Longtemps réservés aux récits de science-fiction, les agents intelligents sont aujourd’hui une réalité technique intégrée dans de nombreuses applications numériques. Ces entités logicielles capables d’agir de façon autonome dans un environnement sont au cœur de l’intelligence artificielle moderne. Mais comment sont-ils réellement conçus ? Quels langages, architectures et outils permettent de les faire fonctionner ? Cet article propose ainsi une plongée technique dans la création d’un agent IA, depuis les bases logicielles jusqu’aux exemples concrets de mise en œuvre.
Les fondations techniques d’un agent IA : Architecture et principes
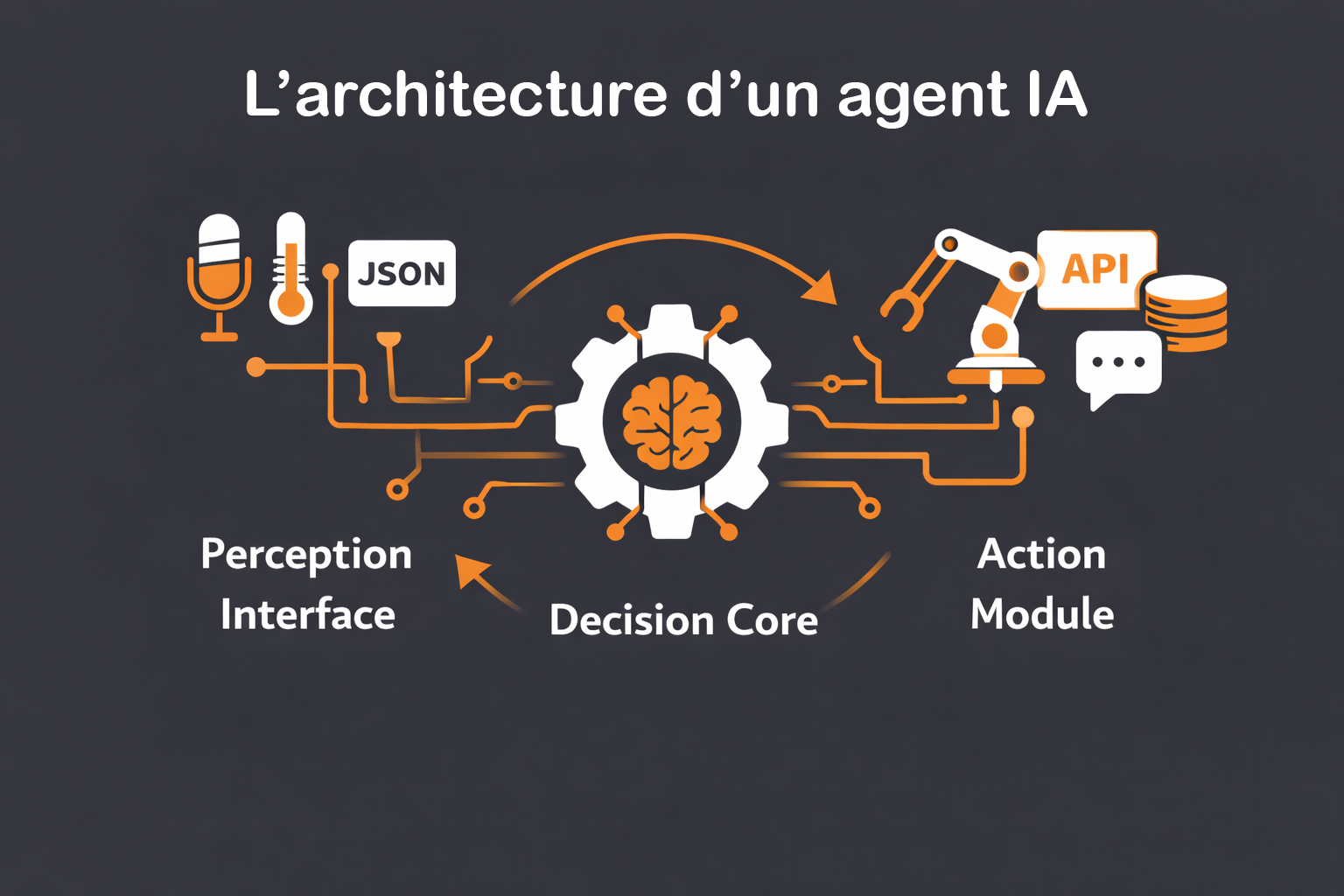
Concevoir un agent intelligent ne peut se résumer seulement à brancher un modèle d’intelligence artificielle à un logiciel ou à injecter quelques lignes de code dans une application. Il s’agit d’un processus méthodique qui mobilise plusieurs disciplines de l’informatique : architecture logicielle, algorithmique, intelligence artificielle, traitement des données, et parfois robotique embarquée. L’agent IA est une entité logicielle autonome qui perçoit son environnement, raisonne sur les données reçues, puis agit de manière contextualisée pour atteindre un objectif. Pour concevoir un tel système, il est indispensable de modéliser avec précision les interactions entre ses différents modules fonctionnels et techniques. La structure canonique d’un agent intelligent repose sur un cycle à trois temps : percevoir → décider → agir. Ce triptyque se retrouve aussi bien dans un assistant vocal que dans un robot de logistique, ou un agent conversationnel en ligne. Il fournit un cadre de conception universel permettant de décliner ensuite l’implémentation selon le domaine applicatif. Voici les trois piliers principaux :
- Interface de perception : L’agent collecte des données de son environnement, qui peuvent être physiques (température, mouvement, audio) ou numériques (requêtes utilisateur, événements système, données API). La perception peut s’appuyer sur des capteurs physiques dans le cas d’un robot, ou sur des flux JSON en provenance de services web dans le cas d’un agent logiciel. Cette couche est souvent enrichie par une étape de prétraitement pour filtrer, normaliser ou enrichir les données en entrée ;
