À première vue, capturer un site web entier peut sembler réservé aux développeurs expérimentés. Pourtant, avec les bons outils et une compréhension claire des méthodes, il devient possible de reproduire localement une grande partie d’un site pour l’analyser, l’archiver ou le consulter hors ligne. Cette pratique, appelée aspiration de site web, s’inscrit aujourd’hui dans de nombreux usages professionnels et personnels. Que vous soyez curieux du fonctionnement d’un site Internet, impliqué dans une stratégie SEO ou simplement à la recherche d’une solution pour travailler hors connexion, il est essentiel de maîtriser les bases. Mais attention : Au-delà de la technique, il existe des règles à respecter, notamment sur le plan légal et éthique.
Ce que signifie et implique le fait d’aspirer un site web
Aspirer un site web consiste à télécharger tout ou partie de ses contenus afin de les consulter localement, sans dépendre d’une connexion Internet. Concrètement, cela implique de récupérer l’ensemble des fichiers qui composent une page web : HTML pour la structure, CSS pour la mise en forme, JavaScript pour les interactions, ainsi que les ressources associées comme les images, les polices ou les vidéos. D’un point de vue technique, cette opération repose sur un processus automatisé appelé crawling. Un robot, aussi appelé crawler ou spider, va analyser une URL de départ, télécharger son contenu, puis extraire tous les liens présents dans le code source. Il va ensuite suivre ces liens un par un, en répétant ce processus de manière récursive. Ce mécanisme permet de cartographier l’arborescence complète du site et d’en récupérer les ressources associées. Lors de cette phase, plusieurs éléments entrent en jeu. Le crawler doit interpréter correctement les chemins relatifs et absolus, gérer les redirections HTTP (codes 301, 302), et éviter les boucles infinies causées par des liens circulaires. Il peut également être configuré pour ignorer certains types de fichiers ou limiter la profondeur d’exploration afin d’optimiser les performances.
Une fois les fichiers téléchargés, un second travail s’opère : La réécriture des liens. Les URLs distantes sont transformées en chemins locaux pour permettre une navigation hors ligne cohérente. Sans cette étape, les pages aspirées continueraient de pointer vers Internet, rendant l’expérience incomplète. Il est également important de comprendre la différence entre les sites statiques et dynamiques. Un site statique est constitué de fichiers directement accessibles sur le serveur. Chaque page existe physiquement et peut être récupérée telle quelle. À l’inverse, un site dynamique génère ses pages à la volée via un langage serveur (comme PHP, Python ou Node.js) en interrogeant une base de données. Dans ce second cas, le crawler ne récupère que le rendu final envoyé au navigateur, et non la logique sous-jacente. Cela signifie que certaines fonctionnalités, comme les recherches internes, les espaces utilisateurs ou les contenus personnalisés, ne pourront pas être reproduites localement. Un autre défi technique concerne le JavaScript moderne. De nombreux sites utilisent aujourd’hui des frameworks comme React ou Vue.js, qui chargent le contenu dynamiquement côté client. Un crawler classique peut alors passer à côté de certaines données, car elles ne sont pas présentes dans le HTML initial. Pour contourner cela, des outils plus avancés utilisent des navigateurs headless capables d’exécuter le JavaScript avant de capturer le rendu final.
Enfin, il faut prendre en compte les aspects liés aux performances et aux ressources. Aspirer un site volumineux peut représenter plusieurs gigaoctets de données et nécessiter une gestion fine de la bande passante, du stockage et du nombre de requêtes envoyées au serveur cible.
