Le reverse proxy agit comme un intermédiaire stratégique entre les utilisateurs et les serveurs web. Il réceptionne les requêtes entrantes, les analyse, puis les transmet au bon serveur en arrière-plan, avant de renvoyer la réponse au client. Invisible pour l’utilisateur final, il joue un rôle essentiel dans la fluidité et la sécurisation des échanges. Souvent méconnu, ce composant technique est pourtant au cœur de nombreuses architectures web modernes. Il permet de répartir la charge, de mettre en cache les contenus, de filtrer les attaques et d’unifier les points d’accès à différents services. Dans cet article, découvrons en détail le fonctionnement et les usages d’un reverse proxy.
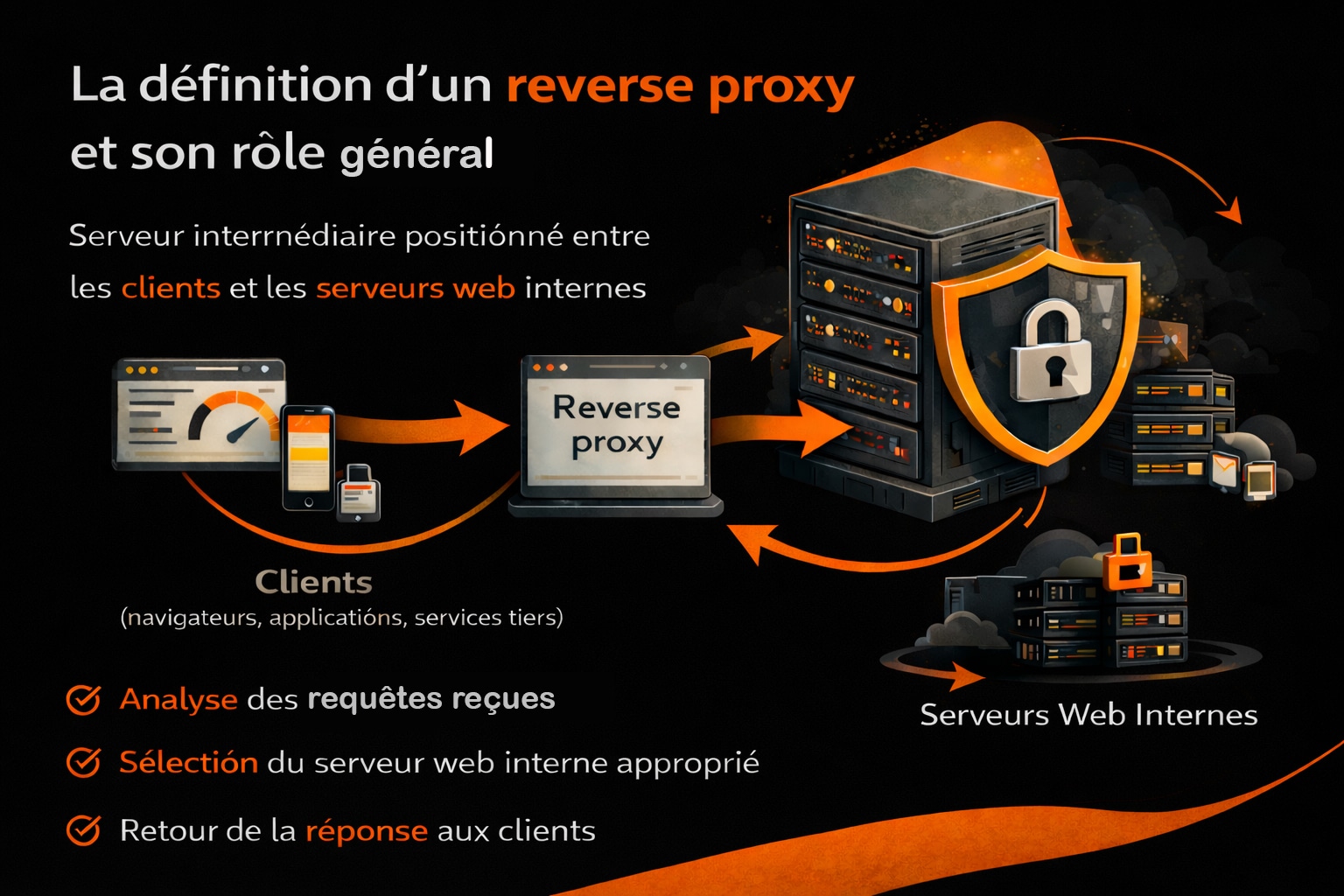
La définition d’un reverse proxy et son rôle général
Un reverse proxy, aussi appelé mandataire inversé, est un serveur intermédiaire positionné entre les clients (navigateurs web, applications mobiles, services tiers) et un ou plusieurs serveurs web internes. Contrairement au proxy classique (ou forward proxy), historiquement utilisé dans les entreprises pour contrôler et filtrer les accès des utilisateurs vers Internet, le reverse proxy agit pour le compte des serveurs. Il reçoit les requêtes entrantes, les analyse et les redirige vers les ressources internes appropriées. Le concept de proxy trouve ses origines dans les années 1990, à une époque où la croissance rapide du Web posait déjà des problématiques de bande passante, de sécurité et de contrôle des accès. Les premiers proxies étaient principalement déployés dans des universités et des grandes entreprises, notamment aux États-Unis et en Europe, pour mutualiser les connexions Internet et limiter la charge sur les réseaux. Le reverse proxy est apparu plus tard, avec l’essor des sites web dynamiques, du e-commerce et des infrastructures à forte audience.
