Depuis quelques années, les intelligences artificielles génératives ont bouleversé notre rapport à l’information, à l’automatisation et à la création de contenu. Au cœur de cette révolution se trouvent les LLM, ou large language models, modèles linguistiques de grande taille. Mais que sont-ils vraiment ? Comment fonctionnent-ils ? Et pourquoi font-ils tant parler d’eux dans les milieux du numérique, de la recherche, et de l’entreprise ? Cet article propose une plongée claire et structurée dans l’univers des LLM, en revenant sur leur définition, leur histoire, leur fonctionnement technique, et leurs usages.
Pour comprendre les bases : Une définition du large language model
Un LLM (Large Language Model) est un modèle d’intelligence artificielle entraîné sur des milliards de mots pour apprendre à prédire et générer du langage humain. Il s’agit d’un réseau de neurones conçu pour comprendre, analyser, traduire, résumer ou produire du texte. Les LLM fonctionnent sur un principe simple en apparence : à partir d’une séquence de mots donnée, ils prédisent la suite la plus probable. En réalité, ces modèles s’appuient sur des architectures mathématiques complexes et des corpus colossaux de données.
| Nom | LLM (Large Language Model) |
| Type de modèle | Réseau de neurones profond basé sur l’architecture Transformer |
| Fonction principale | Génération et compréhension du langage naturel (NLP) |
| Exemples d’usage | Chatbots, rédaction automatisée, traduction, résumé de texte, recherche sémantique |
| Exemples de modèles | GPT (OpenAI), PaLM (Google), LLaMA (Meta), Claude (Anthropic), Gemini (Google DeepMind) |
Ce qui différencie un LLM des modèles linguistiques classiques, c’est sa taille monumentale : Il peut contenir plusieurs centaines de milliards de paramètres. Ces paramètres sont des poids internes qui permettent au modèle de capter les subtilités du langage, comme les métaphores, l’humour, les expressions idiomatiques ou les références culturelles. Plus le modèle est grand, plus sa capacité à comprendre et générer du texte devient fine et nuancée. Les LLM ne se limitent pas à la génération de phrases logiques : ils peuvent aussi adopter un ton, suivre une intention, imiter un auteur, ou structurer une réponse selon des critères précis. Cette modularité linguistique est rendue possible par l’entraînement massif de ces IA sur des jeux de données couvrant des domaines aussi variés que le droit, la médecine, l’histoire, la science ou encore la littérature.
Il faut également comprendre que les LLM ne sont pas programmés de manière explicite. Ils apprennent à travers l’analyse statistique des occurrences de mots dans des textes. Ce processus est appelé apprentissage auto-supervisé : le modèle apprend sans qu’un humain n’ait besoin de labelliser chaque donnée. Cette méthode a permis de franchir un cap en termes d’échelle et de rapidité d’entraînement. Enfin, les LLM sont de plus en plus accessibles via des interfaces conversationnelles. Ce qui était autrefois réservé aux laboratoires de recherche est désormais intégré dans des produits grand public, comme les assistants vocaux, les outils de rédaction intelligente ou les systèmes d’aide à la décision. Grâce à leur flexibilité, les LLM ouvrent la voie à une nouvelle interaction homme-machine basée sur le langage naturel, sans menus, sans interface complexe, juste des mots.
Un retour historique sur les LLM : Des premiers modèles aux géants modernes
L’histoire des Large Language Models (LLM) s’inscrit dans une longue tradition de recherche en intelligence artificielle et en traitement automatique du langage naturel (TALN ou NLP). Si les LLM actuels fascinent par leur capacité à générer du texte cohérent et contextuel, leur évolution repose sur plusieurs décennies de progrès théoriques, techniques et matériels. Les premiers jalons remontent aux années 1950, avec les premières expérimentations en traduction automatique menées aux États-Unis dans un contexte de guerre froide. Le projet Georgetown-IBM (1954) constitue une démonstration emblématique : il traduit une soixantaine de phrases du russe à l’anglais à l’aide de règles linguistiques codées manuellement. À cette époque, l’approche dominante est symbolique : on tente de décrire le langage à l’aide de grammaires formelles et de dictionnaires.