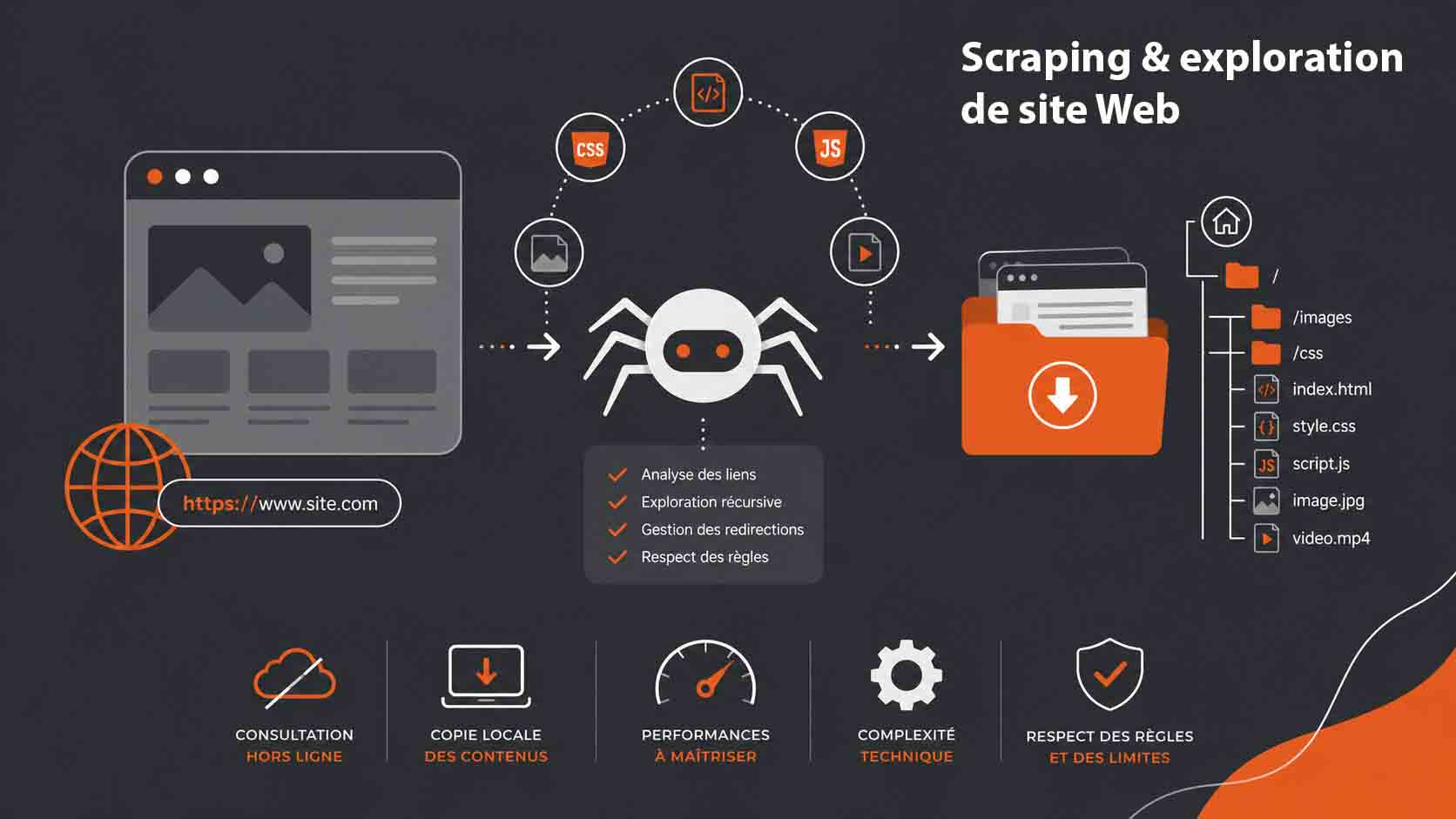
Les outils et méthodes pour aspirer un site web efficacement
Pour aspirer un site web efficacement, il ne suffit pas de choisir un outil au hasard. Chaque solution repose sur une logique différente, avec des capacités plus ou moins avancées en matière de crawling, de gestion des რეს ressources et de reconstruction locale. Comprendre ces différences permet d’adopter une approche plus précise et surtout plus performante.
- HTTrack est souvent considéré comme la porte d’entrée idéale. Ce logiciel open source fonctionne comme un aspirateur complet : il parcourt automatiquement les pages d’un site, télécharge les fichiers nécessaires et reconstruit une arborescence locale fidèle. Il propose des options avancées comme la limitation de profondeur, le filtrage par type de fichier, l’exclusion de certains répertoires ou encore la gestion des connexions simultanées. Il est particulièrement efficace pour les sites statiques ou semi-dynamiques.
- Wget adopte une approche différente, plus technique. Utilisé en ligne de commande, il permet un contrôle très fin du processus d’aspiration. Par exemple, il est possible de :
-
- Récupérer un site en mode miroir avec l’option –mirror
- Convertir les liens pour une navigation locale avec –convert-links
- Limiter la profondeur avec –level
- Reprendre un téléchargement interrompu avec –continu
Cette flexibilité en fait un outil très puissant pour les utilisateurs avancés ou pour automatiser des tâches via des scripts.