À mesure que les applications web se sont complexifiées, notamment avec l’arrivée des architectures multi-serveurs, le reverse proxy s’est imposé comme une brique centrale. Il se positionne en amont des serveurs d’applications ou de contenu, devenant le point d’entrée unique visible depuis Internet. Lorsqu’un client envoie une requête HTTP ou HTTPS, celle-ci transite systématiquement par le reverse proxy, qui orchestre le traitement :
- Analyse de la requête (méthode HTTP, en-têtes, origine, URL, protocole) ;
- Sélection du serveur backend le plus approprié selon des règles définies ;
- Transmission de la requête vers le serveur interne concerné ;
- Retour de la réponse au client, sans exposer l’infrastructure réelle.
Cette approche permet de masquer totalement les serveurs internes, tant sur le plan réseau que logique. Le client n’interagit jamais directement avec le serveur d’application ou de base de données. Pour lui, le reverse proxy représente le serveur final, garantissant une abstraction complète de l’architecture sous-jacente. Avec l’essor des centres de données, du cloud computing et plus récemment des architectures microservices, le rôle du reverse proxy a considérablement évolué. Il ne se limite plus à une simple redirection de requêtes, mais devient un véritable point de contrôle centralisé. Des solutions comme NGINX, né en Russie au début des années 2000 pour répondre à des problématiques de montée en charge, ou HAProxy, largement adopté dans les infrastructures critiques européennes, ont contribué à populariser ce modèle.
À l’échelle mondiale, des services comme Cloudflare exploitent aujourd’hui le principe du reverse proxy à grande échelle, en s’appuyant sur des réseaux de serveurs répartis dans des centaines de villes. Ces infrastructures permettent de rapprocher le contenu des utilisateurs finaux tout en renforçant la sécurité et la résilience des sites web.
Le reverse proxy s’impose ainsi comme un composant structurant des architectures web modernes, à la croisée des enjeux de performance, de sécurité et de gestion des flux. Son rôle général dépasse désormais la simple intermédiation pour devenir un pilier de l’ingénierie web contemporaine.
Le fonctionnement technique et les cas d’usages concrets du reverse Proxy
Le reverse proxy est souvent déployé pour simplifier et optimiser la distribution de trafic dans une infrastructure complexe. Voici ses fonctions les plus courantes :
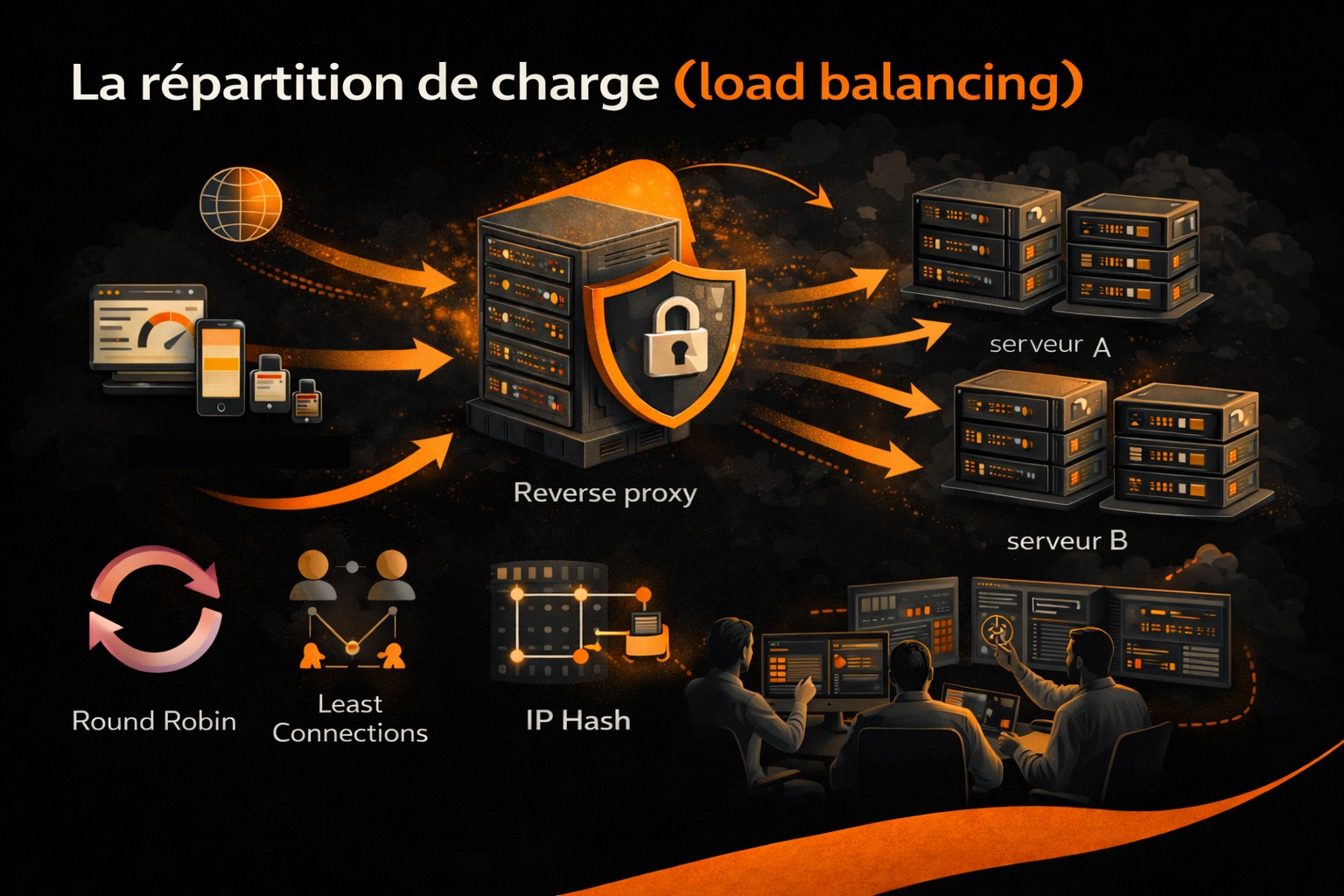
1. La répartition de charge (load balancing)
Le reverse proxy joue un rôle central dans la répartition de charge, aussi appelée load balancing, en distribuant les requêtes entrantes vers un ensemble de serveurs back-end appelés nœuds. Cette fonction est indispensable dans les architectures à haute disponibilité, notamment pour les sites à fort trafic, les API RESTful, les microservices ou les applications cloud-native. Sans reverse proxy, toutes les requêtes d’un site web atterriraient sur un même serveur, ce qui créerait rapidement un goulot d’étranglement en cas de montée en charge. En interposant un reverse proxy, il devient possible de faire circuler le trafic de manière intelligente et équilibrée entre plusieurs serveurs Web par exemple, chacun hébergeant tout ou partie de l’application ou du site concerné. Le reverse proxy utilise des algorithmes de répartition pour décider vers quel serveur diriger chaque requête. Les plus courants sont :
- Round Robin : envoie les requêtes à tour de rôle à chaque serveur. Simple mais sans prise en compte de la charge actuelle.
