À mesure que le web continue de croître à un rythme effréné, comprendre les technologies qui permettent son bon fonctionnement devient un véritable atout. L’un des outils les plus discrets mais essentiels du paysage numérique est le crawler, aussi appelé robot d’indexation ou spider. Derrière ce nom un peu mystérieux se cache une technologie omniprésente qui alimente les moteurs de recherche, les comparateurs de prix ou encore les systèmes de veille automatisée. Dans cet article, étudions en profondeur ce qu’est un crawler, comment il fonctionne et pourquoi il est indispensable au bon référencement des sites web. Que vous soyez un professionnel du numérique, un développeur ou simplement curieux du fonctionnement d’Internet, cette lecture vous apportera les clés pour mieux comprendre les rouages de la navigation automatisée.
Le rôle d’un crawler dans l’écosystème du web
Un crawler, parfois appelé robot d’indexation, spider ou bot, est un programme informatique automatisé dont la mission est d’explorer méthodiquement le contenu d’Internet. Son rôle fondamental est de parcourir les pages web, d’en lire le contenu, d’analyser les liens qu’elles contiennent, puis de suivre ces liens pour découvrir de nouvelles pages. Cette exploration permet de collecter, classer et stocker d’immenses quantités de données, qui sont ensuite utilisées pour créer un index, la base même des moteurs de recherche modernes.
L’histoire des crawlers débute au début des années 1990, à une époque où le web était encore un territoire en friche. Le premier crawler connu est World Wide Web Wanderer, développé en 1993 par Matthew Gray, chercheur au MIT. Ce robot avait pour objectif de mesurer la taille d’Internet. À l’époque, le web ne comptait que quelques centaines de sites, et les enjeux liés à l’indexation restaient marginaux. Très vite, d’autres projets ont vu le jour, comme WebCrawler (créé en 1994), premier moteur de recherche grand public capable d’indexer une page entière, et non seulement les titres. En 1996, les fondateurs de Google, Larry Page et Sergey Brin, mettent au point leur propre crawler, appelé initialement BackRub. Ce robot allait marquer un tournant décisif : non seulement il analysait les pages, mais il évaluait aussi leur pertinence en fonction du nombre et de la qualité des liens entrants. Ce concept, devenu célèbre sous le nom de PageRank, a révolutionné la manière dont les résultats étaient classés.
Un crawler fonctionne donc comme un explorateur numérique, infatigable et méthodique. Lorsqu’un internaute lance une recherche sur Google, Bing ou Qwant, le moteur de recherche ne parcourt pas le web en direct. Il interroge son index, une gigantesque base de données constituée au fil des explorations de ses crawlers. Sans ces robots, les moteurs seraient incapables de proposer des réponses aussi rapides et pertinentes. Le travail des crawlers est d’autant plus stratégique aujourd’hui que le web est devenu tentaculaire : De nos jours, on estime qu’il existe plus de 2 milliards de sites web, et des centaines de milliards de pages. Les robots doivent donc faire preuve d’intelligence dans leur façon de prioriser les contenus à explorer et à indexer. C’est ici qu’intervient la notion de budget de crawl : Chaque site dispose d’un quota de ressources que le moteur lui consacre pour être exploré, en fonction de sa popularité, de sa fréquence de mise à jour et de sa structure technique. Voici les principales missions confiées à un crawler, hier comme aujourd’hui :
- Explorer les pages web : A partir d’une liste initiale d’URL (appelée seed list), le robot visite les pages, analyse leur contenu HTML, et identifie tous les liens internes (menant à d’autres pages du même site) et externes (vers d’autres domaines) ;
- Collecter les données : Le crawler extrait non seulement le texte visible, mais aussi les métadonnées importantes pour le SEO (balises
<title>,<meta description>, balises Hn, attributsalt, etc.) ; - Indexer le contenu : Une fois les informations collectées, elles sont triées et organisées dans une base de données. Cette indexation permet aux moteurs de les retrouver rapidement lorsqu’un internaute tape une requête ;
- Surveiller les changements : Un bon crawler revisite régulièrement les pages pour détecter les modifications, suppressions ou ajouts de contenu, assurant ainsi une fraîcheur maximale de l’index.