- Scrapy se distingue par son orientation data. Contrairement aux outils précédents, il ne cherche pas forcément à reconstruire un site complet, mais plutôt à extraire des données ciblées. Basé sur Python, il permet de définir des règles précises pour naviguer dans un site, identifier des éléments HTML spécifiques (via XPath ou CSS selectors) et structurer les données récupérées. Il est particulièrement utilisé dans les projets de veille, d’analyse concurrentielle ou de collecte de données à grande échelle.
- Pour aller encore plus loin, certains outils modernes comme Puppeteer ou Playwright permettent d’utiliser des navigateurs headless. Ces solutions exécutent le JavaScript comme un vrai navigateur, ce qui les rend indispensables pour aspirer des sites construits avec des frameworks modernes. Elles permettent de capturer le rendu final d’une page après chargement dynamique, ce qu’un crawler classique ne peut pas toujours faire.
Au-delà des outils, la méthode utilisée joue un rôle déterminant. Une aspiration efficace repose sur plusieurs paramètres techniques :
- La gestion de la profondeur de crawl : Limiter le nombre de niveaux explorés constitue un levier essentiel pour maîtriser l’efficacité d’un robot d’exploration. En définissant une profondeur maximale (par exemple 2 ou 3 niveaux à partir de l’URL de départ), on évite que le crawler ne s’enfonce dans des structures arborescentes complexes ou infinies, comme les calendriers dynamiques, les filtres e-commerce ou les boucles de pagination. Cette approche permet non seulement de réduire le volume de données inutiles collectées, mais aussi d’optimiser le temps de traitement et la consommation de ressources. Une bonne gestion de la profondeur doit également tenir compte de la structure du site cible et de la pertinence des contenus situés en profondeur, afin de ne pas passer à côté d’informations stratégiques ;
- Le contrôle du périmètre : Restreindre le crawl à un domaine ou à un sous-domaine spécifique est fondamental pour conserver une cohérence dans la collecte des données. Sans cette limitation, un crawler peut rapidement dériver vers des sites externes via des liens sortants, ce qui dilue la pertinence des résultats et augmente inutilement la charge de traitement. Le contrôle du périmètre inclut également la gestion des protocoles (HTTP vs HTTPS), des ports, ainsi que l’exclusion de certaines sections via des règles précises (comme des patterns d’URL ou des directives robots.txt). Cette maîtrise garantit que le robot reste concentré sur son objectif initial, tout en évitant des risques juridiques ou techniques liés à l’exploration de ressources non autorisées ;
- Le throttling : Ajuster la fréquence des requêtes envoyées au serveur cible est indispensable pour maintenir un équilibre entre performance et respect de l’infrastructure distante. Un crawl trop agressif peut entraîner une surcharge du serveur, provoquer des ralentissements, voire déclencher des mécanismes de protection comme des blocages d’IP ou des captchas. Le throttling consiste donc à introduire des délais entre les requêtes, à limiter le nombre de connexions simultanées et à adapter dynamiquement la cadence en fonction des réponses du serveur (temps de réponse, erreurs, etc.). Une stratégie de throttling bien pensée améliore la stabilité du crawl, réduit les risques d’interruption et favorise une relation plus respectueuse avec les sites explorés ;
- La gestion des erreurs HTTP : Un crawler performant doit être capable de détecter, interpréter et gérer efficacement les différents codes de réponse HTTP. Les erreurs comme les 404 (ressource introuvable), 403 (accès interdit) ou 500 (erreur serveur) ne doivent pas interrompre le processus, mais être intégrées dans une logique de traitement robuste. Cela implique de mettre en place des mécanismes de retry pour certaines erreurs temporaires, d’ignorer ou de journaliser les ressources définitivement indisponibles, et de maintenir une traçabilité des incidents rencontrés. Une bonne gestion des erreurs permet d’éviter la corruption des données collectées, d’améliorer la qualité globale du crawl et de faciliter le diagnostic en cas de problème ;
- Le caching : Mettre en place un système de mise en cache permet d’éviter de télécharger plusieurs fois les mêmes ressources, ce qui représente un gain significatif en termes de temps et de bande passante. Le caching peut être appliqué à différents niveaux : stockage des pages HTML déjà explorées, mémorisation des en-têtes HTTP (comme ETag ou Last-Modified) pour vérifier si une ressource a changé, ou encore utilisation de bases de données pour conserver l’historique des crawls. Cette approche améliore l’efficacité globale du processus, notamment lors de crawls récurrents, et réduit la charge à la fois côté crawler et côté serveur cible. Un bon système de cache doit également prévoir des mécanismes d’expiration et de mise à jour afin de garantir la fraîcheur des données.
