Au cœur des infrastructures informatiques modernes, là où les serveurs traitent en continu des milliers de requêtes, un paramètre discret influence directement les performances : La latence mémoire. Invisible à l’œil nu, elle se manifeste pourtant dans chaque temps de réponse, chaque transaction exécutée et chaque calcul réalisé. Derrière les indicateurs de supervision et les tableaux de bord techniques se cache une réalité matérielle et architecturale qui conditionne la rapidité d’accès aux données. Qu’il s’agisse d’hébergement web, de virtualisation, de bases de données volumineuses ou d’environnements de calcul intensif, la mémoire vive joue un rôle central dans l’efficacité d’un serveur. Toutefois, la quantité de RAM installée ne suffit pas à garantir de hautes performances. La vitesse à laquelle le processeur peut accéder aux informations stockées, autrement dit la latence mémoire, influence directement la fluidité et la stabilité des systèmes. Dans cet article, essayons ensemble de clarifier la définition de la latence mémoire, détailler son fonctionnement technique et examiner ses implications concrètes sur les performances des serveurs professionnels.
Ce que sont les mécanismes de la latence mémoire
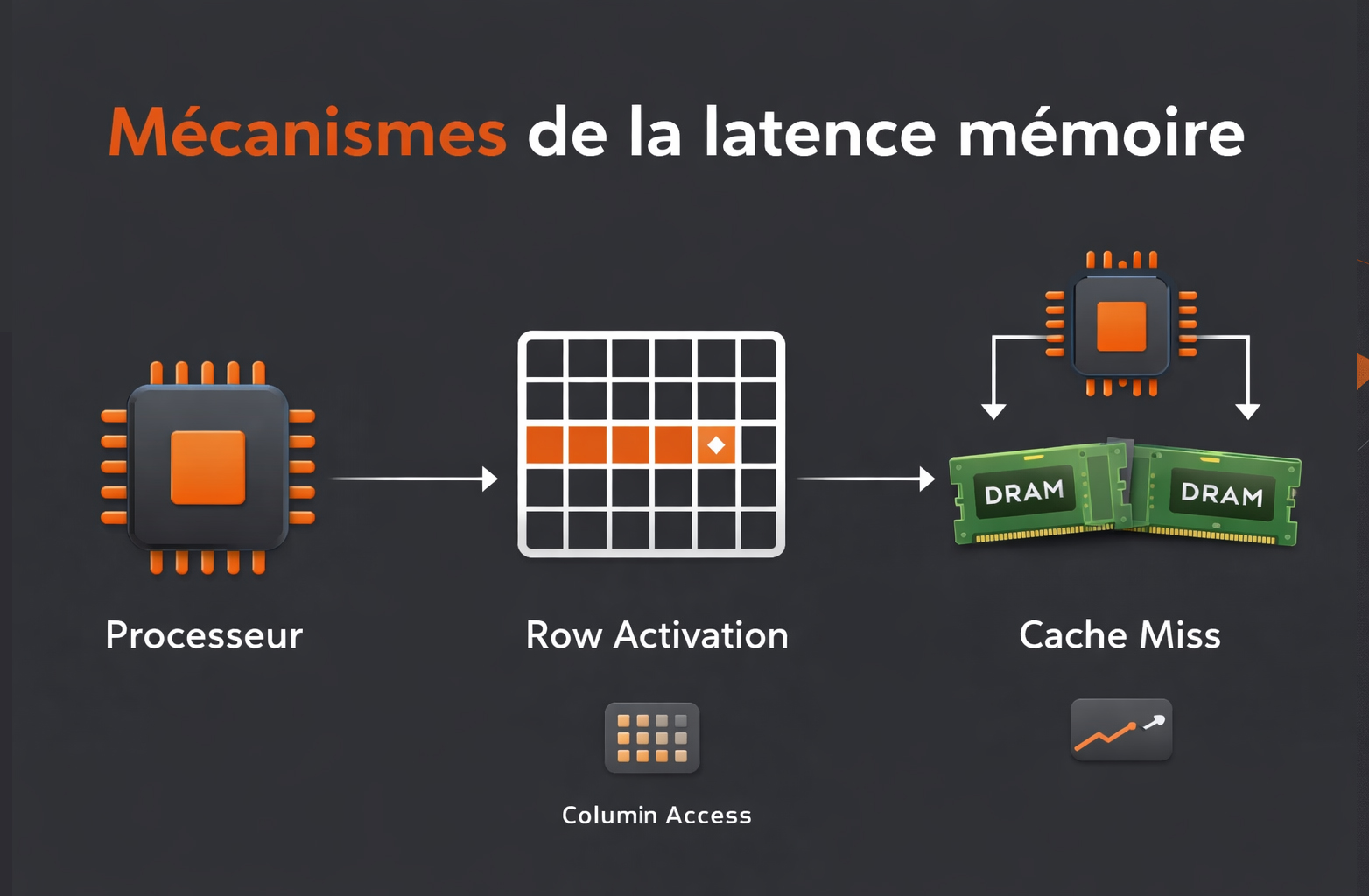
La latence mémoire correspond au délai qui s’écoule entre le moment où le processeur émet une requête d’accès à une donnée en mémoire vive (RAM) et le moment où cette donnée devient effectivement exploitable. Elle s’exprime en nanosecondes (ns) ou en cycles d’horloge. Plus ce délai est court, plus le processeur peut enchaîner rapidement les instructions dépendantes de la mémoire. D’un point de vue architectural, le processeur ne s’adresse pas directement à la RAM à chaque opération. Il exploite d’abord une hiérarchie de caches (L1, L2, L3) conçus pour réduire drastiquement les temps d’accès. Lorsque la donnée recherchée n’est pas présente dans ces caches (on parle alors de cache miss) la requête est transmise au contrôleur mémoire intégré au processeur, qui orchestre l’accès aux modules DRAM. C’est précisément dans cette séquence que la latence mémoire intervient. Le fonctionnement interne de la DRAM repose sur une organisation matricielle en lignes (rows) et colonnes (columns), regroupées en banques (banks). Pour lire une donnée, le contrôleur doit :