- Least Connections : privilégie le serveur ayant le moins de connexions actives au moment de la requête.
- IP Hash : attribue un serveur en fonction de l’adresse IP du client, utile pour la persistance de session (affinité).
- Weighted algorithms : attribue un poids à chaque serveur selon ses capacités (CPU, RAM, latence, etc.).
Certains reverse proxies avancés intègrent des mécanismes de monitoring en temps réel, leur permettant de détecter l’état de santé des serveurs (grâce à des probes HTTP, TCP ou des scripts personnalisés) et de retirer temporairement un nœud du pool en cas de dysfonctionnement — on parle alors de health check ou de failover automatique. Dans une infrastructure avec trois serveurs web (appelés backend1, backend2 et backend3), le reverse proxy peut par exemple appliquer une stratégie Least Connections pour équilibrer le trafic. Si backend2 est actuellement le moins sollicité, la requête lui sera routée, réduisant ainsi le temps de traitement global et répartissant efficacement les ressources serveur.
La répartition de charge peut s’effectuer sur différents protocoles : HTTP, HTTPS, mais aussi TCP et UDP pour les reverse proxies de niveau 4. En niveau 7 (couche applicative), elle peut même prendre en compte des critères comme l’URL, les en-têtes HTTP ou les cookies, ce qui permet un load balancing contextuel. Ce mécanisme améliore ainsi :
- La scalabilité horizontale : En ajoutant de nouveaux serveurs dans le pool à la volée ;
- La résilience : En isolant automatiquement les serveurs défectueux ;
- Les performances : En réduisant la latence et en évitant les engorgements
Le reverse proxy devient donc un répartiteur intelligent, capable d’analyser le contexte, de mesurer la charge en temps réel, et d’assurer un fonctionnement fluide de l’ensemble de l’application, même en cas de forte affluence ou de panne partielle.
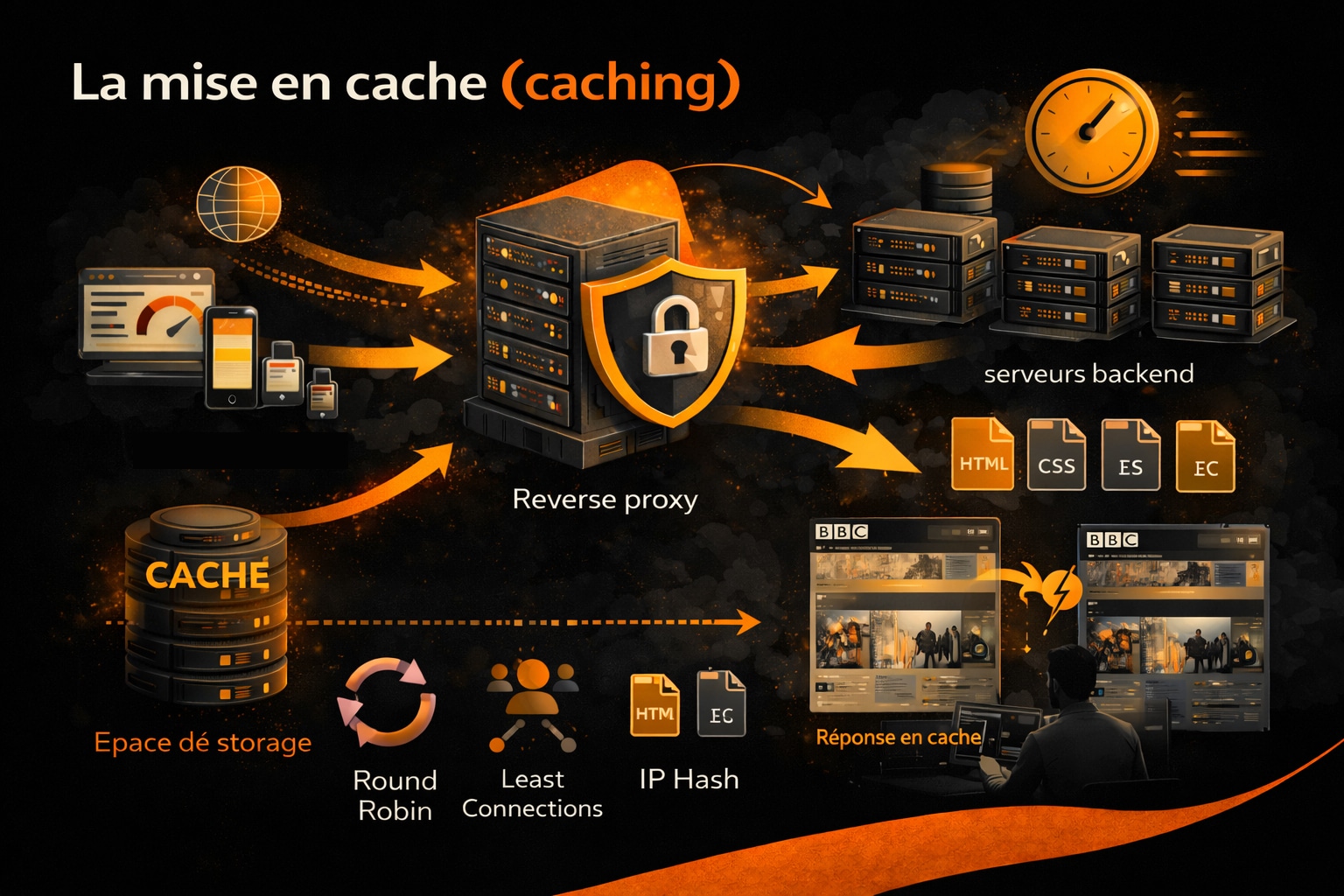
2. La mise en cache (caching)
La mise en cache est l’un des apports majeurs d’un reverse proxy en matière de performance. Elle consiste à stocker temporairement les réponses générées par les serveurs backend afin de pouvoir les réutiliser lors de requêtes identiques ou similaires, sans solliciter à nouveau l’infrastructure applicative. Concrètement, lorsqu’un client demande une ressource (page HTML, image, feuille de style CSS, fichier JavaScript ou réponse d’API), le reverse proxy intercepte la réponse du serveur et peut décider de la conserver dans un espace de stockage dédié (mémoire vive, disque ou cache distribué). Lorsqu’une requête équivalente se présente, le reverse proxy sert directement la version mise en cache, réduisant drastiquement le temps de réponse. La décision de mise en cache repose sur plusieurs paramètres techniques, notamment :