Un autre aspect souvent négligé concerne l’analyse du fichier robots.txt. Ce fichier indique les sections autorisées ou interdites au crawling. Même s’il n’est pas techniquement contraignant, le respecter fait partie des bonnes pratiques pour éviter les conflits avec les administrateurs de sites. Enfin, il est essentiel d’adapter votre stratégie en fonction de votre objectif. Si vous souhaitez archiver un site, privilégiez une approche complète avec reconstruction locale. Si vous cherchez à extraire des données précises, un outil comme Scrapy sera plus pertinent. Et si vous ciblez un site moderne avec beaucoup de JavaScript, les solutions headless deviennent indispensables. Une utilisation maîtrisée des outils et des méthodes permet non seulement d’obtenir des résultats fiables, mais aussi d’optimiser les performances tout en limitant les risques techniques et les blocages côté serveur.
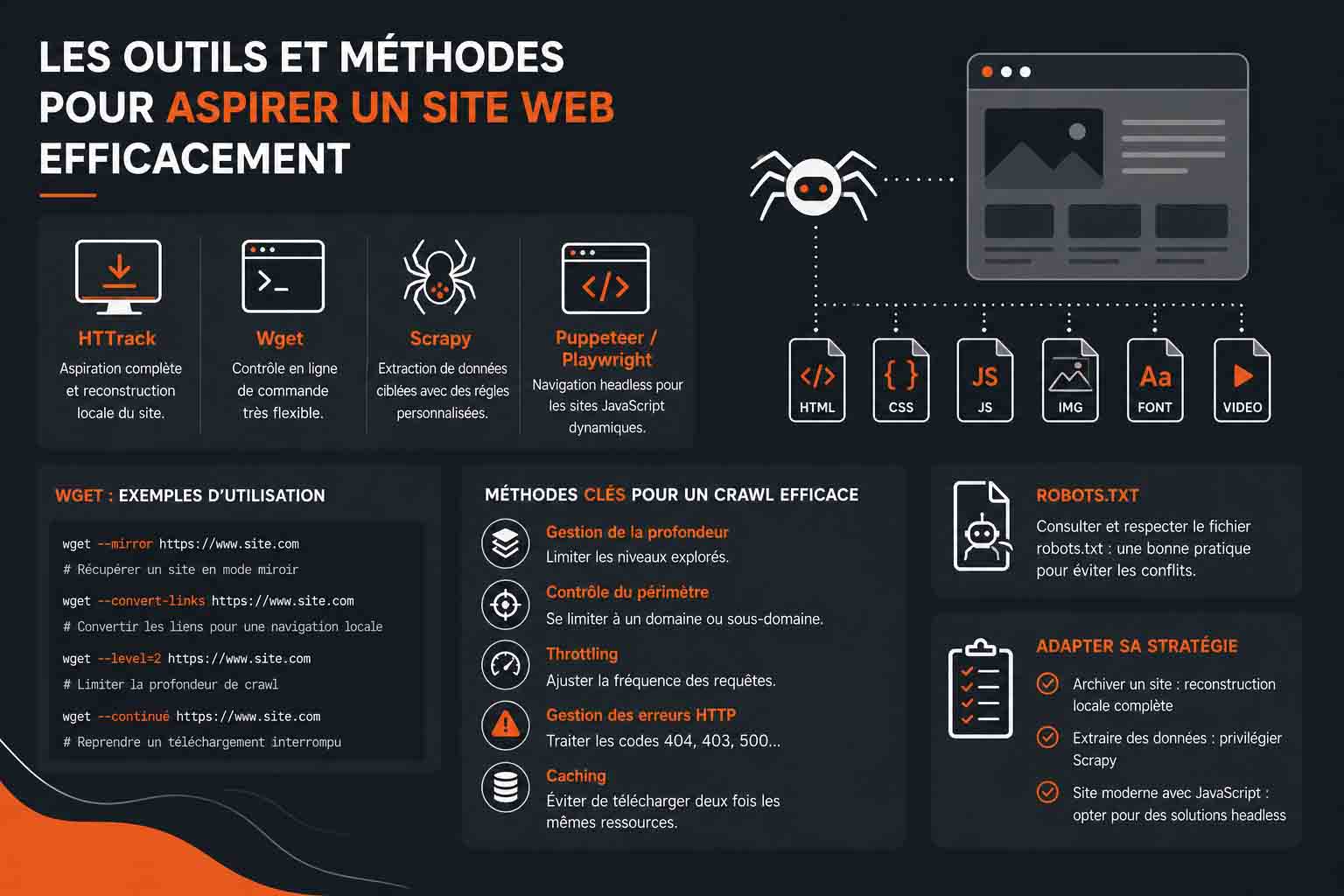
De quel matériel informatique ai-je besoin pour aspirer un site internet
Aspirer un site web peut sembler être une simple opération logicielle, mais en réalité, les performances et la stabilité du processus dépendent fortement du matériel utilisé. Selon la taille du site ciblé, la complexité de ses ressources et la profondeur d’exploration, les exigences matérielles peuvent varier de manière significative. Le premier élément à considérer est le processeur (CPU). Lors d’une aspiration, le CPU est sollicité pour gérer les connexions réseau, analyser le code HTML, parser les liens et traiter les fichiers téléchargés. Pour un usage classique, un processeur multi-cœurs moderne (quad-core ou plus) est recommandé afin de gérer efficacement les opérations simultanées, notamment si vous utilisez plusieurs threads de téléchargement. Plus le nombre de threads est élevé, plus le CPU devra être capable de répartir la charge sans créer de goulets d’étranglement. Pour des projets intensifs, un processeur avec une fréquence élevée et une bonne gestion du multithreading (comme les architectures récentes) améliore considérablement les performances globales.
