Lorsque vous tapez une question dans un moteur de recherche, que vous parlez à un assistant vocal ou que vous échangez avec un chatbot, vous interagissez probablement avec ce qu’on appelle un modèle de langage. Ce terme, de plus en plus répandu dans les discussions sur l’intelligence artificielle, recouvre une réalité technique aussi fascinante que complexe. Mais que désigne-t-on exactement par « modèle de langage » ? Quelle est son origine, comment fonctionne-t-il et pourquoi est-il aujourd’hui au cœur de nombreuses applications numériques ? Plongeons dans l’univers de ces systèmes qui apprennent à comprendre, traiter et générer du langage humain.
Comprendre la définition d’un modèle de langage, en remontant à ses origines
Un modèle de langage est un système informatique capable d’analyser, de comprendre ou de générer des textes en langage naturel, c’est-à-dire le langage tel qu’il est utilisé par les humains dans leur vie quotidienne. Techniquement, il s’agit d’un modèle statistique ou neuronal qui attribue une probabilité à chaque mot ou séquence de mots en fonction de leur contexte. Cela permet, par exemple, de compléter automatiquement une phrase, de corriger une faute ou de produire un texte entier de manière autonome. Pour comprendre comment ces modèles ont émergé, il faut remonter à plusieurs décennies en arrière. Bien avant que l’intelligence artificielle moderne ne s’en empare, l’idée d’un système capable de traiter le langage humain de manière automatisée intéressait déjà les chercheurs en mathématiques, en logique et en linguistique. L’histoire commence dès les années 1940, dans les laboratoires de cryptographie de la Seconde Guerre mondiale, où des figures comme Alan Turing posent les bases de la réflexion computationnelle sur le langage.
Dans les années 1950, à Bell Labs (États-Unis), Claude Shannon révolutionne l’approche du langage avec sa théorie de l’information. Il propose d’analyser les mots et les lettres non pas selon leur signification mais selon leur fréquence et leur probabilité d’apparition. Ce regard statistique sur le langage marque un tournant fondamental : il devient alors possible d’anticiper les unités suivantes d’un texte en étudiant les séquences précédentes. C’est la naissance implicite des premiers modèles de langage probabilistes. En 1957, Noam Chomsky publie Syntactic Structures au MIT, où il introduit la grammaire générative, un modèle formel qui influencera profondément la linguistique informatique. Chomsky défend une approche plus logique et symbolique du langage, en opposition à la vision purement statistique de Shannon. Ce clivage entre symbolisme et empirisme nourrira les débats scientifiques pendant plusieurs décennies.
Durant les années 1960-1970, des projets pionniers comme ELIZA (créé par Joseph Weizenbaum au MIT en 1966) simulent pour la première fois un dialogue en langage naturel avec un humain. ELIZA fonctionne selon des règles simples de correspondance de mots, mais démontre déjà qu’un système peut donner l’illusion d’un échange linguistique, même sans véritable compréhension. Dans les années 1980, les premiers véritables modèles de langage voient le jour, notamment avec l’approche des n-grammes, qui analysent les probabilités d’un mot en fonction des « n » mots précédents. Ces modèles sont simples à mettre en œuvre et très efficaces pour des applications pratiques comme la correction orthographique (déployée notamment par Microsoft dans Word dès les années 1990), ou les premiers traducteurs automatiques. IBM joue alors un rôle central dans le développement de ces outils à travers ses travaux sur la traduction probabiliste.
Le tournant majeur a lieu dans les années 2000 avec l’essor du machine learning. À Stanford, à Toronto, au MIT ou à Cambridge, les chercheurs conçoivent de nouveaux modèles capables d’apprendre à partir de données, plutôt que d’être programmés manuellement. Des personnalités comme Christopher Manning (Stanford NLP Group) ou Yoshua Bengio (Université de Montréal) contribuent à ce mouvement qui place l’apprentissage automatique au cœur des modèles de langage. On assiste alors à l’émergence de modèles plus souples, capables d’interpréter le contexte sur des séquences plus longues qu’auparavant. Dans les années 2010, avec la montée en puissance du deep learning, les modèles de langage deviennent capables d’apprendre des représentations linguistiques riches et abstraites. Les architectures de type RNN (réseaux de neurones récurrents), puis LSTM et GRU, permettent de prendre en compte la mémoire à court et long terme dans les phrases. C’est à ce moment que les modèles comme Word2Vec (introduit par Google en 2013) ou GloVe (par Stanford) révolutionnent la manière dont les mots sont représentés : non plus comme des entités isolées, mais comme des vecteurs dans un espace sémantique.
