Une idée prend forme, un projet se dessine, et soudain, le champ des possibles s’élargit considérablement. Aujourd’hui, concevoir une solution numérique n’exige plus des ressources démesurées ni des cycles de développement interminables. L’intelligence artificielle transforme en profondeur les méthodes de création, d’organisation et de déploiement des produits digitaux, en jouant tour à tour le rôle de levier de productivité, d’outil d’analyse et même de partenaire de conception. Cependant, cette accessibilité nouvelle ne doit pas masquer les exigences du processus. Monter un projet digital avec l’IA implique une approche structurée, une bonne maîtrise des technologies disponibles et une vision stratégique affirmée. L’enjeu n’est pas simplement d’intégrer une innovation tendance, mais de l’exploiter de manière pertinente au service d’un projet cohérent, utile et pérenne. Dans cet article, étudions ensemble en profondeur les étapes, les bonnes pratiques et les pièges à éviter pour transformer une idée en projet numérique viable grâce à l’intelligence artificielle.
Définir une vision claire et identifier les opportunités de l’IA pour un projet numérique
Tout projet numérique débute par une intuition ou une idée, mais sa réussite repose sur sa capacité à être structurée et alignée avec un besoin réel. Dans le contexte de l’intelligence artificielle, cette exigence est encore plus forte. L’IA ne doit jamais être intégrée par effet de mode, mais comme une brique technologique au service d’un objectif précis, mesurable et exploitable à grande échelle.La première phase consiste à formaliser le problème à résoudre. D’un point de vue technique, cela implique souvent une phase de cadrage incluant l’analyse des processus existants, la cartographie des flux de données et l’identification des points de friction. Par exemple, un projet peut viser à réduire le temps de traitement d’une tâche via l’automatisation, améliorer la prise de décision grâce à l’analyse prédictive, ou encore personnaliser une expérience utilisateur en exploitant des modèles de recommandation. L’identification des opportunités liées à l’IA passe également par une compréhension fine des cas d’usage adaptés. Certaines familles de problèmes se prêtent particulièrement bien à l’intégration de modèles intelligents :
- Le traitement du langage naturel (NLP) pour les chatbots, moteurs de recherche ou analyse sémantique ;
- La vision par ordinateur pour la reconnaissance d’images ou le contrôle qualité ;
- Les systèmes de recommandation pour optimiser l’engagement utilisateur ;
- Les modèles prédictifs pour anticiper des comportements ou des tendances.