- Cœur décisionnel : C’est le noyau d’intelligence de l’agent. Il peut reposer sur une logique simple à base de règles (système expert), sur des modèles d’apprentissage automatique (machine learning), ou sur des combinaisons hybrides intégrant raisonnement symbolique et apprentissage statistique. Dans un scénario d’assistance en ligne, il peut s’agir d’un modèle NLP qui détecte les intentions de l’utilisateur et sélectionne la réponse la plus pertinente. Dans le cas d’un agent autonome mobile, il pourra s’agir d’un algorithme de planification de trajectoire, d’évitement d’obstacle ou de stratégie multi-agent ;
- Module d’action : Cette couche exécute les décisions prises. Elle peut piloter un moteur physique (actionneur, robot), déclencher une requête API, modifier une base de données ou afficher une réponse utilisateur. Selon le contexte, l’action peut être immédiate ou planifiée, simple ou composite, locale ou distribuée. Certains agents peuvent même ajuster leurs actions en fonction d’un retour en temps réel (feedback loop), notamment dans les environnements complexes ou incertains.
Ce modèle, aussi appelé agent-environnement, peut être mis en œuvre selon plusieurs paradigmes : orienté objet, réactif, BDI (Belief-Desire-Intention), ou encore via des architectures orientées services. Dans tous les cas, la cohérence entre les trois couches (perception, décision, action) est primordiale pour garantir le comportement autonome, pertinent et stable de l’agent. Du point de vue de la réalisation technique, plusieurs composants logiciels s’avèrent essentiels. Le choix des outils et langages dépend de la nature de l’agent (logiciel, physique, hybride), de son domaine d’application (conversationnel, industriel, décisionnel), et des performances attendues (latence, scalabilité, portabilité).
