Dans un contexte où les systèmes interconnectés génèrent en permanence d’importants volumes de données, les journaux de sécurité s’imposent comme une ressource stratégique encore largement sous-exploitée. Chaque interaction (connexion, tentative d’accès, modification ou anomalie) laisse une trace exploitable. Pourtant, face à cette masse d’informations, la difficulté réside dans leur interprétation et leur mise en valeur pour renforcer la sécurité, notamment dans l’identification des failles de sécurité d’un site Internet. Le SIEM apporte une réponse structurée à cet enjeu en centralisant, analysant et corrélant les journaux afin de fournir une vision globale, cohérente et exploitable du système d’information. Adopté par un nombre croissant d’organisations désireuses de mieux maîtriser leur exposition aux risques, le SIEM (Security Information and Event Management) va bien au-delà d’un simple outil de collecte. Il permet de croiser des données issues de multiples sources, de détecter des comportements anormaux et de réagir avec efficacité face aux incidents. Cette approche ouvre la voie à une sécurité plus proactive, basée sur l’analyse continue et l’amélioration des mécanismes de détection.
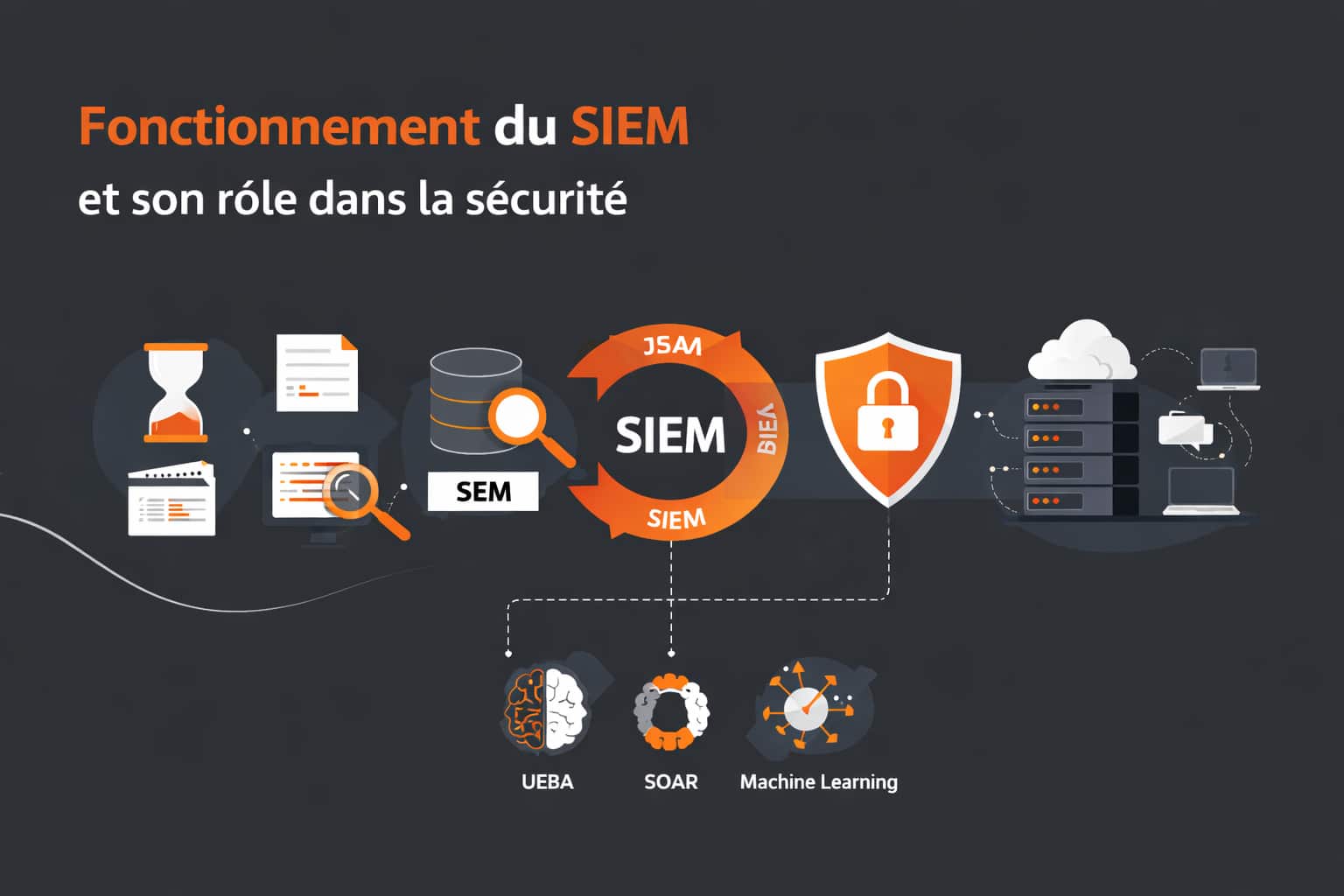
Comprendre le fonctionnement du SIEM et son rôle dans la sécurité
Le SIEM (Security Information and Event Management) s’inscrit dans une évolution progressive des pratiques de sécurité informatique, façonnée par l’augmentation constante des menaces et la complexification des systèmes d’information. Pour bien en comprendre le rôle, il est utile de revenir sur son origine et les transformations qui ont conduit à son adoption généralisée. Dans les années 1990, les entreprises commencent à accumuler des journaux systèmes, principalement pour des besoins techniques : diagnostic, maintenance et audit. À cette époque, les logs sont analysés manuellement ou à l’aide d’outils simples, sans véritable corrélation entre les événements. Avec l’essor d’Internet au début des années 2000 et l’apparition de cyberattaques plus structurées, cette approche devient rapidement insuffisante. C’est dans ce contexte que deux concepts émergent : Le SIM (Security Information Management), centré