Une fois le cas d’usage identifié, il devient nécessaire de cadrer précisément le rôle de l’IA dans l’architecture globale du projet. Cela implique de définir si l’IA agit comme un composant central (core system) ou comme un module d’optimisation complémentaire. Cette distinction impacte directement les choix techniques, les ressources nécessaires et la complexité du projet. Voici un tableau permettant de structurer cette réflexion en confrontant les objectifs métier aux apports techniques de l’IA :
| Objectif métier | Apport technique de l’IA |
|---|---|
| Réduire les coûts opérationnels | Automatisation via modèles de classification, de détection d’anomalies ou de traitement automatique des tâches répétitives |
| Améliorer l’expérience utilisateur | Personnalisation en temps réel grâce à des algorithmes de recommandation et des modèles de segmentation comportementale |
| Optimiser la prise de décision | Analyse prédictive basée sur des modèles de machine learning supervisé et des systèmes de scoring |
| Exploiter des données non structurées | Utilisation de NLP pour extraire, structurer et analyser des textes, documents ou conversations |
| Accélérer un processus métier | Traitement automatisé via modèles entraînés sur des données historiques et intégrés dans des workflows |
| Améliorer le support client | Déploiement de chatbots intelligents capables de comprendre et traiter des demandes complexes en langage naturel |
| Augmenter le taux de conversion | Optimisation des parcours utilisateurs via analyse comportementale et recommandations personnalisées |
| Détecter les fraudes ou anomalies | Modèles de détection d’anomalies en temps réel basés sur des patterns atypiques ou des écarts statistiques |
| Optimiser la gestion des stocks | Prévisions de demande via modèles prédictifs intégrant des données historiques et des variables externes |
| Automatiser la production de contenu | Génération de textes, images ou résumés via modèles génératifs adaptés au contexte métier |
| Améliorer la qualité des données | Nettoyage, déduplication et enrichissement automatisé grâce à des modèles de matching et de classification |
| Optimiser les campagnes marketing | Segmentation avancée et ciblage précis via clustering et modèles prédictifs de comportement |
| Faciliter l’accès à l’information | Moteurs de recherche sémantique et systèmes RAG pour interroger des bases documentaires complexes |
| Réduire les délais de traitement | Automatisation des workflows et orchestration intelligente des tâches via IA |
| Améliorer la maintenance des systèmes | Maintenance prédictive basée sur l’analyse des signaux faibles et des historiques de panne |
| Optimiser la gestion des ressources humaines | Analyse des compétences, tri de CV automatisé et prédiction des besoins en recrutement |
| Renforcer la cybersécurité | Détection d’intrusions et analyse comportementale des utilisateurs pour identifier les activités suspectes |
