Une application web ou un service en ligne peut fonctionner parfaitement avec quelques dizaines d’utilisateurs, mais que se passe-t-il quand ce chiffre grimpe à plusieurs milliers, voire des millions ? C’est là que la scalabilité entre en jeu. Ce concept, central dans le domaine du cloud computing, permet à une infrastructure informatique de s’adapter dynamiquement à la charge de travail. Mais que signifie exactement « être scalable » ? Quels en sont les principes fondamentaux, et comment les entreprises peuvent-elles tirer parti de cette capacité d’adaptation ? Plongeons dans l’univers de la scalabilité pour mieux comprendre ses enjeux techniques et stratégiques.
La définition de la scalabilité dans le cloud computing
La scalabilité, ou « scalability » en anglais, est la capacité d’un système informatique à s’adapter à l’évolution de la charge de travail, que cette charge soit croissante ou décroissante, tout en maintenant un niveau de performance optimal. En d’autres termes, un système scalable est capable de continuer à fonctionner efficacement, même lorsque le nombre d’utilisateurs, les requêtes ou les volumes de données augmentent de manière significative. Dans le contexte du cloud computing, ce concept prend tout son sens. Grâce à la virtualisation des ressources, les infrastructures cloud sont conçues pour être élastiques : elles peuvent évoluer dynamiquement, automatiquement et à la demande, en fonction de la pression exercée sur le système. Le cloud permet ainsi de dimensionner les ressources informatiques en temps réel, sans intervention humaine lourde ni redéploiement coûteux.
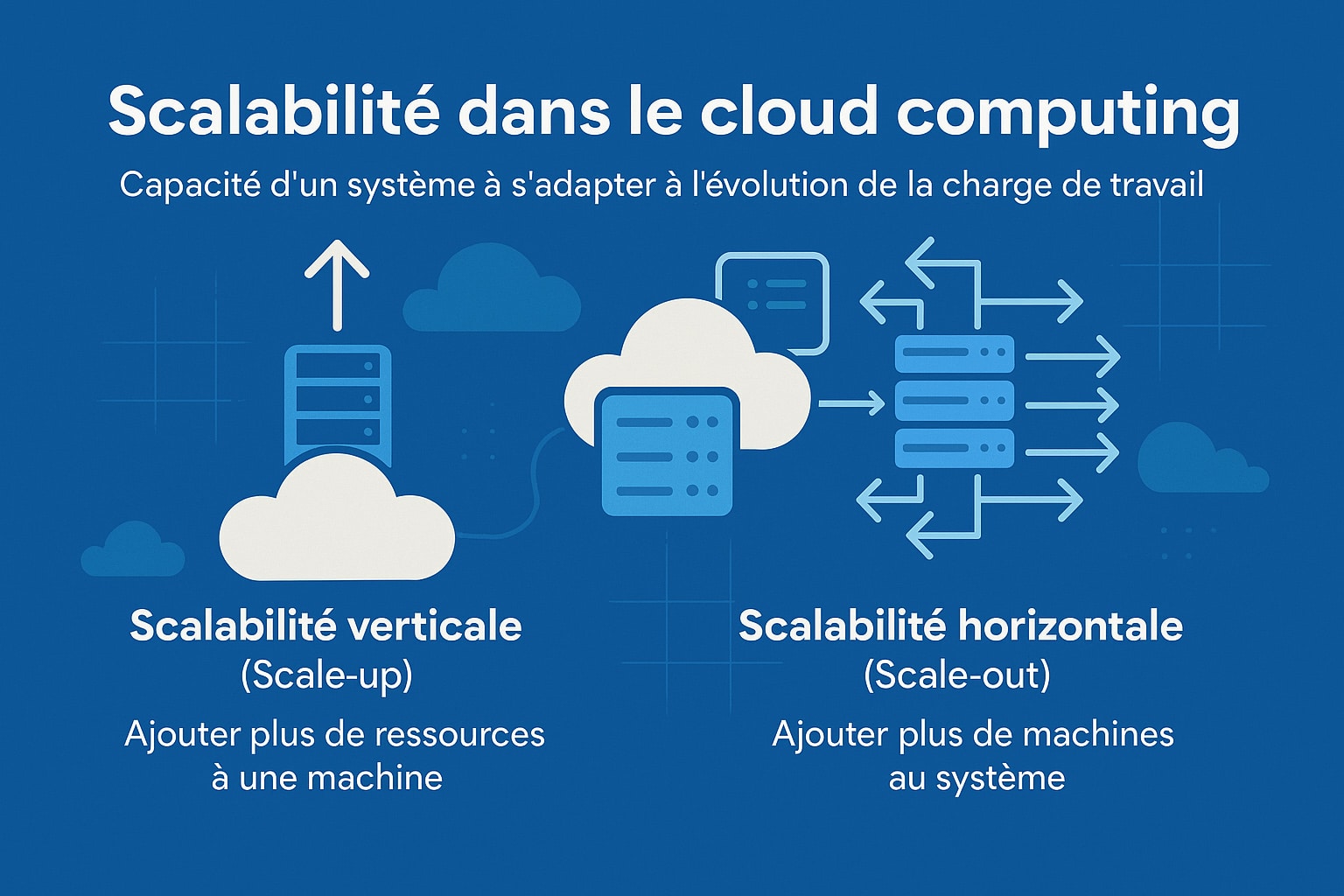
Contrairement aux infrastructures traditionnelles basées sur des serveurs physiques fixes, qui nécessitent souvent un surdimensionnement préventif (et donc un gaspillage de ressources en période creuse), le cloud offre une approche beaucoup plus agile. Il devient possible d’ajuster les capacités en fonction des besoins réels du moment, ce qui permet d’optimiser à la fois les performances et les coûts. On parle alors de scalabilité flexible, rapide et économique. Il existe principalement deux types de scalabilité, chacun avec ses caractéristiques propres :