Mais cette approche montre rapidement ses limites face à la complexité du langage humain. C’est dans les années 1980-1990 qu’un tournant s’opère, avec l’émergence de l’apprentissage statistique. L’idée n’est plus de programmer la langue, mais de l’apprendre à partir de grands corpus. L’introduction des modèles de Markov cachés (HMM), puis des réseaux de neurones récurrents (RNN), marque une nouvelle étape vers des systèmes plus souples et plus performants. Le véritable déclencheur de la révolution LLM survient au début des années 2010, avec deux avancées majeures : la montée en puissance du deep learning, et la disponibilité de capacités de calcul massives (GPU, cloud computing). Des chercheurs comme Yoshua Bengio, Geoffrey Hinton ou Yann LeCun posent alors les bases de l’apprentissage profond appliqué au langage.
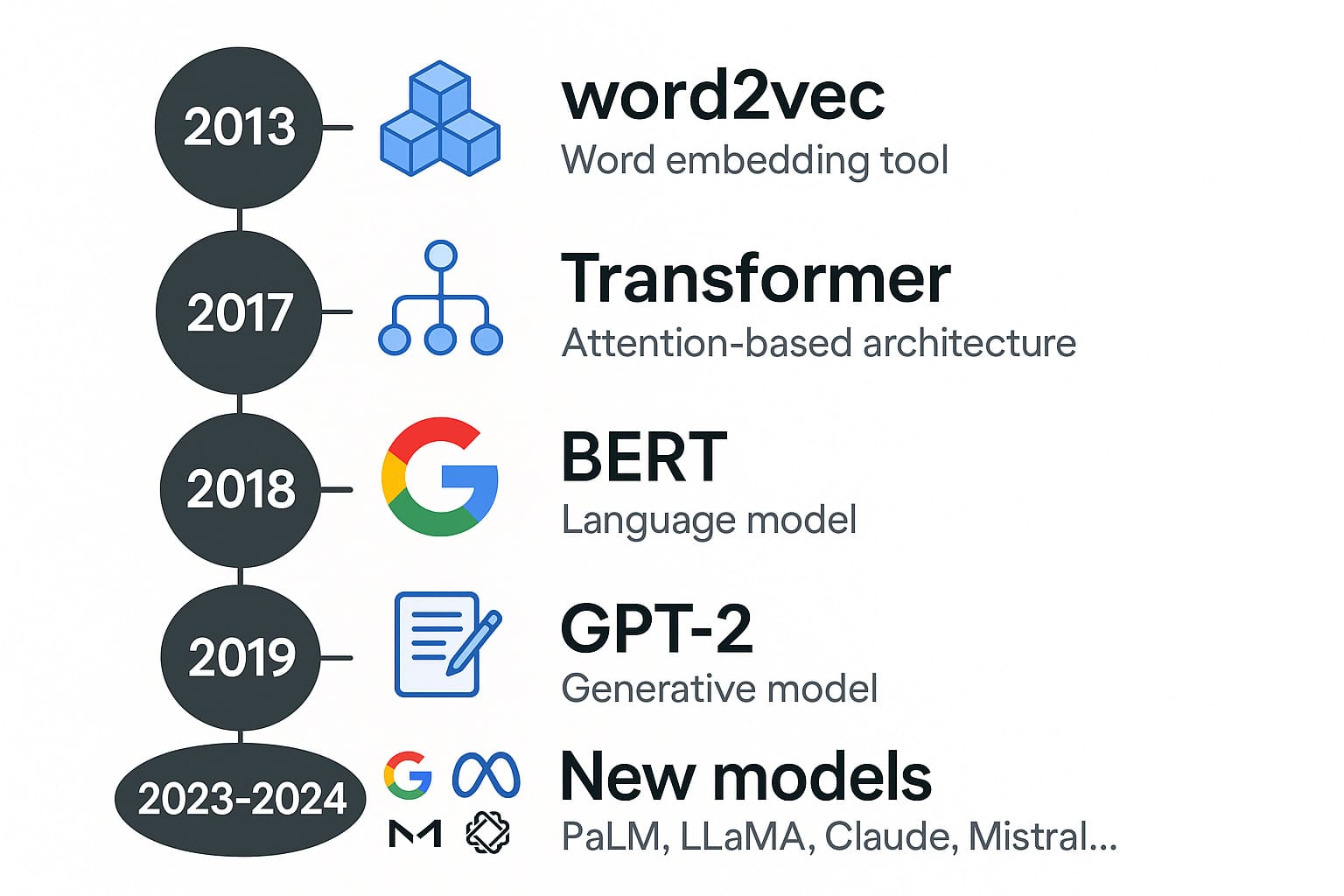
Les jalons marquants de l’évolution des LLM
- 2013 : Google publie word2vec, un outil de vectorisation des mots qui transforme chaque mot en vecteur dans un espace sémantique. Ce concept d’embedding révolutionne la représentation du langage.