La mémoire vive (RAM) joue également un rôle central. Chaque requête, chaque page analysée et chaque fichier temporairement stocké consomme de la mémoire. Pour des projets modestes, 8 Go peuvent suffire, mais dès que vous travaillez sur des sites volumineux ou des crawls profonds, 16 Go voire 32 Go deviennent rapidement nécessaires pour éviter les ralentissements ou les plantages. Une RAM insuffisante peut entraîner une utilisation excessive du swap disque, ce qui dégrade fortement les performances et allonge les temps de traitement. Le stockage est un autre facteur déterminant. Aspirer un site peut générer une grande quantité de données, surtout si des fichiers lourds comme des images haute résolution, des scripts ou des vidéos sont inclus. Un disque SSD est fortement recommandé pour accélérer les opérations de lecture et d’écriture, réduire les temps de latence et améliorer la réactivité globale du système. Les SSD NVMe offrent encore de meilleures performances pour des usages intensifs. En termes de capacité, prévoir plusieurs dizaines de gigaoctets est une base raisonnable pour des projets intermédiaires, mais certains crawls complets peuvent nécessiter plusieurs centaines de gigaoctets.
La connexion réseau est souvent le véritable goulot d’étranglement. Une connexion stable et rapide est essentielle pour télécharger efficacement les ressources. Une bande passante élevée permet d’augmenter le nombre de requêtes simultanées sans dégrader les performances. Toutefois, il est important de configurer correctement le throttling afin de ne pas saturer le serveur cible ni déclencher de mécanismes de protection. Pour des usages avancés, notamment avec des outils utilisant des navigateurs headless, la carte graphique (GPU) peut également intervenir. Bien que son rôle reste secondaire dans la majorité des cas, elle peut accélérer le rendu des pages complexes, notamment lorsque du JavaScript lourd est exécuté. Un autre élément souvent négligé concerne le système de fichiers et la gestion des inodes. Lors de l’aspiration de sites comportant un très grand nombre de petits fichiers, certaines limites système peuvent être atteintes. Un système de fichiers performant, correctement configuré et dimensionné permet d’éviter ces blocages et d’assurer une meilleure stabilité. Enfin, pour des projets à grande échelle, l’utilisation de serveurs dédiés ou de solutions cloud devient pertinente. Cela permet de distribuer la charge, d’augmenter les capacités de traitement et de stocker de grandes quantités de données sans contrainte locale. Dans ces environnements, des paramètres comme le nombre de threads, la gestion des files d’attente, la parallélisation et la tolérance aux pannes doivent être soigneusement optimisés.