sur le stockage et l’analyse des logs à long terme, et le SEM (Security Event Management), orienté vers la détection en temps réel. Au milieu des années 2000, ces deux approches convergent pour donner naissance au SIEM tel qu’on le connaît aujourd’hui. Depuis, les solutions SIEM n’ont cessé d’évoluer. Elles intègrent désormais des capacités avancées comme l’analyse comportementale (UEBA), l’automatisation des réponses (SOAR) et l’exploitation du machine learning. Cette évolution répond à un besoin croissant : faire face à des attaques de plus en plus rapides, sophistiquées et difficiles à détecter. Sur le plan fonctionnel, un SIEM repose sur une idée simple mais puissante : centraliser l’ensemble des journaux de sécurité issus de multiples sources afin de les analyser de manière cohérente. Ces sources incluent notamment :
- Les serveurs (Windows, Linux) ;
- Les applications métiers ;
- Les pare-feu et équipements réseau ;
- Les systèmes de détection et de prévention d’intrusion (IDS/IPS) ;
- Les services cloud et environnements virtualisés.
Des solutions reconnues comme Splunk, IBM QRadar ou encore ArcSight illustrent parfaitement cette capacité à agréger des volumes massifs de données en temps réel. Elles permettent de transformer des logs bruts en informations exploitables, facilitant ainsi la détection d’incidents de sécurité. Le fonctionnement d’un SIEM s’articule autour de plusieurs étapes clés, chacune jouant un rôle déterminant dans la chaîne de valeur :
- La collecte : les données sont récupérées depuis différentes sources via des agents, des API ou des protocoles standards comme Syslog ;
- La normalisation : les logs sont convertis dans un format commun pour permettre une analyse cohérente ;
- L’enrichissement : les données sont complétées avec des informations contextuelles (géolocalisation, réputation d’IP, etc.) ;
- La corrélation : des règles permettent de relier plusieurs événements entre eux afin de détecter des scénarios d’attaque ;
- L’analyse : des algorithmes identifient des comportements anormaux ou suspects ;
- L’alerte : des notifications sont générées en cas de menace potentielle ;
- La visualisation : des tableaux de bord facilitent la compréhension et le pilotage.
