Derrière chaque clic, le web déploie une mécanique discrète que l’utilisateur ne perçoit presque jamais. Parmi ces rouages figurent les redirections, conçues à l’origine pour orienter efficacement les internautes d’une page à une autre. Si leur usage est souvent légitime, certaines pratiques en détournent la finalité pour influencer à la fois les moteurs de recherche et les visiteurs. C’est précisément dans ces dérives que s’inscrit la notion de redirection trompeuse en SEO. À la croisée de la technique et de stratégies plus discutables, ces redirections posent de véritables enjeux en matière de référencement, d’expérience utilisateur et de respect des consignes imposées par des acteurs comme Google. En comprendre les mécanismes, les objectifs et les implications comme pour le back button hijacking d’ailleurs permet d’anticiper les risques tout en affinant sa stratégie de visibilité sur le long terme.
- La définition et le fonctionnement des redirections trompeuses en SEO
- Pourquoi ces redirections trompeuses sont parfois utilisées en SEO
- Exploiter le positionnement obtenu sur des mots-clés
- Transformer un trafic informationnel en trafic commercial
- Maximiser les revenus publicitaires ou affiliés
- Contourner les contraintes éditoriales ou algorithmiques
- Utiliser le cloaking comme levier complémentaire
- Exploiter les domaines expirés et les anciennes URL
- Créer des tunnels de redirection complexes
- Tester des pages sans exposer directement l’URL principale
- Se situer dans une zone grise entre optimisation et manipulation
- Les risques et conséquences à utiliser des redirections trompeuses pour votre site web
La définition et le fonctionnement des redirections trompeuses en SEO
Une redirection trompeuse, ou « deceptive redirect », correspond à un mécanisme technique par lequel un utilisateur ou un robot d’exploration est redirigé vers une ressource différente de celle initialement demandée, avec une intention de manipulation du référencement ou de l’expérience de navigation. Contrairement à une redirection classique, qui répond à une logique de continuité ou d’optimisation technique, la redirection trompeuse introduit une rupture volontaire entre la requête initiale, le contenu indexé et la page réellement affichée. D’un point de vue technique, une redirection peut être implémentée à plusieurs niveaux de l’infrastructure web. Elle peut être gérée directement par le serveur via des codes de statut HTTP comme 301 (redirection permanente) ou 302 (redirection temporaire), mais aussi via des règles de réécriture d’URL, des scripts côté client en JavaScript, ou encore des systèmes intermédiaires comme des CDN ou des reverse proxies. Dans un contexte normal, ces mécanismes servent à maintenir la cohérence d’un site, notamment lors de migrations, de corrections d’URL ou d’optimisation de l’architecture. La dimension trompeuse apparaît lorsque ces redirections sont conditionnées par des variables spécifiques afin de présenter des contenus différents selon le profil du visiteur. Le serveur ou le script peut par exemple analyser l’en-tête HTTP User-Agent pour distinguer un robot d’un navigateur classique, exploiter l’adresse IP pour adapter la réponse en fonction de la localisation, ou encore utiliser des cookies et des sessions pour déclencher une redirection différée. Cette logique conditionnelle permet de masquer le comportement réel aux moteurs de recherche tout en orientant l’utilisateur vers une page à forte valeur commerciale ou publicitaire.
Dans certains cas, le moteur de recherche indexe une page riche en contenu optimisé, structurée pour répondre à des requêtes spécifiques. Cependant, lors de l’accès réel, l’utilisateur est redirigé instantanément (parfois via JavaScript ou meta refresh) vers une page sans lien direct avec la requête initiale. Ce décalage entre indexation et affichage constitue le cœur du mécanisme trompeur. Ces pratiques reposent souvent sur des configurations techniques avancées, mêlant logique serveur et exécution côté client, ce qui les rend difficiles à détecter sans analyse approfondie des réponses HTTP ou simulation de navigation avec différents profils.
