Les données structurées sont un vocabulaire sémantique que l’on intègre dans le code HTML pour aider les moteurs de recherche à comprendre le contenu d’une page Web. Elles suivent généralement les standards définis par Schema.org — un projet lancé en 2011 par Google, Microsoft, Yahoo et Yandex. On parle aussi de microdonnées ou de rich snippets lorsque ces données s’affichent visuellement dans la SERP (Search Engine Results Page). Leur objectif n’est pas d’améliorer directement le classement SEO, mais bien d’augmenter la visibilité du résultat, de capter l’attention et donc d’améliorer le CTR (taux de clic).
Exemples d’affichage des données structurées
Les extraits enrichis (rich snippets) sont des affichages complémentaires dans les résultats de recherche. Ils améliorent la visibilité d’un lien en y ajoutant des éléments visuels ou informatifs issus du balisage sémantique (notes, prix, images, auteur, durée, etc.).
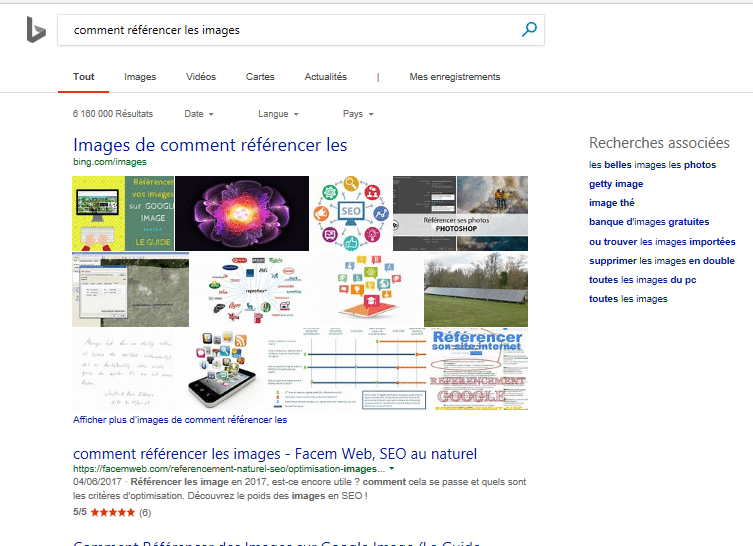
Voici un premier exemple sur Bing où l’on distingue l’intégration de la notation (étoiles), du nombre d’avis et du prix :
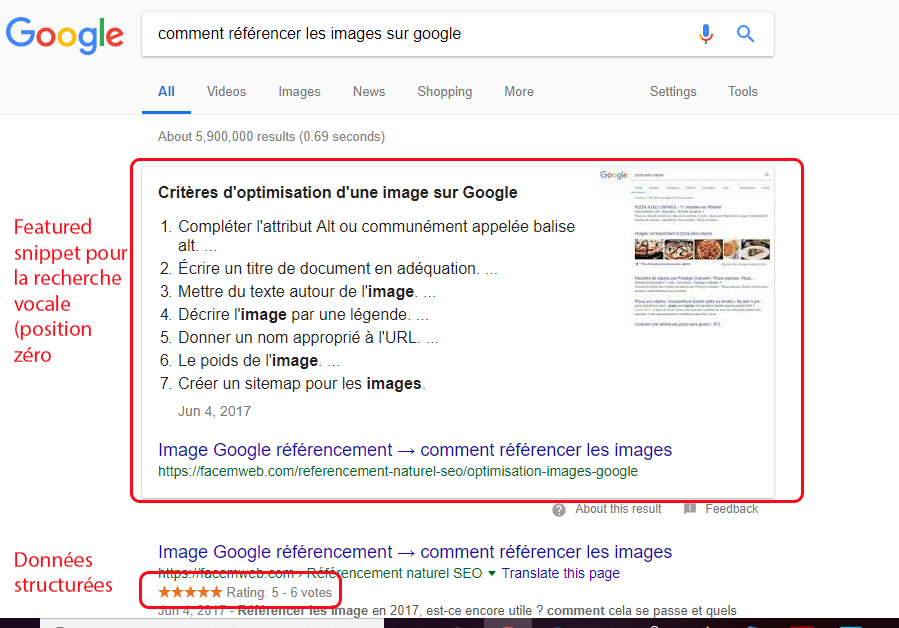
Et ici sur Google, avec un affichage complet incluant un featured snippet (position zéro) :
⚠️ À noter : Qwant, tout comme DuckDuckGo, n’affiche pas (ou très peu) d’extraits enrichis. Ces moteurs misent sur la confidentialité mais offrent moins de « rich data visualisation » que leurs concurrents.