| Améliorer les produits ou services | Analyse des retours clients et des données d’usage pour orienter les évolutions produit |
| Automatiser les tâches administratives | Extraction d’informations depuis des documents (factures, contrats) via OCR et NLP |
| Optimiser la logistique | Planification intelligente des itinéraires et optimisation des flux grâce à des modèles prédictifs |
En parallèle, il est indispensable d’évaluer la faisabilité technique. Cela inclut plusieurs dimensions : La disponibilité et la qualité des données, la capacité à les exploiter (data engineering), les compétences en interne avec notamment un chef de projet digital, ainsi que les contraintes d’infrastructure. Un projet basé sur l’IA nécessite souvent une pipeline de données robuste intégrant collecte, nettoyage, transformation et stockage. Il est également pertinent de distinguer les approches possibles : utiliser des modèles pré-entraînés via des API (approche rapide et peu coûteuse) ou développer des modèles sur mesure (plus performant mais plus exigeant). Ce choix dépend du niveau de différenciation recherché et des ressources disponibles. Enfin, définir une vision claire implique d’anticiper la scalabilité et la maintenabilité du projet. Une architecture moderne s’appuie généralement sur des microservices, permettant d’isoler les composants IA et de les faire évoluer indépendamment. De plus, la mise en place de pratiques MLOps (Machine Learning Operations) devient essentielle pour gérer le cycle de vie des modèles : Versioning, déploiement continu, monitoring et réentraînement.
Construire une architecture technique et choisir les bons outils pour son projet numérique avec l’IA
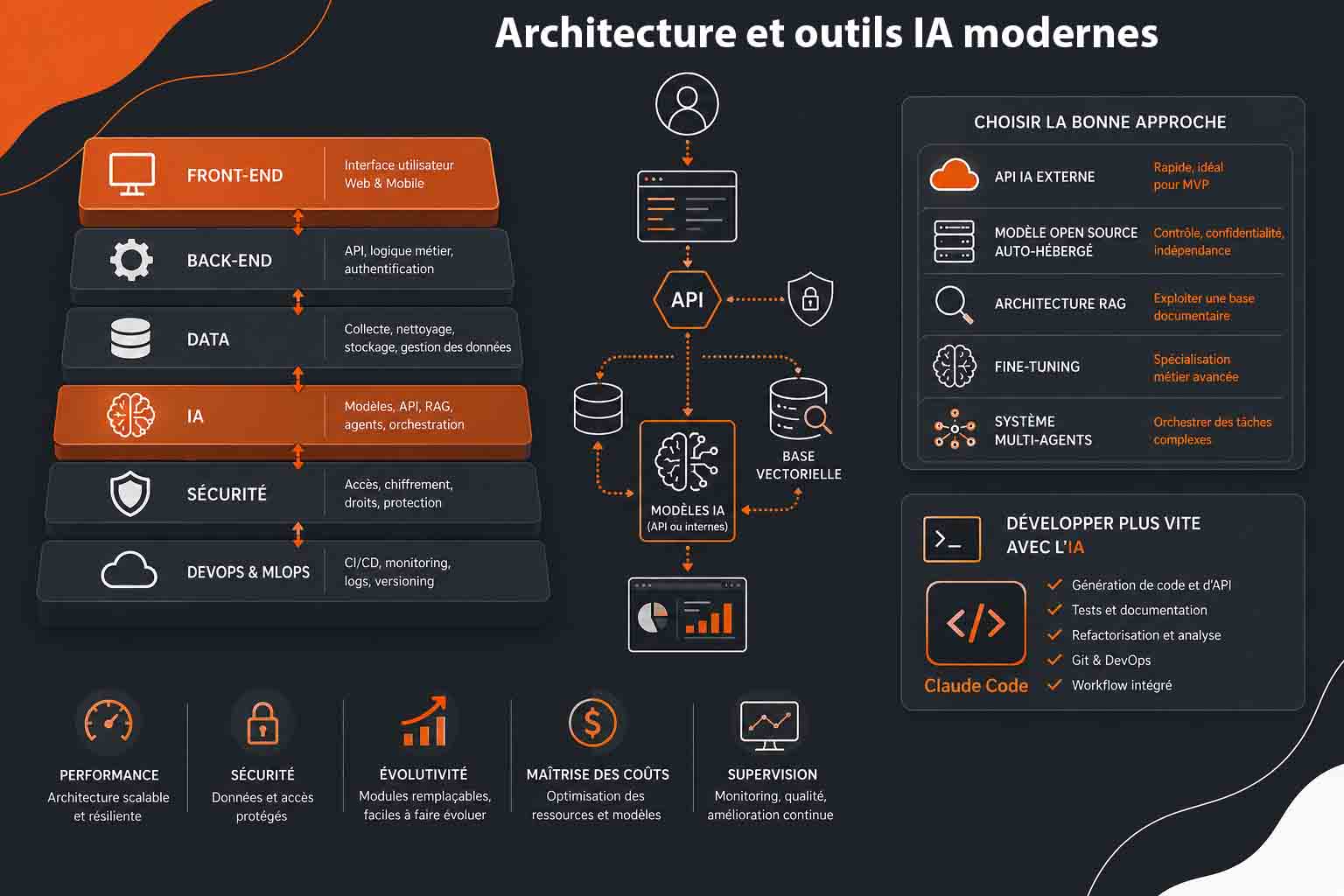
Une fois la vision définie, le projet numérique entre dans une phase beaucoup plus opérationnelle : La conception de l’architecture technique. C’est à ce moment que l’intelligence artificielle cesse d’être une intention stratégique pour devenir une brique concrète du système d’information. Les choix réalisés ici auront un impact direct sur la performance, la sécurité, la maintenabilité, les coûts d’exploitation et la capacité du projet à évoluer. Un projet numérique avec l’IA ne se limite pas à brancher une API sur une interface utilisateur. Il faut penser l’ensemble de la chaîne technique : collecte des données, stockage, traitement, appel aux modèles, gestion des droits, supervision, journalisation, sécurité, tests, déploiement et amélioration continue. Une bonne architecture doit être capable de fonctionner aujourd’hui, tout en restant suffisamment flexible pour intégrer de nouveaux modèles, de nouveaux usages ou de nouvelles contraintes réglementaires.