- Activer la ligne contenant la donnée (Row Activation) ;
- Sélectionner la colonne correspondante (Column Access) ;
- Précharger la ligne suivante si nécessaire (Precharge).
Chacune de ces étapes est associée à des délais spécifiques, exprimés sous forme de timings mémoire.
Les principaux paramètres influençant la latence
- La fréquence de la mémoire (MHz ou MT/s) ;
- Les timings mémoire (CAS latency, tRCD, tRP, tRAS) ;
- Le nombre de canaux mémoire exploités ;
- L’architecture du contrôleur mémoire intégré (IMC) ;
- La topologie du système (NUMA, multi-socket).
La CAS latency (CL) est le timing le plus connu. Elle représente le nombre de cycles nécessaires entre l’envoi d’une commande de lecture (READ) et la disponibilité des premières données sur le bus mémoire. Toutefois, ce chiffre doit être interprété en tenant compte de la fréquence réelle.
La latence effective en nanosecondes peut être estimée grâce à la formule suivante :
Latence (ns) = (CAS latency / fréquence effective) × 2000
Par exemple, une mémoire DDR4-3200 avec une CAS latency de 16 cycles n’aura pas nécessairement une latence supérieure à une DDR4-2400 CL14, car l’augmentation de fréquence peut compenser l’élévation du nombre de cycles.
La lecture détaillée des timings mémoire
| Paramètre | Rôle dans la latence mémoire |
|---|---|
| CAS latency (CL) | Délai entre la commande de lecture et la sortie des données sur le bus mémoire. |
| tRCD (Row to Column Delay) | Temps nécessaire entre l’activation d’une ligne et l’accès à une colonne spécifique. |
| tRP (Row Precharge) | Délai requis pour fermer une ligne active avant d’en ouvrir une nouvelle. |
| tRAS (Row Active Time) | Durée minimale pendant laquelle une ligne doit rester active pour garantir l’intégrité des données. |
| Command Rate (CR) | Nombre de cycles entre l’activation de la puce mémoire et l’exécution de la commande suivante. |
Ces paramètres fonctionnent conjointement. Une simple lecture aléatoire peut mobiliser plusieurs de ces délais successivement, ce qui explique pourquoi la latence perçue dépend d’un ensemble de facteurs et non d’un seul indicateur.
