Des voitures capables de s’adapter à la circulation, des assistants vocaux qui comprennent ce que vous dites ou encore des plateformes qui vous recommandent des films comme si elles lisaient dans vos pensées : Derrière ces prouesses se cache le machine learning, ou apprentissage automatique. Cette technologie permet aux machines d’apprendre à partir de données, sans que chaque action soit codée à la main. Présente dans de nombreux services que nous utilisons au quotidien, elle transforme profondément la manière dont les systèmes informatiques prennent des décisions. Mais comment cela fonctionne-t-il exactement ? Qu’implique réellement cette capacité d’apprentissage ? C’est ce que nous allons découvrir ensemble dans cet article.
- Les fondements du machine learning : Définition & histoire
- Les origines conceptuelles du machine learning dans les années 1950
- L’essor académique et les premières formalisation du machine learning dans les années 1960-1980
- Le renouveau dans les années 1990 et l’arrivée de l’apprentissage à grande échelle
- L’avènement du deep learning et l’ère des données massives
- Le machine learning est une discipline en constante évolution
- Le fonctionnement d’un algorithme de machine learning
- Les applications concrètes du machine learning
Les fondements du machine learning : Définition & histoire
Le machine learning, ou apprentissage automatique, est un domaine de l’intelligence artificielle (IA) qui vise à permettre aux ordinateurs d’apprendre à effectuer des tâches à partir de données, sans avoir été explicitement programmés pour chacune d’elles. Contrairement aux algorithmes traditionnels, qui nécessitent des instructions codées étape par étape, le machine learning repose sur des modèles statistiques qui s’améliorent à mesure qu’ils reçoivent de nouvelles données. C’est cette capacité d’adaptation qui en fait l’un des moteurs les plus puissants des technologies modernes. Mais pour bien comprendre cette discipline, il faut remonter à ses origines, qui prennent racine au milieu du XXème siècle, à la croisée des mathématiques, de la logique formelle, de la psychologie cognitive et de l’informatique naissante.
Les origines conceptuelles du machine learning dans les années 1950
L’idée que les machines puissent apprendre est antérieure à l’invention même des ordinateurs modernes. Dès 1950, Alan Turing, mathématicien britannique considéré comme l’un des pères fondateurs de l’informatique, pose les bases de la réflexion sur l’intelligence artificielle dans son article fondateur « Computing Machinery and Intelligence ». Il y propose le célèbre test de Turing, visant à évaluer si une machine peut imiter l’intelligence humaine au point d’être indiscernable dans une conversation.
Quelques années plus tard, en 1952, un programme rudimentaire d’apprentissage voit le jour avec Arthur Samuel, informaticien chez IBM. Il crée un logiciel capable d’apprendre à jouer au jeu de dames. Ce logiciel ne repose pas sur des règles précises, mais améliore ses performances en jouant des parties et en mémorisant les configurations gagnantes. C’est Samuel qui, le premier, utilise le terme « machine learning » pour désigner ce processus d’amélioration automatique par l’expérience.
L’essor académique et les premières formalisation du machine learning dans les années 1960-1980
Durant les décennies suivantes, le développement du machine learning progresse lentement mais sûrement. Dans les années 1960 et 1970, plusieurs chercheurs s’intéressent à la reconnaissance de motifs (pattern recognition), à la modélisation statistique et à la théorie des probabilités. C’est aussi à cette période que l’on commence à explorer les réseaux de neurones artificiels, une tentative d’imiter le fonctionnement du cerveau humain à l’aide d’unités interconnectées appelées « neurones ». Le perceptron, inventé par Frank Rosenblatt en 1957, est l’un des premiers modèles de ce type, capable de classer des données linéaires simples. Mais l’enthousiasme initial retombe avec la publication du rapport Perceptrons par Marvin Minsky et Seymour Papert en 1969. Ce rapport met en lumière les limites majeures du perceptron et freine les financements pour la recherche sur les réseaux de neurones pendant plus d’une décennie. On parle alors d’un premier « hiver de l’IA ».