Avec le temps, les SIEM modernes ont également intégré des capacités de stockage à long terme pour répondre aux exigences réglementaires (comme celles liées à la conformité), ainsi que des fonctions d’investigation avancée pour les équipes SOC (Security Operations Center). L’un des apports majeurs du SIEM réside dans sa capacité à détecter des signaux faibles. Là où un événement isolé pourrait sembler anodin, sa corrélation avec d’autres activités peut révéler une attaque en cours. Par exemple, une connexion depuis un pays inhabituel suivie d’un accès à des données sensibles peut immédiatement déclencher une alerte. Aujourd’hui, avec la montée en puissance du cloud, des architectures hybrides et du télétravail, le rôle du SIEM s’est encore renforcé. Il devient un point central de visibilité dans des environnements distribués, où les frontières traditionnelles du système d’information ont disparu. Ainsi, le SIEM est une plateforme stratégique qui permet de transformer un volume massif de journaux en une intelligence de sécurité exploitable. Grâce à lui, les organisations peuvent non seulement détecter plus rapidement les incidents, mais aussi mieux comprendre leur origine et améliorer en continu leur posture de sécurité.
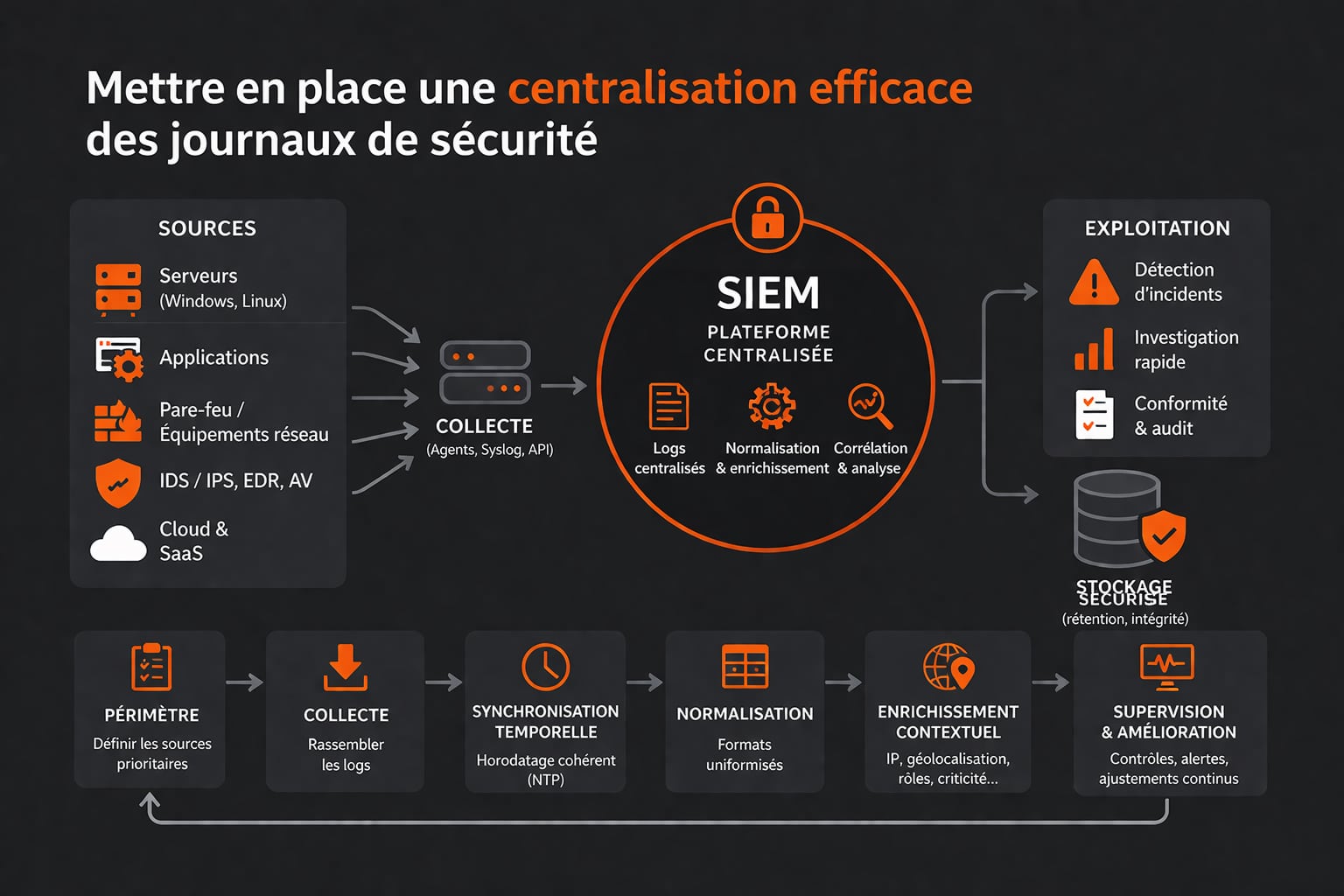
Mettre en place une centralisation efficace des journaux de sécurité
La mise en place d’une centralisation efficace des journaux de sécurité constitue l’un des fondements d’un projet SIEM réussi. Dans de nombreuses organisations, les traces techniques existent déjà, mais elles restent dispersées entre les serveurs, les applications, les équipements réseau, les environnements cloud et les outils de sécurité. Tant que ces informations demeurent cloisonnées, elles perdent une grande partie de leur valeur opérationnelle. Une tentative de connexion anormale sur un annuaire, un changement suspect sur un pare-feu et un accès inhabituel à une application métier peuvent sembler anodins lorsqu’ils sont examinés séparément. Une fois rapprochés dans une même plateforme, ils