- La scalabilité verticale (scale-up) : Cette approche consiste à augmenter la puissance d’une instance unique en lui ajoutant davantage de ressources matérielles, telles que de la mémoire RAM, des processeurs (CPU) plus performants, ou un stockage plus rapide (SSD, NVMe). Elle est généralement plus simple et rapide à mettre en œuvre, notamment dans des environnements virtualisés ou sur des machines cloud configurables à la volée. Toutefois, cette méthode atteint rapidement ses limites physiques : chaque machine a un plafond de capacité qu’il n’est pas toujours possible de dépasser. En outre, elle introduit un point de défaillance unique (single point of failure), car toute l’application repose sur un seul nœud, ce qui peut nuire à la disponibilité et à la résilience du système ;
- La scalabilité horizontale (scale-out) : Cette méthode repose sur l’ajout de nouvelles instances ou machines virtuelles dans l’infrastructure pour répartir uniformément la charge de travail. Plutôt que de surcharger un seul serveur, on déploie plusieurs nœuds identiques ou spécialisés, souvent orchestrés derrière un répartiteur de charge (load balancer) capable de distribuer les requêtes selon la charge ou la disponibilité. Cette stratégie est plus complexe à concevoir et à maintenir (elle nécessite notamment de veiller à la statelessness des services et à la cohérence des données partagées) mais elle est bien plus flexible à grande échelle. Elle est particulièrement adaptée aux architectures distribuées, comme les microservices ou les conteneurs orchestrés par Kubernetes, et constitue le fondement de l’élasticité dans les environnements cloud modernes.
Dans la pratique, ces deux formes de scalabilité ne s’opposent pas mais se complètent. Une application cloud bien conçue peut tirer parti des deux, en fonction du type de ressource à faire évoluer (base de données, backend, frontend, etc.). Par exemple, on pourra faire évoluer verticalement une base de données relationnelle tout en augmentant horizontalement les instances applicatives pendant un pic de trafic.