Le renouveau dans les années 1990 et l’arrivée de l’apprentissage à grande échelle
C’est à partir des années 1990 que le machine learning connaît un regain d’intérêt, en grande partie grâce à l’évolution des capacités de calcul et à la disponibilité croissante de données numériques. Les algorithmes deviennent plus efficaces, et des approches plus robustes émergent, comme les machines à vecteurs de support (SVM), les arbres de décision ou encore les forêts aléatoires (random forests). La discipline se structure alors autour de trois grandes familles d’apprentissage :
- L’apprentissage supervisé : L’algorithme apprend à partir d’exemples annotés. C’est le cas d’un modèle qui, après avoir été entraîné sur des milliers d’images étiquetées « chat » ou « chien », peut prédire la catégorie d’une nouvelle image (Voir aussi notre sujet sur Google Lens) ;
- L’apprentissage non supervisé : L’algorithme explore des données non étiquetées pour en extraire des regroupements ou des structures sous-jacentes, comme dans la segmentation de clientèle ou l’analyse de clusters ;
- L’apprentissage par renforcement : Inspiré du conditionnement comportemental, ce type d’apprentissage repose sur un agent qui interagit avec un environnement et ajuste ses actions en fonction des récompenses ou pénalités reçues. C’est ce que l’on retrouve dans les algorithmes qui apprennent à jouer à des jeux ou à naviguer dans un espace donné.
L’avènement du deep learning et l’ère des données massives
Au début des années 2010, le machine learning franchit un nouveau cap avec l’essor du deep learning (apprentissage profond), une sous-discipline qui repose sur des réseaux de neurones profonds (deep neural networks). Cette approche permet de modéliser des structures complexes dans des données non structurées comme les images, les vidéos ou le langage naturel. Le point de bascule se situe en 2012, lors du concours ImageNet, où une équipe de l’Université de Toronto dirigée par Geoffrey Hinton remporte la compétition avec un réseau profond, AlexNet, qui surclasse largement les autres modèles dans la reconnaissance d’images.
Depuis lors, le machine learning, porté par le deep learning, alimente des avancées majeures dans la reconnaissance vocale (comme Siri, Alexa ou Google Assistant), la traduction automatique (Google Translate), la conduite autonome, la détection de maladies, la modération de contenu, et bien d’autres domaines. Les figures clés de cette évolution sont nombreuses : Yann LeCun (créateur du réseau convolutionnel utilisé pour la vision par ordinateur), Yoshua Bengio et Geoffrey Hinton ont reçu ensemble en 2018 le prix Turing, souvent considéré comme le « Nobel » de l’informatique, pour leurs contributions majeures au développement du deep learning.
Le machine learning est une discipline en constante évolution
Le machine learning ne cesse d’évoluer, porté par l’innovation en matière d’architecture algorithmique, de puissance de calcul et de disponibilité de données massives. Aujourd’hui, il s’inscrit dans une dynamique de démocratisation : les outils sont de plus en plus accessibles, les bibliothèques logicielles (comme Scikit-Learn, TensorFlow ou PyTorch) permettent à un public plus large de créer des modèles performants, et les applications se multiplient dans tous les secteurs.