- 2017 : L’article « Attention is All You Need » de Vaswani et al. introduit le Transformer, une architecture qui abandonne les RNN au profit du mécanisme d’attention. Cette innovation permet des parallélisations massives et une compréhension fine du contexte global.
- 2018 : Google lance BERT (Bidirectional Encoder Representations from Transformers), un modèle de compréhension du langage capable d’intégrer le contexte à gauche et à droite d’un mot simultanément. Il excelle dans les tâches de type Q&A, classification ou complétion.
- 2019 : OpenAI publie GPT-2, un modèle génératif entraîné de manière unidirectionnelle sur 40 Go de textes. Pour la première fois, un modèle écrit de longs paragraphes cohérents, avec une fluidité surprenante.
- 2020 : GPT-3 voit le jour avec 175 milliards de paramètres. Sa taille inédite, ses performances en génération libre et sa capacité à « zero-shot learning » (répondre sans exemple préalable) en font une avancée majeure.
- 2023–2024 : Entrée de nouveaux acteurs majeurs :
- Google développe PaLM puis Gemini, des modèles multitâches très performants ;
- Meta propose la série LLaMA (Large Language Model Meta AI), dont certaines versions sont open source ;
- Anthropic lance Claude, avec un accent mis sur la sécurité et l’alignement éthique ;
- Mistral.ai, start-up française, fait sensation en 2023 avec un modèle open source puissant et optimisé.
Cette accélération fulgurante s’explique par la convergence de plusieurs éléments : une meilleure compréhension des architectures, des bases de données toujours plus massives (Wikipedia, Common Crawl, livres numérisés…), et des avancées matérielles (TPU, GPU de dernière génération). Les chercheurs utilisent également des méthodes comme la fine-tuning (ajustement sur des cas d’usage précis) ou le RLHF (reinforcement learning from human feedback) pour améliorer la pertinence et la sécurité des réponses. En parallèle, le développement des modèles open source (comme Falcon, BLOOM, LLaMA ou Mistral) a permis une démocratisation sans précédent. De simples développeurs peuvent aujourd’hui héberger un LLM sur un serveur personnel ou intégrer une IA générative à une application métier. Ces avancées ont aussi posé de nouveaux défis : consommation énergétique, biais des données d’entraînement, hallucinations, sécurité et usages malveillants.
Comment fonctionne un LLM : L’architecture et l’apprentissage
Le fonctionnement d’un Large Language Model repose sur une combinaison complexe de mathématiques, d’algorithmes d’apprentissage profond et d’ingénierie logicielle. À la différence des anciens modèles probabilistes (comme les n-grammes ou les HMM), les LLM s’appuient sur des réseaux de neurones profonds, et plus précisément sur l’architecture Transformer, introduite en 2017 par Google dans l’article fondateur Attention is All You Need. Cette architecture a radicalement changé la manière dont les modèles comprennent et génèrent du texte.Le cœur de la puissance d’un LLM réside dans sa capacité à modéliser le langage comme une séquence dynamique d’interdépendances, et non comme une simple suite de mots. Il ne s’agit pas seulement de « deviner le mot suivant », mais de construire un espace vectoriel dans lequel chaque mot, phrase ou paragraphe est représenté par un point multidimensionnel en relation avec les autres.