Des géants comme Googlebot (Google), Bingbot (Microsoft) ou Baidu Spider (Baidu) sillonnent chaque jour des milliards de pages web à travers le monde. Ils opèrent depuis des centres de données répartis sur tous les continents : de Mountain View en Californie à Singapour, en passant par Dublin et Francfort. Ces infrastructures colossales permettent de faire tourner des milliers de serveurs, chacun dédié à une tâche spécifique du crawling.
Mais tous les crawlers ne servent pas à des moteurs de recherche. Certains, comme Screaming Frog ou Sitebulb, sont utilisés en SEO technique pour auditer les sites web, repérer les erreurs de structure ou les problèmes d’indexation. D’autres, comme ceux développés en interne par des entreprises, permettent de surveiller les prix, extraire des données produits ou faire de la veille concurrentielle. Enfin, il est important de noter que le comportement des crawlers est encadré : les propriétaires de sites peuvent contrôler leur accès via le fichier robots.txt, ou encore à l’aide de balises spécifiques comme <meta name="robots" content="noindex">. Certains protocoles plus avancés comme sitemap.xml permettent aussi d’orienter les robots vers les pages à privilégier.
Comment fonctionne un crawler : Les étapes et technologies utilisées
Le fonctionnement d’un crawler repose sur une architecture complexe, conçue pour répondre à la nécessité d’explorer rapidement, efficacement et en continu l’immense volume d’informations disponibles sur le web. Ce processus s’appuie sur des mécanismes distribués, des algorithmes de sélection de liens, des systèmes de gestion de files d’attente, et une infrastructure capable de résister à des charges massives tout en restant réactive. La première étape du crawling commence avec ce qu’on appelle une seed list : un ensemble d’URL de départ jugées pertinentes ou stratégiques. Ces URL peuvent provenir de différentes sources, comme des sitemaps XML soumis par les webmasters, des bases de données internes ou des liens récupérés lors de précédents crawlings. Une fois ces adresses identifiées, le robot démarre son cycle d’exploration.
Contrairement à une idée reçue, le processus n’est pas linéaire. Il repose sur une boucle asynchrone, souvent pilotée par une architecture distribuée de type MapReduce ou microservices. Un composant du système est chargé d’envoyer des requêtes HTTP GET à chaque URL, simulant le comportement d’un navigateur. Le robot reçoit en retour le code HTML de la page, parfois accompagné de ressources complémentaires (CSS, JavaScript, images, etc.) en fonction de la configuration du crawler (mode texte ou mode navigateur complet, comme dans le cas de Puppeteer ou Playwright). Une fois le contenu récupéré, entre en jeu le module d’analyse syntaxique, ou parser. Il extrait les éléments structurants : balises <title>, <meta name="description">, titres hiérarchiques H1 à H6, liens hypertextes, attributs alt des images, texte visible, mais aussi scripts embarqués et données structurées (comme le JSON-LD ou le microdata). Dans certains cas, le crawler est aussi équipé pour exécuter du JavaScript et interpréter des contenus dynamiques, notamment sur des sites développés en Single Page Application (SPA).
Chaque lien extrait est analysé : il peut être immédiatement mis en file d’attente pour un crawl futur, mis de côté (s’il est interdit par le robots.txt) ou enrichi avec des métadonnées (comme sa profondeur dans la structure du site, son importance relative ou sa fréquence de mise à jour). Le scheduler (ou planificateur) priorise ensuite les prochaines URL à explorer en fonction d’algorithmes spécifiques. Ceux-ci prennent en compte le PageRank, la fraîcheur du contenu, les performances du serveur distant, ou encore la fréquence de modification historique de la page. Les robots sont aussi conçus pour limiter leur impact sur les serveurs visités. Ils utilisent des mécanismes de throttling (ralentissement automatique) et respectent les indications contenues dans les en-têtes HTTP comme Crawl-Delay. Dans des systèmes plus avancés, le crawler peut également gérer des sessions d’authentification, des cookies ou des headers personnalisés, afin d’explorer des zones protégées ou dynamiques.