- Les en-têtes HTTP (
Cache-Control,Expires,ETag,Last-Modified) - Le type de contenu (statique ou dynamique)
- La méthode HTTP (principalement
GETetHEAD) - Les règles de cache définies dans la configuration du reverse proxy
Un reverse proxy avancé, comme NGINX ou Varnish, peut implémenter des stratégies de cache sophistiquées, incluant :
- Cache en mémoire pour des réponses très fréquentes à faible latence ;
- Cache sur disque pour des volumes de données plus importants ;
- Cache avec expiration contrôlée (TTL – Time To Live) ;
- Cache conditionnel basé sur des cookies, des en-têtes ou des paramètres d’URL.
Dans les environnements dynamiques, le reverse proxy peut également gérer des mécanismes de validation du cache. Par exemple, grâce aux en-têtes If-None-Match ou If-Modified-Since, il peut vérifier si une ressource a changé avant de renvoyer la version stockée, évitant ainsi des transferts inutiles. La mise en cache en reverse proxy est particulièrement efficace dans les cas suivants :
- Sites à fort trafic avec un contenu majoritairement identique pour tous les utilisateurs ;
- Applications web exposant des API publiques ;
- Plateformes e-commerce avec des pages catalogue fréquemment consultées.
Sur le plan opérationnel, ce mécanisme permet de :
- Réduire la charge CPU et mémoire des serveurs backend ;
- Diminuer la latence perçue par l’utilisateur final ;
- Absorber des pics de trafic sans dégrader le service ;
- Limiter les coûts d’hébergement et de montée en charge.
En agissant comme une couche de cache intermédiaire, le reverse proxy devient un accélérateur applicatif à part entière. Il contribue à lisser les variations de trafic tout en améliorant la stabilité globale de l’infrastructure, notamment lors d’événements à forte audience ou de campagnes marketing générant un afflux massif de visiteurs.
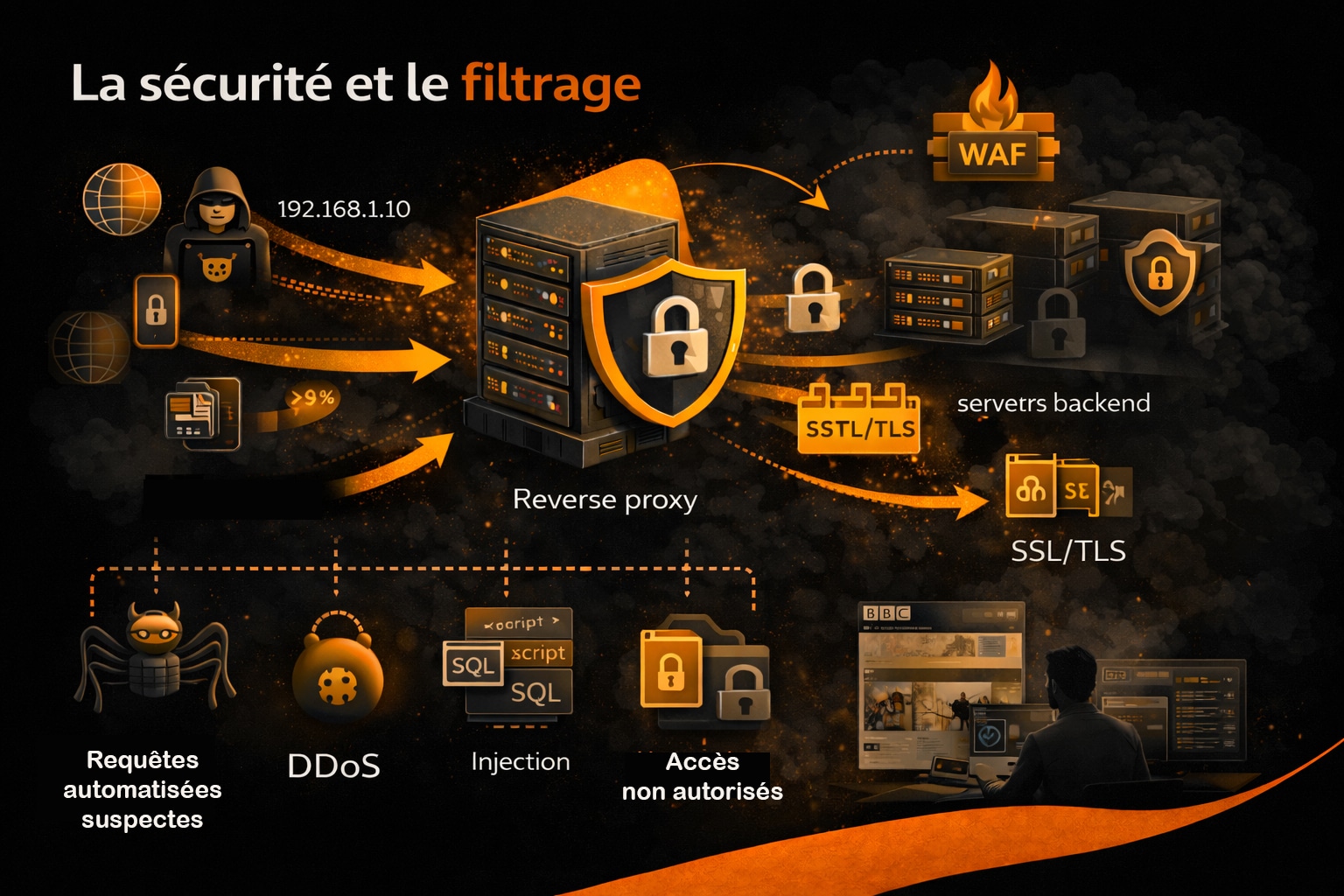
3. La sécurité et le filtrage
Le reverse proxy constitue une première ligne de défense entre Internet et les serveurs internes. En centralisant le point d’entrée de l’infrastructure, il permet de contrôler, analyser et filtrer l’ensemble des flux entrants avant qu’ils n’atteignent les applications. Cette position stratégique en fait un composant majeur des dispositifs de sécurité web modernes. L’un des premiers apports du reverse proxy en matière de sécurité réside dans le masquage de l’infrastructure réelle. Les adresses IP des serveurs backend, leurs ports et parfois même leurs technologies