appuyant sur des contenus vérifiables. |
| Personnalisation | Possibilité d’adapter les réponses à une base documentaire spécifique (documents internes, FAQ, connaissances métier), ce qui rend le système particulièrement utile en entreprise. |
| Technologie sous-jacente | Utilisation fréquente de bases vectorielles permettant de comparer les requêtes et documents via des mesures de similarité comme la distance cosinus. |
| Embeddings | Transformation des textes (documents et requêtes) en vecteurs numériques facilitant la comparaison sémantique, même lorsque les formulations diffèrent. |
| Base de connaissances | Ensemble structuré de documents internes ou externes servant de source d’information, pouvant être mis à jour indépendamment du modèle génératif. |
| Actualisation des données | Permet d’intégrer rapidement de nouvelles informations sans nécessiter de réentraînement complet du modèle, ce qui réduit les coûts et les délais. |
| Scalabilité | Capacité à gérer de grandes quantités de données et à maintenir des performances élevées grâce à l’optimisation des systèmes de recherche vectorielle. |
| Contrôle des sources | Possibilité de limiter les réponses à des corpus validés, garantissant une meilleure maîtrise de la qualité et de la fiabilité des informations utilisées. |
| Cas d’usage | Utilisé dans les chatbots, les assistants internes, les moteurs de recherche intelligents ou encore les outils d’analyse documentaire avancée. |
| Interopérabilité | Peut être intégré avec différents outils et systèmes d’information (CRM, ERP, bases documentaires), facilitant son adoption dans des environnements existants. |
En pratique, les documents sont transformés en vecteurs numériques (embeddings), ce qui permet d’identifier rapidement les contenus les plus pertinents en fonction de la requête utilisateur. Cette capacité à connecter génération et recherche d’information fait de l’architecture RAG une approche particulièrement adaptée aux environnements exigeant précision, traçabilité et mise à jour continue des connaissances.
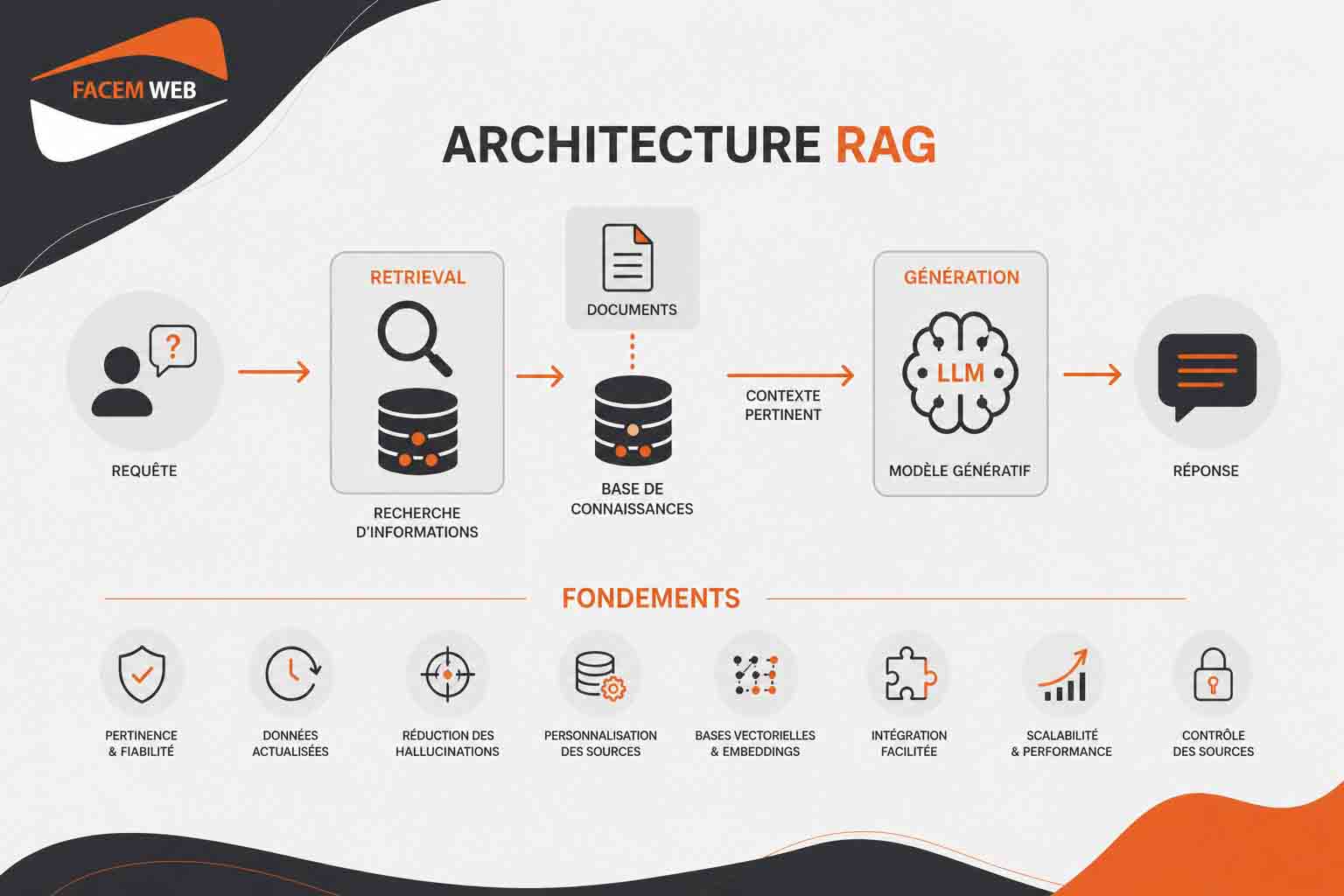
Le fonctionnement d’une architecture RAG étape par étape
Pour comprendre la puissance d’une architecture RAG, il faut la voir comme une chaîne de traitement complète. Chaque étape joue un rôle précis : Recevoir la demande, retrouver les bonnes informations, construire un contexte fiable, puis générer une réponse exploitable. Cette logique permet au modèle de langage de ne pas répondre uniquement à partir de sa mémoire interne, mais de s’appuyer sur des données sélectionnées au moment de la requête.