Autres exemples de rich snippets fréquents :
- Produits : affichage du prix, de la disponibilité, de la note client.
- Avis : étoiles, nombre d’évaluations, synthèse de la critique.
- Recettes : image, durée de préparation, calories, ingrédients.
- Événements : lieu, date, horaires.
- FAQ : Google affiche directement les questions/réponses sous la meta description.
- How-to : pour les tutoriels étape par étape avec images et actions définies.
Exemple sur mobile d’un rich snippet avec FAQ :
On voit les questions/réponses apparaître directement sous le lien :
- Comment utiliser cette fonctionnalité ? → Réponse dans la meta - Est-ce que c’est gratuit ? → Oui, dans la version de base...
Affichage dans Google Discover :
Les contenus structurés via Article ou NewsArticle peuvent être favorisés par Google pour apparaître dans Google Discover sur mobile avec image large, auteur, date, etc.
Extrait enrichi pour recette de cuisine (format JSON-LD)
Voici un exemple d’utilisation de JSON-LD (format recommandé) pour une recette :
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Recipe",
"name": "Crêpes maison faciles",
"image": "https://exemple.com/images/crepes.jpg",
"description": "Des crêpes moelleuses à préparer en 10 minutes.",
"keywords": "crêpes, dessert, facile",
"author": {
"@type": "Person",
"name": "Julie Martin"
},
"prepTime": "PT10M",
"cookTime": "PT15M",
"totalTime": "PT25M",
"recipeYield": "10 crêpes",
"recipeCategory": "Dessert",
"recipeCuisine": "Française",
"nutrition": {
"@type": "NutritionInformation",
"calories": "210 calories"
},
"recipeIngredient": [
"250g de farine",
"3 œufs",
"1/2 litre de lait",
"1 pincée de sel",
"1 c. à soupe d'huile"
],
"recipeInstructions": [
"Mélanger la farine et les œufs.",
"Incorporer progressivement le lait.",
"Ajouter l’huile et le sel.",
"Cuire dans une poêle chaude 1 à 2 minutes par face."
]
}
</script>
Ce type de balisage permet l’apparition directe des informations dans la SERP : temps de préparation, image, note, calories, etc.
Remarques techniques :
- Utilisez Google Rich Results Test pour vérifier votre balisage : https://search.google.com/test/rich-results
- Préférez le format JSON-LD (à intégrer dans le <head> ou via un plugin WordPress comme Rank Math ou Yoast)
- Assurez-vous de bien structurer votre contenu HTML avant même d’ajouter les données structurées
Les données structurées ne sont pas une baguette magique, mais leur impact sur la visibilité, le taux de clics et la fiabilité perçue de vos pages peut être considérable, en particulier pour les sites e-commerce, médias et blogs spécialisés.
Générer du code propre avec Schema.org
La création de balisage structuré peut sembler fastidieuse, surtout si l’on débute avec le format JSON-LD. Heureusement, de nombreux outils existent pour vous aider à générer un code propre, conforme aux exigences des moteurs de recherche. Ces générateurs vous guident dans la déclaration des propriétés prévues par schema.org.
Les outils classiques à votre disposition :
- Google Structured Data Markup Helper : parfait pour débuter avec une interface visuelle ;
- Schema Markup Generator de TechnicalSEO : générateur simple pour articles, produits, organisations ;
- SchemaApp : une solution complète (gratuite et payante) pour les agences et les grandes structures.
Nouvelles solutions basées sur l’IA :
- ChatGPT (ou autres IA génératives) : capable de produire un balisage JSON-LD personnalisé à partir d’une simple description (exemple : “fais-moi une fiche schema.org pour un produit de 59€, en stock, avec 200 avis et une note de 4.7”) ;
- Merkle Schema Generator (IA assistée) : propose un encodage semi-automatique avec validation sémantique ;
- Plugins IA WordPress comme RankMath Pro + GPT : certaines extensions intègrent déjà une couche IA pour suggérer des balisages optimisés
Ces outils facilitent l’adoption du balisage structuré, même sans connaissance avancée en développement. Vous pouvez en quelques minutes générer du JSON-LD valide, tester sa compatibilité, et l’intégrer à vos pages.