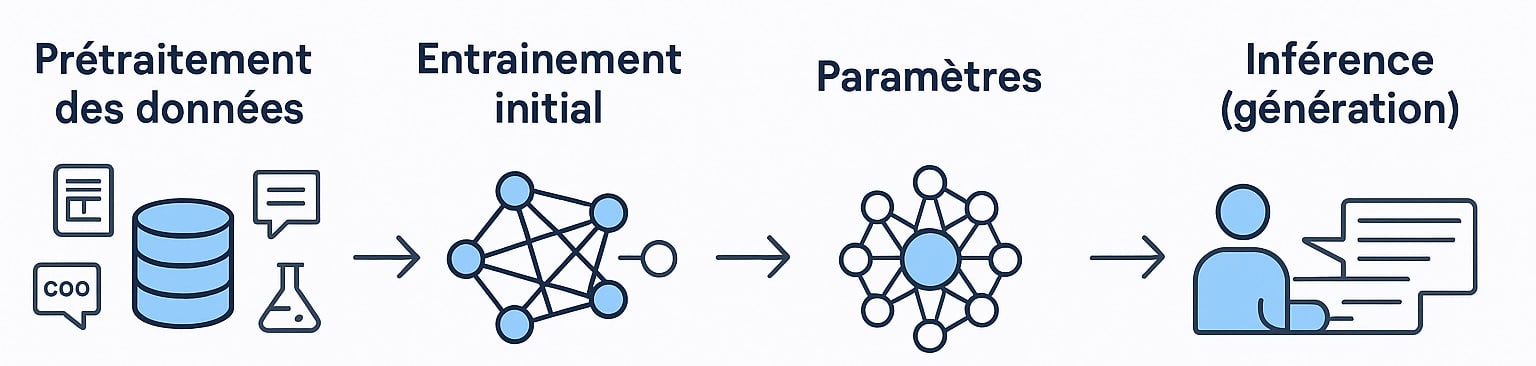
Les grandes étapes du fonctionnement d’un LLM
| Prétraitement des données | Avant l’apprentissage, le modèle a besoin de données. On collecte des milliards de mots issus de sources diverses : livres, encyclopédies, journaux, dialogues de forums, documents scientifiques, code source (GitHub), etc. Ces données sont ensuite nettoyées (suppression de contenus dupliqués, erreurs, contenu toxique) puis tokenisées. La tokenisation consiste à découper le texte en unités compréhensibles par le modèle : cela peut être des mots entiers, des sous-mots, ou même des caractères. GPT, par exemple, utilise une tokenisation en sous-mots basée sur Byte Pair Encoding (BPE). |
| Entraînement initial | Le modèle est ensuite entraîné à prédire le prochain token à partir d’une séquence. Cette tâche est appelée modélisation de langage causale. Chaque prédiction génère une perte (erreur de prédiction), qui est minimisée par rétropropagation à travers des milliers de couches et de poids. L’entraînement se fait sur des infrastructures massives de calcul (clusters de GPU/TPU), sur plusieurs semaines, et mobilise plusieurs centaines de gigaoctets de VRAM. |
| Paramètres | Un LLM comme GPT-3 dispose de 175 milliards de paramètres, c’est-à-dire des valeurs ajustables (poids) qui permettent au réseau de capturer les régularités linguistiques dans les données. Plus un modèle possède de paramètres, plus il peut théoriquement capturer des relations fines, mais plus il est aussi coûteux à entraîner et à exploiter. |
| Fine-tuning (ajustement) | Une fois le pré-entraînement terminé, on peut affiner le modèle sur des corpus spécialisés pour l’adapter à une tâche : classification, résumé, traduction, conversation, rédaction juridique ou médicale, génération de code, etc. Ce processus est appelé fine-tuning supervisé. Une alternative consiste à utiliser l’instruction tuning, qui consiste à exposer le modèle à des instructions explicites pour le rendre plus interactif. |
| Inférence (génération) | Lorsqu’un utilisateur saisit un texte (prompt), le LLM l’analyse, encode les tokens, puis génère mot après mot la suite la plus probable. Il utilise des techniques comme la température (pour moduler la créativité), la top-k sampling ou le nucleus sampling (top-p) pour éviter une sortie trop déterministe ou trop aléatoire. |
Comprendre sans comprendre ? La nature statistique des LLM
Il est essentiel de rappeler que, malgré leur performance, les LLM ne comprennent pas le langage comme un humain. Ils ne possèdent ni intention, ni conscience, ni intuition. Ils opèrent par apprentissage statistique : à partir de milliards d’exemples, ils apprennent les probabilités conditionnelles entre des séquences de mots. Ils peuvent donner l’illusion de la compréhension, car ils ont vu et mémorisé suffisamment de contextes pour reproduire des formes linguistiques complexes. Cependant, leur maîtrise repose entièrement sur la qualité, la diversité et la quantité des données d’entraînement. Un LLM n’a pas de mémoire d’instance ni de connaissance du monde en temps réel, sauf si des mécanismes comme le retrieval-augmented generation (RAG) ou une mémoire externe sont mis en place.
Le rôle de l’attention et des embeddings
L’élément central de l’architecture Transformer est le mécanisme d’attention : chaque mot d’une séquence peut « prêter attention » aux autres, même s’ils sont éloignés. Cela permet de capturer des relations longues (contrairement aux RNN) et d’établir des dépendances contextuelles riches. Chaque token est projeté dans un embedding vectoriel qui évolue au fil des couches pour refléter son sens dans le contexte global. C’est cette représentation dynamique qui permet au modèle d’adapter ses réponses à une variété quasi infinie de requêtes.