La réception de la requête utilisateur
Tout commence par une question, une instruction ou une demande formulée par l’utilisateur. Il peut s’agir d’une requête simple, comme “Quels sont les avantages d’un contrat SaaS ?”, ou d’une demande plus complexe, par exemple “Compare les clauses de résiliation de ces trois contrats et identifie les risques pour le client”. À ce stade, le système doit comprendre l’intention de l’utilisateur. Il peut analyser les mots-clés, le contexte conversationnel, la langue utilisée, le niveau de détail attendu et parfois même le rôle de la personne qui pose la question. Dans un environnement professionnel, cette étape peut aussi intégrer des paramètres comme les droits d’accès, le département de l’utilisateur ou le périmètre documentaire autorisé.
La préparation et le nettoyage de la requête
Avant d’interroger une base documentaire, la requête peut être reformulée ou enrichie. Cette étape permet d’améliorer la qualité de la recherche. Par exemple, une question courte ou ambiguë peut être transformée en une requête plus explicite afin de mieux cibler les documents pertinents. Le système peut également supprimer certains éléments inutiles, détecter des synonymes, identifier des entités importantes comme un nom de produit, une date, un client ou un type de document. Cette préparation évite de lancer une recherche trop vague et augmente les chances de récupérer un contexte réellement utile.
La transformation en embeddings
La requête est ensuite convertie en embedding, c’est-à-dire en représentation numérique. Un embedding permet de représenter le sens d’un texte sous forme de vecteur. Grâce à cette transformation, le système peut comparer la demande de l’utilisateur avec des documents, non pas seulement mot à mot, mais selon leur proximité sémantique. Cette étape est l’un des fondements techniques de RAG. Deux phrases formulées différemment peuvent ainsi être considérées comme proches si elles expriment la même idée. Par exemple, “comment rompre un contrat SaaS ?” et “quelles sont les conditions de résiliation d’un abonnement logiciel ?” peuvent renvoyer vers des contenus similaires, même si les termes utilisés ne sont pas identiques.