ne sont jamais exposés publiquement. Un attaquant ne peut interagir qu’avec le reverse proxy, ce qui réduit considérablement la surface d’attaque directe. Au-delà de cette fonction d’abstraction réseau, le reverse proxy est capable de mettre en œuvre des mécanismes de filtrage actif. Il peut analyser chaque requête HTTP ou HTTPS afin de détecter des comportements anormaux ou malveillants, tels que :
- Les attaques par déni de service distribué (DDoS), via la limitation de débit (rate limiting) ou le blocage d’IP ;
- Les tentatives d’injection SQL ou de scripts (XSS) identifiées dans les paramètres d’URL ou les corps de requête ;
- Les requêtes automatisées suspectes (bots, scanners, crawlers agressifs) ;
- Les accès non autorisés à des ressources sensibles.
Pour renforcer ces capacités, de nombreux reverse proxies intègrent ou s’appuient sur des pare-feu applicatifs web (Web Application Firewall – WAF). Ces derniers appliquent des règles basées sur des signatures connues, des heuristiques comportementales ou des modèles de trafic. Des solutions comme ModSecurity, intégré à NGINX ou Apache, permettent par exemple de bloquer automatiquement des schémas d’attaque répertoriés dans les règles OWASP. Le reverse proxy joue également un rôle central dans la gestion du chiffrement. En assurant la terminaison SSL/TLS, il prend en charge :
- La négociation des protocoles et des suites cryptographiques
- Le déchiffrement des requêtes entrantes
- La gestion et le renouvellement des certificats
Les serveurs backend peuvent ainsi fonctionner sur des connexions internes non chiffrées, simplifiant leur configuration tout en maintenant un haut niveau de sécurité sur le périmètre externe. Sur des architectures plus avancées, le reverse proxy peut également imposer des règles de sécurité supplémentaires, comme :
- L’authentification préalable (JWT, OAuth2, authentification mutualisée)
- Le contrôle des en-têtes HTTP (HSTS, CSP, X-Frame-Options)
- La segmentation des accès selon l’origine géographique ou le type de client
En concentrant l’ensemble de ces mécanismes sur une seule couche d’entrée, le reverse proxy permet une gestion centralisée de la sécurité. Cela facilite les audits, la maintenance et les mises à jour des règles de protection, tout en réduisant les risques d’erreurs de configuration dispersées sur plusieurs serveurs applicatifs.
Le reverse proxy ne se substitue pas aux mesures de sécurité internes, mais il constitue un rempart efficace qui filtre, amortit et bloque une grande partie des menaces avant qu’elles n’atteignent les composants les plus sensibles de l’infrastructure.