| Composant | Rôle | Technologies courantes |
|---|---|---|
| Système d’entrée | Collecte des données de l’environnement | Python + API REST, capteurs IoT (MQTT), sockets, Webhooks, Kafka |
| Moteur décisionnel | Analyse, inférence, prédiction, planification | Python, TensorFlow, PyTorch, scikit-learn, Prolog, Rasa |
| Gestion de l’état | Suivi du contexte, de la mémoire de session ou des variables internes | Redis, MongoDB, PostgreSQL, SQLite, files JSON, graphes RDF |
| Moteur d’action | Déclenchement d’événements, communication, exécution | API REST, CLI, bots Slack/Discord, HTTP clients, UI web ou mobile |
À cela peuvent s’ajouter des composants transversaux comme :
- Un système de logs et de monitoring (ElasticSearch, Prometheus, Grafana) pour suivre les décisions prises par l’agent, identifier les comportements inattendus, ou analyser les performances ;
- Un module de feedback pour apprendre en continu à partir des résultats (ex. : retour utilisateur, évaluation de performance, métriques métier) ;
- Des interfaces d’administration pour superviser, ajuster ou reprogrammer les comportements de l’agent en fonction des évolutions du système cible.
Le défi principal réside souvent dans l’intégration fluide de ces briques au sein d’une architecture cohérente et maintenable. Cela suppose une bonne séparation des responsabilités, l’utilisation de design patterns (comme le pattern observer, event-driven, ou pub/sub), et une stratégie claire de gestion des erreurs, du temps réel et des dépendances entre modules.
Une fois ce squelette en place, la création d’un agent IA passe à une phase plus concrète : l’implémentation logicielle. Celle-ci dépendra des objectifs opérationnels (réactivité, personnalisation, autonomie, collaboration multi-agent), mais aussi des langages, frameworks et bibliothèques choisis. C’est ce que nous allons explorer dans la section suivante.
Les langages de programmation utilisés pour créer un agent IA
Le développement d’un agent IA repose sur une combinaison de briques logicielles, allant de la collecte de données à la prise de décision autonome. Le choix du langage de programmation joue donc un rôle central dans la flexibilité, la maintenabilité, la performance et l’intégrabilité de l’agent dans son environnement cible. Ce choix dépend de plusieurs facteurs techniques :
- Le type d’agent (conversationnel, robotique, décisionnel, distribué, etc.) ;
- Le niveau d’intelligence attendu (règles simples, machine learning, apprentissage en ligne) ;
- Les contraintes techniques (latence, embarqué, accès aux capteurs, intégration SI) ;
- Le contexte d’exécution (cloud, edge, navigateur, microservices, terminal).
Certains langages favorisent la rapidité de prototypage et l’intégration de bibliothèques IA existantes, d’autres offrent un contrôle plus fin sur les ressources système, ce qui les rend idéaux pour les agents critiques ou embarqués. Voici une présentation des langages les plus pertinents dans ce domaine, chacun ayant ses forces spécifiques selon l’architecture de l’agent à concevoir.
Python : Le langage roi de l’intelligence artificielle
Python est de loin le langage le plus utilisé dans le domaine de l’intelligence artificielle et du développement d’agents IA. Sa popularité s’explique par :
- Une syntaxe intuitive et concise, idéale pour le prototypage rapide
- Un écosystème extrêmement riche en bibliothèques de data science et de machine learning
- Une large communauté et de nombreuses ressources open source
Un agent IA développé en Python peut couvrir toutes les étapes du cycle perception → raisonnement → action. Voici quelques tâches typiques :
- Interroger des APIs ou capteurs via
requests,httpxoupaho-mqtt - Maintenir un état de session ou de contexte avec
sqlite3,Redisou des structures JSON sérialisées avecpickle - Utiliser des modèles NLP préentraînés grâce à la librairie
transformersde Hugging Face - Créer des systèmes de décision prédictifs avec
scikit-learn,XGBoost,LightGBM, ou des réseaux de neurones avecTensorFlowouPyTorch
Python s’intègre également facilement à des frameworks de déploiement web comme Flask ou FastAPI, ce qui permet de transformer un agent en microservice déployable sur un cloud public (AWS Lambda, Azure Functions, Google Cloud Run) ou privé (Docker, Kubernetes).