L’indexation préalable des documents
Pour qu’une architecture RAG fonctionne, les documents doivent généralement être préparés en amont. Cette préparation consiste à collecter les sources, les nettoyer, les découper en segments puis les transformer en embeddings. Ces embeddings sont ensuite stockés dans une base vectorielle. Les documents peuvent provenir de nombreuses sources : Fichiers PDF, pages web, bases de connaissances, tickets de support, contrats, comptes rendus, documentations produit, procédures internes ou contenus issus d’un CRM. Une bonne indexation est indispensable, car la qualité des réponses dépend directement de la qualité des documents disponibles et de leur structuration.
Le découpage des documents en fragments
Les documents longs ne sont généralement pas envoyés tels quels au modèle. Ils sont découpés en fragments, parfois appelés chunks. Chaque fragment contient une portion cohérente du document, par exemple un paragraphe, une section ou un groupe de phrases. Ce découpage doit être équilibré. Des fragments trop courts risquent de manquer de contexte, tandis que des fragments trop longs peuvent contenir trop d’informations inutiles. Une architecture RAG performante repose donc sur une stratégie de découpage adaptée au type de contenu traité.
La recherche d’information ou retrieval
Une fois la requête transformée en embedding, le système interroge la base vectorielle pour identifier les fragments les plus proches sur le plan sémantique. Cette recherche peut utiliser différentes mesures de similarité, comme la similarité cosinus ou la distance euclidienne. L’objectif est de retrouver les passages les plus susceptibles d’aider le modèle à répondre correctement. Dans certains cas, la recherche vectorielle est combinée avec une recherche classique par mots-clés. On parle alors de recherche hybride. Cette approche est souvent efficace lorsque les documents contiennent des références précises, des codes produits, des noms propres ou des termes métier spécifiques.
Le filtrage des résultats récupérés
Tous les résultats récupérés ne sont pas nécessairement utiles. Une étape de filtrage permet d’écarter les contenus trop éloignés, obsolètes, redondants ou non autorisés. Dans un contexte d’entreprise, le filtrage peut aussi tenir compte des droits d’accès de l’utilisateur afin d’éviter de lui fournir des informations confidentielles. Cette étape joue un rôle important dans la fiabilité du système. Elle permet de réduire le bruit documentaire et d’éviter que le modèle génératif s’appuie sur des informations faibles, contradictoires ou hors sujet.
Le classement et le reranking des passages
Après la première récupération des documents, certains systèmes appliquent une étape de reranking. Il s’agit de reclasser les passages récupérés selon leur pertinence réelle par rapport à la question posée. Le reranking permet d’affiner les résultats avant de les transmettre au modèle génératif. Il est particulièrement utile lorsque la base documentaire est volumineuse ou lorsque plusieurs documents semblent proches, mais que seuls certains répondent précisément à la demande.
La construction du contexte
Les passages les plus pertinents sont ensuite regroupés pour former un contexte. Ce contexte est ajouté à la requête initiale et transmis au modèle de langage. C’est à ce moment que l’architecture RAG se distingue clairement d’un simple chatbot : Le modèle ne répond pas seul, il répond à partir d’un ensemble d’informations sélectionnées. La construction du contexte doit être soigneusement organisée. Le système peut inclure les extraits documentaires, leurs titres, leurs sources, leurs dates de mise à jour ou encore des consignes précises indiquant au modèle comment utiliser ces informations.
La génération de la réponse par le modèle de langage
Le modèle génératif reçoit la question de l’utilisateur ainsi que le contexte récupéré. Il produit ensuite une réponse structurée, fluide et adaptée au besoin exprimé. Le modèle peut synthétiser plusieurs passages, reformuler des informations complexes, comparer des éléments ou proposer une explication pédagogique. L’enjeu consiste à générer une réponse fidèle aux sources fournies. Dans une architecture RAG bien conçue, le modèle doit éviter d’ajouter des informations non présentes dans le contexte lorsque la réponse attendue dépend de documents précis.