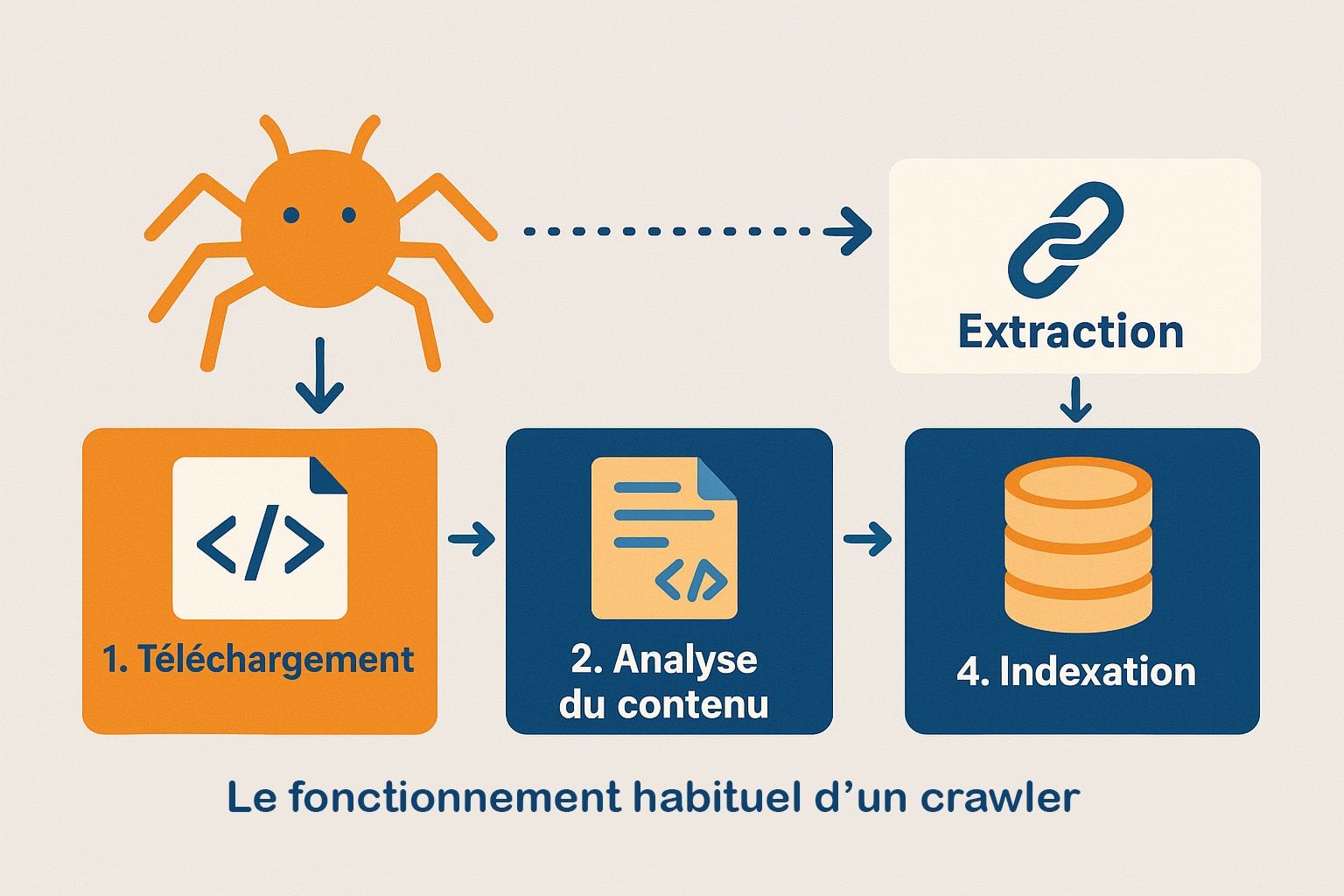
Voici un schéma simplifié du fonctionnement d’un crawler :
| Étape | Description |
|---|---|
| 1. Téléchargement | Le crawler envoie une requête HTTP pour récupérer le code source de la page web. |
| 2. Analyse du contenu | Le HTML est parsé pour identifier les textes, balises, liens et données structurées. |
| 3. Extraction des liens | Les URLs détectées sont filtrées, classées et ajoutées à une file d’attente priorisée. |
| 4. Indexation | Le contenu pertinent est structuré et stocké dans une base de données pour la recherche. |
| 5. Vérification de mise à jour | Les anciennes pages sont revisitées à intervalles définis pour détecter les changements. |
Le cœur du système repose souvent sur une pile technologique modulaire et évolutive. Voici les principaux composants et outils utilisés :
- Les bibliothèques de crawling : Scrapy (Python), BeautifulSoup (Python), Cheerio (JavaScript), Puppeteer ou Playwright pour simuler des navigateurs ;
- Les langages de programmation : Python pour sa rapidité de prototypage, Java pour la robustesse, ou Node.js pour l’asynchrone natif ;
- Les files d’attente distribuées : Apache Kafka, RabbitMQ, Amazon SQS ou Redis Streams, pour gérer les millions d’URL à traiter ;
- Les bases de données d’indexation : Elasticsearch, Solr ou Bigtable, selon les besoins en recherche plein texte, scalabilité ou tolérance aux pannes ;
- Les systèmes de stockage : HDFS (Hadoop Distributed File System), Google Cloud Storage, S3 d’AWS pour archiver les pages brutes ou analysées ;
- Les planificateurs intelligents : algorithmes propriétaires intégrant des logiques d’apprentissage automatique pour optimiser le parcours de crawling selon les performances et l’évolution du web cible.
Le contrôle des accès est également un point clé. Les sites web peuvent définir les règles d’exploration via le fichier robots.txt, situé à la racine du domaine. Ce fichier texte simple autorise ou interdit certains crawlers, spécifie les chemins à exclure, et indique le lien vers un éventuel sitemap.xml. Parallèlement, les balises <meta name="robots"> permettent d’affiner le comportement robotique page par page, en interdisant par exemple l’indexation ou le suivi des liens (noindex, nofollow). Les crawlers modernes doivent aussi s’adapter à des défis nouveaux, tels que l’explosion des contenus multimédias, l’intégration croissante de données en temps réel (tweets, prix, disponibilités produits), ou encore les restrictions liées à la vie privée (RGPD, cookie walls, authentification OAuth). Pour y faire face, les éditeurs de crawlers incorporent de plus en plus des modules de reconnaissance visuelle (computer vision), d’analyse de scripts tiers, et même des modèles d’IA générative pour résumer ou classifier les contenus en temps réel.
Ainsi, derrière le fonctionnement apparemment simple d’un robot qui « parcourt le web« , se cache un écosystème technique avancé, évolutif et résolument tourné vers la performance, la qualité des données et le respect des contraintes imposées par les éditeurs de contenu. Le crawling, loin d’être une tâche brute, est aujourd’hui une science d’optimisation algorithmique, à l’intersection de l’ingénierie logicielle, du traitement de l’information et de l’éthique numérique.