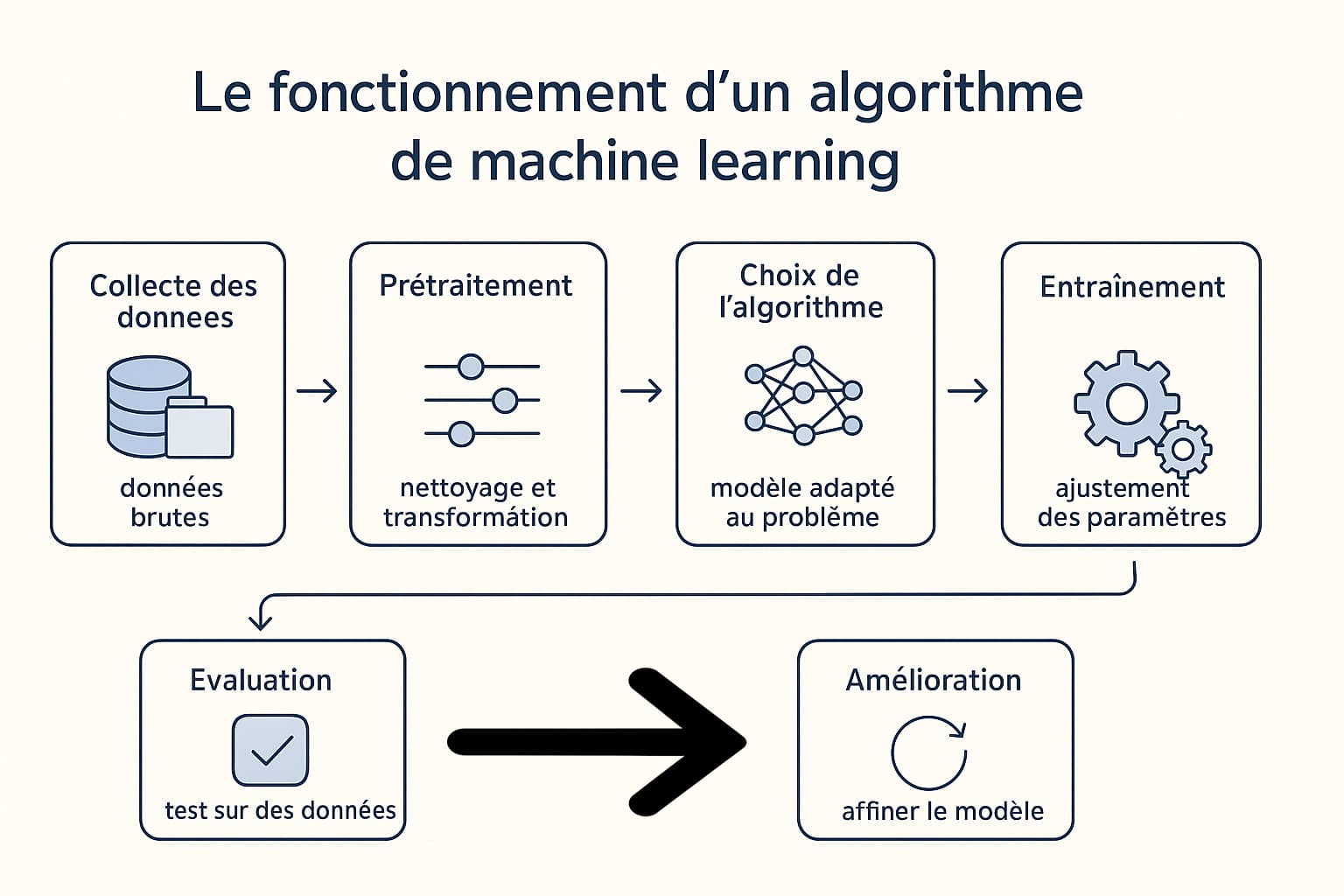
Le fonctionnement d’un algorithme de machine learning
Le processus d’apprentissage automatique repose sur une suite d’étapes techniques, structurées et interdépendantes. Chaque phase influe directement sur la qualité finale du modèle, et un écart ou une erreur à l’un des niveaux peut compromettre l’ensemble du projet. Le fonctionnement d’un algorithme de machine learning est donc bien plus qu’un simple entraînement sur des données : il s’agit d’un véritable cycle d’ingénierie des données et de modélisation mathématique. Ce processus est itératif, ce qui signifie qu’il est répété plusieurs fois afin de corriger, optimiser et affiner les performances du modèle à chaque passage. Voici les principales étapes techniques, présentées dans le tableau ci-dessous :
| Étape | Description technique |
|---|---|
| Collecte des données | Cette étape consiste à réunir les données nécessaires à l’entraînement du modèle. Ces données peuvent être structurées (tableaux, bases SQL), semi-structurées (fichiers JSON, XML) ou non structurées (images, sons, textes libres). La qualité, la quantité et la représentativité des données influencent fortement la performance du modèle final. |
| Prétraitement des données | Les données brutes sont rarement exploitables telles quelles. Il faut donc les nettoyer (suppression des doublons, gestion des valeurs manquantes), les transformer (normalisation, standardisation), les encoder (conversion des variables catégorielles en vecteurs numériques) et parfois les réduire (sélection de variables, réduction de dimension). |
| Choix de l’algorithme | Selon la nature du problème (classification, régression, clustering, etc.), on choisit un ou plusieurs algorithmes adaptés. Parmi les plus utilisés : arbres de décision, forêts aléatoires, k-nearest neighbors (KNN), réseaux de neurones, support vector machines (SVM), ou encore modèles de gradient boosting (XGBoost, LightGBM). |
| Entraînement du modèle | Le modèle apprend à partir d’un jeu de données d’entraînement. Il ajuste ses paramètres internes pour minimiser une fonction de coût (par exemple, l’erreur quadratique moyenne pour une régression, ou la cross-entropie pour une classification). Cette étape peut impliquer la validation croisée, la régularisation et l’optimisation via des algorithmes comme la descente de gradient. |
| Évaluation du modèle | Le modèle est testé sur un jeu de données indépendant (données de test) pour estimer sa capacité de généralisation. On utilise des métriques comme l’exactitude, le rappel, la précision, le score F1, ou encore l’AUC-ROC selon les cas. Ces mesures permettent d’identifier les biais et les faiblesses du modèle. |
| Amélioration et itération | Selon les performances observées, plusieurs actions peuvent être entreprises : ajustement des hyperparamètres (tuning), ajout de nouvelles données, sélection de nouvelles variables, ou même changement d’algorithme. On peut également recourir à des techniques avancées comme l’ensemble learning, la bagging ou le stacking pour combiner plusieurs modèles. |