L’ajout de références et de sources
Dans de nombreux cas, la réponse peut être accompagnée de références, d’extraits ou de liens vers les documents utilisés. Cette traçabilité est particulièrement utile dans les environnements professionnels, juridiques, techniques ou réglementaires. Les sources permettent à l’utilisateur de vérifier l’origine des informations et de consulter le document complet si nécessaire. Elles renforcent aussi la confiance dans le système, car la réponse n’apparaît pas comme une simple génération automatique, mais comme une synthèse fondée sur des éléments identifiables.
La restitution à l’utilisateur
La réponse est ensuite renvoyée à l’utilisateur dans le format attendu : Texte court, explication détaillée, tableau comparatif, liste d’actions, résumé, recommandation ou réponse conversationnelle. Le format peut varier selon l’usage : support client, assistant interne, moteur de recherche intelligent ou outil d’aide à la décision. Une bonne restitution ne consiste pas seulement à fournir une information correcte. Elle doit aussi être lisible, hiérarchisée et adaptée au niveau de connaissance de l’utilisateur. Le même système RAG peut donc produire une réponse technique pour un expert et une explication simplifiée pour un utilisateur métier.
La gestion des cas sans réponse
Un système RAG fiable doit aussi savoir reconnaître lorsqu’il ne dispose pas d’informations suffisantes. Si les documents récupérés ne permettent pas de répondre correctement, il est préférable que le système indique une limite plutôt que de produire une réponse approximative. Cette capacité à dire “je ne dispose pas d’éléments suffisants dans les sources disponibles” est essentielle pour limiter les hallucinations. Elle transforme le système en outil plus maîtrisable, notamment dans les secteurs où l’exactitude des informations est déterminante.
L’amélioration continue du pipeline RAG
Une architecture RAG n’est pas figée. Elle peut être améliorée en continu grâce à l’analyse des requêtes, des réponses générées et des retours utilisateurs. Les équipes peuvent identifier les documents manquants, les passages mal indexés, les requêtes mal comprises ou les réponses insuffisamment précises. Cette boucle d’amélioration permet d’optimiser progressivement la qualité du retrieval, la pertinence du contexte et la fiabilité des réponses. En entreprise, elle constitue un levier important pour transformer un simple prototype IA en système robuste et réellement utile au quotidien.
La valeur du pipeline RAG dans un contexte professionnel
Ce fonctionnement étape par étape, structuré sous forme de pipeline, introduit une véritable mémoire externe contrôlable. Chaque brique du pipeline RAG (de la recherche d’information à la génération) contribue à fiabiliser le résultat final. Au lieu de dépendre uniquement des connaissances internes du modèle, l’entreprise peut connecter l’IA à ses propres données, les mettre à jour régulièrement et maîtriser précisément les sources utilisées. C’est cette logique de pipeline qui rend l’architecture RAG particulièrement adaptée aux usages professionnels : Elle améliore la précision, facilite la traçabilité, réduit les réponses inventées et permet de créer des assistants capables d’exploiter un patrimoine documentaire spécifique de manière structurée et évolutive.