Enfin, Python est idéal pour le développement de prototypes fonctionnels rapidement testables, puis éventuellement portés vers un langage plus performant si nécessaire.
JavaScript (Node.js) : agents pour applications web en temps réel
JavaScript, et plus particulièrement sa version côté serveur via Node.js, est particulièrement adapté au développement d’agents IA qui interagissent directement avec des interfaces web ou des utilisateurs. Il est souvent utilisé pour :
- Construire des chatbots embarqués dans des interfaces web
- Créer des agents conversationnels intégrés aux réseaux sociaux (Messenger, WhatsApp, Discord)
- Développer des assistants vocaux pour applications web ou des extensions de navigateur
Node.js offre de nombreux avantages :
- Un modèle non bloquant orienté événement, parfait pour le temps réel
- Une compatibilité native avec les frameworks frontend modernes (React, Vue.js, Angular)
- La possibilité de manipuler WebSocket, WebRTC, GraphQL pour une communication bidirectionnelle fluide entre client et serveur
En associant Node.js à des services cloud d’intelligence artificielle comme Dialogflow, OpenAI API, ou Microsoft Azure Cognitive Services, on peut créer des agents très réactifs, sans avoir à héberger soi-même des modèles complexes.
Langages spécialisés pour l’IA symbolique et les règles
Pour les agents reposant sur des raisonnements logiques formels ou des systèmes à base de règles, certains langages déclaratifs restent inégalés en expressivité et en lisibilité :
- Prolog : Langage déclaratif fondé sur la logique du premier ordre, utilisé pour exprimer des relations et construire des raisonnements complexes par un mécanisme d’unification et de recherche automatique. Il est particulièrement adapté à la création de moteurs d’inférence, à la résolution de contraintes logiques, et à la modélisation de comportements agents dans les architectures BDI (Belief-Desire-Intention). Grâce à sa capacité à exprimer facilement des faits, règles et requêtes logiques, Prolog est souvent utilisé dans la recherche académique, la robotique cognitive ou encore les systèmes de recommandation transparents ;
- CLIPS : Acronyme de “C Language Integrated Production System”, CLIPS est un environnement de développement de systèmes experts initialement conçu par la NASA. Il permet de créer des systèmes basés sur des règles de production, combinant faits déclaratifs et règles de type condition-action. CLIPS propose une syntaxe proche de Lisp, un moteur d’inférence performant (basé sur l’algorithme Rete) et une gestion efficace des faits dynamiques. Il est particulièrement utilisé dans des secteurs critiques où la logique doit être formalisée, validée et traçable : systèmes d’aide au diagnostic médical, simulation de mission spatiale, analyse financière ou détection d’anomalies industrielles ;
- Drools : Moteur de règles open source développé en Java, Drools est largement intégré dans des systèmes d’information d’entreprise, notamment dans des contextes métiers complexes nécessitant une séparation claire entre la logique de gestion (business rules) et le code applicatif. Il permet de gérer un grand volume de règles, de prioriser leur exécution, de créer des workflows décisionnels, et de les maintenir sans redéploiement du code. Grâce à son moteur basé sur l’algorithme Rete et à son intégration avec les architectures JEE ou Spring Boot, Drools est utilisé dans des systèmes d’automatisation de processus métiers, des moteurs de tarification dynamique, ou des plateformes de conformité réglementaire (finance, assurance, télécoms).
Ces langages permettent de formaliser des comportements complexes de manière déclarative, comme par exemple :
peut_envoyer_facture(X) :- est_client_actif(X), a_contrat_valide(X).Ils sont particulièrement pertinents dans les domaines où l’interprétabilité, la traçabilité des décisions ou la conformité réglementaire sont des exigences fortes (droit, médical, aviation).