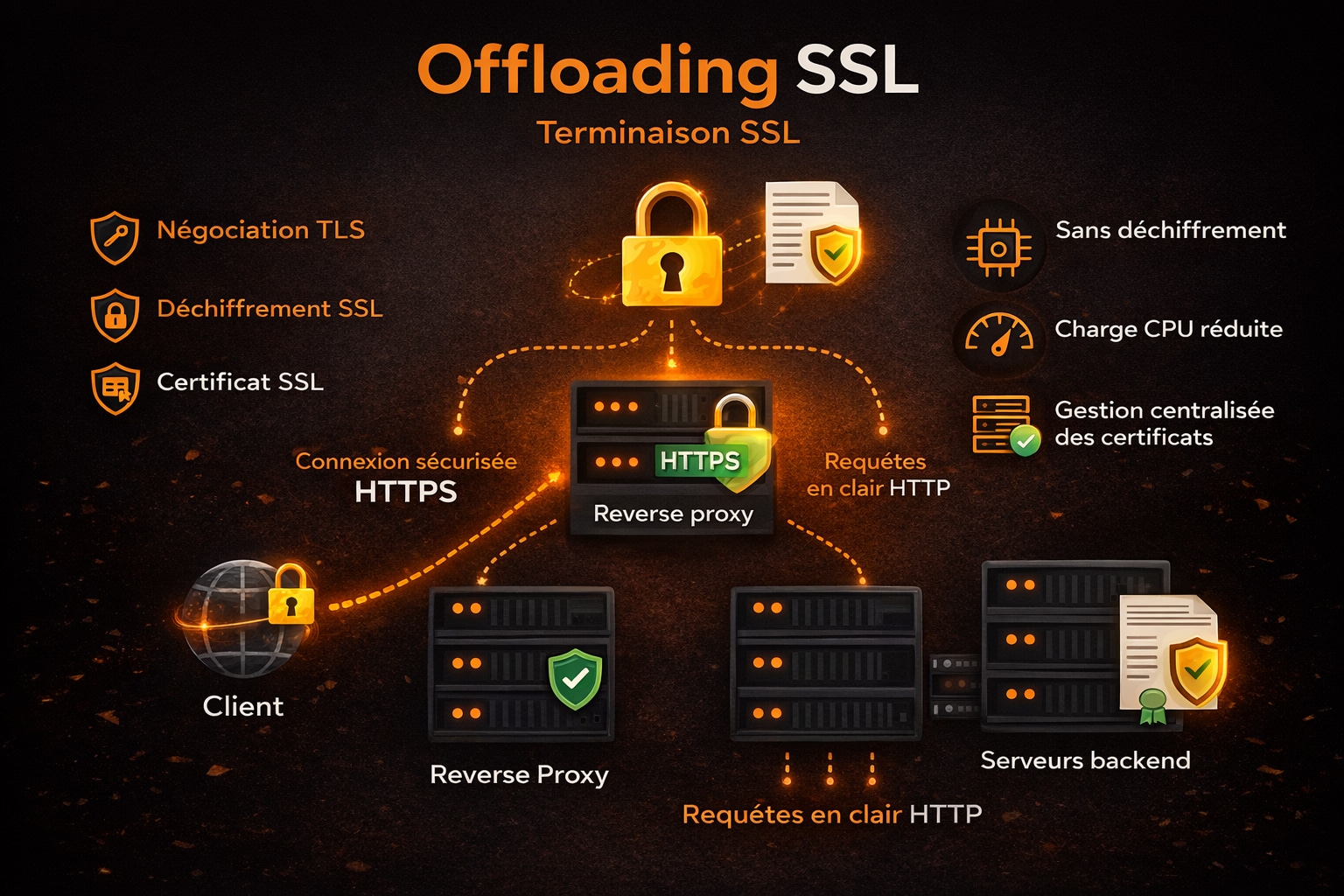
4. Offloading SSL (terminaison SSL)
L’offloading SSL, également appelé terminaison SSL/TLS, consiste à déléguer au reverse proxy la gestion complète du chiffrement des connexions sécurisées. Dans ce modèle, le reverse proxy devient le point de terminaison HTTPS visible depuis Internet, tandis que les serveurs backend reçoivent des requêtes en clair sur le réseau interne. Le protocole SSL/TLS repose sur des mécanismes cryptographiques complexes, incluant des opérations de chiffrement asymétrique lors de la négociation initiale, puis de chiffrement symétrique pour le transfert des données. Ces opérations sollicitent fortement le processeur, en particulier lors d’un grand nombre de connexions simultanées. En centralisant cette charge sur un reverse proxy optimisé, il est possible de libérer des ressources significatives sur les serveurs applicatifs. Lorsqu’un client établit une connexion HTTPS, le reverse proxy prend en charge :
- La négociation du protocole TLS et de la version supportée ;
- Le choix des suites cryptographiques compatibles ;
- La validation et la présentation du certificat SSL ;
- Le déchiffrement des requêtes entrantes et le chiffrement des réponses sortantes.
Une fois la connexion sécurisée établie, le reverse proxy transmet la requête au serveur backend via une connexion HTTP ou HTTPS interne, selon les exigences de sécurité de l’infrastructure. Dans les environnements cloisonnés (réseaux privés, VLAN, VPC), cette approche simplifie considérablement la configuration des serveurs applicatifs. La terminaison SSL facilite également la gestion centralisée des certificats. Au lieu de déployer et maintenir des certificats SSL sur chaque serveur backend, un seul point de configuration est nécessaire. Cela réduit les risques d’expiration, d’erreur de configuration ou d’incohérence entre environnements. Des outils d’automatisation, comme Let’s Encrypt ou des solutions PKI internes, peuvent être intégrés directement au reverse proxy. D’un point de vue performance, l’offloading SSL permet :
- Une meilleure absorption des pics de trafic HTTPS
- Une réduction de la charge CPU sur les serveurs applicatifs
- Une optimisation du temps de réponse global
Sur les reverse proxies modernes, la gestion SSL/TLS est souvent couplée à des optimisations avancées, telles que :
- La reprise de session TLS (session resumption) ;
- Le support de HTTP/2 et HTTP/3 (QUIC) ;
- L’activation de mécanismes de sécurité comme HSTS.