La première décision consiste à déterminer le niveau d’intégration de l’IA dans le projet. Dans certains cas, l’IA joue un rôle périphérique : génération de texte, résumé automatique, assistant conversationnel, classification simple ou aide à la recherche. Dans d’autres cas, elle devient le cœur même du produit, par exemple pour une plateforme de recommandation, un outil d’analyse prédictive, un moteur de scoring ou un assistant métier capable d’interagir avec plusieurs sources de données.Cette distinction est importante, car elle influence toute l’architecture. Une IA utilisée comme fonctionnalité secondaire peut souvent reposer sur des API externes. En revanche, une IA placée au centre du produit demande une architecture plus robuste, avec une gestion fine des données, des mécanismes de contrôle qualité, une stratégie de monitoring et parfois des modèles spécialisés. Voici les principales couches techniques à prévoir dans une architecture numérique intégrant l’IA :
- Une couche front-end pour l’interface utilisateur, développée par exemple avec React, Vue.js, Next.js ou Angular ;
- Une couche back-end pour gérer la logique métier, les API, l’authentification et les workflows ;
- Une couche data pour collecter, nettoyer, structurer et stocker les données ;
- Une couche IA pour appeler des modèles externes, héberger des modèles internes ou orchestrer plusieurs agents ;
- Une couche sécurité pour protéger les accès, les données sensibles et les échanges applicatifs ;
- Une couche DevOps et MLOps pour automatiser les tests, les déploiements, le monitoring et le versioning.
Le choix des outils dépend ensuite du niveau de maturité du projet. Pour un prototype ou un MVP, il est souvent préférable d’aller vite avec des solutions existantes. Une API d’IA générative, une base vectorielle managée, un framework web moderne et un hébergement cloud peuvent suffire à valider le concept. Pour un produit destiné à la production, il faudra aller plus loin : gestion des environnements, tests automatisés, supervision, chiffrement, audit des prompts, contrôle des coûts et stratégie de réversibilité. Les API d’IA générative comme celles d’OpenAI, Anthropic, Mistral AI ou Google permettent de créer rapidement des fonctionnalités avancées : génération de contenu, analyse documentaire, extraction d’informations, traduction, reformulation, classification, assistance conversationnelle ou génération de code. Elles réduisent fortement le temps de développement, mais introduisent aussi une dépendance à un fournisseur externe, à ses tarifs, à ses limites d’usage et à ses évolutions techniques. Pour les projets manipulant beaucoup de documents, une architecture RAG, pour Retrieval-Augmented Generation, est souvent pertinente. Elle consiste à connecter un modèle de langage à une base documentaire ou métier afin de produire des réponses mieux contextualisées. Techniquement, cela suppose de découper les documents en fragments, de générer des embeddings, de les stocker dans une base vectorielle, puis de récupérer les passages les plus pertinents au moment de la requête utilisateur.
Dans ce type d’architecture, des outils comme PostgreSQL avec pgvector, Pinecone, Weaviate, Qdrant ou Elasticsearch peuvent être utilisés pour la recherche sémantique. Le back-end orchestre ensuite la requête : il récupère la question de l’utilisateur, interroge la base vectorielle, injecte les éléments pertinents dans le prompt, appelle le modèle IA, puis renvoie une réponse contrôlée à l’interface. Pour les projets plus avancés, il peut être nécessaire d’entraîner ou d’adapter des modèles spécifiques. Cela implique une chaîne plus lourde : collecte des données, nettoyage, annotation, entraînement, évaluation, optimisation et déploiement. Le fine-tuning peut être utile lorsqu’un modèle généraliste ne répond pas assez précisément à un contexte métier. Toutefois, il ne doit pas être choisi automatiquement. Dans de nombreux cas, un bon système RAG, des prompts bien conçus et une structuration correcte des données donnent de meilleurs résultats avec moins de complexité. Le choix entre API externe, modèle open source, fine-tuning ou RAG doit donc être fait selon des critères techniques et métier. Le tableau suivant permet de comparer les principales approches :
| Approche technique | Cas d’usage recommandé |
|---|---|
| API IA externe | Idéale pour un MVP, un assistant conversationnel, la génération de contenu ou l’analyse rapide de texte sans infrastructure lourde |
| Modèle open source auto-hébergé | Adapté aux projets nécessitant plus de contrôle, une meilleure confidentialité ou une réduction de la dépendance fournisseur |