Les types de crawlers et leurs usages
Les crawlers ne se limitent pas à une seule fonction ou une seule catégorie d’outils. Il en existe une diversité importante, chacun conçu pour répondre à un objectif précis, avec des niveaux de sophistication variables. Ces robots ne sont pas uniquement le domaine réservé des moteurs de recherche : de nombreuses entreprises, institutions, chercheurs et développeurs indépendants les utilisent pour collecter, surveiller ou auditer des données sur le web. Voici un panorama des principaux types de crawlers et de leurs usages concrets dans différents contextes :
- Crawlers des moteurs de recherche : Ce sont les plus connus et les plus puissants. Googlebot, Bingbot, Baidu Spider ou YandexBot ont pour mission de parcourir le web mondial pour alimenter les index des moteurs de recherche. Ils fonctionnent en continu, à grande échelle, avec des architectures distribuées réparties dans plusieurs centres de données. Leur objectif est d’offrir une couverture aussi exhaustive que possible, tout en respectant les contraintes techniques des sites visités. Ils utilisent des algorithmes avancés de sélection de liens, des systèmes de priorisation, et s’adaptent automatiquement à la performance des serveurs cibles ;
- Crawlers d’audit SEO : Ces outils sont utilisés par les experts en référencement naturel pour analyser la santé technique d’un site. Des logiciels comme Screaming Frog, Oncrawl, Sitebulb ou SEMrush Site Audit permettent d’identifier des problèmes structurels : balises manquantes ou dupliquées, erreurs HTTP (404, 500…), mauvaise hiérarchie des titres, liens cassés, redirections mal configurées, vitesse de chargement des pages, ou encore analyse du budget de crawl. Ces crawlers sont généralement configurables, et peuvent fonctionner en local ou via le cloud ;
- Crawlers de veille : Également appelés crawlers de surveillance ou de monitoring, ils sont conçus pour détecter les changements sur des pages web ou des portions de site précises. Cela peut concerner l’évolution d’un prix, l’ajout de nouveaux produits, la publication d’un article, ou la mise à jour d’une condition juridique. Ces outils sont utilisés dans des domaines variés comme la veille concurrentielle, le e-commerce, le juridique, ou même la cybersécurité. Leur efficacité repose souvent sur une fréquence de crawling personnalisée et une capacité à détecter des différences entre deux versions d’un même contenu ;
- Crawlers d’extraction de données (web scraping) : Leur objectif est de collecter des données structurées à partir de pages web, souvent dans le but de les réutiliser dans un autre environnement (base de données, tableau de bord, intelligence artificielle). Ces crawlers sont programmés pour extraire des informations précises comme des noms de produits, des prix, des avis, des horaires, ou encore des coordonnées. Ils sont utilisés par des comparateurs de prix, des marketplaces, des portails immobiliers, ou encore des plateformes d’analyse de tendances. Certains d’entre eux s’appuient sur des frameworks de scraping comme Scrapy, Octoparse ou ParseHub ;