L’année 2017 marque une rupture définitive dans cette histoire avec la publication par Google Brain du célèbre article “Attention is All You Need”, dans lequel est introduite l’architecture Transformer. Cette innovation permet de traiter des séquences de texte entières en parallèle, plutôt que mot à mot comme dans les RNN. Elle améliore drastiquement les performances, l’efficacité d’apprentissage et la capacité à capturer les dépendances longues dans le texte.
À partir de ce socle technique, des modèles comme GPT (OpenAI), BERT (Google), RoBERTa (Meta AI), T5 (Google) ou XLNet voient le jour entre 2018 et 2021. Ces modèles sont entraînés sur des corpus immenses (jusqu’à plusieurs centaines de milliards de mots) et capables de générer du texte fluide, de répondre à des questions, de traduire, résumer, reformuler ou même coder.
En France, le laboratoire Hugging Face, fondé à New York en 2016 par des Français, joue un rôle central dans la démocratisation des modèles de langage open source. En 2022, leur projet Bloom devient le premier grand modèle de langage multilingue open source entraîné sur un supercalculateur français (le cluster Jean Zay, au CNRS à Saclay).
En l’espace de 70 ans, les modèles de langage sont passés d’un concept mathématique de prédiction probabiliste à des systèmes capables d’écrire des romans, de discuter en plusieurs langues ou d’automatiser des tâches complexes. Cette évolution repose à la fois sur les avancées théoriques des chercheurs, les capacités techniques croissantes des ordinateurs, et la disponibilité massive de données textuelles sur Internet.
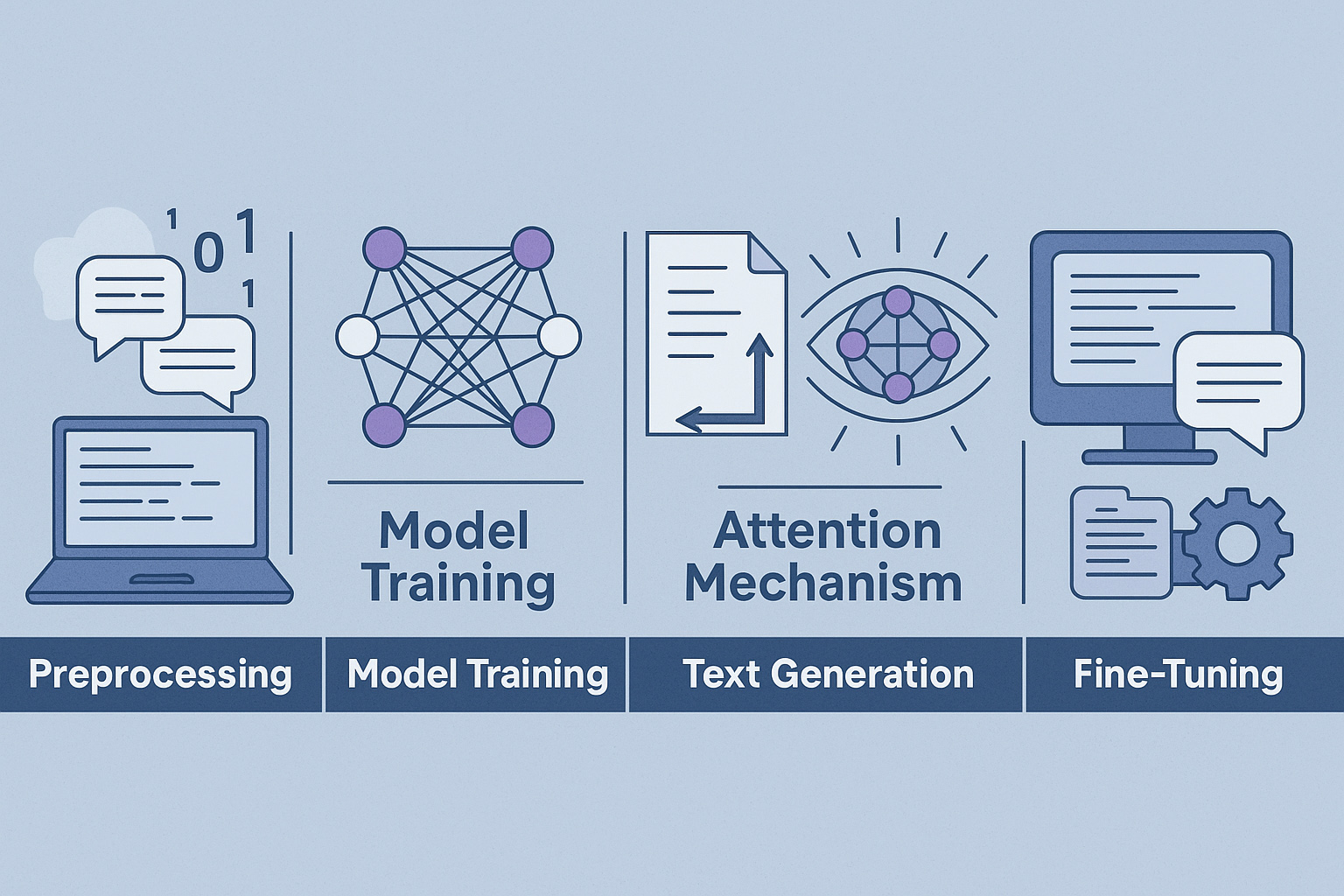
Les principes de fonctionnement d’un modèle de langage
Le fonctionnement d’un modèle de langage repose sur une série d’étapes complexes, mêlant statistiques avancées, apprentissage machine et architecture neuronale. À la croisée de la linguistique computationnelle et de l’intelligence artificielle, un modèle de langage ne « comprend » pas le texte comme un humain, mais l’analyse à travers des régularités mathématiques apprises au fil de milliards de lignes de texte. Son objectif : Produire ou transformer des séquences linguistiques de manière cohérente, fluide et contextuellement adaptée. Du prétraitement des données à la génération finale de texte, en passant par la représentation vectorielle ou l’ajustement de milliards de paramètres, chaque phase est cruciale et mobilise des ressources informatiques considérables. Voici une présentation détaillée des principales étapes qui composent le cœur du fonctionnement d’un modèle de langage moderne.