Les usages actuels des LLM : De l’assistant virtuel à l’automatisation métier
L’essor des Large Language Models a profondément transformé l’usage de l’intelligence artificielle dans les environnements professionnels. Initialement perçus comme de simples outils conversationnels ou générateurs de texte, les LLM sont aujourd’hui devenus des briques technologiques centrales dans de nombreux secteurs. Leur capacité à comprendre le langage naturel, à synthétiser l’information et à générer des réponses adaptées leur permet d’intervenir dans une multitude de cas d’usage, allant de l’interaction client à l’aide à la décision stratégique. Les entreprises de toutes tailles (des startups aux multinationales) adoptent désormais les LLM pour automatiser, assister ou améliorer des tâches autrefois humaines, répétitives ou coûteuses. Voici quelques exemples concrets d’applications dans les domaines professionnels :
| Service client | Les assistants conversationnels basés sur des LLM sont capables de gérer une grande partie des demandes utilisateurs : Réponses aux FAQ, résolution de problèmes simples, orientation vers les bons services, compréhension du langage naturel même en présence de fautes ou d’ambiguïtés. De nombreuses plateformes intègrent des LLM pour fournir une assistance 24h/24, multilingue et personnalisée. Exemples : ChatGPT dans Intercom, Zendesk ou Salesforce Einstein GPT. |
| Marketing digital | Les professionnels du marketing utilisent les LLM pour automatiser des tâches à forte valeur ajoutée : Rédaction de contenus optimisés SEO, génération de titres accrocheurs, création d’articles de blog, scripts vidéo, messages publicitaires, posts pour les réseaux sociaux… Ils peuvent également analyser les sentiments dans les commentaires clients ou générer des variantes d’annonces pour les campagnes A/B. |
| Développement informatique | Avec des outils comme GitHub Copilot (basé sur Codex, un LLM d’OpenAI), les développeurs peuvent bénéficier d’une assistance au codage en temps réel. Ces modèles suggèrent des fonctions, corrigent les erreurs, génèrent de la documentation, et peuvent même expliquer du code existant. Cela permet de gagner un temps considérable, surtout dans les phases de prototypage ou de maintenance logicielle. |
| Éducation | Les LLM sont utilisés comme tuteurs personnalisés capables d’expliquer des concepts complexes, de générer des quiz adaptés au niveau de l’élève, ou de reformuler des notions pour les rendre plus compréhensibles. Ils peuvent aussi accompagner les enseignants dans la création de supports pédagogiques. Des plateformes éducatives comme Khan Academy, avec Khanmigo, expérimentent déjà l’intégration de LLM dans l’apprentissage interactif. |
| Traduction et linguistique | Grâce à leur entraînement multilingue, les LLM permettent une traduction automatique fluide dans des dizaines de langues. Contrairement aux anciens traducteurs automatiques, ils tiennent compte du contexte, du style et des nuances culturelles. Ils peuvent également reformuler, corriger des fautes, adapter un texte à un registre différent, ou générer des contenus multilingues. Des modèles comme NLLB (No Language Left Behind) de Meta visent à inclure les langues peu représentées. |
Des usages verticaux et spécialisés en pleine expansion
Au-delà des applications généralistes, les LLM s’orientent de plus en plus vers des cas d’usage verticaux, dans des secteurs comme la médecine, le droit, les assurances ou la finance. Par exemple :
- LLM médicaux : analyse de rapports cliniques, génération de comptes rendus médicaux, réponses aux questions des patients (ex. : PubMedGPT) ;
- LLM juridiques : aide à la rédaction de contrats, recherche jurisprudentielle, simplification du langage légal ;
- LLM pour la finance : analyse de documents réglementaires, résumés d’actualités financières, extraction d’indicateurs clés.
Ces modèles spécialisés, souvent entraînés sur des données sectorielles propriétaires, permettent une plus grande précision dans les domaines sensibles ou complexes. Ils offrent également des gains de temps et de productivité considérables, tout en réduisant les risques d’erreur humaine.
LLM intégrés dans les outils quotidiens
On assiste également à une généralisation des LLM dans les outils de bureau et logiciels collaboratifs. Par exemple :
- Microsoft Copilot dans Word, Excel et Outlook (intégration de GPT-4 dans Microsoft 365) ;
- Notion AI pour aider à la rédaction et à la structuration de notes ;
- Slack GPT pour résumer des conversations ou générer des réponses automatiques.
Cette intégration fluide transforme progressivement la façon dont les professionnels travaillent : moins de tâches répétitives, plus de créativité et de capacité d’analyse. En centralisant les données et en automatisant la production de texte, les LLM deviennent de véritables collaborateurs augmentés.

0 commentaires