Les principes techniques de la scalabilité dans le cloud computing
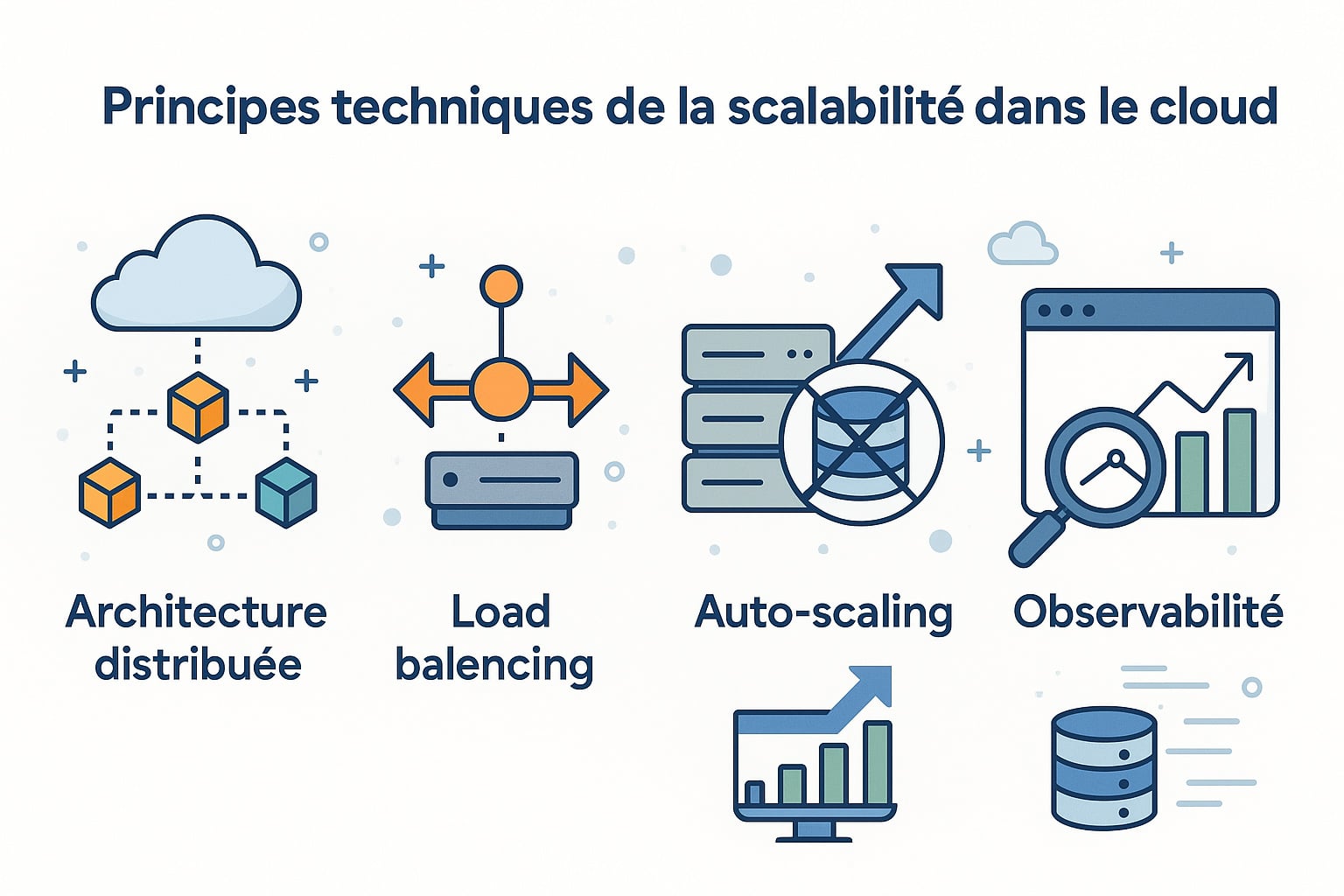
Pour qu’un système soit réellement scalable dans un environnement cloud, il ne suffit pas d’ajouter des ressources de manière brute. Il faut concevoir l’architecture et l’infrastructure dès le départ selon des principes techniques spécifiques, qui garantissent la capacité du système à évoluer dynamiquement, sans interruption de service ni dégradation des performances. Ces principes concernent aussi bien l’organisation logicielle que la gestion opérationnelle de l’infrastructure. Voici les fondations techniques essentielles à mettre en place pour assurer une scalabilité efficace et durable :
| Principe | Description |
|---|---|
| Architecture distribuée | Concevoir l’application sous forme de services découplés (microservices, conteneurs, fonctions serverless) permet de faire évoluer chaque composant indépendamment, sans impacter le reste du système. Chaque module (authentification, paiement, recherche, etc.) peut être déployé sur des nœuds dédiés et mis à l’échelle selon ses propres besoins. Cette approche favorise la résilience, la maintenance et le déploiement continu. Elle repose sur des protocoles de communication légers comme REST, gRPC ou AMQP, un système de routage distribué, et des mécanismes de tolérance aux pannes (timeouts, retries, circuit breakers) pour assurer la stabilité en cas de défaillance partielle. |
| Load balancing | L’utilisation d’équilibreurs de charge (tels que AWS Elastic Load Balancer, HAProxy, NGINX ou Traefik) permet de répartir automatiquement les requêtes entrantes entre plusieurs instances de services ou de serveurs backend. Le load balancing évite les saturations, améliore la répartition des ressources, et garantit une haute disponibilité. Il peut utiliser divers algorithmes (round robin, IP hash, least connections, weighted routing) et être combiné à des sondes de santé (health checks) pour ne rediriger les flux que vers les instances en bon état de fonctionnement. |
| Statelessness | Une application conçue selon le principe de statelessness ne stocke aucune donnée d’état (session, contexte, utilisateur) localement. Chaque requête est traitée de manière indépendante, ce qui permet d’ajouter ou de supprimer des instances de manière transparente, sans affecter l’expérience utilisateur. Les données d’état sont externalisées via des services dédiés comme Redis pour les sessions, RabbitMQ ou Kafka pour les files de messages, et des bases de données centralisées. Ce modèle est particulièrement adapté aux environnements cloud distribués où l’élasticité est une exigence de base. |