| Composant | Détails et recommandations |
|---|---|
| Processeur (CPU) | Un processeur multi-cœurs (quad-core minimum) est recommandé pour gérer efficacement les requêtes simultanées et le parsing des pages. Les architectures récentes avec hyperthreading permettent d’optimiser les performances lors de crawls intensifs. |
| Mémoire vive (RAM) | 8 Go suffisent pour des projets simples, mais 16 à 32 Go sont recommandés pour des sites volumineux. Une RAM suffisante évite le swap disque et garantit la fluidité du traitement. |
| Stockage (SSD) | Un SSD est fortement conseillé pour accélérer les lectures/écritures. Les SSD NVMe offrent les meilleures performances. Prévoir au minimum 50 Go pour des projets intermédiaires, voire beaucoup plus selon le volume. |
| Connexion réseau | Une connexion stable avec une bonne bande passante est indispensable. Elle permet d’augmenter le nombre de requêtes simultanées tout en maintenant des temps de réponse rapides. |
| Carte graphique (GPU) | Optionnelle mais utile pour les crawls avec rendu JavaScript. Elle peut améliorer les performances des navigateurs headless utilisant l’accélération matérielle. |
| Système de fichiers | Doit être capable de gérer un grand nombre de fichiers. Une bonne gestion des inodes est essentielle pour éviter les limitations lors de crawls massifs. |
| Infrastructure (serveur/cloud) | Recommandée pour les projets à grande échelle. Permet la distribution de charge, la parallélisation et une meilleure scalabilité du processus de crawl. |
Les aspects légaux à ne pas négliger lors de l’aspiration de site web
Aspirer un site web ne se limite pas à une simple opération technique. Derrière chaque page téléchargée se trouvent des droits, des obligations et un cadre juridique précis qu’il est indispensable de comprendre avant de lancer un processus de récupération automatisée. La majorité des contenus disponibles en ligne sont protégés par le droit d’auteur. Cela inclut non seulement les textes, mais aussi les images, les vidéos, les éléments graphiques, l’architecture du site et parfois même la structure des bases de données. En pratique, cela signifie que toute reproduction, même partielle, est encadrée. Une copie réalisée pour un usage strictement personnel est généralement tolérée, mais dès qu’il y a diffusion, modification ou exploitation commerciale, une autorisation préalable devient nécessaire. Au-delà du droit d’auteur, il faut également prendre en compte le droit des bases de données. En Europe, ce droit protège les investissements réalisés pour constituer une base de données. Aspirer massivement un site peut alors être considéré comme une extraction substantielle, ce qui est juridiquement encadré et potentiellement sanctionnable. Les conditions générales d’utilisation (CGU) constituent un autre élément clé. De nombreux sites précisent explicitement les règles concernant le scraping, l’aspiration ou l’utilisation automatisée de leurs contenus. Certaines plateformes interdisent totalement ces pratiques, tandis que d’autres les encadrent via des API officielles. Ignorer ces règles peut engager votre responsabilité contractuelle, même si le site est accessible publiquement.
Un point souvent sous-estimé concerne les mesures techniques de protection. Certains sites mettent en place des dispositifs pour limiter ou bloquer l’accès automatisé : CAPTCHA, limitation de débit, authentification obligatoire ou blocage d’adresses IP. Contourner volontairement ces mécanismes peut être interprété comme une tentative d’accès frauduleux, avec des implications juridiques plus lourdes. La question des données personnelles est également centrale. En Europe, le Règlement Général sur la Protection des Données (RGPD) impose un cadre strict concernant la collecte, le stockage et l’utilisation des informations permettant d’identifier une personne. Aspirer des données comme des noms, adresses email ou profils utilisateurs sans base légale claire (consentement, intérêt légitime, obligation contractuelle) expose à des sanctions importantes. Il est important de comprendre que le caractère public d’une donnée ne signifie pas qu’elle est librement exploitable. Le RGPD s’applique dès lors qu’il y a traitement de données personnelles, y compris lorsqu’elles sont accessibles en ligne. Dans ce contexte, certaines bonnes pratiques permettent de réduire les risques :
- Vérifier systématiquement les mentions légales et les CGU du site ciblé
- Limiter l’aspiration à un usage interne, analytique ou éducatif
- Éviter toute republication ou redistribution sans autorisation explicite
- Ne pas collecter ni stocker de données personnelles sans base légale valide
- Respecter les signaux techniques comme le fichier robots.txt et les limitations serveur
Enfin et pour conclure, il est recommandé d’adopter une approche proportionnée, d’éviter notamment cet usage dans la perspective contrôlable autrement d’un blog disparu par exemple. Aspirer un site entier n’est pas toujours nécessaire : Cibler uniquement les ressources utiles permet de réduire l’impact technique et les risques juridiques. Adopter une démarche responsable et informée permet d’exploiter pleinement les possibilités offertes par l’aspiration de site web, tout en respectant les règles qui structurent l’écosystème numérique.

0 commentaires