| Prétraitement des données | L’entraînement d’un modèle de langage commence par une étape fondamentale : le prétraitement des données. Les textes sont collectés à partir de multiples sources (livres, articles scientifiques, blogs, pages web, forums, conversations, transcriptions, etc.). Cette phase nécessite un travail minutieux de nettoyage : suppression des doublons, des caractères inutiles, des balises HTML, des spams, et parfois des contenus jugés sensibles. Ensuite, les données sont transformées en unités appelées tokens, qui peuvent être des mots entiers, des sous-parties de mots, voire des caractères, selon le découpage choisi. Cette tokenisation est une étape déterminante, car elle conditionne la manière dont le modèle percevra le langage. |
|---|---|
| Entraînement du modèle | L’entraînement est la phase durant laquelle le modèle apprend à prédire un mot à partir de ceux qui l’entourent. Il passe en revue d’immenses quantités de données et ajuste ses paramètres (poids synaptiques) à chaque itération. Un modèle moderne comme GPT-4 ou PaLM peut contenir entre 100 et 500 milliards de paramètres, chacun devant être optimisé. L’apprentissage repose sur une fonction de perte (loss function) qui mesure l’écart entre la prédiction du modèle et la réalité. Ce processus peut durer plusieurs semaines, nécessite des supercalculateurs ou des fermes de GPU, et consomme plusieurs centaines de MWh. Des organisations comme OpenAI, Google ou Meta utilisent des clusters spécialisés pour entraîner ces modèles sur des infrastructures cloud ultra-performantes. |
| Représentation vectorielle du langage | Pour que la machine puisse « comprendre » le langage, les mots doivent être transformés en une forme exploitable mathématiquement. Cette étape passe par les embeddings : chaque token est associé à un vecteur de plusieurs centaines de dimensions. Ces vecteurs traduisent la position du mot dans un espace sémantique, c’est-à-dire qu’ils reflètent ses relations avec d’autres mots. Ainsi, les mots proches par le sens (ex. : « chat », « animal », « félin ») auront des vecteurs similaires. Cette représentation dense permet au modèle de capturer la polysémie, les associations d’idées et les contextes d’usage. |
| Mécanisme d’attention | L’un des éléments clés de l’architecture Transformer est le mécanisme d’attention. Il permet au modèle de « pondérer » l’importance de chaque mot du contexte pour prédire ou analyser le mot cible. Par exemple, dans la phrase « Le chat qui dormait sous la table ronronnait doucement », le modèle doit comprendre que « chat » est le sujet de « ronronnait ». L’attention aide à établir ces liens à longue distance dans la phrase. C’est ce mécanisme qui a permis de dépasser les limites des réseaux neuronaux classiques (RNN, LSTM), en offrant une meilleure capacité de modélisation du contexte global. |