| Auto-scaling | Mettre en place des politiques d’auto-scaling permet d’adapter dynamiquement la capacité de l’infrastructure en fonction de la charge, sans intervention humaine. Ces mécanismes se basent sur des métriques précises (CPU, mémoire, requêtes par seconde, latence, etc.) pour déclencher la création ou la suppression d’instances. Des services comme AWS Auto Scaling, Azure VMSS, Google Cloud Autoscaler, ou Kubernetes HPA/VPA permettent d’ajuster en temps réel la puissance de calcul disponible. Cela garantit une performance constante tout en optimisant les coûts opérationnels. |
| Observabilité | Une scalabilité efficace dépend d’une observabilité approfondie. Il s’agit de collecter, visualiser et analyser des données temps réel sur le comportement du système. Cela inclut la surveillance des métriques (CPU, mémoire, trafic, erreurs), la centralisation des logs, et le traçage distribué des appels entre microservices. Des outils comme Prometheus (monitoring), Grafana (dashboards), Datadog, New Relic, ELK Stack (ElasticSearch, Logstash, Kibana), ou OpenTelemetry permettent de détecter les anomalies, anticiper les pics de charge, et ajuster les ressources de manière proactive. |
| Infrastructure as Code (IaC) | L’Infrastructure as Code (IaC) permet de gérer, déployer et versionner l’ensemble de l’infrastructure via du code déclaratif ou impératif. Des outils comme Terraform (multi-cloud), AWS CloudFormation, Pulumi ou Ansible permettent d’automatiser la création de ressources (VM, load balancers, bases de données, réseaux, etc.), de faciliter les tests d’infrastructure, et de reproduire rapidement un environnement de développement, de test ou de production. En intégrant l’IaC dans les pipelines CI/CD, les équipes DevOps peuvent répondre rapidement aux besoins de scalabilité, tout en assurant la cohérence et la traçabilité des déploiements. |
Ces principes sont à la base du paradigme cloud natif, où les applications sont pensées dès le départ pour être résilientes, déployables à grande échelle, et agiles face aux variations de charge. L’objectif est double : Garantir la performance de l’application, quelles que soient les conditions, et optimiser les coûts en adaptant dynamiquement les ressources à la demande réelle.
Une bonne stratégie de scalabilité repose donc sur une combinaison équilibrée entre architecture logicielle, gestion de l’infrastructure et mise en place d’outils de supervision. Lorsqu’elle est bien maîtrisée, elle devient un levier puissant pour soutenir la croissance, améliorer la disponibilité, et accélérer la mise en production de nouvelles fonctionnalités.