Ces étapes ne sont pas linéaires, mais font partie d’un cycle itératif qui peut inclure de nombreux retours en arrière. Par exemple, l’évaluation peut révéler que les données sont déséquilibrées ou biaisées, ce qui nécessite de revenir à l’étape de prétraitement. Ou encore, un modèle performant en entraînement peut surapprendre (overfitting) et échouer en test, nécessitant des ajustements techniques. En pratique, le succès d’un projet de machine learning repose autant sur la qualité des données que sur la maîtrise des outils et des concepts mathématiques. Ce processus mobilise des compétences variées : compréhension métier (pour cadrer le problème), ingénierie logicielle (pour gérer les pipelines de données), statistiques avancées (pour construire des modèles robustes), et bien sûr, expertise en IA.
C’est pourquoi les projets de machine learning impliquent souvent une équipe pluridisciplinaire, réunissant data scientists, data engineers, ML engineers et experts métier, qui collaborent en continu pour améliorer les performances des systèmes intelligents.
Les applications concrètes du machine learning
Le machine learning n’est pas une théorie confinée aux laboratoires ou aux publications scientifiques. Il façonne déjà notre quotidien, souvent de manière invisible, en se glissant dans les services numériques, les systèmes industriels, les outils médicaux ou encore les objets connectés. Grâce à sa capacité d’analyse massive et d’apprentissage continu, le machine learning trouve des applications dans une variété impressionnante de domaines. Ces usages reposent sur une seule force motrice : L’exploitation intelligente des données. Qu’il s’agisse de comprendre les comportements humains, d’optimiser des processus logistiques ou de prédire des événements futurs, l’apprentissage automatique permet de prendre des décisions rapides, pertinentes et souvent plus précises qu’un humain ne le pourrait. Voici un aperçu approfondi des secteurs où son influence est déjà manifeste :
| Domaine | Applications concrètes |
|---|---|
| Finance |
|
| Santé |
|
| Commerce |
|
| Transport |
|
| Marketing |
|
| Industrie & fabrication |
|
| Éducation |
|
| Justice & sécurité |
|
Cette diversité d’usages repose sur plusieurs atouts techniques du machine learning : Sa capacité à traiter des volumes massifs de données, sa flexibilité à apprendre sur différents formats (texte, son, image, séries temporelles) et sa faculté à s’améliorer continuellement en s’adaptant au contexte. De plus, l’évolution rapide des infrastructures cloud et des bibliothèques open source (comme TensorFlow, PyTorch ou Scikit-learn) rend ces technologies accessibles à un nombre croissant d’organisations, grandes ou petites.
Le machine learning agit donc comme un levier d’optimisation, d’innovation et de transformation digitale. Que ce soit dans la santé, l’industrie ou les services, son intégration dans les processus décisionnels devient un facteur déterminant de compétitivité, d’efficacité et d’expérience utilisateur.

0 commentaires