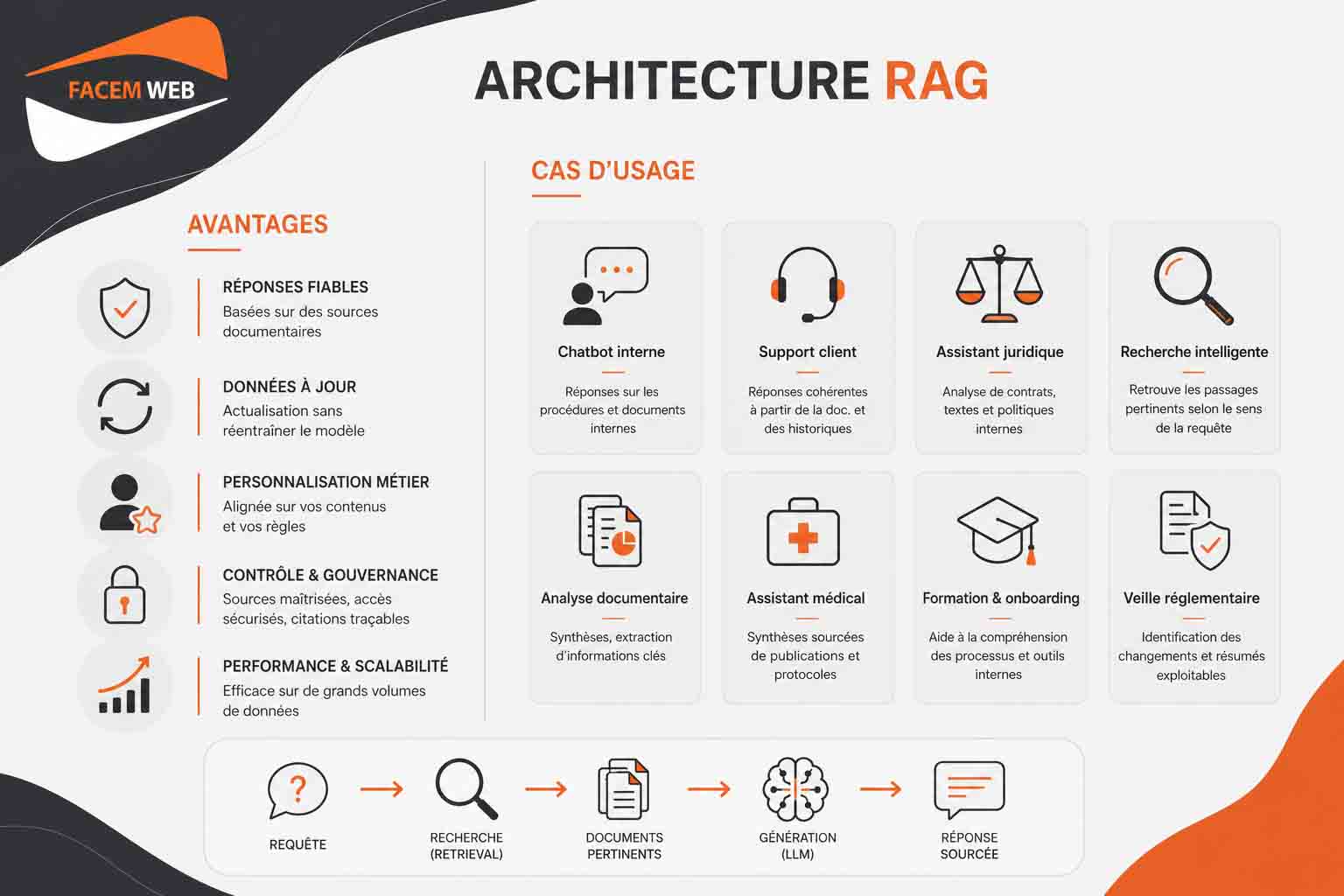
Les avantages et cas d’usage d’une architecture RAG (Exemples)
L’adoption croissante des architectures RAG s’explique par leur capacité à répondre à des besoins concrets en matière de performance, de fiabilité et de maîtrise des données. Avant d’explorer leurs cas d’usage, il est essentiel de comprendre les bénéfices qu’elles apportent dès leur mise en œuvre.
Une fiabilité renforcée grâce aux sources documentaires
L’un des principaux avantages d’une architecture RAG réside dans sa capacité à ancrer les réponses dans des sources identifiables. Le modèle ne s’appuie pas uniquement sur ses connaissances internes : il consulte une base documentaire, récupère les passages utiles, puis génère une réponse à partir de ce contexte. Cette approche réduit les approximations, limite les hallucinations et améliore la confiance accordée aux réponses produites, notamment lorsque les informations doivent être vérifiables.