peuvent au contraire révéler un scénario d’attaque cohérent. Centraliser les logs ne consiste donc pas uniquement à collecter des fichiers ou à remonter des événements dans un outil unique. Il s’agit de bâtir une chaîne de traitement fiable, lisible et exploitable, capable de transformer des données brutes en éléments d’analyse. Cette centralisation doit répondre à plusieurs objectifs en parallèle : améliorer la visibilité, accélérer la détection des incidents, faciliter l’investigation, répondre aux exigences d’audit et renforcer la conservation des preuves en cas de compromission.
La première étape consiste à définir précisément le périmètre de collecte. Une erreur fréquente consiste à vouloir tout remonter sans hiérarchiser les priorités. Cette approche produit rapidement l’effet inverse de celui recherché : Trop de bruit, trop d’événements peu utiles, des coûts de stockage en hausse et des analystes noyés sous les alertes. Une centralisation efficace commence donc par une cartographie des actifs critiques et des événements à forte valeur de sécurité. Les journaux liés aux authentifications, aux élévations de privilèges, aux accès aux données sensibles, aux connexions distantes, aux changements de configuration, aux flux réseau, aux détections antivirus, aux alertes EDR, aux activités d’administration et aux actions sur les comptes à privilèges doivent généralement faire partie des priorités. Cette démarche suppose aussi de tenir compte du contexte métier. Une entreprise industrielle ne surveillera pas exactement les mêmes événements qu’un établissement de santé, une banque ou une plateforme e-commerce. Dans certains cas, les journaux issus des applications métiers sont aussi importants que ceux des composants d’infrastructure, car ils permettent de détecter des fraudes, des usages anormaux ou des actions incompatibles avec le rôle d’un utilisateur. La centralisation doit donc être pensée comme un projet de sécurité aligné sur les risques réels de l’organisation, et non comme une simple opération technique.