| Architecture RAG | Recommandée pour exploiter une base documentaire, une FAQ, un intranet, une documentation technique ou des données métier internes |
| Fine-tuning | Utile lorsque le modèle doit adopter un comportement spécialisé, un vocabulaire métier précis ou une classification très spécifique |
| Système multi-agents | Pertinent pour orchestrer plusieurs tâches complexes comme recherche, analyse, génération, validation, test et documentation |
Un autre point essentiel concerne le choix des outils de développement. Les environnements assistés par l’IA ont beaucoup progressé. Des solutions comme GitHub Copilot, Cursor, Windsurf ou Claude Code permettent d’accélérer l’écriture du code, la compréhension d’une base existante, la génération de tests, la correction d’erreurs et la documentation technique. Claude Code, en particulier, bénéficie actuellement d’une forte visibilité chez les développeurs. Anthropic le présente comme un outil de codage agentique capable de lire une base de code, modifier des fichiers, exécuter des commandes, lancer des tests et s’intégrer aux outils de développement. Il est disponible dans le terminal, l’IDE, l’application desktop et le navigateur, ce qui le rend intéressant pour des équipes qui veulent intégrer l’IA directement dans leur workflow technique. Son intérêt ne réside pas seulement dans la génération de snippets. Claude Code s’inscrit dans une logique d’agent de développement : il peut analyser un dépôt, comprendre l’architecture existante, proposer des modifications sur plusieurs fichiers, automatiser certaines tâches répétitives, accompagner les workflows Git et aider à produire du code plus rapidement. Cette approche est particulièrement utile pour monter un projet numérique avec l’IA, car elle permet de prototyper plus vite, de documenter plus proprement et de réduire le temps passé sur certaines tâches techniques répétitives. Il faut toutefois l’utiliser avec méthode. Un assistant de code agentique ne remplace pas une revue technique humaine. Le code généré doit être relu, testé, sécurisé et intégré dans une chaîne de validation. Dans un projet professionnel, il est recommandé d’encadrer son usage avec des règles précises : conventions de code, fichiers de contexte, limites d’accès aux secrets, validation par pull request, tests automatisés et vérification des dépendances. L’intégration de Claude Code ou d’un outil similaire peut être particulièrement efficace dans plusieurs situations :
- Générer rapidement une structure de projet back-end ou front-end ;
- Créer des endpoints API à partir d’un cahier des charges fonctionnel ;
- Produire des tests unitaires et des tests d’intégration ;
- Documenter une base de code existante ;
- Refactoriser des composants complexes ;
- Identifier des incohérences dans une architecture logicielle ;
- Automatiser certaines tâches Git ou DevOps.
Pour l’infrastructure, le choix dépendra du niveau d’exigence du projet. Un MVP peut être hébergé sur Vercel, Netlify, Railway, Render ou Supabase. Une application plus robuste pourra s’appuyer sur AWS, Google Cloud, Microsoft Azure ou OVHcloud, avec une séparation claire entre les environnements de développement, de préproduction et de production. Dans une architecture professionnelle, il est recommandé de séparer les responsabilités. Le front-end ne doit pas appeler directement les services IA sensibles. Les appels aux modèles doivent passer par un back-end sécurisé, capable de gérer l’authentification, les quotas, la journalisation, le filtrage des entrées, la protection contre les injections de prompt et la maîtrise des coûts. Cette couche intermédiaire permet aussi de changer de fournisseur IA plus facilement si nécessaire. La sécurité doit être pensée dès le départ. Les projets IA manipulent souvent des données sensibles : Informations clients, documents internes, historiques de conversation, données personnelles ou données stratégiques. Il faut donc prévoir le chiffrement des données, la gestion des accès par rôle, la rotation des clés API, la journalisation des actions, l’anonymisation lorsque c’est possible et une politique claire de conservation des données. Un autre risque technique concerne les prompts. Dans une application IA, les prompts deviennent une partie de la logique métier. Ils doivent donc être versionnés, testés et documentés comme du code. Une modification de prompt peut changer fortement le comportement du système. Pour éviter les dérives, il est utile de mettre en place des jeux de tests avec des cas représentatifs, des cas limites et des scénarios d’attaque, notamment pour détecter les hallucinations, les réponses hors périmètre ou les injections de prompt.