L’usage de langages bas niveau : C++, Rust, Go pour la performance
Pour des agents IA embarqués sur des dispositifs physiques, ou déployés dans des contextes nécessitant une maîtrise précise des ressources, les langages compilés à faible empreinte mémoire sont souvent privilégiés. Parmi eux :
- C++ : Langage compilé de bas niveau extrêmement performant, C++ est largement utilisé dans les systèmes critiques où la maîtrise des ressources matérielles est essentielle. En robotique, il est souvent utilisé pour développer des modules temps réel de bas niveau, tels que les contrôleurs de mouvement, les interfaces capteurs ou les algorithmes de navigation embarqués. Dans l’univers des jeux vidéo, il constitue la colonne vertébrale des moteurs graphiques comme Unreal Engine, en raison de ses capacités à manipuler la mémoire, le multithreading et les graphismes 3D avec précision. On le retrouve aussi dans les systèmes embarqués industriels (automates, systèmes de vision, automates programmables) où la latence, la stabilité et le contrôle précis sont primordiaux. C++ est également très utilisé dans le framework ROS (Robot Operating System), notamment pour la création de nœuds robotisés temps réel ;
- Rust : Langage moderne conçu pour concilier performance, sécurité et robustesse, Rust se distingue par son système de gestion de la mémoire sans garbage collector, ce qui le rend particulièrement adapté aux applications embarquées, sécurisées et sensibles aux erreurs de mémoire (overflows, pointeurs sauvages, race conditions). Il est de plus en plus utilisé pour développer des agents IA embarqués dans des systèmes edge (IoT, drones, capteurs intelligents), ainsi que pour construire des composants critiques dans des systèmes multi-agents distribués. Grâce à sa compilation statique, sa vérification stricte à la compilation et ses performances comparables au C++, Rust s’impose dans des domaines comme la cybersécurité, les blockchains, ou les réseaux embarqués nécessitant haute résilience et efficacité énergétique ;
- Go (Golang) : Développé par Google, Go est un langage compilé conçu pour la simplicité, la rapidité d’exécution et l’extrême facilité de développement de systèmes distribués. Son modèle natif de gestion de la concurrence via les goroutines et les canaux (channels) en fait un excellent choix pour la conception d’agents répartis dans des architectures orientées microservices ou fonctionnant sur le cloud. Go est souvent utilisé pour développer des orchestrateurs, des agents supervisés dans des infrastructures DevOps (par exemple avec Kubernetes), ou encore des traitements en flux (streaming de données, agents de collecte d’événements). Son écosystème, sa portabilité et ses temps de compilation très rapides le rendent idéal pour les déploiements massifs d’agents légers, résilients, communicants et facilement maintenables.
Ces langages permettent notamment de :
- Accéder directement au matériel (drivers de capteurs, caméras, moteurs, etc.) ;
- Optimiser la latence dans les systèmes embarqués ou les agents autonomes ;
- Déployer des agents en réseau (multi-agents distribués) avec une consommation minimale de ressources.
Par exemple, un robot autonome utilisant ROS (Robot Operating System) pourra combiner des modules écrits en C++ pour les calculs de trajectoire, et en Python pour la gestion des modèles IA intégrés. Quant à Go, il se prête bien à la création d’agents de traitement de flux en parallèle (ex. : traitement de données temps réel, supervision réseau, IA distribuée dans des conteneurs Docker). Le choix de ces langages est souvent motivé par la recherche d’une exécution déterministe, de performances critiques, ou de robustesse sur des systèmes embarqués à faible consommation énergétique. De fait, il n’existe pas un langage unique pour développer un agent IA, mais des choix complémentaires à faire selon l’usage prévu. Python excelle pour la phase de prototypage et l’intelligence des modèles, Node.js pour l’interaction en ligne, Prolog pour le raisonnement symbolique, et Rust ou C++ pour les agents déployés sur le terrain. Une architecture robuste pourra même combiner plusieurs langages, chacun dédié à un sous-système de l’agent, orchestrés via des APIs, des messages ou des queues (comme RabbitMQ ou MQTT).