Une fois les sources identifiées, il faut organiser la collecte. Celle-ci peut s’appuyer sur différents mécanismes : Agents installés sur les serveurs, protocoles comme Syslog, connecteurs natifs, API cloud, relais intermédiaires ou collecteurs dédiés. Le choix dépend du type de source, du niveau de granularité attendu, des contraintes de performance et des exigences de sécurité. Dans tous les cas, la collecte doit être fiable, horodatée correctement et suffisamment résiliente pour éviter toute perte d’événements. Un journal absent ou tronqué au moment d’un incident peut compromettre toute l’analyse. La question de l’horodatage est d’ailleurs souvent sous-estimée. Pour corréler correctement des événements provenant de dizaines de systèmes différents, il faut que les équipements partagent une référence temporelle cohérente, généralement via NTP. Sans cette synchronisation, il devient difficile de reconstituer précisément une chronologie d’attaque. Quelques minutes d’écart entre plusieurs sources peuvent suffire à brouiller l’investigation, voire à masquer la séquence réelle des actions malveillantes.
Vient ensuite l’étape de la normalisation. Les journaux de sécurité sont naturellement hétérogènes. Un contrôleur de domaine, un pare-feu, une base de données, une application SaaS et un proxy web ne décrivent pas les événements de la même manière. Certains produisent des formats structurés, d’autres des messages textuels plus difficiles à exploiter. La normalisation vise à harmoniser ces données autour de champs communs : date, source, destination, utilisateur, adresse IP, type d’action, niveau de gravité, résultat, identifiant d’événement, équipement concerné ou localisation. C’est cette homogénéisation qui rend possible l’analyse transversale. À ce stade, l’enrichissement des données apporte une valeur supplémentaire. Un log brut indique qu’une adresse IP s’est connectée à un service. Un log enrichi peut préciser que cette IP provient d’un pays inhabituel, qu’elle est associée à un fournisseur cloud souvent utilisé dans des campagnes d’attaque, qu’elle a déjà été observée dans une liste de menaces, ou encore que le compte visé possède des privilèges élevés. Plus le contexte est riche, plus les règles de détection gagnent en pertinence et plus les équipes sécurité peuvent trier rapidement ce qui relève d’une activité normale ou d’un comportement suspect.
La gestion des volumes représente un autre chantier majeur. Les environnements modernes génèrent des quantités considérables de journaux, parfois plusieurs millions d’événements par jour. Sans stratégie de filtrage, de priorisation et de rétention, la plateforme SIEM peut devenir coûteuse, lente et difficile à piloter. Il est donc nécessaire de distinguer les journaux à forte valeur temps réel, ceux utiles à l’investigation différée et ceux conservés principalement pour l’audit ou la conformité. Certaines données méritent une conservation longue, d’autres peuvent être agrégées, échantillonnées ou filtrées en amont selon des règles précises. L’objectif n’est pas de réduire la visibilité, mais d’optimiser la qualité du signal.
La rétention doit elle aussi être définie avec méthode. Elle dépend du cadre réglementaire, des contraintes contractuelles, du secteur d’activité, du niveau de risque et des besoins internes d’investigation. Il faut déterminer combien de temps conserver les données en ligne pour les recherches rapides, combien de temps les archiver, et dans quelles conditions les restaurer en cas d’enquête. Une politique de conservation sérieuse distingue généralement le stockage chaud, accessible immédiatement, et le stockage froid, moins coûteux mais plus lent à consulter. La sécurisation des journaux eux-mêmes est un point déterminant. Les logs ont une valeur probatoire et deviennent souvent des cibles lors d’une attaque. Un acteur malveillant qui obtient un accès privilégié cherchera parfois à effacer ses traces, à modifier l’historique ou à désactiver la remontée d’événements. Pour limiter ce risque, les journaux doivent être transmis de façon sécurisée, stockés dans un environnement protégé, bénéficier d’un contrôle d’accès strict et, lorsque c’est possible, être protégés contre l’altération grâce à des mécanismes d’intégrité. La séparation des rôles, l’immutabilité sur certaines briques de stockage et la supervision de la chaîne de collecte renforcent nettement la fiabilité globale du dispositif.