Le rôle du contrôleur mémoire et de la topologie serveur
Dans les serveurs modernes (DDR4 et DDR5), le contrôleur mémoire est intégré directement au processeur. Il gère :
- La distribution des accès entre les canaux mémoire ;
- La gestion des files d’attente de requêtes ;
- L’optimisation de l’ordre des accès pour limiter les changements de lignes.
Dans les architectures multi-socket, la notion de NUMA (Non-Uniform Memory Access) introduit une latence variable selon la localisation physique de la mémoire. Chaque processeur possède sa mémoire locale, accessible plus rapidement que la mémoire attachée à un autre processeur. Lorsqu’un thread accède à une mémoire distante, la requête transite par l’interconnexion inter-socket (par exemple Intel UPI ou AMD Infinity Fabric), ce qui augmente mécaniquement le temps d’accès. Cette différence peut atteindre plusieurs dizaines de nanosecondes supplémentaires, ce qui devient significatif pour les charges fortement dépendantes de la mémoire, telles que les bases de données en mémoire ou les environnements de calcul intensif.
Ainsi, la latence mémoire ne dépend pas uniquement des caractéristiques des barrettes installées. Elle résulte d’une interaction complexe entre la DRAM, le contrôleur mémoire, l’architecture processeur, la topologie NUMA et la nature des charges applicatives exécutées sur le serveur.
L’impact de la latence mémoire sur les performances des serveurs
Sur un poste de travail bureautique ou un environnement domestique, une variation de quelques nanosecondes de latence mémoire reste généralement imperceptible. Les charges sont intermittentes, les pics d’utilisation courts et les applications rarement optimisées pour exploiter pleinement les ressources matérielles. En revanche, dans un serveur fonctionnant 24h/24 sous forte contrainte transactionnelle comme un serveur dédié, la latence mémoire devient un paramètre structurant de la performance globale. Un serveur traite simultanément des milliers, voire des millions d’opérations par seconde. Chaque requête applicative déclenche une succession d’instructions CPU, dont une part importante dépend d’accès mémoire. Lorsque la latence augmente, le processeur passe davantage de temps en attente de données, ce qui se traduit par une hausse des cycles d’inactivité (CPU stalls). Même avec un processeur performant et un nombre élevé de cœurs, le sous-système mémoire peut ainsi devenir un facteur limitant.
Les types d’applications particulièrement sensibles
Certaines charges de travail sont plus exposées que d’autres à l’impact de la latence mémoire :
- Les bases de données transactionnelles (OLTP)
- Les systèmes de virtualisation et d’hyperconvergence
- Les applications analytiques en temps réel (in-memory, BI, streaming)
- Les environnements de calcul haute performance (HPC)
Dans une base de données relationnelle, par exemple, chaque requête SQL peut impliquer :
- La consultation d’index en mémoire
- L’accès aux buffers de pages
- La vérification des verrous et structures internes
- La mise à jour de journaux transactionnels
Ces opérations génèrent de nombreux accès aléatoires à la mémoire. Une latence plus élevée augmente le temps de parcours des structures de données (B-Tree, tables de hachage, caches internes), ce qui rallonge le temps de réponse des requêtes. À grande échelle, cela peut dégrader le débit transactionnel (TPS) et augmenter la latence applicative perçue par les utilisateurs. Dans les environnements virtualisés, l’impact est également significatif. L’hyperviseur répartit les ressources physiques entre plusieurs machines virtuelles. Lorsque ces VM exécutent des charges intensives (bases de données, serveurs applicatifs, services web), elles sollicitent simultanément la mémoire. Une latence élevée peut provoquer :
- Une augmentation du temps d’attente CPU au sein des VM ;
- Une baisse de la consolidation possible par hôte ;
- Une dégradation des performances lors des pics de charge.