- Crawlers scientifiques et institutionnels : Moins connus du grand public, ces robots sont développés par des centres de recherche, des universités ou des bibliothèques numériques pour collecter des corpus à des fins d’analyse sémantique, de veille documentaire ou de préservation du patrimoine numérique. Le projet Common Crawl, par exemple, fournit des archives web massives à la communauté scientifique pour entraîner des modèles de traitement du langage naturel ;
- Crawlers orientés IA : Avec l’émergence des modèles de langage et des systèmes d’apprentissage machine, certains crawlers sont spécifiquement conçus pour extraire des textes et des documents pertinents servant à l’entraînement ou à la mise à jour de corpus d’intelligence artificielle. Ces crawlers sont particulièrement vigilants aux licences d’utilisation des contenus collectés (open source, Creative Commons, domaine public…).
Le choix du type de crawler dépend des objectifs poursuivis, mais aussi des contraintes techniques et éthiques. Certains crawlers sont extrêmement légers : ils n’explorent qu’un nombre limité de pages, sans exécuter de JavaScript, et se concentrent uniquement sur des balises HTML spécifiques. À l’inverse, d’autres sont capables de simuler un navigateur complet grâce à des outils comme Puppeteer ou Selenium. Ils peuvent gérer des sessions utilisateurs, interagir avec des formulaires ou exécuter des scripts JavaScript complexes, ce qui les rend indispensables pour crawler des sites modernes reposant sur des technologies SPA (Single Page Application).
Il convient aussi de prendre en compte l’impact des crawlers sur les serveurs visités. Un crawler mal configuré peut envoyer des centaines de requêtes en quelques secondes, surchargeant l’hébergement d’un site fragile. C’est pourquoi de nombreuses plateformes mettent en place des protections : limites de débit (rate limiting), détection d’IP suspectes, challenges CAPTCHA ou blocage via robots.txt. Les crawlers professionnels doivent donc intégrer des mécanismes de respect des bonnes pratiques : limitation de fréquence (throttling), respect des consignes de robots.txt, gestion des redirections, traitement des erreurs HTTP, et surtout respect des conditions d’utilisation des sites web ciblés.
Dans le cadre légal, certains usages du crawling peuvent aussi soulever des questions. En Europe, le RGPD encadre l’extraction de données personnelles. Aux États-Unis, des affaires judiciaires comme hiQ Labs vs. LinkedIn ont montré que l’accès automatisé à des plateformes peut être contesté en justice, même si les données sont accessibles publiquement. Il est donc primordial d’associer au crawling une analyse juridique préalable, en particulier lorsqu’il s’agit de projets commerciaux ou à grande échelle.

0 commentaires