Il est également essentiel de documenter la qualité de la collecte. Une centralisation efficace ne se résume pas à un déploiement initial. Elle doit être maintenue dans le temps. À chaque évolution du système d’information, ajout d’application, migration cloud, changement d’architecture ou refonte réseau, il faut vérifier que les sources attendues remontent toujours correctement. De nombreuses organisations découvrent lors d’un incident que certains journaux ne sont plus transmis depuis plusieurs semaines, simplement à cause d’un certificat expiré, d’un connecteur cassé ou d’une mise à jour mal appliquée. Des contrôles de complétude, des tableaux de bord de santé et des tests réguliers sont donc indispensables. La centralisation des journaux de sécurité doit enfin être pensée comme un processus vivant. Elle gagne à être améliorée en continu, en fonction des incidents rencontrés, des nouvelles menaces, des retours du SOC et des besoins métiers. Un bon dispositif n’est pas seulement exhaustif ; il est surtout utile, cohérent et actionnable. Lorsqu’elle est bien conçue, la centralisation permet aux équipes de passer d’une logique de collecte subie à une logique d’observation structurée, où chaque événement contribue à une meilleure compréhension du risque. Le tableau ci-dessous résume les grands piliers à prendre en compte pour construire une centralisation robuste, exploitable et durable.
| Étape | Objectif |
|---|---|
| Définition du périmètre | Identifier les actifs, applications, équipements et événements réellement prioritaires pour la sécurité et la conformité |
| Cartographie des sources | Recenser les systèmes producteurs de logs : serveurs, annuaires, pare-feu, proxy, EDR, applications, équipements réseau, services cloud et outils métiers |
| Collecte des événements | Rassembler les journaux depuis différentes sources au moyen d’agents, de connecteurs, d’API ou de protocoles comme Syslog |
| Synchronisation temporelle | Garantir des horodatages cohérents entre toutes les sources pour faciliter la corrélation et la reconstitution chronologique des incidents |
| Normalisation | Uniformiser les formats de données afin de rendre les logs comparables et exploitables dans une même logique d’analyse |
| Enrichissement contextuel | Ajouter des informations utiles comme la criticité d’un actif, la géolocalisation, la réputation d’une IP, le rôle d’un utilisateur ou le niveau de privilège |
| Filtrage et réduction du bruit | Écarter les événements redondants ou peu utiles pour améliorer le rapport signal sur bruit et limiter les coûts inutiles |
| Stockage sécurisé | Conserver les données de manière protégée, intègre et accessible, tout en empêchant leur altération ou leur suppression non autorisée |
| Politique de rétention | Définir la durée de conservation des logs en fonction des besoins d’investigation, des obligations réglementaires et des capacités de stockage |
| Contrôle d’accès | Limiter la consultation, l’administration et l’export des journaux aux seules personnes autorisées selon le principe du moindre privilège |
| Supervision de la chaîne de collecte | Vérifier en continu que les connecteurs, agents et flux de remontée fonctionnent correctement et qu’aucune source ne devient muette |
| Corrélation | Identifier des relations entre événements dispersés afin de faire émerger des scénarios d’attaque, des comportements suspects ou des anomalies |
| Préparation à l’investigation | Faciliter les recherches, les pivots d’analyse et la restitution des événements pour accélérer la réponse à incident |
| Amélioration continue | Faire évoluer la collecte et les priorités en fonction des incidents observés, des nouvelles menaces, des changements d’architecture et des besoins du SOC |
En pratique, une centralisation efficace des journaux de sécurité repose sur un équilibre. Il faut être suffisamment large pour ne pas créer d’angles morts, mais suffisamment sélectif pour préserver la lisibilité de la plateforme. Il faut collecter vite, mais aussi collecter juste. Il faut stocker beaucoup, tout en sachant hiérarchiser. C’est cette combinaison entre couverture, qualité, sécurité et gouvernance qui permet à un SIEM de devenir un véritable outil d’aide à la décision, et non un simple réceptacle de logs.
