Que vous soyez développeur, analyste de données ou simplement curieux du fonctionnement des applications modernes, vous avez probablement déjà croisé le nom PostgreSQL. Derrière ce nom un peu énigmatique se cache un puissant système de gestion de base de données relationnelle utilisé dans le monde entier, aussi bien par des startups que par des géants du web. Mais que signifie réellement « PostgreSQL » ? Quelle est son histoire, ses particularités, et pourquoi est-elle autant plébiscitée ? Cet article vous propose une immersion complète dans l’univers de PostgreSQL, ses fondements, son fonctionnement et ses usages dans l’écosystème numérique contemporain.
Les origines historiques et l’évolution de postgresql
Pour comprendre pleinement ce qu’est PostgreSQL, il faut remonter à une époque charnière de l’informatique moderne : les années 1970. C’est à cette période que le concept même de base de données relationnelle prend forme, sous l’impulsion du chercheur britannique Edgar F. Codd. Travaillant chez IBM à San José, en Californie, Codd publie en 1970 un article fondateur intitulé « A Relational Model of Data for Large Shared Data Banks », dans lequel il propose un modèle mathématique rigoureux pour organiser et interroger les données via des relations (tables) et des opérations logiques. Cette théorie allait bouleverser les systèmes de stockage, alors dominés par des structures hiérarchiques ou en réseau, bien plus rigides.
À des milliers de kilomètres de là, sur la côte ouest des États-Unis, à l’Université de Californie à Berkeley, le professeur Michael Stonebraker s’enthousiasme pour ce nouveau paradigme. Il lance en 1973, avec Eugene Wong et d’autres chercheurs, le projet Ingres (INteractive Graphics and REtrieval System), qui vise à concrétiser les idées de Codd dans un système opérationnel. Ingres devient rapidement l’un des premiers SGBD relationnels fonctionnels, et influence directement la création de produits commerciaux comme Sybase, SQL Server ou encore Informix. Plusieurs ingénieurs ayant travaillé sur Ingres fondent ensuite leurs propres entreprises, disséminant ainsi les principes relationnels dans toute l’industrie. Mais Stonebraker n’en reste pas là. Insatisfait des limites d’Ingres, notamment en matière de flexibilité des types de données et d’intégration des objets, il lance en 1986 un nouveau projet baptisé POSTGRES (pour « Post-Ingres »). L’objectif est clair : créer un système capable non seulement de gérer les données relationnelles classiques, mais aussi de traiter des structures plus complexes, comme les objets, les ensembles imbriqués ou encore les hiérarchies. Ce projet visionnaire est financé en partie par le DARPA et la NSF, deux organismes américains de recherche stratégique, preuve de l’importance accordée à la gestion des données à l’époque.
POSTGRES introduit alors des innovations techniques majeures : un moteur transactionnel avancé, une gestion fine des journaux de transactions (WAL pour Write-Ahead Logging), la possibilité de définir ses propres types de données (user-defined types), et surtout une architecture modulaire pensée pour l’extensibilité. Ces fondations techniques deviendront la marque de fabrique du futur PostgreSQL. En 1995, à mesure que le langage SQL s’impose comme standard de requêtage dans le monde entier, les développeurs de POSTGRES décident d’en intégrer la compatibilité. Ce tournant marque le passage de POSTGRES à PostgreSQL, nom officialisé en 1996. Contrairement à une idée reçue, le nom PostgreSQL ne désigne pas une « version postérieure de SQL », mais bien la combinaison historique entre Postgres et SQL.
Le projet entre alors dans une nouvelle ère. Sa gestion devient communautaire, avec un groupe central de développeurs bénévoles répartis dans plusieurs pays : États-Unis, Allemagne, Japon, Russie, France… PostgreSQL n’appartient à aucune entreprise, ce qui garantit son indépendance technologique. Les contributions se font via un processus ouvert, transparent, fondé sur des revues de code, des tests collaboratifs et des décisions collégiales.