Des données plus récentes sans réentraîner le modèle
Une architecture RAG permet d’actualiser les connaissances disponibles sans relancer un entraînement complet du modèle de langage. Il suffit d’ajouter, modifier ou supprimer des documents dans la base de connaissances pour que le système puisse exploiter de nouvelles informations. Cette souplesse est particulièrement utile dans les secteurs où les contenus évoluent rapidement : documentation produit, réglementation, procédures internes, offres commerciales, politiques RH ou bases de support client.
Une personnalisation adaptée aux besoins métier
Les entreprises peuvent connecter une architecture RAG à leurs propres ressources : FAQ, guides internes, contrats, tickets de support, bases de connaissances, comptes rendus, documents techniques ou contenus commerciaux. Le système devient alors capable de produire des réponses alignées avec le vocabulaire, les règles et les processus de l’organisation. Cette personnalisation transforme un modèle généraliste en assistant métier spécialisé, capable d’exploiter un patrimoine documentaire précis.
Un meilleur contrôle des réponses et des usages
Le contrôle des sources constitue un autre atout majeur d’une architecture RAG. Une entreprise peut définir précisément le périmètre documentaire exploité par le système : limiter les réponses à un corpus validé, exclure certains contenus sensibles, gérer les droits d’accès ou encore imposer des règles strictes de citation. Cette capacité de gouvernance permet d’aligner les réponses générées avec les politiques internes, les exigences réglementaires et les standards de qualité propres à chaque organisation. Dans des secteurs sensibles comme la finance, la santé, le droit, l’assurance ou l’industrie, cette maîtrise devient indispensable, car elle garantit que les informations diffusées reposent sur des sources fiables et vérifiées. L’architecture RAG s’inscrit ainsi dans une logique de contrôle et de traçabilité, où chaque réponse peut être reliée à un contenu précis, réduisant les risques liés à l’interprétation ou à la génération non encadrée. Cette approche prend encore plus de valeur lorsqu’elle est intégrée dans des systèmes plus avancés, comme des agents IA : ces derniers ne se contentent pas de répondre à une question, mais peuvent enchaîner des actions, interroger plusieurs sources, vérifier des informations, reformuler des résultats et prendre des décisions dans un cadre défini. Le contrôle des sources devient alors un levier central pour encadrer leur comportement et garantir leur alignement avec les objectifs métier. L’architecture RAG permet ainsi de combiner performance de l’IA générative, structuration des données et pilotage des usages, en offrant un cadre robuste pour déployer des systèmes intelligents capables d’interagir avec des données complexes tout en respectant des contraintes opérationnelles fortes.
| Cas d’usage | Apport d’une architecture RAG |
|---|---|
| Chatbot interne pour les employés | Répond aux questions RH, IT, juridiques ou opérationnelles en s’appuyant sur les procédures et documents internes de l’entreprise. |
| Support client automatisé | Fournit des réponses cohérentes à partir de la documentation officielle, des FAQ, des guides produit et des historiques de tickets. |
| Assistant juridique | Analyse des contrats, textes réglementaires ou politiques internes afin de produire des synthèses, comparaisons et points d’attention. |
| Moteur de recherche intelligent | Va au-delà de la recherche par mots-clés en retrouvant des passages pertinents selon le sens de la requête utilisateur. |
| Analyse documentaire avancée | Résume de grands volumes de documents, extrait des informations clés et facilite la comparaison entre plusieurs sources. |
| Assistant médical ou scientifique | Interroge des publications, protocoles ou bases spécialisées pour produire des synthèses compréhensibles et sourcées. |
| Formation et onboarding | Aide les nouveaux collaborateurs à comprendre les processus, outils et règles internes à partir de contenus validés. |
| Veille réglementaire | Permet de retrouver rapidement les textes applicables, d’identifier les changements et de produire des résumés exploitables. |

0 commentaires