Dans les architectures à grande échelle, notamment dans le cloud ou les environnements conteneurisés, l’offloading SSL devient un élément structurant. Il permet d’unifier la politique de chiffrement, de simplifier les déploiements et d’assurer un niveau de sécurité homogène sur l’ensemble des services exposés.
En déléguant la terminaison SSL au reverse proxy, l’infrastructure gagne ainsi en performance, en cohérence et en maintenabilité, tout en respectant les standards actuels de sécurité des échanges sur le Web.
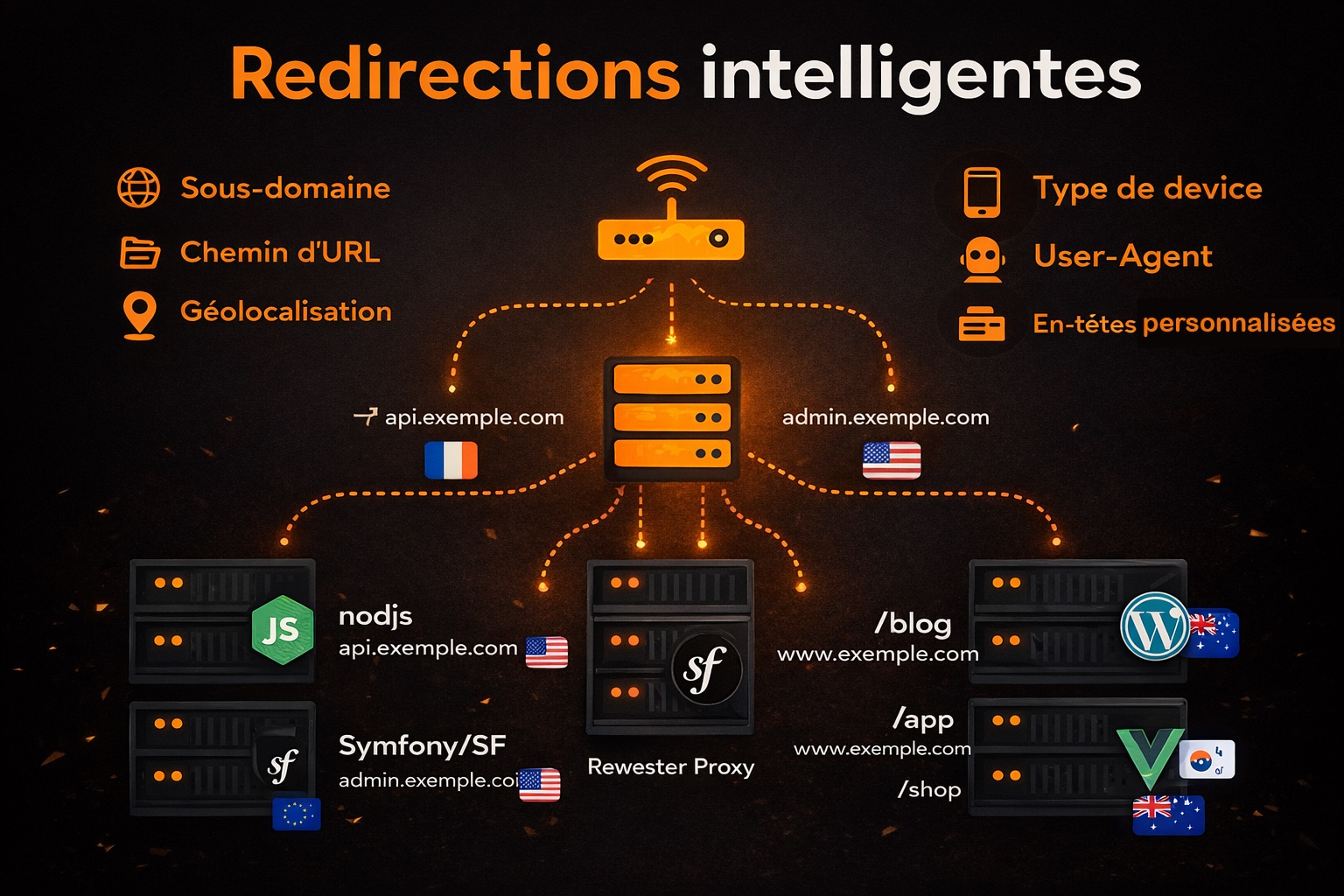
5. Redirections intelligentes
En plus de répartir les requêtes ou de sécuriser les échanges, le reverse proxy est capable d’effectuer des redirections intelligentes, également appelées routage conditionnel ou dynamic routing. Cette capacité repose sur l’analyse fine des informations contenues dans les requêtes entrantes, ce qui permet de les router vers des serveurs ou des services spécifiques en fonction de critères définis. Ce type de routage est particulièrement utile dans des architectures modernes, où différents services coexistent derrière un point d’entrée unique. Le reverse proxy devient alors un routeur applicatif de niveau 7, capable de prendre des décisions contextuelles basées sur des éléments de la couche application du modèle OSI. Voici quelques exemples concrets de critères utilisés pour les redirections :
- Le sous-domaine : Une requête vers
api.exemple.compeut être redirigée vers une API Node.js, tandis queadmin.exemple.comcible un back-office sous Symfony ou Laravel ; - Le chemin d’URL : Les requêtes vers
/blogpeuvent être dirigées vers un CMS (WordPress), tandis que/apppointe vers une application SPA hébergée séparément ; - L’adresse IP ou la géolocalisation de l’utilisateur : Utile pour rediriger vers des serveurs régionaux (Europe, Asie, Amérique) ou appliquer des règles spécifiques à certains pays (ex. : restrictions légales) ;
- Le type de device ou l’User-Agent : Pour proposer des interfaces spécifiques aux mobiles, tablettes ou bots ;
- Les en-têtes personnalisés : Utilisés pour gérer des versions différentes d’une application, par exemple dans des stratégies de déploiement progressif (canary release ou blue/green deployment).