Depuis le début des années 2000, PostgreSQL bénéficie d’une adoption croissante dans les milieux universitaires, gouvernementaux et industriels. Sa fiabilité en fait un choix naturel pour des projets critiques : bases de données scientifiques, systèmes d’information d’État, applications financières, et plus récemment, solutions cloud natives. Des sociétés comme Red Hat, Fujitsu ou EnterpriseDB participent activement au développement de PostgreSQL, tout en proposant des services professionnels autour de cette technologie. Chaque version majeure publiée annuellement apporte son lot d’améliorations : Performances accrues, meilleure parallélisation, compression, nouvelles syntaxes SQL, ou encore intégration plus fluide avec des langages comme Python, Java ou Rust. En 2010, l’arrivée de l’extension PostGIS ouvre PostgreSQL aux systèmes d’information géographique, lui permettant de concurrencer des outils spécialisés comme Oracle Spatial ou ESRI.
En parallèle, le monde du cloud change la donne. Des géants comme Amazon (via Amazon Aurora et RDS), Microsoft (Azure Database for PostgreSQL) ou Google (Cloud SQL) proposent désormais des versions managées de PostgreSQL, rendant sa mise en œuvre accessible à tous, sans compétence système poussée. Cette ubiquité renforce encore sa position dans les infrastructures modernes.
Aujourd’hui, PostgreSQL est plus qu’un simple SGBDR : C’est une plateforme de données complète, capable de répondre à des cas d’usage variés allant du traitement transactionnel (OLTP) à l’analyse décisionnelle (OLAP), en passant par le temps réel, le JSON, la géolocalisation ou encore l’intégration avec des IA.
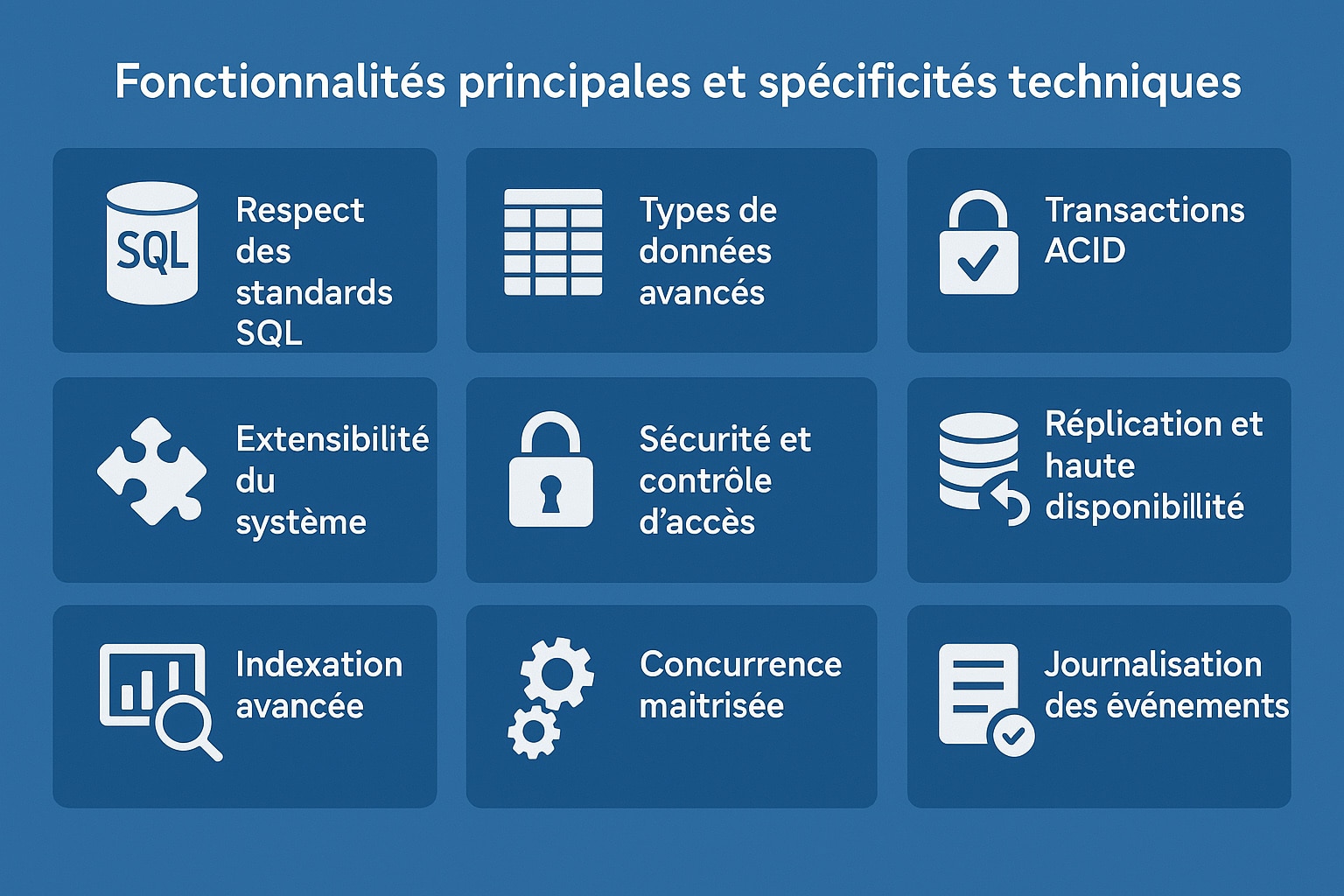
Les fonctionnalités principales et spécificités techniques de postgresql
PostgreSQL est reconnu pour la richesse de ses fonctionnalités, son respect des standards industriels et sa grande capacité d’adaptation. Sa conception modulaire et son architecture ouverte en font un outil particulièrement adapté aux projets ambitieux, qu’ils soient scientifiques, commerciaux, ou liés à la donnée publique. Voici en détail les principales fonctionnalités techniques qui expliquent son succès grandissant dans les environnements professionnels comme open source :
| Fonctionnalité | Description |
|---|---|
| Respect des standards SQL | PostgreSQL est l’un des SGBD les plus conformes aux normes SQL (ANSI SQL et SQL:2008). Il permet d’écrire des requêtes robustes et portables, tout en offrant des fonctionnalités avancées comme les expressions régulières, les requêtes récursives ou les vues matérialisées. |
| Types de données avancés | Outre les types classiques (integer, text, date, boolean), PostgreSQL prend en charge les JSON/JSONB, tableaux, hstore (clé/valeur), UUID, XML, types géographiques (PostGIS), réseaux (CIDR, inet), et autorise la création de types personnalisés. |
| Transactions ACID | Le moteur PostgreSQL repose sur le respect des principes ACID (Atomicité, Cohérence, Isolation, Durabilité), garantissant l’intégrité des données même en cas de coupure ou d’échec d’opération. Il permet aussi les transactions imbriquées via les points de sauvegarde (SAVEPOINT). |