Dans les architectures NUMA, un mauvais placement des VM peut accentuer le phénomène si une machine virtuelle accède majoritairement à de la mémoire distante.
L’analyse comparative selon les scénarios d’usage du serveur
| Scénario | Sensibilité à la latence mémoire | Impact potentiel |
|---|---|---|
| Serveur web statique | Faible à modérée | Léger impact sur le temps de réponse, généralement masqué par le cache applicatif |
| Serveur applicatif dynamique | Modérée à élevée | Augmentation du temps de traitement des requêtes complexes |
| Base de données relationnelle | Élevée | Baisse du débit transactionnel et hausse de la latence des requêtes |
| Virtualisation dense | Élevée | Réduction de la densité de VM et performances variables en charge |
| Calcul scientifique / HPC | Très élevée | Allongement significatif des temps de calcul et perte d’efficacité parallèle |
Un point souvent sous-estimé est l’effet cumulatif. Une augmentation de 10 ou 15 nanosecondes peut sembler marginale sur un accès isolé. Cependant, multipliée par plusieurs millions d’accès mémoire par seconde et par des dizaines de cœurs actifs, elle représente un volume considérable de cycles processeur perdus en attente. Dans les environnements analytiques ou HPC, où les algorithmes manipulent de grands ensembles de données en mémoire, cette accumulation peut réduire l’efficacité du parallélisme. Les threads passent davantage de temps à attendre les données qu’à exécuter des calculs, ce qui diminue le rendement global du système.
Les mécanismes de compensation et les limites
Les architectures modernes intègrent plusieurs mécanismes pour atténuer l’impact de la latence mémoire :
- Des caches processeur de grande capacité (L3 partagé, parfois L4)
- Des algorithmes avancés de prélecture (hardware prefetching)
- Une meilleure gestion des files d’attente mémoire
- Des optimisations logicielles adaptées à la topologie NUMA
Les compilateurs et les applications peuvent également être optimisés pour améliorer la localité des données, réduire les accès aléatoires et favoriser des structures plus adaptées au cache (cache-friendly data structures). Néanmoins, ces mécanismes ne suppriment pas l’impact d’une latence élevée. Ils en limitent les effets dans certains cas, mais lorsque la charge est fortement dépendante de la mémoire, la qualité du sous-système mémoire reste déterminante. Une conception cohérente de l’infrastructure (choix du processeur, nombre de canaux mémoire, fréquence adaptée, respect de la topologie NUMA) demeure essentielle pour garantir des performances stables et prévisibles.
Optimiser et maîtriser la latence mémoire dans un environnement serveur
Réduire la latence mémoire dans un serveur ne repose pas sur un simple ajustement de paramètre BIOS ou sur le choix d’une fréquence plus élevée. Il s’agit d’une démarche globale qui combine sélection matérielle rigoureuse, compréhension fine de l’architecture processeur, configuration adaptée du système d’exploitation et optimisation des applications. La performance mémoire est le résultat d’un équilibre entre capacité, bande passante, latence et cohérence architecturale.
L’optimisation matérielle : Poser des bases solides
Le premier levier d’optimisation concerne le matériel. Les serveurs professionnels sont conçus pour fonctionner avec des combinaisons précises de processeurs et de modules mémoire. Respecter les recommandations du constructeur permet d’éviter des baisses de fréquence automatiques ou des comportements non optimaux du contrôleur mémoire. Sur le plan matériel, il est recommandé de :
- Choisir des modules mémoire certifiés par le constructeur du serveur (RDIMM, LRDIMM, ECC selon les besoins) ;
- Maintenir une configuration homogène (même capacité, même fréquence, mêmes timings) ;
- Exploiter pleinement les canaux mémoire disponibles par processeur ;
- Éviter les mélanges de densités ou de générations différentes.
Les processeurs modernes disposent de plusieurs canaux mémoire (6, 8 voire plus selon les gammes). Pour atteindre une latence et une bande passante optimales, chaque canal doit être peuplé de manière équilibrée. Une configuration déséquilibrée (par exemple un nombre impair de barrettes ou une distribution asymétrique entre sockets) peut entraîner :
- Une baisse de la fréquence effective de la mémoire ;
- Une augmentation de la latence moyenne ;
- Une réduction de la bande passante agrégée.