| Type de redirection | Principe technique |
|---|---|
| Basée sur l’agent utilisateur | Le serveur analyse le User-Agent et délivre un contenu ou une redirection différente selon qu’il s’agisse d’un robot ou d’un utilisateur réel. |
| Géographique | Utilisation de bases de données IP (GeoIP) pour rediriger automatiquement l’utilisateur vers une version différente, parfois sans cohérence avec la requête. |
| Conditionnelle | Déclenchée via JavaScript ou logique backend après une interaction utilisateur (clic, scroll, délai), ce qui complique la détection par les crawlers. |
| Meta refresh | Implémentée dans le code HTML avec un délai court, elle simule un rechargement automatique vers une autre URL. |
| Hybride avec cloaking | Combine affichage différencié et redirection pour présenter un contenu optimisé aux moteurs tout en redirigeant les utilisateurs vers une autre page. |
En pratique, la détection de ces redirections nécessite des outils capables de reproduire différents contextes de navigation : Variation des User-Agents, tests depuis plusieurs localisations, ou encore analyse des logs serveur. Sans cette approche technique, ces mécanismes peuvent rester invisibles tout en influençant fortement la manière dont un site est perçu et indexé par les moteurs de recherche.
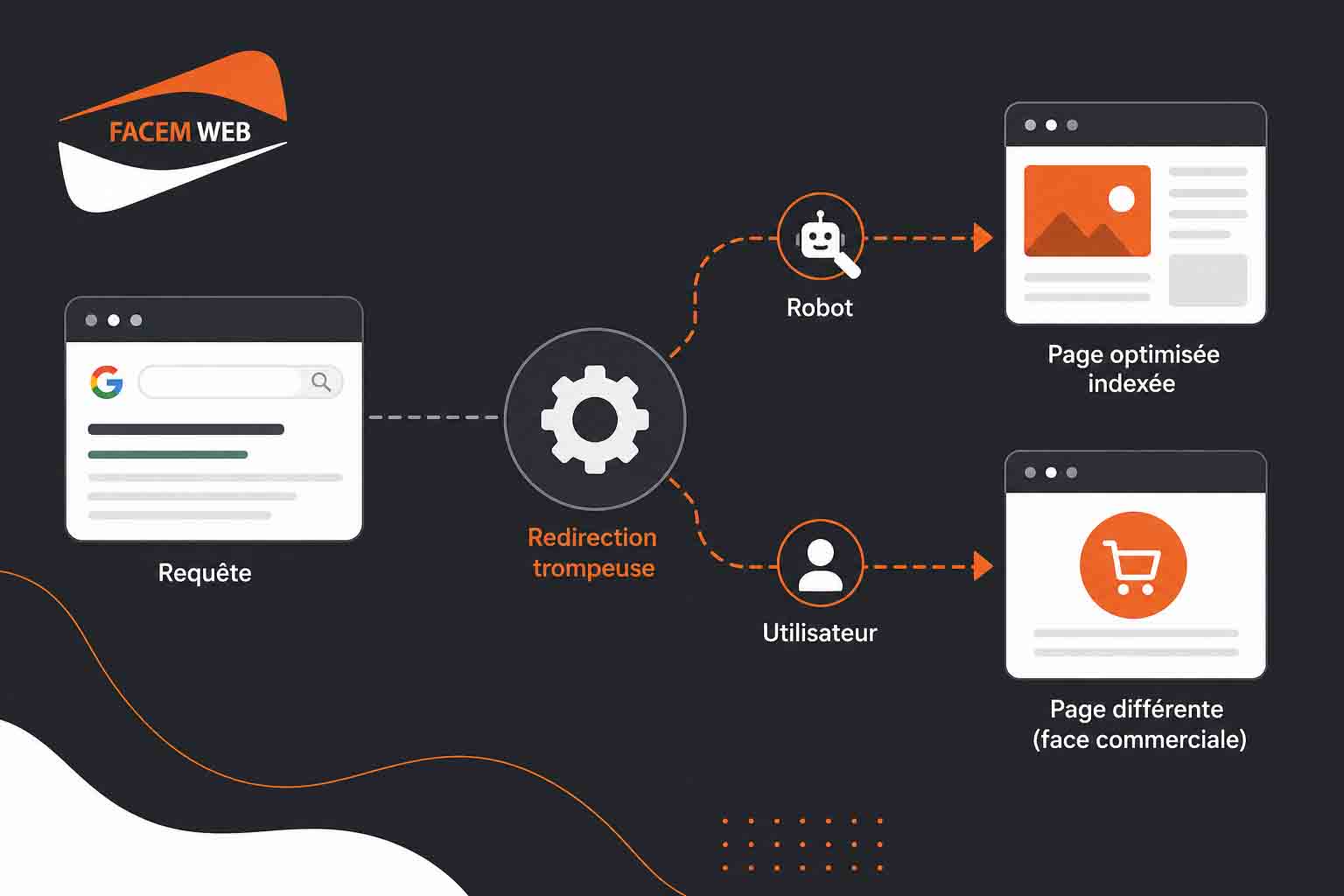
Pourquoi ces redirections trompeuses sont parfois utilisées en SEO
Dans une logique d’optimisation agressive, certaines redirections trompeuses sont utilisées pour capter du trafic, orienter les visiteurs vers des pages plus rentables ou exploiter des écarts entre ce que les moteurs de recherche analysent et ce que les internautes voient réellement. Le principe repose souvent sur une dissociation entre la page pensée pour l’indexation et la page pensée pour la monétisation. Cette pratique s’inscrit dans une logique opportuniste : faire apparaître une URL sur des requêtes intéressantes, puis rediriger une partie du trafic vers une destination jugée plus rentable. Selon le contexte, cela peut concerner des pages affiliées, des tunnels de conversion, des contenus publicitaires, des pages locales ou des contenus difficilement positionnables en référencement naturel classique.
Exploiter le positionnement obtenu sur des mots-clés