| Extensibilité du système | PostgreSQL peut être enrichi par des extensions (PostGIS, pg_trgm, citext, etc.), des langages de procédures (PL/pgSQL, PL/Python, PL/Perl, etc.) et la création de fonctions, d’opérateurs, de types ou d’agrégats sur mesure. C’est l’un des SGBD les plus personnalisables. |
| Sécurité et contrôle d’accès | Le système d’authentification de PostgreSQL inclut le support LDAP, Kerberos, certificats SSL, ou encore l’authentification GSSAPI. Il offre une gestion fine des rôles, des permissions, des schémas, et des politiques de sécurité par ligne (Row-Level Security). |
| Réplication et haute disponibilité | PostgreSQL intègre nativement la réplication en streaming, la réplication logique (par table ou publication), la restauration PITR (Point-in-Time Recovery) et la gestion de clusters haute disponibilité avec outils tiers comme Patroni ou repmgr. |
| Indexation avancée | Il prend en charge plusieurs types d’index (B-tree, Hash, GIN, GiST, BRIN), permettant d’optimiser les requêtes sur des colonnes textuelles, géographiques ou volumineuses. Il autorise aussi les index partiels et multicolonne. |
| Concurrence maîtrisée | Grâce à son implémentation du MVCC (Multiversion Concurrency Control), PostgreSQL permet l’exécution simultanée de nombreuses requêtes sans verrouillage lourd, tout en conservant la cohérence des données. |
| Journalisation des événements | Chaque modification de données est enregistrée dans un journal (Write-Ahead Log), garantissant la récupération complète après crash. Ce mécanisme est également utilisé pour les sauvegardes incrémentales et la réplication. |
| Support des opérations analytiques | PostgreSQL dispose de fonctions analytiques (window functions), de tableaux croisés (crosstab), d’agrégats personnalisés et peut gérer des charges de type OLAP grâce à ses optimisations internes. |
| Interopérabilité avec d’autres systèmes | Grâce aux Foreign Data Wrappers (FDW), PostgreSQL peut interroger d’autres bases de données (MySQL, Oracle, MongoDB, CSV, etc.) comme s’il s’agissait de tables locales. Il permet aussi des connexions externes via REST, GraphQL, ODBC ou JDBC. |
| Planification des tâches | Avec l’extension pg_cron, PostgreSQL peut planifier des tâches internes (requêtes, maintenance, rapports), évitant le recours à des outils externes comme cron ou Airflow pour les besoins simples. |
Au-delà de ces fonctionnalités techniques, PostgreSQL s’intègre naturellement aux environnements cloud modernes. Il est nativement supporté par les grands fournisseurs (Amazon Web Services, Microsoft Azure, Google Cloud Platform) à travers des services managés comme :
- Amazon RDS for PostgreSQL et Amazon Aurora PostgreSQL pour une configuration automatisée et haute disponibilité sur AWS ;
- Azure Database for PostgreSQL, avec un support natif des outils Microsoft et une intégration à Active Directory ;
- Google Cloud SQL for PostgreSQL, permettant une mise en place rapide avec gestion automatique des sauvegardes et des montées en charge.