Les avantages de la scalabilité du cloud computing pour les entreprises
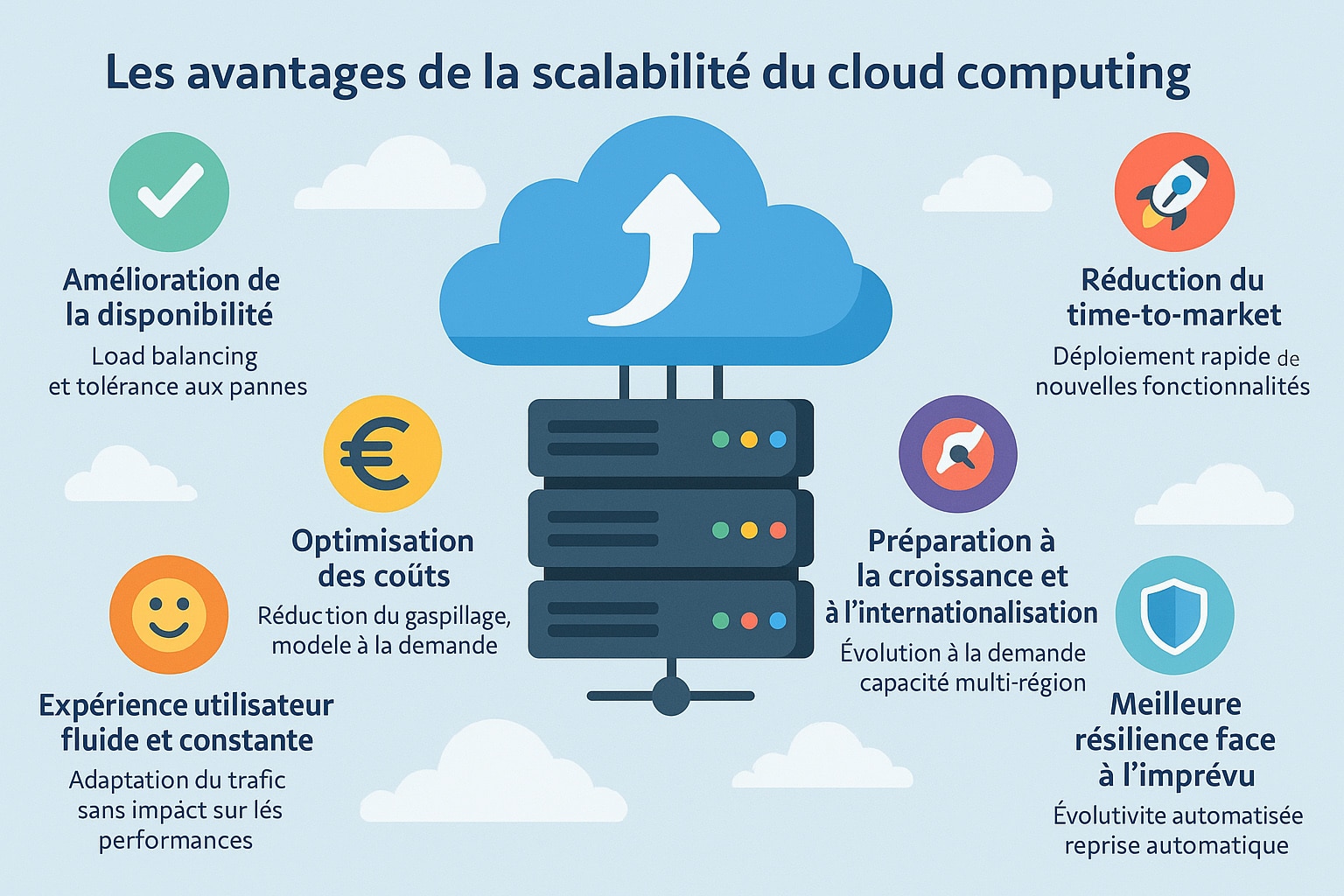
Adopter une stratégie de scalabilité cloud (contrôlée notamment par un architecte cybersécurité) permet aux entreprises, quel que soit leur secteur ou leur taille, de répondre plus efficacement aux exigences techniques, économiques et stratégiques d’un environnement numérique en constante évolution. Que ce soit pour faire face à une hausse soudaine de trafic, pour optimiser les investissements IT, ou pour soutenir la croissance de leur activité, les bénéfices de la scalabilité sont nombreux et directement mesurables. Voici les principaux avantages que les entreprises peuvent retirer d’une infrastructure cloud scalable :
- Amélioration de la disponibilité : En multipliant les points de déploiement et en répartissant intelligemment la charge via des mécanismes de load balancing (tels que les équilibreurs de charge applicatifs ou réseau), les systèmes scalables réduisent drastiquement le risque de panne ou d’interruption de service. Même en cas de défaillance matérielle ou logicielle sur une instance, d’autres ressources prennent automatiquement le relais grâce à une architecture redondante. Cette tolérance aux pannes, renforcée par des stratégies de réplication et de failover, assure une haute disponibilité (HA), essentielle pour les applications critiques comme les services bancaires, les plateformes e-commerce ou les outils SaaS professionnels ;
- Optimisation des coûts : Avec la scalabilité dynamique, les ressources sont provisionnées à la demande selon des seuils précis de consommation (CPU, mémoire, nombre de connexions, etc.). Cela signifie que l’entreprise ne paie que pour ce qui est réellement utilisé, selon un modèle à la consommation (« pay-as-you-go » ou « on-demand pricing »). Cette approche élimine le gaspillage lié aux infrastructures surdimensionnées en basse saison ou inutilisées en période creuse. Elle est particulièrement pertinente pour les start-ups, les sites événementiels, ou les plateformes à trafic irrégulier, qui peuvent ainsi maîtriser leurs dépenses sans compromettre les performances ;
- Réduction du time-to-market : Une infrastructure scalable permet de raccourcir significativement les cycles de développement et de déploiement. Les nouvelles fonctionnalités, services ou correctifs peuvent être lancés rapidement grâce à des environnements de test et de production provisionnés automatiquement. En intégrant des pipelines CI/CD, de l’Infrastructure as Code (IaC) et des conteneurs (Docker, Kubernetes), les équipes DevOps bénéficient d’une agilité accrue. Cela permet de passer plus rapidement du prototype au produit final, avec des itérations fréquentes, des tests automatisés, et une mise en production sans coupure de service ;