L’une des motivations les plus fréquentes consiste à utiliser une page optimisée pour se positionner sur des mots-clés à fort volume de recherche. Cette page peut contenir un contenu informatif, structuré, pertinent en apparence, avec des titres travaillés, un champ lexical riche, des données structurées et une optimisation sémantique poussée. Une fois la page visible dans les résultats de recherche, la redirection intervient pour envoyer l’utilisateur vers une autre URL. Cette destination peut être moins informative, plus commerciale ou totalement différente de l’intention initiale. L’intérêt est de profiter du classement acquis par la première page tout en orientant le trafic vers une page plus rentable. Le problème vient du décalage entre l’intention de recherche et la page finale. L’internaute clique sur un résultat en pensant accéder à une réponse précise, mais il arrive sur une page qui ne correspond pas toujours à sa demande. D’un point de vue SEO, cette méthode cherche à séparer la page qui ranke de la page qui convertit.
Transformer un trafic informationnel en trafic commercial
Les requêtes informationnelles attirent souvent un volume important de visiteurs. Elles sont recherchées, faciles à travailler éditorialement et permettent de capter des internautes en phase de découverte. En revanche, elles ne convertissent pas toujours directement. Certaines redirections trompeuses sont donc utilisées pour transformer ce trafic informationnel en trafic transactionnel. Une page peut se positionner sur une question, une définition, un guide ou un comparatif, puis rediriger l’utilisateur vers une offre, une landing page, un formulaire ou une page d’affiliation. Cette logique est particulièrement visible dans les niches où la valeur commerciale d’un lead est élevée. Le contenu initial sert d’appât sémantique, tandis que la destination finale sert d’outil de monétisation. La redirection devient alors un pont forcé entre une intention de recherche large et une intention commerciale imposée.
Maximiser les revenus publicitaires ou affiliés
Une autre raison fréquente concerne la monétisation. Certains sites utilisent les redirections trompeuses pour envoyer les visiteurs vers des pages contenant davantage de publicités, d’interstitiels, de pop-ups, de liens affiliés ou d’offres sponsorisées.Dans ce cas, l’objectif n’est pas forcément de vendre directement un produit, mais d’augmenter artificiellement la valeur de chaque visite. Plus la page finale est chargée en éléments monétisables, plus le trafic peut générer de revenus à court terme. Ce type de pratique peut aussi être combiné à des systèmes de tracking avancés. Selon la source du trafic, le pays, l’appareil utilisé ou le comportement de l’utilisateur, la redirection peut envoyer vers différentes offres. Un visiteur mobile peut être redirigé vers une page d’abonnement, tandis qu’un visiteur desktop peut rester sur une page éditoriale. Cette segmentation rend la mécanique plus difficile à repérer.