Cette compatibilité cloud permet aux entreprises de profiter de la puissance de PostgreSQL sans en gérer l’infrastructure, et de l’intégrer facilement dans des architectures modernes orientées microservices, serverless, ou big data. Elle participe à sa montée en puissance dans les projets innovants à l’échelle mondiale.
Les cas d’usage et d’adoption dans le monde réel de postgresql
PostgreSQL s’est imposé au fil des années comme une solution de référence dans le domaine des bases de données relationnelles. Sa souplesse d’utilisation, sa robustesse, ses fonctionnalités avancées et sa licence open source ont séduit aussi bien les développeurs indépendants que les grandes entreprises et les administrations publiques. Des sites web aux systèmes critiques, de l’analyse de données à la cartographie, les cas d’usage de PostgreSQL sont multiples et en constante évolution. Voici un panorama de son adoption dans différents secteurs d’activité :
- Applications web et mobiles : Grâce à sa compatibilité avec de nombreux frameworks backend (Django, Rails, Laravel, Express, etc.) et sa simplicité de déploiement, PostgreSQL est souvent le choix par défaut pour les applications web modernes. Des startups technologiques à forte croissance comme Instacart ou Deliveroo utilisent PostgreSQL pour stocker les données utilisateurs, gérer les transactions, et faire évoluer leur infrastructure rapidement ;
- Analyse de données et business intelligence : PostgreSQL offre des capacités analytiques puissantes avec ses fonctions de fenêtrage, de regroupement avancé et ses extensions spécialisées comme cstore_fdw (format colonne) ou pg_partman (partitionnement). Il est souvent utilisé comme moteur de back-end pour des outils de BI comme Metabase, Superset ou Redash. Certaines entreprises l’utilisent aussi en complément de data lakes pour des analyses opérationnelles en temps quasi réel ;
- Traitement de données géospatiales : Grâce à l’extension PostGIS, PostgreSQL devient un véritable système d’information géographique (SIG). Il est utilisé par des agences gouvernementales, des villes intelligentes, des services de livraison ou des plateformes d’itinéraires. Par exemple, l’IGN (Institut Géographique National en France) et OpenStreetMap exploitent PostgreSQL/PostGIS pour stocker, interroger et servir des cartes en ligne avec précision ;
- ERP, CRM et outils métiers : Des applications open source majeures telles qu’Odoo (ERP) ou Dolibarr utilisent PostgreSQL comme moteur de base de données. Sa fiabilité et sa capacité à gérer des volumes croissants d’écritures en font une base idéale pour les systèmes de gestion intégrés. Les entreprises peuvent ainsi adapter facilement leurs outils métiers sans coûts de licences prohibitifs ;
- Plateformes SaaS (Software as a Service) : De nombreuses solutions SaaS modernes sont construites sur PostgreSQL. Cela inclut des outils de gestion de projet (comme Asana ou Notion dans leurs premières versions), de marketing automation, ou encore de gestion de contenu. PostgreSQL permet de mutualiser plusieurs comptes clients tout en conservant une gestion fine de la sécurité et de la séparation des données ;