La qualité des données reste également un facteur déterminant. Une IA performante repose sur des données propres, cohérentes et bien structurées. Avant de connecter un modèle à une base métier, il faut souvent mener un travail de data engineering : suppression des doublons, normalisation des formats, enrichissement des métadonnées, classification des documents et contrôle des droits d’accès. Sans cette étape, même un excellent modèle produira des résultats approximatifs. Enfin, l’architecture doit prévoir la supervision. Un projet numérique avec l’IA ne se pilote pas uniquement avec des métriques techniques classiques comme le temps de réponse ou le taux d’erreur serveur. Il faut aussi suivre des indicateurs propres à l’IA : Pertinence des réponses, taux de reformulation, coût par requête, taux d’escalade vers un humain, fréquence des hallucinations, satisfaction utilisateur, latence du modèle et stabilité des performances dans le temps.
Construire une architecture technique solide pour un projet numérique avec l’IA revient donc à trouver le bon équilibre entre rapidité, contrôle, sécurité et évolutivité. Les outils récents comme Claude Code accélèrent fortement le développement, mais la réussite repose toujours sur une conception rigoureuse : une architecture modulaire, des données fiables, des tests automatisés, une supervision continue et une gouvernance claire des usages de l’intelligence artificielle.
Déployer, tester et améliorer en continu un projet numérique avec l’IA
Le déploiement d’un projet numérique avec l’IA ne marque pas la fin du travail technique. Il correspond plutôt au passage d’un environnement maîtrisé à un environnement réel, dans lequel les utilisateurs, les données, les comportements et les contraintes opérationnelles vont mettre le système à l’épreuve. Une solution IA peut fonctionner correctement en phase de démonstration, puis révéler des limites dès qu’elle est confrontée à des volumes importants, à des cas d’usage imprévus ou à des données plus hétérogènes. Avant toute mise en production, il est donc nécessaire de préparer une stratégie de déploiement progressive. L’objectif n’est pas de rendre immédiatement l’outil accessible à tous, mais de sécuriser chaque étape : tests internes, bêta fermée, déploiement auprès d’un groupe restreint, puis ouverture plus large. Cette approche réduit les risques techniques et permet de collecter rapidement des retours exploitables. Dans un projet intégrant de l’intelligence artificielle, les tests doivent couvrir plusieurs niveaux. Il ne suffit pas de vérifier que l’application fonctionne. Il faut aussi évaluer la pertinence des réponses, la stabilité du modèle, la sécurité des entrées, le comportement en cas d’erreur et la cohérence des résultats dans le temps :
- Les tests unitaires valident les fonctions isolées du code ;
- Les tests d’intégration vérifient les échanges entre front-end, back-end, base de données et services IA ;
- Les tests fonctionnels contrôlent les parcours utilisateurs ;
- Les tests de charge mesurent la résistance de l’application face à un trafic élevé ;
- Les tests de sécurité identifient les failles potentielles ;
- Les tests IA évaluent la qualité, la cohérence et la fiabilité des sorties générées.
Pour une application basée sur un modèle génératif, il est recommandé de constituer un jeu de tests représentatif. Celui-ci doit inclure des cas simples, des cas complexes, des formulations ambiguës, des requêtes hors périmètre et des tentatives de contournement. Cette base de test permet de comparer les versions successives du système et d’éviter qu’une amélioration apparente ne dégrade d’autres comportements. La mise en production doit également intégrer une logique d’observabilité. Une application IA doit être surveillée en continu, non seulement sur le plan technique, mais aussi sur la qualité de ses résultats. Le monitoring doit inclure la latence, les erreurs serveur, la consommation de ressources, le coût par requête, le taux d’échec des appels API, mais aussi des indicateurs métiers comme le taux de satisfaction, le taux de correction humaine ou le taux d’abandon.