Exemple d’architecture modulaire : Création pas à pas d’un agent IA simple
Pour comprendre comment construire concrètement un agent intelligent, rien de tel qu’un exemple de mise en œuvre pas à pas. Imaginons ici un agent IA déployé dans un contexte de support client. Sa mission : répondre automatiquement à des questions fréquentes d’utilisateurs (FAQ), à travers une interface web intuitive. Ce type d’agent peut être intégré à un site e-commerce, une plateforme SaaS, ou un portail institutionnel pour offrir un support 24/7 sans surcharge humaine.
1. Définition du périmètre de l’agent IA
Avant de démarrer le développement, il est essentiel de délimiter clairement les objectifs de l’agent, ses interfaces d’interaction et les ressources sur lesquelles il va s’appuyer pour générer ses réponses.
- Objectif : répondre de manière autonome et contextuelle à des questions fréquemment posées par les utilisateurs (FAQ), en langage naturel. L’agent doit pouvoir comprendre les intentions exprimées, rechercher une réponse appropriée dans une base de connaissances, et fournir un retour synthétique.
- Interface : intégration dans une interface web sous forme de chatbot, affiché en bas de page ou via une boîte de dialogue. Le frontend repose sur
React.jspour une expérience utilisateur fluide, avec une communication en temps réel vers le backend. - Source de vérité : une base de connaissances structurée sous forme textuelle ou semi-structurée (format JSON ou base de données NoSQL), contenant des couples question-réponse, enrichis éventuellement par des métadonnées (catégorie, priorité, tags).
2. Stack technologique
La pile technologique choisie doit permettre un développement rapide, une bonne scalabilité, et une intégration fluide avec les outils de NLP modernes. Voici un exemple de stack minimaliste mais robuste :
| Composant | Technologie |
|---|---|
| Frontend | React.js (interface utilisateur, composants chatbot, gestion des événements) |
| Backend | Flask (micro-framework Python léger pour l’API REST) |
| Modèle NLP | Hugging Face Transformers (modèles comme DistilBERT, GPT-2 pour le question answering) |
| Base de données | MongoDB (stockage des paires Q/R et historique des conversations) |
3. Étapes de développement de l’agent IA
Voici les principales étapes à suivre pour créer et déployer cet agent IA de support client :
- Création d’une API Flask avec endpoint
/ask: Ce point d’entrée centralise les échanges entre l’interface utilisateur et la logique métier de l’agent. Lorsqu’un utilisateur saisit une question, celle-ci est envoyée en requête POST vers l’endpoint/ask. L’API doit valider le format des données, gérer les erreurs éventuelles (ex. : champ vide ou malformé), et orchestrer les différentes étapes de traitement (chargement du contexte, appel au modèle, formatage de la réponse). C’est également à ce niveau que peuvent être ajoutées des métriques de suivi (temps de réponse, logs, score de confiance) ; - Chargement d’un modèle NLP : L’agent s’appuie sur une pipeline NLP de type « question-answering », capable de croiser une question et un contexte textuel pour générer une réponse ciblée. Grâce à la bibliothèque
transformersde Hugging Face, il est possible d’intégrer facilement des modèles préentraînés commeDistilBERTouRoBERTa. Ces modèles, tout en étant relativement légers, offrent d’excellents résultats sur des tâches de compréhension de texte, tout en permettant une exécution raisonnablement rapide sur CPU ou GPU. Le modèle peut être chargé au démarrage de l’API ou dynamiquement, selon les besoins de scalabilité ; - Recherche dans la base de connaissances : Une fois la question capturée, il faut identifier les documents ou les blocs de texte les plus susceptibles de contenir la réponse. Cette étape peut être mise en œuvre via une recherche par mots-clés simples, mais elle gagne en efficacité lorsqu’on utilise des techniques de similarité sémantique comme la vectorisation par embeddings (TF-IDF, FastText, ou