Exploiter les journaux pour détecter et anticiper les menaces
Une fois les journaux de sécurité correctement centralisés, l’enjeu ne réside plus dans la collecte, mais dans leur exploitation intelligente. C’est à ce moment précis que le SIEM prend toute sa dimension. Il ne s’agit plus seulement d’observer des événements isolés, mais de leur donner du sens, de les relier entre eux et d’identifier des schémas révélateurs d’activités malveillantes. Grâce à des règles de corrélation, le SIEM est capable d’associer plusieurs événements qui, pris individuellement, pourraient sembler anodins. Par exemple, une succession de tentatives de connexion échouées suivie d’un accès réussi sur un compte sensible peut signaler une attaque par force brute. De la même manière, une connexion depuis une localisation inhabituelle, combinée à un téléchargement massif de données, peut indiquer une compromission en cours. Au-delà des règles statiques, les solutions modernes intègrent des mécanismes d’analyse comportementale. Elles établissent une base de référence des comportements normaux (horaires de connexion, volumes d’échange, usages applicatifs) et détectent automatiquement les écarts. Cette capacité permet d’identifier des menaces plus discrètes, notamment celles qui échappent aux signatures classiques. Les SIEM permettent également d’automatiser certaines réponses. Lorsqu’un scénario suspect est détecté, des actions peuvent être déclenchées sans intervention humaine : blocage d’une adresse IP, suspension d’un compte, isolement d’un poste ou génération d’un ticket d’incident. Cette automatisation réduit considérablement le temps de réaction et limite l’impact des attaques.
L’exploitation des logs ne se limite pas à la réaction. Elle s’inscrit aussi dans une démarche d’anticipation. En analysant les tendances, les fréquences d’événements et les signaux faibles, il devient possible d’identifier des comportements précurseurs d’attaque. Cette approche permet d’agir en amont, avant même qu’un incident majeur ne survienne.
L’intégration avec des outils d’analyse avancée comme Elasticsearch ou des plateformes de visualisation telles que Grafana renforce encore ces capacités. Elle permet de naviguer dans de grands volumes de données, de créer des tableaux de bord dynamiques et de faciliter l’investigation lors d’un incident. Enfin, l’apport de l’intelligence artificielle et du machine learning transforme progressivement les capacités des SIEM. Ces technologies permettent de détecter des anomalies complexes, d’ajuster automatiquement les modèles de détection et de réduire les faux positifs. Elles contribuent à rendre la surveillance plus fine, plus adaptative et plus pertinente face à des menaces en constante évolution. Pour structurer efficacement cette exploitation, plusieurs étapes clés peuvent être distinguées :
| Étape | Objectif |
|---|---|
| Définition des cas d’usage | Identifier les scénarios de menace à surveiller en priorité selon le contexte métier et les risques |
| Mise en place des règles de corrélation | Détecter des combinaisons d’événements révélatrices d’attaques ou de comportements anormaux |
| Analyse comportementale | Identifier les écarts par rapport aux usages habituels des utilisateurs et des systèmes |
| Détection en temps réel | Repérer immédiatement les incidents pour réduire le délai de réaction |
| Génération d’alertes | Notifier les équipes de sécurité avec des informations contextualisées et exploitables |
| Automatisation des réponses | Déclencher des actions automatiques pour contenir rapidement une menace |
| Investigation | Analyser les événements en profondeur pour comprendre l’origine et l’impact d’un incident |
| Visualisation | Suivre l’activité de sécurité via des tableaux de bord clairs et dynamiques |
| Analyse des tendances | Identifier des signaux faibles et des évolutions dans les comportements à risque |
| Amélioration continue | Ajuster les règles, affiner les détections et enrichir les scénarios au fil du temps |
Exploiter les journaux de sécurité ne consiste donc pas uniquement à détecter des incidents, mais à construire une véritable intelligence de sécurité. En combinant corrélation, automatisation, analyse avancée et amélioration continue, le SIEM devient un outil central pour anticiper les menaces et renforcer durablement la résilience du système d’information.

0 commentaires