| Indicateur à suivre | Utilité pour le projet IA |
|---|---|
| Temps de réponse | Mesure la rapidité perçue par l’utilisateur et permet d’identifier les lenteurs liées au modèle ou à l’infrastructure |
| Taux d’erreur | Permet de détecter les problèmes applicatifs, les appels API échoués ou les réponses inexploitables |
| Coût par requête | Aide à contrôler le budget lorsque le projet repose sur des API IA facturées à l’usage |
| Pertinence des réponses | Évalue la qualité réelle des résultats générés par le modèle selon des critères métier |
| Taux d’escalade humaine | Indique la part des situations où l’IA ne suffit pas et où une intervention humaine reste nécessaire |
| Satisfaction utilisateur | Mesure l’adéquation entre la solution proposée et les attentes réelles des utilisateurs |
L’amélioration continue repose ensuite sur la collecte structurée des retours. Chaque interaction peut devenir une source d’apprentissage, à condition d’être correctement encadrée. Les retours utilisateurs, les corrections humaines, les notes de satisfaction, les abandons de parcours ou les reformulations de requêtes permettent d’identifier les points faibles du système. Il est important de distinguer l’apprentissage automatique du modèle et l’amélioration du produit. Dans de nombreux projets, le modèle ne s’améliore pas seul en temps réel. Les données collectées doivent être analysées, filtrées, validées, puis utilisées pour ajuster les prompts, enrichir une base documentaire, améliorer un pipeline RAG, modifier une règle métier ou entraîner une nouvelle version du modèle. Cette gouvernance évite d’introduire des erreurs, des biais ou des données non conformes dans le système.
Pour les projets utilisant une architecture RAG, l’amélioration continue passe souvent par la qualité de la base documentaire. Il faut vérifier si les documents sont à jour, si les fragments sont bien découpés, si les métadonnées sont pertinentes et si la recherche vectorielle remonte les bonnes informations. Une réponse médiocre ne vient pas toujours du modèle : elle peut provenir d’un mauvais contexte, d’une donnée obsolète ou d’un index mal structuré. Les prompts doivent eux aussi être pilotés dans le temps. Un prompt efficace lors du lancement peut devenir insuffisant lorsque les usages se diversifient. Il est donc recommandé de versionner les prompts, de documenter les changements, de tester chaque nouvelle version et de mesurer son impact avant de la généraliser. Dans une équipe technique, les prompts doivent être traités comme des composants applicatifs à part entière. La sécurité reste un sujet permanent après le déploiement. Les utilisateurs peuvent saisir des données sensibles, tenter de détourner le comportement du modèle ou provoquer des réponses hors cadre. Il faut donc mettre en place des filtres d’entrée, des règles de sortie, une limitation des usages, une journalisation des événements sensibles et des mécanismes de détection des comportements anormaux.
L’éthique et la conformité doivent également être intégrées au cycle d’amélioration. Un projet IA peut produire des biais, manquer de transparence ou générer des réponses difficiles à expliquer. Pour limiter ces risques, il est nécessaire de définir clairement le rôle de l’IA, d’informer les utilisateurs lorsqu’ils interagissent avec un système automatisé, de prévoir des mécanismes de contestation ou de correction, et de limiter l’usage des données personnelles au strict nécessaire. Dans certains contextes, il est préférable de conserver un humain dans la boucle. C’est particulièrement vrai lorsque l’IA influence une décision sensible, produit une recommandation métier importante ou manipule des informations à fort impact. Le principe du human-in-the-loop permet de combiner rapidité algorithmique et validation humaine, tout en réduisant les risques d’erreur. Enfin, l’amélioration continue doit être organisée dans une logique produit. Il faut planifier des cycles courts, prioriser les évolutions selon leur impact, suivre une feuille de route et arbitrer entre performance, coût, sécurité et expérience utilisateur. Une fonctionnalité IA peut être techniquement impressionnante, mais inutile si elle ne résout pas un problème concret ou si elle dégrade le parcours utilisateur.
Déployer, tester et améliorer en continu un projet numérique avec l’IA revient donc à installer une discipline complète autour du produit : supervision technique, évaluation métier, contrôle qualité, gouvernance des données, sécurité, conformité et écoute des utilisateurs. C’est cette capacité à apprendre, corriger et évoluer qui transforme un simple prototype IA en solution numérique fiable, durable et réellement utile.

0 commentaires