Sentence-BERT). Le backend peut ainsi comparer la question à l’ensemble des documents disponibles et sélectionner dynamiquement le ou les passages les plus proches, qui serviront de contexte au modèle QA ; - Retour de la réponse au frontend : Le résultat du modèle, généralement une phrase ou un extrait contextuel, est ensuite encapsulé dans une réponse JSON envoyée au frontend. Celui-ci l’affiche sous forme de message dans le chatbot. Il est également possible d’y associer des métadonnées (score de confiance, source du document, date de mise à jour) pour enrichir l’affichage. Un système de loading visuel ou de transitions peut être ajouté côté React pour rendre l’échange plus fluide et naturel, renforçant ainsi l’expérience utilisateur ;
- Apprentissage progressif via feedback utilisateur : Pour améliorer continuellement la qualité des réponses, l’agent peut intégrer une boucle de rétroaction utilisateur. Après chaque réponse, l’utilisateur peut donner une évaluation simple (ex. : 👍 ou 👎, ou un score de satisfaction). Ces feedbacks sont collectés, horodatés et associés à la question initiale, au contexte sélectionné et à la réponse générée. Cette base de feedbacks peut être exploitée périodiquement pour réentraîner le modèle (dans le cas d’un fine-tuning supervisé) ou pour ajuster les paramètres de sélection du contexte, voire détecter les zones d’incompréhension récurrentes.
4. Code simplifié de l’endpoint
Voici un exemple minimal d’implémentation de l’API en Python avec Flask, utilisant une pipeline pré-entraînée de Hugging Face :
from flask import Flask, request, jsonify
from transformers import pipeline
app = Flask(__name__)
qa_pipeline = pipeline("question-answering")
@app.route("/ask", methods=["POST"])
def ask():
data = request.json
question = data.get("question")
context = "Base de connaissances importée ici"
result = qa_pipeline(question=question, context=context)
return jsonify(result)
Ce code peut être facilement enrichi par un système de vectorisation de texte (TF-IDF, FastText, Sentence Transformers) pour sélectionner dynamiquement le bon contexte dans une base de données volumineuse avant interrogation du modèle NLP.
5. Enrichissements possibles de l’agent
Une fois le cœur de l’agent fonctionnel, de nombreuses optimisations et extensions peuvent être mises en place pour augmenter sa pertinence, sa résilience et son évolutivité :
- Système de mémoire conversationnelle : Permet de suivre l’historique des échanges utilisateur-agent, afin de maintenir un contexte conversationnel. Utile pour répondre à des questions de suivi comme « et pour la version premium ? » ou « tu peux me redonner l’adresse ? » ;
- Moteur de règles métier : Pour détecter certains mots-clés ou expressions critiques (ex. : « remboursement », « erreur de livraison ») et déclencher automatiquement une escalade vers un conseiller humain via un ticketing ou un live chat ;
- Module d’apprentissage supervisé : En collectant suffisamment de données d’usage (questions posées, pertinence des réponses, feedbacks utilisateurs), on peut entraîner un modèle propriétaire plus performant, adapté au domaine spécifique (ex. : juridique, médical, bancaire) ;
- Multilinguisme : En intégrant des modèles multilingues (XLM-RoBERTa, mBERT), l’agent peut répondre en plusieurs langues, avec détection automatique de la langue d’entrée ;
- Gestion des émotions ou du ton : Avec des outils d’analyse de sentiment, l’agent peut adapter son ton (plus empathique en cas de frustration détectée) ou alerter un opérateur si une tension monte dans l’échange.
Ce type d’architecture modulaire constitue une excellente base pour développer des agents IA spécialisés, capables d’évoluer avec les besoins métier. L’intégration progressive de capacités avancées (apprentissage, mémoire, personnalisation) permet d’atteindre un haut niveau de pertinence sans complexité excessive initiale. C’est aussi une architecture facilement industrialisable dans un environnement cloud natif (Kubernetes, API Gateway, monitoring, CI/CD).

0 commentaires