- Secteur bancaire et assurances : La conformité ACID, le chiffrement SSL natif et les fonctionnalités de sécurité avancées (comme le row-level security) permettent à PostgreSQL d’être utilisé dans des environnements réglementés. Certaines banques européennes et néobanques ont fait le choix de PostgreSQL pour gérer les comptes clients et les transactions. C’est le cas de certaines composantes d’architectures internes chez Revolut ou N26 ;
- Sciences, recherche et spatial : Des institutions scientifiques comme la NASA, le CERN ou des universités de renom (MIT, Oxford, Sorbonne Université) utilisent PostgreSQL pour le stockage de grandes quantités de données expérimentales, la gestion d’observations spatiales ou l’analyse de corpus scientifiques. La combinaison de sa fiabilité et de sa capacité à gérer de gros volumes en fait un outil privilégié dans l’enseignement supérieur et la recherche ;
- Administrations et gouvernements : Dans un contexte de souveraineté numérique, de plus en plus d’administrations choisissent PostgreSQL comme alternative aux solutions propriétaires. En France, le projet Base Adresse Nationale, ou encore les bases utilisées par l’<strong’Insee et l’OpenData.gouv.fr, reposent sur PostgreSQL. L’Union européenne finance également des initiatives pour promouvoir son adoption dans les infrastructures critiques ;
- Plateformes de streaming et réseaux sociaux : Des géants du web comme Instagram ou Reddit ont utilisé PostgreSQL pour des services à très fort trafic. La scalabilité horizontale (via la réplication ou des outils comme Citus) et la robustesse des transactions ont permis à ces entreprises de maintenir une haute disponibilité, même avec des millions d’utilisateurs actifs simultanés.
Au-delà des cas spécifiques, PostgreSQL séduit par sa capacité à évoluer en fonction des besoins techniques. Il est aussi capable de s’insérer dans des architectures complexes :
- en tant que backend relationnel d’un site web,
- comme référentiel central dans un data warehouse hybride,
- ou encore comme stockage transactionnel dans des systèmes de microservices conteneurisés (via Kubernetes, Docker, etc.).
Cette polyvalence repose sur une communauté dynamique et mondiale, qui assure le développement, la documentation et le support autour du projet. À chaque nouvelle version, des améliorations substantielles sont proposées : meilleure gestion des index, requêtes parallèles plus rapides, compression avancée, sécurité accrue… Le tout sans verrou propriétaire ni dépendance à un fournisseur unique.
Par rapport à des solutions commerciales comme Oracle ou Microsoft SQL Server, PostgreSQL offre une autonomie technologique précieuse, une transparence totale sur le fonctionnement du moteur, et un coût d’exploitation maîtrisé. Cela permet aux entreprises de toutes tailles de construire des solutions performantes, évolutives, et éthiques du point de vue de la gestion des données.

0 commentaires