Contourner les contraintes éditoriales ou algorithmiques
Certaines thématiques sont plus difficiles à positionner que d’autres, notamment lorsqu’elles touchent à des secteurs sensibles, fortement concurrentiels ou soumis à une surveillance algorithmique importante. Dans ces cas, les redirections trompeuses peuvent être utilisées pour présenter aux moteurs une version plus acceptable d’un contenu, tout en affichant aux utilisateurs une page plus agressive. Le site peut ainsi proposer aux robots une page propre, informative et conforme en apparence, puis orienter les internautes vers une page plus commerciale, moins qualitative ou plus risquée d’un point de vue SEO. Cette logique cherche à éviter que la page finale soit directement évaluée par les moteurs de recherche. Techniquement, cela peut reposer sur l’analyse du User-Agent, de l’adresse IP, du référent ou de certains signaux de navigation. Le moteur reçoit une version stable, tandis que l’utilisateur réel est traité différemment. C’est précisément cette différence de traitement qui rend la pratique problématique.
Utiliser le cloaking comme levier complémentaire
Les redirections trompeuses sont parfois associées au cloaking. Le cloaking consiste à présenter un contenu différent selon le profil du visiteur : robot d’exploration, utilisateur humain, navigateur mobile, provenance géographique ou source de trafic. Lorsque le cloaking est combiné à une redirection, la mécanique devient plus élaborée. Le moteur peut crawler une page optimisée, tandis que l’utilisateur est envoyé ailleurs. Cette combinaison permet de dissocier trois éléments : l’URL visible dans les résultats, le contenu analysé par le moteur et la destination réelle de l’internaute. Cette approche est utilisée pour masquer la finalité commerciale ou publicitaire d’une page, mais aussi pour tester différentes destinations sans modifier l’URL qui se positionne. Elle permet de conserver une façade SEO stable tout en changeant régulièrement les pages de destination.
Exploiter les domaines expirés et les anciennes URL
Les redirections trompeuses peuvent aussi intervenir dans des stratégies autour des domaines expirés ou des anciennes URL bénéficiant déjà d’un historique SEO. Un domaine récupéré peut disposer de backlinks, d’autorité, d’anciennes pages indexées ou d’un trafic résiduel. Certains acteurs utilisent alors ces actifs pour rediriger les visiteurs vers des pages sans rapport avec le contenu historique du domaine. L’objectif est de récupérer une partie de la popularité, du trafic ou de la confiance accumulée par l’ancien site. Dans une approche légitime, une redirection depuis un ancien domaine doit conserver une cohérence thématique. Dans une approche trompeuse, cette cohérence disparaît : un ancien site éditorial peut rediriger vers une page commerciale, une offre affiliée ou une thématique totalement différente.
Créer des tunnels de redirection complexes
Une redirection trompeuse n’est pas toujours directe. Elle peut passer par plusieurs URL intermédiaires afin de masquer la destination finale, répartir les signaux ou compliquer l’analyse technique. On parle alors de chaînes de redirection. Ces tunnels peuvent intégrer des paramètres UTM, des scripts de tracking, des pages tampon ou des redirections conditionnelles. Selon le profil du visiteur, la chaîne peut s’arrêter à une étape différente ou aboutir à une destination spécifique. Cette complexité permet de rendre le comportement moins évident lors d’un audit rapide. Un crawler classique peut voir une redirection propre, tandis qu’un utilisateur réel, dans un contexte précis, peut être envoyé vers une page différente.