| Génération de texte | Une fois entraîné, le modèle peut générer du texte en prédisant les mots un à un, selon la probabilité qu’ils apparaissent dans une suite donnée. Le processus repose sur un échantillonnage probabiliste : le modèle ne choisit pas systématiquement le mot le plus probable, mais peut explorer d’autres alternatives pour produire un texte plus naturel. Différents réglages (température, top-k, top-p sampling) permettent d’influencer le style, la créativité ou la cohérence du texte produit. Plus le modèle est performant, plus le résultat semble fluide, précis et pertinent, au point de rendre parfois indiscernable la frontière entre contenu humain et machine. |
| Affinage et spécialisation (fine-tuning) | Après l’entraînement initial, un modèle de langage peut être affiné pour des tâches ou domaines spécifiques. Ce fine-tuning repose sur un second entraînement, à partir d’un sous-ensemble de données ciblées : corpus médicaux, juridiques, techniques, etc. Le modèle apprend alors à adapter son vocabulaire, son style et sa logique au contexte visé. Il peut aussi être soumis à une supervision humaine pour corriger ses erreurs ou éviter des dérives (toxicité, désinformation, biais). Ce processus est essentiel pour rendre le modèle opérationnel dans des environnements sensibles ou professionnels. |
| Evaluation et déploiement | Une fois le modèle entraîné et affiné, il doit être évalué selon plusieurs critères : cohérence, exactitude, absence de biais, temps de réponse, efficacité énergétique. Des métriques comme BLEU (pour la traduction), ROUGE (pour le résumé) ou F1-score (pour la classification) sont utilisées. Les modèles validés peuvent alors être déployés dans des API, des assistants vocaux, des plateformes de rédaction, ou embarqués dans des logiciels métiers. Le déploiement implique aussi des mises à jour régulières et un suivi éthique et technique. |
La puissance d’un modèle de langage dépend d’un ensemble de facteurs imbriqués. Plus les données d’entraînement sont riches, diversifiées et pertinentes, meilleure sera la compréhension contextuelle. La taille du modèle (en nombre de paramètres), le volume de calcul disponible, la durée de l’entraînement et la qualité des ajustements humains sont également décisifs. Mais cette montée en puissance n’est pas sans conséquences : elle pose des défis en matière de soutenabilité environnementale, d’inclusion linguistique (modèles souvent biaisés vers l’anglais), et de gouvernance des usages. Au-delà des prouesses techniques, les modèles de langage posent une question centrale : Que signifie « comprendre » un langage ? Si ces systèmes peuvent produire des réponses bluffantes, ils ne possèdent ni conscience, ni intention, ni expérience humaine. Leur fonctionnement repose exclusivement sur l’analyse statistique de structures linguistiques, sans accès réel au sens vécu. C’est pourquoi leur usage demande une approche prudente, encadrée et éthiquement réfléchie.