Dans les environnements conteneurisés (Kubernetes, Docker Swarm), cette capacité de routage dynamique est essentielle. Le reverse proxy peut s’intégrer à des orchestrateurs via des service discovery automatiques, redirigeant chaque type de requête vers le bon pod ou le bon container en fonction des règles déclaratives. Les reverse proxies comme Traefik, NGINX, ou encore Envoy Proxy sont capables de parser des informations complexes (headers, cookies, méthodes HTTP, etc.) pour appliquer des règles de redirection dynamiques. Certains peuvent même intégrer des langages de templating ou des expressions conditionnelles pour affiner les correspondances de routage. Ce type de redirection conditionnelle est particulièrement utile dans les cas suivants :
- Architecture microservices : chaque microservice est mappé sur un chemin ou un domaine précis ;
- Applications multilingues : détection de la langue du navigateur ou du pays d’origine pour rediriger vers la bonne version ;
- Portails multisites : plusieurs sites sont hébergés sur une même infrastructure, différenciés par domaine ou chemin ;
- Déploiements évolutifs : les versions alpha, beta et production cohabitent et sont servies à différents groupes d’utilisateurs.
En orchestrant ces redirections de manière souple et granulaire, le reverse proxy devient un outil stratégique pour gérer la complexité croissante des architectures web. Il permet d’unifier l’accès à des services hétérogènes, de personnaliser l’expérience utilisateur en fonction de son contexte, et de simplifier le déploiement progressif de nouvelles fonctionnalités.
Cette capacité de routage intelligent renforce la flexibilité, la résilience et l’évolutivité des systèmes, en apportant une couche d’intelligence réseau directement au niveau de l’entrée HTTP.
Les solutions les plus utilisées pour mettre en place un reverse proxy
Le choix d’un reverse proxy dépend fortement de l’architecture globale, des besoins fonctionnels, des contraintes de performance, de la scalabilité attendue et du niveau d’automatisation souhaité. Il existe aujourd’hui plusieurs solutions, open source ou commerciales, capables de jouer ce rôle stratégique dans des environnements variés : infrastructure bare metal, machines virtuelles, conteneurs, cloud public ou hybride. Certains reverse proxies sont conçus pour la simplicité de configuration, d’autres pour les performances extrêmes ou l’intégration avancée dans des stacks cloud-native. Les critères de sélection incluent souvent :
- La compatibilité avec les protocoles (HTTP/1.1, HTTP/2, TCP, UDP, gRPC…) ;
- Le support du load balancing, du SSL/TLS et du caching ;
- La capacité à gérer le service discovery et les microservices ;
- L’intégration à l’écosystème DevOps (Kubernetes, Docker, CI/CD, observabilité…).
Voici un aperçu des reverse proxies les plus utilisés actuellement, avec leurs points forts techniques et les scénarios où ils excellent :
| Solution | Points forts | Cas d’usage |
|---|---|---|
| NGINX | Léger, modulaire, haute performance Supporte le SSL/TLS, HTTP/2, WebSockets, caching Load balancing statique ou dynamique Configuration déclarative avec blocs location, upstream… |
Sites web à fort trafic Reverse proxy simple à maintenir API gateway dans des architectures REST Proxy frontal dans les PaaS internes |
| Apache HTTP Server (mod_proxy) | Intégré à l’écosystème Apache Supporte mod_proxy, mod_proxy_http, mod_proxy_balancer Large base installée, bonne documentation Flexible pour les configurations avancées |
Infrastructures existantes basées sur Apache Migration vers HTTPS avec mod_ssl Sites avec besoins modérés en charge Applications PHP historiques |
| HAProxy | Réputé pour sa robustesse et sa scalabilité Load balancing TCP/HTTP avancé Support du health check natif et du stickiness Très utilisé dans les architectures bancaires, télécoms, cloud |
Infrastructures critiques avec haute disponibilité Répartition de charge sur de multiples serveurs Couplage avec Consul, Etcd ou Keepalived Architectures orientées performance brute |
| Traefik | Conçu pour les microservices et containers Intégration native avec Docker, Kubernetes, Consul Support du routing dynamique via étiquettes et annotations Dashboard intégré, Let’s Encrypt automatisé |
Environnements cloud-native Stack DevOps avec CI/CD Applications conteneurisées avec routage dynamique Déploiements évolutifs dans Kubernetes |
| Cloudflare (SaaS) | Reverse proxy géré en mode SaaS (Software as a Service) Protection DDoS, WAF, cache global via CDN HTTP/3, Argo Smart Routing, Zero Trust Aucun déploiement serveur nécessaire |
Sites exposés au public nécessitant performance et sécurité Simplification de la gestion SSL/TLS Accélération globale via réseau Edge Protection contre attaques L3/L7 |
Ces solutions ne sont pas exclusives entre elles. Il est courant, dans des infrastructures complexes, de combiner plusieurs reverse proxies à différents niveaux. Par exemple, un HAProxy peut gérer le trafic TCP/HTTP au niveau d’un datacenter, tandis que NGINX ou Traefik s’occupent du routage applicatif en frontal des microservices.
Le bon choix dépendra donc toujours de l’architecture cible, de l’expérience des équipes, des contraintes de scalabilité, et des objectifs de performance ou de sécurité recherchés.

0 commentaires