Types de contenus pris en charge couramment :
- Produits e-commerce (
Product,Offer,AggregateRating) - Recettes (
Recipe,NutritionInformation,HowTo) - Événements (
Event,Place,Performer) - Entreprises locales (
LocalBusiness,OpeningHoursSpecification) - Personnes et organisations (
Person,Organization,ContactPoint) - Articles, livres, FAQ, cours, vidéos, podcasts, etc.
Quel impact SEO réel ?
Contrairement à certaines croyances encore répandues, les données structurées ne sont pas un critère direct de classement dans l’algorithme de Google. Elles n’influencent pas le positionnement pur d’une page dans la SERP. En revanche, leur rôle dans l’enrichissement de l’affichage et dans le comportement utilisateur est déterminant.
Voici les avantages concrets observés :
- Affichage enrichi : votre lien peut afficher des étoiles, prix, durée, image, auteurs, extraits FAQ, fil d’Ariane, etc.
- Hausse du taux de clic (CTR) : selon Moz, Ahrefs ou Backlinko, l’ajout de rich snippets peut entraîner un CTR 10 à 30 % plus élevé.
- Amélioration de la compréhension des contenus par les crawlers (Googlebot, Bingbot…) qui indexent plus efficacement les relations entres les entités sémantiques.
- Avantage concurrentiel sur des requêtes à forte intention transactionnelle ou locale (produits, services, événements).
Google recommande l’usage de JSON-LD pour :
Organization: informations institutionnelles sur votre entreprise ou marqueBreadcrumbList: le fil d’Ariane visible directement dans la SERPWebSiteetSearchAction: pour déclarer la fonction de recherche interne à un site
Intégrer ces balises dans vos modèles de page (thèmes WordPress, CMS custom, ou framework comme Next.js ou Laravel) vous garantit une structuration solide, lisible par les moteurs et évolutive.
À retenir : vous n’avez pas besoin de tout coder à la main. Aujourd’hui, l’IA vous assiste, les plugins CMS s’en chargent souvent, et les outils de test de Google ou Bing valident votre travail. Mais le vrai gain reste dans la compréhension fine de vos données et dans leur hiérarchisation.
Exemple de données structurées JSON-LD enrichies pour un site Web
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "WebSite",
"@id": "https://facemweb.com/#website",
"url": "https://facemweb.com/",
"name": "Facem Web",
"alternateName": "Agence SEO & création de site WordPress",
"description": "Facem Web est une agence web spécialisée en référencement naturel, création de sites WordPress et accompagnement SEO technique depuis plus de 10 ans.",
"publisher": {
"@type": "Organization",
"name": "Facem Web",
"url": "https://facemweb.com/",
"logo": {
"@type": "ImageObject",
"url": "https://facemweb.com/wp-content/uploads/2014/04/logo-ipad-icon.png",
"width": 200,
"height": 60
},
"sameAs": [
"https://www.facebook.com/facemweb.fr",
"https://twitter.com/facemweb",
"https://www.linkedin.com/company/facemweb"
],
"contactPoint": {
"@type": "ContactPoint",
"telephone": "+33-3-20-00-00-00",
"contactType": "Customer Service",
"areaServed": "FR",
"availableLanguage": ["French"]
}
},
"potentialAction": {
"@type": "SearchAction",
"target": "https://facemweb.com/?s={search_term_string}",
"query-input": "required name=search_term_string"
},
"inLanguage": "fr"
}
</script>
Explications des éléments ajoutés :
| Élément | Fonction |
|---|---|
@id |
Permet d’identifier de manière unique cette entité dans d’autres balisages (utile pour relier avec d’autres types comme Organization). |
alternateName |
Indique une variante de nom utilisée couramment pour la marque ou le site. |
description |
Résumé utile pour les Knowledge Panels et autres affichages enrichis. |
publisher |
Définit l’organisation qui publie le site (logo, nom, liens sociaux, numéro de téléphone). |
contactPoint |
Important pour les entreprises locales, facilite la création de fiches enrichies. |
inLanguage |
Spécifie la langue principale du site, ici en français. |
Vous l’aurez compris : les données structurées ne sont pas des gadgets. Bien implémentées, elles peuvent offrir un avantage concurrentiel important dans une SERP saturée. D’autant plus qu’elles influencent aussi les recherches personnalisées, l’historique de recherche, et peuvent améliorer la visibilité à moyen terme.

0 commentaires