Il est également important de considérer le rang (single rank, dual rank) et l’impact potentiel sur le comportement du contrôleur mémoire. Dans certains cas, une configuration dual rank bien répartie peut améliorer les performances grâce à une meilleure interleaving.
Maîtriser la topologie NUMA dans les architectures multi-socket
Dans les environnements multi-processeurs, la compréhension de la topologie NUMA (Non-Uniform Memory Access) est indispensable. Chaque processeur dispose de sa mémoire locale, accessible plus rapidement que la mémoire distante reliée via une interconnexion inter-socket. L’objectif est de favoriser la localité mémoire, c’est-à-dire s’assurer que les threads s’exécutent préférentiellement sur le processeur qui détient les données qu’ils manipulent. L’affinité processeur-mémoire peut être optimisée via :
- Le paramétrage du système d’exploitation (numactl, politiques d’allocation mémoire) ;
- La configuration des hyperviseurs (affinité vCPU, réservation mémoire par nœud NUMA) ;
- L’adaptation des applications pour respecter la localité mémoire.
Dans un cluster de virtualisation, par exemple, une machine virtuelle configurée avec plus de vCPU qu’un seul nœud NUMA peut entraîner des accès fréquents à de la mémoire distante. Une conception adaptée à la taille réelle des nœuds NUMA physiques permet de limiter ces surcoûts de latence.
L’optimisation logicielle et le tuning applicatif
Le logiciel joue également un rôle central. Certaines bases de données et plateformes de virtualisation intègrent des mécanismes avancés pour améliorer la gestion mémoire :
- Allocation mémoire locale prioritaire ;
- Réduction des accès aléatoires grâce à des structures de données optimisées ;
- Gestion fine des buffers et caches internes.
Les développeurs peuvent contribuer à réduire l’impact de la latence en :
- Optimisant la localité spatiale et temporelle des données ;
- Limitant les accès mémoire non séquentiels ;
- Évitant les structures de données fragmentées.
Dans les environnements analytiques ou HPC, l’optimisation des algorithmes pour améliorer l’utilisation du cache peut réduire significativement le nombre d’accès à la mémoire principale, et donc l’exposition à la latence.
La supervision et les indicateurs de performance mémoire
Une optimisation efficace repose sur la mesure. Il est essentiel de surveiller régulièrement les métriques liées à la mémoire afin d’identifier d’éventuels goulots d’étranglement :
- Taux de défauts de cache (cache miss ratio) ;
- Temps d’attente CPU liés à la mémoire (memory stalls) ;
- Répartition de l’utilisation entre les nœuds NUMA ;
- Bande passante mémoire consommée.
Des outils comme les compteurs matériels (PMU), les utilitaires d’analyse système ou les tableaux de bord des hyperviseurs permettent d’obtenir une vision précise du comportement mémoire. L’analyse croisée entre charge CPU et latence mémoire aide à déterminer si la performance est limitée par le calcul ou par l’accès aux données.
Trouver le bon équilibre entre capacité, bande passante et latence
Dans certains contextes très exigeants (trading haute fréquence, bases de données en mémoire, calcul scientifique intensif) l’adoption de modules mémoire optimisés pour une latence plus faible ou de plateformes orientées performance peut produire un gain mesurable. Toutefois, l’optimisation ne consiste pas uniquement à rechercher la fréquence la plus élevée ou les timings les plus agressifs. Une fréquence accrue peut augmenter la bande passante tout en modifiant les timings effectifs. À l’inverse, une capacité insuffisante peut provoquer du swapping ou une pression excessive sur les caches, annulant tout bénéfice lié à une faible latence.
L’objectif est donc d’aligner la configuration mémoire avec la nature réelle des charges de travail. Une base de données transactionnelle privilégiera une latence réduite et une bonne localité NUMA, tandis qu’un workload analytique massif pourra nécessiter davantage de bande passante et de capacité.

0 commentaires