Tester des pages sans exposer directement l’URL principale
Certaines redirections trompeuses sont utilisées pour tester des pages de conversion sans les exposer directement aux moteurs de recherche. L’URL positionnée reste stable, tandis que les destinations finales changent selon les tests marketing. Cette logique peut être utilisée pour comparer plusieurs landing pages, offres, formulaires ou tunnels de vente. En apparence, cela ressemble à de l’optimisation de conversion. Le problème apparaît lorsque la page finale n’a plus de cohérence avec le contenu indexé ou lorsque les moteurs et les utilisateurs ne reçoivent pas la même expérience. La frontière avec un test A/B légitime dépend donc de la transparence, de la cohérence éditoriale et de l’absence de manipulation envers les moteurs de recherche.
Se situer dans une zone grise entre optimisation et manipulation
Toutes les redirections dynamiques ne sont pas en soi trompeuses. Un site multilingue peut rediriger un utilisateur vers la bonne version linguistique. Un site e-commerce peut adapter l’expérience selon le pays, la devise ou la disponibilité des produits. Un site mobile peut orienter vers une version mieux adaptée à l’appareil utilisé. La zone grise apparaît lorsque la redirection sert moins l’utilisateur qu’elle ne sert une logique de manipulation SEO ou commerciale. Si la page finale respecte l’intention de recherche, la redirection peut être défendable. Si elle crée une rupture nette entre la promesse du résultat de recherche et le contenu affiché, elle devient problématique. En résumé, les redirections trompeuses sont parfois utilisées parce qu’elles permettent de séparer artificiellement visibilité, indexation et monétisation. Elles peuvent générer des gains rapides, mais elles reposent sur une mécanique instable : Plus l’écart entre la page indexée et la page affichée est important, plus le risque SEO augmente.

Les risques et conséquences à utiliser des redirections trompeuses pour votre site web
Si les redirections trompeuses peuvent donner l’impression d’offrir un gain rapide en trafic ou en monétisation, elles exposent un site à des conséquences lourdes sur le plan SEO. Les moteurs de recherche cherchent à faire correspondre le résultat affiché, le contenu exploré et l’expérience réelle de l’utilisateur. Lorsqu’une URL présente une version aux robots et une autre aux visiteurs, le signal envoyé devient incohérent. Cette incohérence peut entraîner une perte de confiance algorithmique, une baisse progressive des positions, une action manuelle, voire une désindexation partielle ou totale des pages concernées. Les effets ne se limitent pas au référencement naturel que l’on considèrera ici comme black hat. Une redirection perçue comme abusive dégrade immédiatement l’expérience utilisateur : L’internaute clique sur un résultat avec une attente précise, puis arrive sur une page différente, commerciale, publicitaire ou sans rapport direct avec sa recherche. Cela peut provoquer une hausse du taux de rebond, une baisse du temps passé sur le site, une diminution des interactions et une perte de crédibilité. À moyen terme, ces signaux comportementaux peuvent fragiliser la performance globale du site, surtout si la pratique touche des pages stratégiques générant du trafic qualifié. Sur le plan commercial, le risque est également important. Une redirection mal maîtrisée peut casser un tunnel de conversion, réduire la confiance envers la marque, perturber le suivi analytique et fausser les données de performance. Les rapports SEO, SEA, affiliation ou analytics deviennent moins fiables, car la source, la page d’entrée et la page finale ne racontent plus la même histoire. Pour limiter ces risques, il est préférable d’utiliser des redirections transparentes, cohérentes avec l’intention de recherche et techniquement justifiables, en contrôlant régulièrement les réponses HTTP, les chaînes de redirection, les logs serveur et le comportement réel affiché selon différents profils de navigation :
| Risque identifié | Conséquences possibles pour le site Web |
|---|---|
| Pénalité algorithmique | Le moteur peut réduire la visibilité des pages concernées si la redirection est interprétée comme une tentative de manipulation du classement. |
| Action manuelle | Une intervention humaine peut entraîner une sanction visible dans les outils pour webmasters, avec nécessité de correction puis demande de réexamen. |