Les usages, les avantages et les limites des modèles de langage
Les modèles de langage ont connu une adoption fulgurante dans de nombreux secteurs. Leur capacité à traiter, analyser ou générer du langage naturel leur permet d’automatiser des tâches auparavant réservées à l’humain. Du service client à la création de contenu, en passant par le codage ou la traduction, ils s’invitent dans tous les environnements numériques. Voici un aperçu détaillé des principaux cas d’usage observés à ce jour :
| Chatbots et assistants vocaux | Les modèles de langage sont utilisés pour simuler des conversations humaines en temps réel. Ils permettent de répondre aux questions des utilisateurs, de les guider dans des procédures simples ou d’automatiser des tâches répétitives. Ces systèmes sont souvent déployés dans le e-commerce, les services publics ou la relation client.
|
|---|---|
| Traduction automatique | Grâce aux modèles multilingues, il est désormais possible de traduire rapidement des documents entiers avec un haut niveau de qualité. Ces outils sont utilisés aussi bien pour la traduction instantanée de messages que pour des documents techniques.
|
| Rédaction de contenu | Les outils basés sur les modèles de langage permettent de produire automatiquement des textes pour divers usages : articles de blog, publicités, emails, descriptions produits, publications sur les réseaux sociaux, etc. Ils sont particulièrement utiles dans les services marketing et communication.
|
| Analyse de sentiment | Ces systèmes peuvent détecter et classer les émotions exprimées dans un texte : positif, négatif, neutre. Cette capacité est précieuse pour les entreprises qui souhaitent analyser l’opinion publique ou le retour client à grande échelle.
|
| Résumé automatique | Un modèle de langage peut extraire les informations clés d’un long document, d’un article ou d’un rapport. Cela facilite la lecture rapide de grandes quantités de texte et permet aux professionnels de gagner du temps dans leur veille informationnelle.
|
| Codage automatique | Certains modèles sont spécialisés dans l’analyse et la génération de code informatique. Ils aident les développeurs à écrire, corriger ou commenter du code en langage naturel, parfois même à partir de simples instructions écrites.
|
Les principales limites des modèles de langage
Malgré leurs performances impressionnantes, les modèles de langage ne sont pas infaillibles. Ils comportent des risques techniques, éthiques et juridiques qu’il est essentiel de connaître pour les utiliser de manière responsable. Voici une synthèse des limites les plus importantes rencontrées aujourd’hui :
| Hallucinations | Un modèle de langage peut produire du contenu inventé, incorrect ou trompeur, surtout s’il est utilisé sans accès à une base de données fiable. Cela peut être problématique dans les domaines comme la santé, le droit ou le journalisme.
|
|---|---|
| Biais cognitifs | En apprenant à partir de textes disponibles sur Internet, les modèles peuvent intégrer et reproduire des stéréotypes sociaux, raciaux, sexistes ou culturels. Ces biais posent un problème d’équité et de neutralité dans les décisions automatisées.
|
| Consommation énergétique | L’entraînement des modèles de grande taille nécessite d’énormes quantités d’électricité et de ressources matérielles. Cela soulève des préoccupations environnementales croissantes, notamment face à l’empreinte carbone du numérique.
|
| Dépendance à l’anglais | Une grande partie des données d’entraînement sont issues de corpus anglophones, ce qui peut réduire la performance des modèles dans d’autres langues. Les réponses peuvent être moins précises, moins naturelles, voire incorrectes dans des contextes multilingues.
|
| Propriété intellectuelle | Les modèles sont souvent entraînés à partir de contenus disponibles en ligne, sans accord explicite des auteurs. Cela soulève des questions légales sur le droit d’auteur, notamment pour les textes générés à partir de sources protégées.
|
Les modèles de langage offrent ainsi un champ d’applications immense, mais leur déploiement nécessite une gestion rigoureuse des risques. L’encadrement humain, la transparence des processus et l’attention portée à l’éthique sont aujourd’hui des piliers essentiels pour tirer pleinement parti de leur potentiel tout en en limitant les dérives.

0 commentaires