- Expérience utilisateur fluide et constante : La capacité à absorber instantanément des hausses de trafic sans compromettre la vitesse ou la stabilité est un avantage majeur pour les applications orientées client. Lors de pics de charge — comme un lancement de produit, une campagne promotionnelle, ou une diffusion en direct —, l’infrastructure s’ajuste automatiquement pour maintenir des temps de réponse optimaux. Cela évite les latences, les erreurs 500, ou les ralentissements qui nuisent à la navigation. Une expérience fluide renforce la confiance, réduit les taux de rebond et améliore les conversions, notamment sur mobile où l’instantanéité est attendue ;
- Préparation à la croissance et à l’internationalisation : Une entreprise en phase de croissance rapide peut se heurter à des limites d’infrastructure si celle-ci n’est pas conçue pour évoluer. Grâce à la scalabilité, elle peut absorber sans interruption un volume croissant d’utilisateurs, de requêtes et de données. De plus, les plateformes cloud permettent de déployer des ressources dans plusieurs zones géographiques (multi-région ou multi-zone), réduisant ainsi la latence pour les utilisateurs situés à l’étranger. Cette flexibilité est essentielle pour les entreprises souhaitant se déployer à l’échelle mondiale tout en respectant les exigences de conformité locale (RGPD, souveraineté des données, etc.) ;
- Meilleure résilience face à l’imprévu : La scalabilité, lorsqu’elle est couplée à des systèmes d’auto-healing, de redondance et de supervision proactive, permet de gérer automatiquement les imprévus sans intervention humaine. Qu’il s’agisse d’un pic de charge soudain, d’une défaillance matérielle ou d’un bug applicatif, le système peut se reconfigurer en temps réel, relancer les services affectés ou répliquer les données vers une instance saine. Cela limite l’impact des incidents, garantit une continuité d’activité et réduit les coûts liés aux interruptions non planifiées.
À l’heure où la transformation numérique devient incontournable, la scalabilité s’impose comme un levier stratégique. Elle ne se contente pas de soutenir la croissance technique d’un système : elle libère aussi l’innovation, accélère les cycles de développement, et offre un avantage concurrentiel durable. En misant sur une architecture cloud pensée pour évoluer, les entreprises se donnent les moyens de répondre efficacement aux défis de demain, tout en gardant la maîtrise de leurs coûts et en garantissant une qualité de service constante à leurs utilisateurs.

0 commentaires