| Désindexation partielle | Certaines URL peuvent disparaître des résultats si elles ne correspondent plus au contenu réellement proposé aux utilisateurs. |
| Désindexation totale | Dans les cas les plus graves, l’ensemble du domaine peut perdre sa présence dans les résultats organiques. |
| Perte de positions | Les mots-clés travaillés peuvent reculer progressivement, notamment si le moteur détecte une incohérence entre contenu indexé et destination finale. |
| Perte de confiance algorithmique | Le domaine peut être évalué avec davantage de prudence, ce qui ralentit l’impact des futures optimisations SEO. |
| Déclassement sur des requêtes stratégiques | Les pages les plus importantes peuvent perdre leur visibilité sur des mots-clés à forte valeur, affectant directement le trafic qualifié. |
| Gaspillage du crawl budget | Les robots explorent des redirections inutiles au lieu d’indexer les pages réellement importantes du site. |
| Blocage du crawl | Des redirections mal configurées peuvent empêcher l’accès à certaines صفحات, limitant leur indexation. |
| Chaînes de redirection trop longues | Des redirections successives ralentissent l’accès aux pages et diluent les signaux SEO transmis. |
| Boucles de redirection | Une mauvaise configuration peut créer des boucles infinies, rendant certaines pages totalement inaccessibles. |
| Perte ou dilution du PageRank interne | Une mauvaise correspondance entre URL source et URL cible affaiblit la transmission d’autorité entre les pages. |
| Rupture du maillage interne | Les liens internes peuvent pointer vers des URL redirigées de manière incohérente, réduisant l’efficacité globale du maillage. |
| Incohérence des signaux SEO | Les moteurs reçoivent des informations contradictoires entre contenu indexé, redirections et destination finale. |
| Dégradation de l’expérience utilisateur | L’utilisateur ne trouve pas le contenu attendu, ce qui génère frustration et perte de confiance. |
| Hausse du taux de rebond | Une page finale non pertinente pousse les visiteurs à quitter rapidement le site. |
| Baisse du temps passé sur le site | Le manque de cohérence réduit l’engagement et la consultation d’autres pages. |
| Diminution des pages vues | Les utilisateurs explorent moins le site en raison d’une expérience jugée trompeuse ou peu fiable. |
| Impact négatif sur la conversion | Une redirection inattendue diminue les ventes, leads ou interactions commerciales. |
| Perte de crédibilité de la marque | Le site est perçu comme peu fiable, ce qui peut nuire durablement à son image. |
| Augmentation des signalements utilisateurs | Les visiteurs peuvent signaler le site comme trompeur, ce qui renforce les signaux négatifs envoyés aux moteurs. |
| Données analytics faussées | Les parcours utilisateurs deviennent difficiles à analyser en raison des écarts entre page d’entrée et destination réelle. |
| Attribution marketing perturbée | Les performances des campagnes SEO, SEA ou affiliation deviennent moins fiables et plus difficiles à interpréter. |
| Tracking incomplet ou erroné | Les redirections peuvent casser les balises de suivi ou modifier les sessions utilisateurs. |
| Surveillance renforcée | Le site peut être davantage contrôlé par les moteurs après détection de comportements suspects. |
| Risque de blacklist | Dans certains cas extrêmes, le domaine peut être considéré comme spam et exclu de certains services. |
| Risque de sécurité perçu | Des redirections inattendues peuvent être assimilées à du phishing ou à du contenu compromis. |
| Perte de partenaires commerciaux | Les partenaires peuvent suspendre leur collaboration si le trafic est jugé trompeur ou de mauvaise qualité. |
| Baisse de qualité du trafic | Les visiteurs redirigés ne correspondent pas à l’intention initiale, ce qui réduit leur valeur. |
| Augmentation du taux d’abandon | Les utilisateurs quittent rapidement le site sans interaction en raison d’une mauvaise expérience. |
| Complexification des audits SEO | Les analyses nécessitent des tests avancés (User-Agent, géolocalisation, devices) pour détecter les comportements réels. |
| Maintenance technique alourdie | Les redirections conditionnelles complexes rendent le site plus difficile à maintenir et à faire évoluer. |
| Risque d’erreurs de configuration | Une mauvaise gestion des règles de redirection peut impacter l’ensemble du site et provoquer des dysfonctionnements. |
Voilà, vous savez tout ou presque de la redirection trompeuse. Évitez dans la mesure du possible de l’utiliser…

0 commentaires